常用自然语言处理NLP模型原理
一、文本处理流程
-
文本清洗:html标签与转义字符、多余空格、根据需要清除邮箱、账号、网址、手机号、作者信息等信息
-
预处理:去除停用词、加载自定义词库(实体词库、垂直领域词库)、分词
-
特征提取:关键词、实体词
-
建模:文本分类、文本聚类、情感分析、标签提取
-
优化:停用词库与自定义词库清洗与丰富、文本标签清洗、模型调整
-
效果评估:满足线上使用要求,准确率、速度
-
上线部署:部署api接口
二、NLP算法
- 深度学习在自然语言处理当中,除了在分类问题上能够取得较好效果外(如单选问题:情感分类、文本分类、正确答案分类问题等),在信息抽取上,尤其是在元组抽取上基本上是一塌糊涂,在工业场景下很难达到实用水准。
- 目前各种评测集大多是人为标注的,人为标注的大多为干净环境下的较为规范的文本,而且省略了真实生产环节中的多个环节。在评测环节中达到的诸多state-of-art方法,在真实应用场景下泛化能力很差,大多仅仅是为了刷榜而刷榜。
- 目前关于知识图谱的构建环节中,数据大多数都还是来自于结构化数据,半结构化信息抽取次之,非结构化数据抽取最少。半结构化信息抽取,即表格信息抽取最为危险,一个单元格错误很有可能导致所有数据都出现错误。非结构化抽取中,实体识别和实体关系识别难度相当大。
- 工业场景下命名实体识别,标配的BILSTM+CRF实际上只是辅助手段,工业界还是以领域实体字典匹配为主,大厂中往往在后者有很大的用户日志,这种日志包括大量的实体信息。因此,生产环节中的实体识别工作中,基础性词性的构建和扩展工作显得尤为重要。
- 目前关于知识图谱推理问题,严格意义上不属于推理的范畴,最多只能相当于是知识补全问题,如评测中的知识推理任务,是三元组补全问题。
- 目前舆情分析还是处于初级阶段。目前舆情分析还停留在以表层计量为主,配以浅层句子级情感分析和主题挖掘技术的分析。对于深层次事件演化以及对象级情感分析依旧还处于初级阶段。
- Bert本质上仅仅是个编码器,是word2vec的升级版而已,不是无所不能,仅仅是编码能力强,向量表示上语义更为丰富,然而大多人都装糊涂。
- 学界和业界最大的区别在于,学界以探索前沿为目的,提新概念,然后搭个草图就结束,目光并不长远,打完这一战就不知道下一战打什么,下一战该去哪里打,什么时候打,或者打一枪换个阵地再打。而业界,往往面临着生存问题,需要考虑实际问题,还是以解决实际问题为主,因此没必要把学界的那一套理念融入到生产环节中,要根据实际情况制定自己的方法。
- 利用结构化数据,尤其是百科类infobox数据,采集下来,存入到Neo4j图数据库中,就称自己建立了知识图谱的做法是伪知识图谱做法。基于这类知识图谱,再搞个简单的问答系统,就标榜自己是基于知识图谱的智能问答,实际上很肤浅。
- 知识图谱不是结构化知识的可视化(不是两个点几条边)那么简单,那叫知识的可视化,不是知识图谱。知识图谱的核心在于知识的图谱化,特点在于知识的表示方法和图谱存储结构,前者决定了知识的抽象表示维度,后者决定了知识运行的可行性,图算法(图遍历、联通图、最短路径)。基于图谱存储结构,进行知识的游走,进行知识表征和未知知识的预测。
- 物以稀为贵,大家都能获取到的知识,往往价值都很低。知识图谱也是这样,只有做专门性的具有数据壁垒的知识图谱,才能带来商业价值。
- 目前智能问答,大多都是人工智障,通用型的闲聊型问答大多是个智障,多轮对话缺失,答非所问等问题层出不穷。垂直性的问答才是出路,但真正用心做的太少,大多都是处于demo级别。
- 大多数微信自然语言处理软文实际上都不可不看,纯属浪费时间。尤其是在对内容的分析上,大多是抓语料,调包统计词频,提取关键词,调包情感分析,做柱状图,做折线图,做主题词云,分析方法上千篇一律。应该从根本上去做方法上的创新,这样才能有营养,从根本上来说才能有营养可言。文本分析应该从浅层分析走向深层分析,更好地挖掘文本的语义信息。
- 目前百科类知识图谱的构建工作有很多,重复性的工作不少。基于开放类百科知识图谱的数据获取接口有复旦等开放出来,可以应用到基本的概念下实体查询,实体属性查询等,但目前仅仅只能做到一度。
- 基于知识图谱的问答目前的难点在于两个方面,1)多度也称为多跳问题,如姚明的老婆是谁,可以走14条回答,但姚明的老婆的女儿是谁则回答不出来,这种本质上是实体与属性以及实体与实体关系的分类问题。2)多轮问答问题。多轮分成两种,一种是指代补全问答, 如前一句问北京的天气,后者省略“的天气”这一词,而只说“北京”,这个需要进行意图判定并准确加载相应的问答槽。另一种是追问式多轮问答,典型的在天气查询或者酒店预订等垂直性问答任务上。大家要抓住这两个方面去做。
- 关系挖掘是信息抽取的重要里程碑,理解了实体与实体、实体与属性、属性与属性、实体与事件、事件与事件的关系是解决真正语义理解的基础,但目前,这方面,在工业界实际运用中,特定领域中模板的性能要比深度学习多得多,学界大多采用端到端模型进行实验,在这方面还难以超越模版性能。
1、TF-IDF
1)原理:词频-逆文档频率;一种用于信息检索与文本挖掘的常用加权技术;一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
2)主要思想:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
3)公式:
TF=在某一文本中词条w出现的次数/该文本中所有的词条数目
IDF=log(语料库的文档总数/(包含词条w的文档数+1)),避免分母为0
TF-IDF=TF*IDF
4)优缺点:实现简单,容易理解,但未考虑词语语义信息,无法处理一词多义与一义多词
5)应用:搜索引擎,关键词提取,文本相似性计算,文本摘要
6)python调参:
提取关键词
keywords = jieba.analyse.extract_tags(sentence, topK=10, withWeight=False, allowPOS=()) # 主要调参指定词性的词
提取特征向量
tfidf = TfidfVectorizer(ngram_range=(1, 2), min_df=1, max_df=0.9, token_pattern=r"(?u)\b\w+\b", stop_words=stopwords, max_features=1000)
'''
ngram_range=(1, 2) : 词组长度为1和2
min_df : 忽略出现频率小于1的词
max_df : 忽略在百分之九十以上的文本中出现过的词
token_pattern=r"(?u)\b\w+\b" : 包含单字
stop_words : 停用词表
max_features=1000: 最大特征向量维度
'''
2、Textrank
1)原理:将每个句子看成一个节点,若两个句子之间有相似性,认为对应的两个节点之间有一个无向有权边,权值是相似度。通过pagerank算法(两个假设:数量假设,页面A被其他网页链接越多,页面A越重要;质量假设,质量越高的页面链接指向页面A,页面A越重要)计算得到的重要性最高的若干句子可以当作摘要。PageRank主要用于对在线搜索结果中的网页进行排序。
PageRank的核心公式是PageRank值的计算公式。公式如下: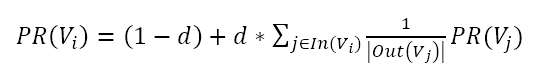
其中,PR(Vi)表示结点Vi的rank值,In(Vi)表示结点Vi的前驱结点集合,Out(Vj)表示结点Vj的后继结点集合。
这个公式来自于《统计学习方法》,等号右边的平滑项(通过某种处理,避免一些突变的畸形值,尽可能接近实际情况)不是(1-d),而是(1-d)/n。
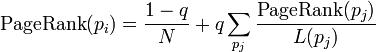
![]() 是被研究的页面,
是被研究的页面,![]() 是
是![]() 链入页面的数量,
链入页面的数量,![]() 是
是![]() 链出页面的数量,而N是所有页面的数量。
链出页面的数量,而N是所有页面的数量。
在文本自动摘要的案例中,TextRank和PageRank的相似之处在于:
-
用句子代替网页
-
任意两个句子的相似性等价于网页转换概率
-
相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
不过公式有些小的差别,那就是用句子的相似度类比于网页转移概率,用归一化的句子相似度代替了PageRank中相等的转移概率,这意味着在TextRank中,所有节点的转移概率不会完全相等。
TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
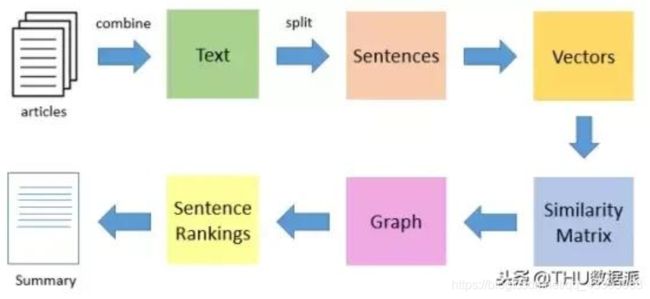
3、知识库构建
- 停用词库
- 语料库
- 自定义分词词库
- 人物库
- 垂直领域词库
4、知识图谱
- 三元组
- NEO4教程:Neo4j是一个世界领先的开源图形数据库。 它是由Neo技术使用Java语言完全开发的。
-
CQL代表Cypher查询语言。 像Oracle数据库具有查询语言SQL,Neo4j具有CQL作为查询语言。
Neo4j CQL:
-
它是Neo4j图形数据库的查询语言。
-
它是一种声明性模式匹配语言
-
它遵循SQL语法。
-
它的语法是非常简单且人性化、可读的格式。
5、预训练模型
语言模型

预训练模型(Pre-trained Models,PTMs)
深度学习时代,为了充分训练深层模型参数并防止过拟合,通常需要更多标注数据喂养。在NLP领域,标注数据更是一个昂贵资源。PTMs从大量无标注数据中进行预训练使许多NLP任务获得显著的性能提升。总的来看,预训练模型PTMs的优势包括:
- 在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游任务;
- 为模型提供了一个更好的初始化参数,在目标任务上具备更好的泛化性能、并加速收敛;
- 是一种有效的正则化手段,避免在小数据集上过拟合(一个随机初始化的深层模型容易对小数据集过拟合);
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量,这也是分布式表示:向量的每一维度都没有实际意义,而整体代表一个具体概念。
分布式表示相较于传统的独热编码(one-hot)表示具备更强的表示能力,而独热编码存在维度灾难和语义鸿沟(不能进行相似度计算)等问题。传统的分布式表示方法,如矩阵分解(SVD/LSA)、LDA等均是根据全局语料进行训练,是机器学习时代的产物。PTMs也属于分布式表示的范畴。
PTMs两大范式:「浅层词嵌入」和「预训练编码器」。
浅层词嵌入( Non-Contextual Embeddings):即词向量,其主要特点是学习到的是上下文独立的静态词嵌入,其主要代表如下。这一类词嵌入通常采取浅层网络进行训练,而应用于下游任务时,整个模型的其余部分仍需要从头开始学习。因此,对于这一范式的PTMs没有必要采取深层神经网络进行训练,采取浅层网络加速训练也可以产生好的词嵌入。
- NNLM
- word2vec(CBOW、Skip-Gram)
- Glove

浅层词嵌入的主要缺陷为:
- 词嵌入与上下文无关,每个单词的嵌入向量始终是相同,因此不能解决一词多义的问题。
- 通常会出现OOV问题(out of vocabulary,未登录词),为了解决这个问题,相关文献提出了字符级表示或sub-word表示,如CharCNN 、FastText和 Byte-Pair Encoding 。
预训练编码器(Contextual Embeddings):主要目的是通过一个预训练的编码器能够输出上下文相关的词向量,解决一词多义的问题。这一类预训练编码器输出的向量称之为「上下文相关的词嵌入」。这一类「预训练编码器」范式的PTMs主要代表有ELMO、GPT-1、BERT、XLNet等。
- CNN(序列模型):TEXTCNN,设定窗口,然后对窗口内的若干词进行卷积操作,得到这个窗口内的词的嵌入表示
- RNN(序列模型):基于LSTM/GRU的,基于单向(从左向右)或者双向的RNN模型,对整个序列进行建模,得到每个词的语境下的嵌入表示
- 全连接自注意力模型(self-attention,非序列化模型):使用全连接图,来建立任意两个词之间的关系,并通过大规模无标注数据,让模型自动学习结构化信息。通常,两个词之间的”连接权重“会被自注意力机制动态计算。典型的代表就是Transformer中的multi-head self-attention网络结构了
- ELMO
- BERT
- GPT
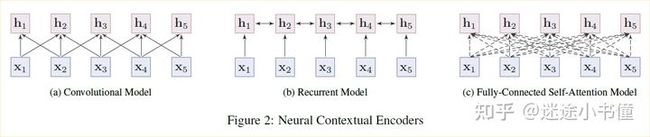
上图中,(a)里面的卷积网络,可以认为窗口为3,例如 h2 由 x1、x2、x3 决定。(b)里面的 h2 由 h1 ,h3 和 x2 决定,具体可以使用LSTM, GRU等网络结构。(c)有点复杂,可以结合Transformer网络结构来理解。
分析:
序列模型:局部性偏见,难于捕捉长距离交互;但是容易训练,并在若干NLP任务上取得了不错的结果;
非序列模型:(代表是Transformer)更强大,使用的参数更多,可以更好的覆盖长距离依赖的问题;但是,需要大规模训练语料(可以是unlabel的!),容易在中小规模数据上过拟合。
当然,Transformer已经是目前几年的研究热点,不单单在NLP领域,在CV领域和speech领域也越来越引起重视,俨然成为了“中流砥柱”!
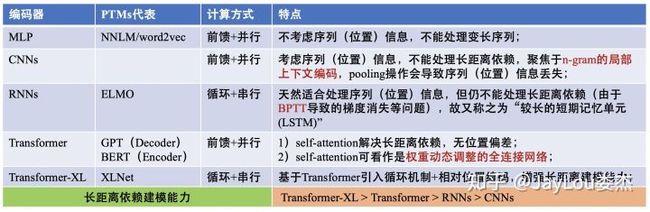
上图给出了NLP各种编码器间的对比。PTMs中预训练编码器通常采用LSTM和Transformer(Transformer-XL),其中Transformer又依据其attention-mask方式分为Transformer-Encoder和Transformer-Decoder两部分。此外,Transformer也可看作是一种图神经网络GNN。

三、参考文献
-
实话实说:中文自然语言处理的N个真实情况
-
NLP中预训练模型的综述I
-
PTMs:NLP预训练模型的全面总结
-
2020年3月18日,邱锡鹏老师发表了关于NLP预训练模型的综述《Pre-trained Models for Natural Language Processing: A Survey》,这是一篇全面的综述,系统地对PTMs进行了归纳分类