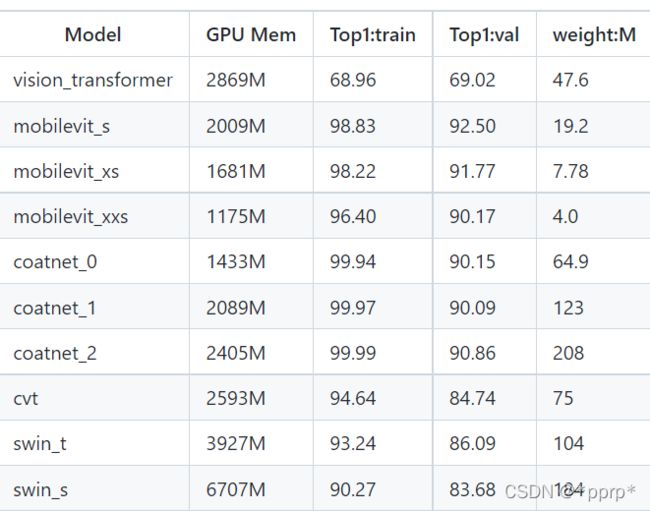
CvT: 如何将卷积的优势融入Transformer
【GiantPandaCV导语】与之前BoTNet不同,CvT虽然题目中有卷积的字样,但是实际总体来说依然是以Transformer Block为主的,在Token的处理方面引入了卷积,从而为模型带来的局部性。最终CvT最高拿下了87.7%的Top1准确率。
引言
CvT架构的Motivation也是将局部性引入Vision Transformer架构中,期望通过引入局部性得到更高的性能和效率权衡。因此我们主要关注CvT是如何引入局部性的。具体来说提出了两点改进:
- Convolutional token embedding
- Convolutional Projection
通过以上改进,模型不仅具有卷积的优势(局部感受野、权重共享、空间下采样等特性带来的优势),如平移不变形、尺度不变性、旋转不变性等,也保持了Self Attention的优势,如动态注意力、全局语义信息、更强的泛化能力等。
展开一点讲,Convolutional Vision Transformer有两点核心:
- 第一步,参考CNN的架构,将Transformer也设计为多阶段的层次架构,每个stage之前使用convolutional token embedding,通过使用卷积+layer normalization能够实现降维的功能(注:逐渐降低序列长度的同时,增加每个token的维度,可以类比卷积中feature map砍半,通道数增加的操作)
- 第二步,使用Convolutional Projection取代原来的Linear Projection,该模块实际使用的是深度可分离卷积实现,这样也能有效捕获局部语义信息。
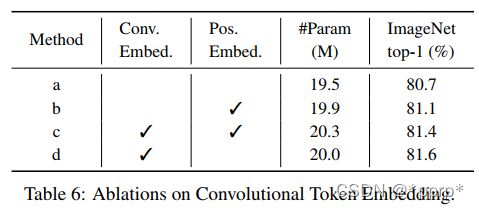
需要注意的是:CvT去掉了Positional Embedding模块,发现对模型性能没有任何影响。认为可以简化架构的设计,并且可以在分辨率变化的情况下更容易适配。
比较
在相关工作部分,CvT总结了一个表格,比较方便对比:
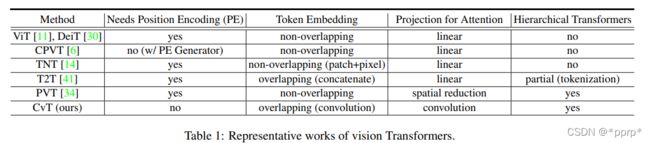
方法
在引言部分已经讲得比较详细了,下面对照架构图复盘一下(用尽可能通俗的语言描述):
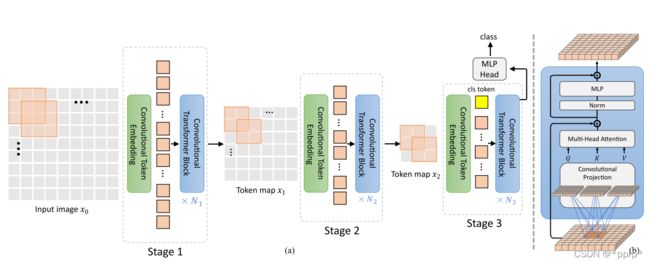
- 绿色框是conv token embedding操作,通俗来讲,使用了超大卷积核来提升局部性不足的问题。
- 右图蓝色框中展示的是改进的self attention,通俗来讲,使用了non local的操作,使用深度可分离卷积取代MLP做Projection,如下图所示:
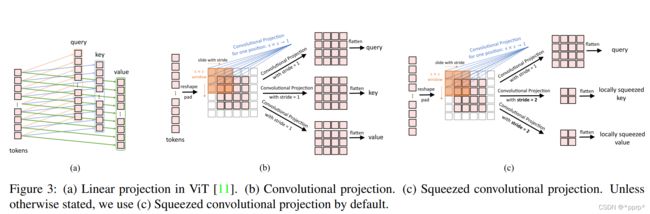
- 如图(a)所示,Vision Transformer中使用的是MLP进行Linear Projection, 这样的信息是全局性的,但是计算量比较大。
- 如图(b)所示,使用卷积进行映射,这种操作类似Non Local Network,使用卷积进行映射。
- 如图©所示,使用的是带stride的卷积进行压缩,这样做是处于对效率的考量,token数量可以降低四倍,会带来一定的性能损失。
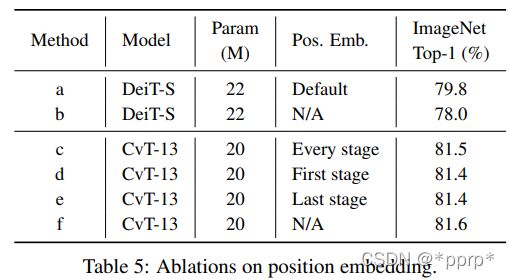
Positional embedding探讨:
由于Convolutional Projection在每个Transformer Block中都是用,配合Convolutional Token Embedding操作,能够给模型足够的能力来建模局部空间关系,因此可以去掉Transformer中的Positional Embedding操作。从下表发现,pe对模型性能影响不大。
与其他工作的对比:
- 同期工作1:Tokens-to-Tokens ViT: 使用Progressive Tokenization整合临近token,使用Transformer-based骨干网络具有局部性的同时,还能降低token序列长度。
- **区别:**CvT使用的是multi-stage的过程,token长度降低的同时,其维度在增加,从而保证模型的容量。同时计算量相比T2T有所改善。
- **同期工作2:**Pyramid Vision Transformer(PVT): 引入了金字塔架构,使得PVT可以作为Backbone应用于Dense prediction任务中。
- **区别:**CvT也使用了金字塔架构,区别在于CvT中提出使用stride卷积来实现空间降采样,进一步融合了局部信息。
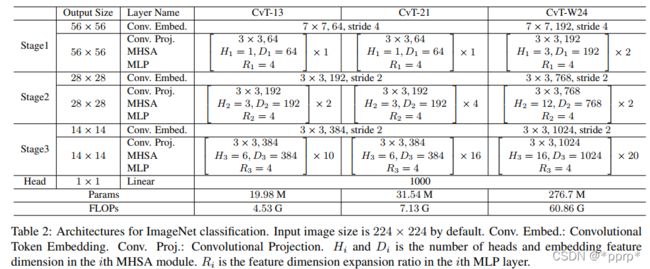
最终模型架构如下:
实验
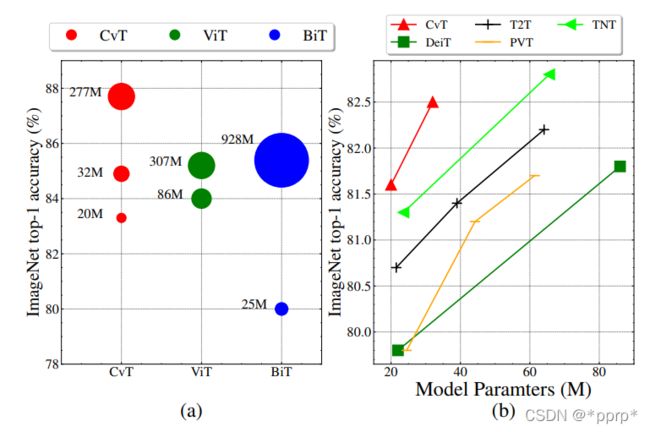
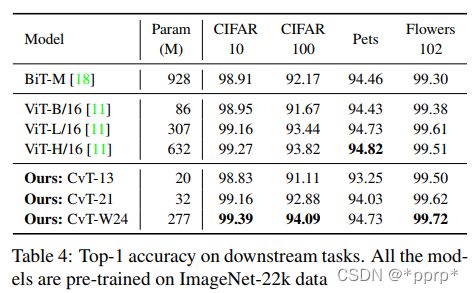
左图中令人感兴趣的是BiT,这篇是谷歌的文章big transfer,探究CNN架构在大规模数据与训练的效果,可以看出即便是纯CNN架构模型参数量也可以非常巨大,而Vision Transformer还有CvT等在同等精度下模型参数量远小于BiT,这一定程度上说明了Transformer结合CNN在数据量足够的情况下性能可以非常可观,要比单纯CNN架构的模型性能更优。
右图展示了CvT和几种vision transformer架构的性能比较,可见CvT在权衡方面做的非常不错。
与SOTA比较:
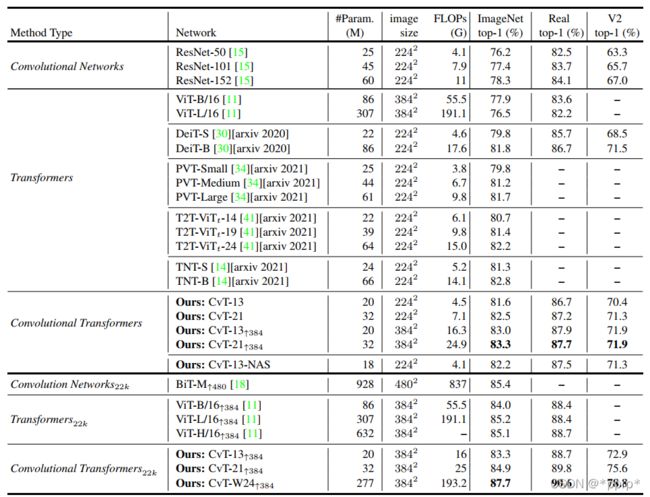
有趣的是CvT-13-NAS也采用了搜索的方法DA-NAS,主要搜索对象是key和value的stride,以及MLP的Expansion Ratio, 最终搜索的结果要比Baseline略好。
在无需JFT数据集的情况下,CvT最高调整可以达到87.7%的top1 准确率。
其他数据集结果:
消融实验

代码
Convolutional Token Embedding代码实现:可以看出,实际上就是大卷积核+大Stride的滑动引入的局部性。
class ConvEmbed(nn.Module):
""" Image to Conv Embedding
"""
def __init__(self,
patch_size=7,
in_chans=3,
embed_dim=64,
stride=4,
padding=2,
norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.proj = nn.Conv2d(
in_chans, embed_dim,
kernel_size=patch_size,
stride=stride,
padding=padding
)
self.norm = norm_layer(embed_dim) if norm_layer else None
def forward(self, x):
x = self.proj(x)
B, C, H, W = x.shape
x = rearrange(x, 'b c h w -> b (h w) c')
if self.norm:
x = self.norm(x)
x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
return x
Convolutional Projection代码实现,具体看_build_projection函数:
class Attention(nn.Module):
def __init__(self,
dim_in,
dim_out,
num_heads,
qkv_bias=False,
attn_drop=0.,
proj_drop=0.,
method='dw_bn',
kernel_size=3,
stride_kv=1,
stride_q=1,
padding_kv=1,
padding_q=1,
with_cls_token=True,
**kwargs
):
super().__init__()
self.stride_kv = stride_kv
self.stride_q = stride_q
self.dim = dim_out
self.num_heads = num_heads
# head_dim = self.qkv_dim // num_heads
self.scale = dim_out ** -0.5
self.with_cls_token = with_cls_token
self.conv_proj_q = self._build_projection(
dim_in, dim_out, kernel_size, padding_q,
stride_q, 'linear' if method == 'avg' else method
)
self.conv_proj_k = self._build_projection(
dim_in, dim_out, kernel_size, padding_kv,
stride_kv, method
)
self.conv_proj_v = self._build_projection(
dim_in, dim_out, kernel_size, padding_kv,
stride_kv, method
)
self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias)
self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias)
self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim_out, dim_out)
self.proj_drop = nn.Dropout(proj_drop)
def _build_projection(self,
dim_in,
dim_out,
kernel_size,
padding,
stride,
method):
if method == 'dw_bn':
proj = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(
dim_in,
dim_in,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=False,
groups=dim_in
)),
('bn', nn.BatchNorm2d(dim_in)),
('rearrage', Rearrange('b c h w -> b (h w) c')),
]))
elif method == 'avg':
proj = nn.Sequential(OrderedDict([
('avg', nn.AvgPool2d(
kernel_size=kernel_size,
padding=padding,
stride=stride,
ceil_mode=True
)),
('rearrage', Rearrange('b c h w -> b (h w) c')),
]))
elif method == 'linear':
proj = None
else:
raise ValueError('Unknown method ({})'.format(method))
return proj
def forward_conv(self, x, h, w):
if self.with_cls_token:
cls_token, x = torch.split(x, [1, h*w], 1)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
if self.conv_proj_q is not None:
q = self.conv_proj_q(x)
else:
q = rearrange(x, 'b c h w -> b (h w) c')
if self.conv_proj_k is not None:
k = self.conv_proj_k(x)
else:
k = rearrange(x, 'b c h w -> b (h w) c')
if self.conv_proj_v is not None:
v = self.conv_proj_v(x)
else:
v = rearrange(x, 'b c h w -> b (h w) c')
if self.with_cls_token:
q = torch.cat((cls_token, q), dim=1)
k = torch.cat((cls_token, k), dim=1)
v = torch.cat((cls_token, v), dim=1)
return q, k, v
def forward(self, x, h, w):
if (
self.conv_proj_q is not None
or self.conv_proj_k is not None
or self.conv_proj_v is not None
):
q, k, v = self.forward_conv(x, h, w)
q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads)
k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads)
v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads)
attn_score = torch.einsum('bhlk,bhtk->bhlt', [q, k]) * self.scale
attn = F.softmax(attn_score, dim=-1)
attn = self.attn_drop(attn)
x = torch.einsum('bhlt,bhtv->bhlv', [attn, v])
x = rearrange(x, 'b h t d -> b t (h d)')
x = self.proj(x)
x = self.proj_drop(x)
return x
参考
https://github.com/microsoft/CvT/blob/main/lib/models/cls_cvt.py
https://arxiv.org/pdf/2103.15808.pdf
https://zhuanlan.zhihu.com/p/142864566
笔者在cifar10数据集上修改了CvT中的Stride等参数,在不用任何数据增强和Trick的情况下得到了下图结果,Top1为84.74。虽然看上去性能比较差,但是这还没有调参以及加上数据增强方法,只训练了200个epoch的结果。
python train.py --model 'cvt' --name "cvt" --sched 'cosine' --epochs 200 --lr 0.01
感兴趣的可以点击下面链接调参:
https://github.com/pprp/pytorch-cifar-model-zoo