推荐系统实战1——什么是推荐系统与常见的推荐系统评价指标
推荐系统实战1——什么是推荐系统与常见的推荐系统评价指标
- 学习前言
- 什么是推荐系统
-
- 一、为什么要有推荐系统
- 二、生活中的推荐系统
- 三、推荐系统的组成
- 四、推荐模型的种类
-
- 1、基于协同过滤的方法
-
- a、基于user的协同过滤方法
- b、基于item的协同过滤算法
- 2、基于内容的方法
- 3、基于模型的方法
- 4、基于流行度的算法
- 推荐系统的评价指标
-
- 一、推荐系统的常见任务
- 二、什么是TP、TN、FP、FN
- 三、什么是Precision、Recall、F1
-
- 1、为什么需要Precision、Recall、F1
- 2、Precision、Recall、F1的计算
- 四、什么是AUC
学习前言
工作需要了解一些有关推荐系统的内容,首先学一下什么是推荐系统与常见的推荐系统评价指标吧。

什么是推荐系统
一、为什么要有推荐系统
顾名思义,推荐系统的功能就是推荐,在当前信息量急速膨胀的互联网时代,每一个人都面向了海量的数据,哪怕是一个小平台,数据量可能都是以千万为单位的,这个时候让用户自己一个一个去选择,显然是不可能的。推荐系统则可以面对海量的数据信息,从中快速推荐出符合用户特点的东西。
一个好的推荐系统是互利共赢的,用户可以获取到他们最需要的内容(如商品、音乐、新闻等)。平台也可以获取到他们最需要的内容(如流量、成交量、播放量等)。而一个差的推荐系统会导致用户获取不到有价值的东西,最终导致平台失去用户。
在我的眼里,推荐系统的功能可以归纳为以下四点:
功能一:帮助用户找到想要的东西。
功能二:提高平台的点击率、完播率等。
功能三:降低信息过载。
功能四:挖掘用户特点,为用户开拓未知的兴趣。
二、生活中的推荐系统
现在已经是2022年了,推荐系统遍布生活的方方面面,最常见的推荐系统例子有网购、音乐、短视频、长视频、直播、新闻等:
如图为淘宝网,下面的猜你喜欢便是推荐系统所做的工作。
如图为QQ音乐,下面的推荐便是推荐系统所做的工作。

如图为B站,下面的推荐便是推荐系统所做的工作:
三、推荐系统的组成
推荐系统的最重要组成部分便是推荐算法。
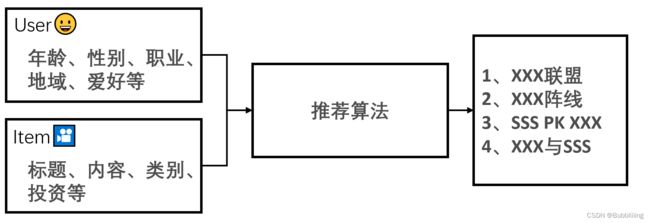
与深度学习类似的是,推荐算法其实也可以看作是黑匣子。常见的CV分类算法输入就是一张图片,中间的处理过程我们先不去看,输出是这个图片的种类。而推荐算法的输入为user和item的各种属性和特征。
user指的是用户,他的属性与特点包括年龄、性别、职业、地域、爱好等。
item指的是物品,它的属性与特点包括标题、内容、类别、价格、功能等。
推荐算法的输出是一个针对于用户的按照喜爱度排行的推荐列表。

四、推荐模型的种类
推荐算法大致可以分为以下几种类型:
1、基于协同过滤的方法
基于协同过滤的方法是基于user和item过去的交互产生新推荐的系统。协同过滤方法的主要思想是检测过去的user与item的交互情况,以估计相似的用户和相似的项目,并根据这些估计的相似度进行预测。
协同过滤方法的主要优点是它们不需要有关用户或物品的信息,如果某个user与各个item的互动越多,推荐就越准确:对于一组固定的用户和物品,越来越多的互动可以使系统越来越有效。然而,该模式只考虑过去的交互来进行推荐,因此协同过滤存在“冷启动问题”:无法向新用户推荐东西。
协同过滤方法也可以分为两类,分别为:
a、基于user的协同过滤方法
基于user的协同过滤算法可以分为以下几个步骤:
- 获得每个user对每个item的评价(是否购买、好评情况等)。
- 依据当前user对每个item的评价进行对比,计算出每个user与当前user之间的相似情况。
- 选出与当前user最相似的若干个user。
- 将这若干个user评价较高并且当前user没有涉及过的若干个item推荐给当前用户。
如图所示:

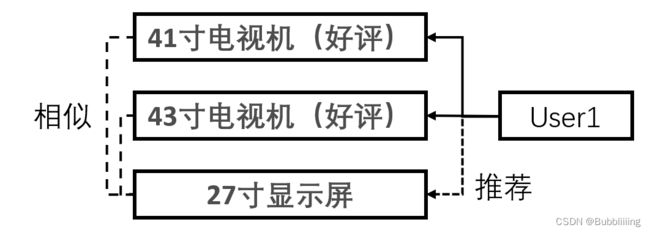
b、基于item的协同过滤算法
基于item的协同过滤算法可以分为以下几个步骤:
- 获得每个user对每个item的评价(是否购买、好评情况等)。
- 计算出当前user涉及的item与其它item之间的相似情况。
- 选出最相似的若干个且其它用户评分较高的item推荐给当前用户。
如图所示:
2、基于内容的方法
基于内容的方法与基于协同过滤的方法不同,基于内容的方法使用的是有关user和item的属性信息。
假设我们现在有一个电影推荐系统:
有关user(观众)的属性信息是例如年龄、性别、工作、爱好、地域等。
有关item(电影)的属性信息是例如类别、主要演员、持续时间、投资金额等。
基于内容的方法本质上是基于对user和item自身的特征或者属性直接分析和计算。更直白的来说,就是事先给出物品画像和用户画像,这样,我们就能根据用户喜欢什么直接给用户推荐物品。
比如我们知道User 1喜欢看喜剧,item 1也是一部喜剧,那我们就可以将电影item 1推荐给用户。现有的基于内容的方法大多使用技术分析手段来提取特征,从而计算相似性进行推荐,其重点在于信息获取与过滤。
3、基于模型的方法
基于模型的方法与基于内容的方法有一定的相似性,都需要利用到有关user和item的属性信息。
依然假设我们现在有一个电影推荐系统:
有关user(观众)的属性信息是例如年龄、性别、工作、爱好、地域等。
有关item(电影)的属性信息是例如类别、主要演员、持续时间、投资金额等。
基于模型的方法会依托于一些机器学习的模型,首先使用过去大量的user与item的点击情况进行训练,在需要推荐时,将user和item输入到网络当中进行预测,根据预测出的点击率在线进行推荐。
4、基于流行度的算法
基于流行度的算法简单粗暴,直接根据内容的点击量和播放量等数据来进行热度排序来推荐给用户。常见场景有热门电影榜、热歌榜、CSDN热榜、知乎热榜等等。
推荐系统的评价指标
一、推荐系统的常见任务
最常见的推荐系统任务就是CTR点击任务,通过模型为user推荐最有可能点击的items,因此推荐系统常常被看作一个二分类任务,判断这个item是否要推荐给user。在推荐系统的测试集里面,如果一个样本的标签为1,代表user点击了这个item,它是一个正样本;如果一个样本的标签为0,代表user没有点击这个item,它是一个负样本。
二、什么是TP、TN、FP、FN
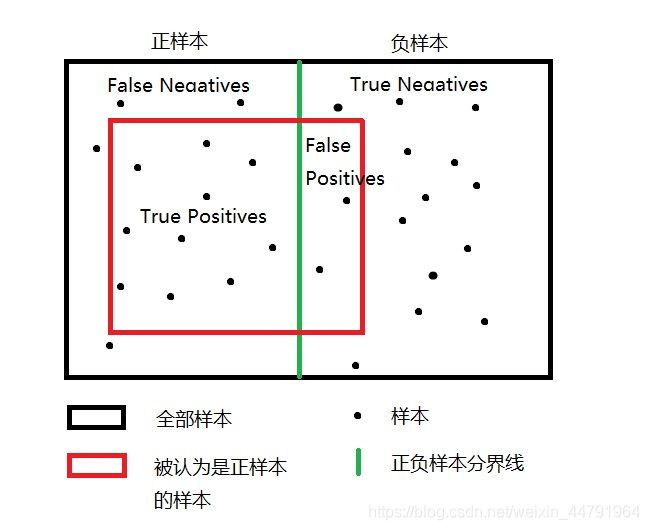
TP的英文全称为True Positives,其指的是被分配为正样本,而且分配对了的样本,代表的是被正确分类的正样本。
TN的英文全称为True Negatives,其指的是被分配为负样本,而且分配对了的样本,代表的是被正确分类的负样本。
FP的英文全称为False Positives,其指的是被分配为正样本,但分配错了的样本,代表的是被错误分类的负样本。
FN的英文全称为False Negatives,其指的是被分配为负样本,但分配错了的样本,代表的是被错误分类的正样本。
三、什么是Precision、Recall、F1
1、为什么需要Precision、Recall、F1
假设现在有1个用户,电影仓库里面有100个电影,里面共有30个喜剧和70个恐怖片。
用户想要看喜剧。电影仓库给用户推荐了50个电影,其中包括了30个喜剧,但也包括了20个恐怖片。
如何评价电影仓库的推荐情况呢?
从一方面看,系统里就只有30个喜剧,系统推荐了30个喜剧,所有喜剧都被推荐了,系统还不错。这里体现的就是召回率(Recall),代表系统能否将需要的对象都找到。
从另一方面看,系统推荐了50个剧,里面只包含了30个喜剧,只有60%推荐对了,系统不太行。这里体现的就是精确度(Precision),代表系统找到的对象是否正确。
看系统要从多方面去看,不能只看一个方面,因此提出了F1指标,F1指标是Precision、Recall的结合,具体查看下面。
2、Precision、Recall、F1的计算
Recall指的是召回率。
Precision指的是精确度。
两个分别代表什么意思呢?
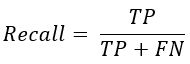
Recall的具体含义是:分类器认为是正类并且确实是正类的部分占所有确实是正类的比例,代表系统能否将需要的对象都找到。
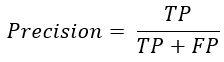
Precision的具体含义是:分类器认为是正类并且确实是正类的部分占分类器认为是正类的比例,代表系统找到的对象是否正确。
F1指标是Precision、Recall的结合,是一个综合指标:
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F_1=2\times\frac{Precision \times Recall}{Precision+Recall} F1=2×Precision+RecallPrecision×Recall
一般来讲,我们希望一个算法的F1指标越高越好。
四、什么是AUC
在了解AUC前,我们需要首先学一下ROC曲线,ROC曲线由两部分组成:
横轴是FPR,代表负样本 被判别器 判定为正样本的比例。
纵轴是TPR,代表正样本 被判别器 判定为正样本的比例,同Recall。
F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
以二分类为例,通常一个样本的预测结果为0-1之间,我们可以设置不同的门限,获取到不同的FPR与TPR值,然后绘制在图片上,就可以获得ROC曲线了。
当我们将所有的样本均当作正样本,即门限为0,那么此时TN=0,FN也等于0,FPR和TPR均为1。
当我们将所有的样本均当作负样本,即门限为1,那么此时FP=0,TP也等于0,FPR和TPR均为0。
如果系统将所有的样本都预测正确,此时FP=0,FN=0,FPR为0,TPR为1,对应下图左上角的点。
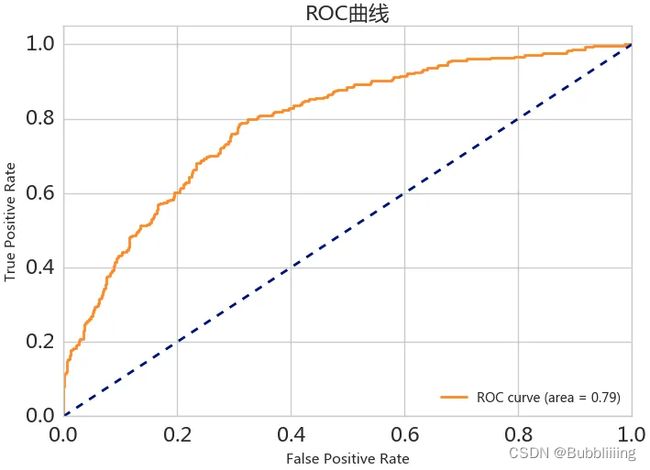
AUC(Area Under Curve)是为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。