Ensembling Off-the-shelf Models for GAN Training(GAN模型迎来预训练时代,仅需1%的训练样本)
Ensembling Off-the-shelf Models for GAN Training
(集成现成的GAN训练模型)
论文链接:https://arxiv.org/abs/2112.09130
项目链接:https://github.com/nupurkmr9/vision-aided-gan
视频链接:https://www.youtube.com/watch?v=oHdyJNdQ9E4
解决了什么问题?
每次GAN模型都要从头训练的日子过去了!最近CMU联手Adobe提出了一种新的模型集成策略,让GAN模型也能用上预训练,成功解决「判别器过拟合(训练集性能很强,但在验证集上表现得很差)」这个老大难问题。
图像生成本身就需要能够捕捉和模拟真实世界视觉现象中的复杂统计数据,不然生成出来的图片不符合物理世界规律,直接一眼鉴定为「假」。
预训练模型提供知识、GAN模型提供生成能力,二者强强联合,多是一件美事!
问题来了,哪些预训练模型、以及如何结合起来才能改善GAN模型的生成能力?
最近来自CMU和Adobe的研究人员在CVPR 2022发表了一篇文章,通过「选拔」的方式将预训练模型与GAN模型的训练相结合。
GAN模型的训练过程由一个判别器和一个生成器组成,其中判别器用来学习区分真实样本和生成样本的相关统计数据,而生成器的目标则是让生成的图像与真实分布尽可能相同。
理想情况下,判别器应当能够测量生成图像和真实图像之间的分布差距。
但在数据量十分有限的情况下,直接上大规模预训练模型作为判别器,非常容易导致生成器被「无情碾压」,然后就「过拟合」了。
通过在FFHQ 1k数据集上的实验来看,即使采用最新的可微分数据增强方法,判别器仍然会过拟合,训练集性能很强,但在验证集上表现得很差。
Training and validation accuracy w.r.t. training iterations for our DINO [11] based discriminator vs. baseline StyleGAN2-ADA discriminator on FFHQ 1k dataset.
Figure 3. Our discriminator based on pretrained features has higher accuracy on validation real images and thus shows better generalization. In the above training, vision aided adversarial loss is added at the 2M iteration.
此外,判别器可能会关注那些人类无法辨别但对机器来说很明显的伪装。
为了平衡判别器和生成器的能力,研究人员提出将一组不同的预训练模型的表征集合起来作为判别器。
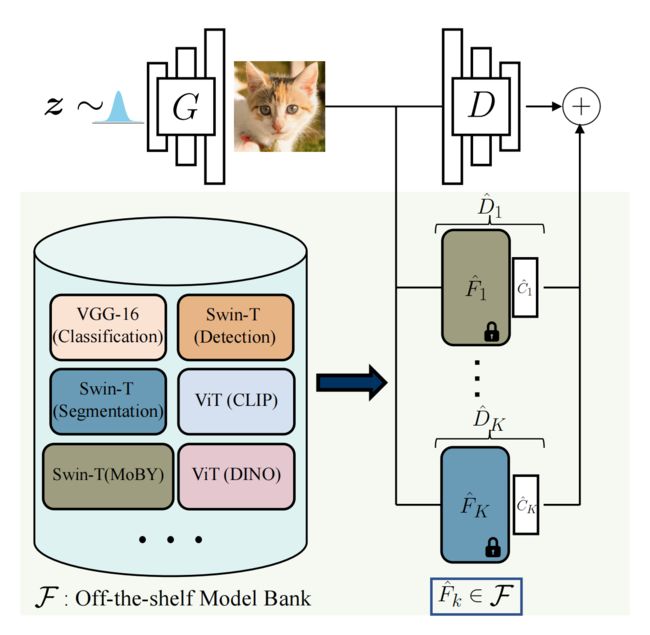 Vision-aided GAN training.
Vision-aided GAN training.
Figure 1. The model bank F consists of widely used and state-of-the-art pretrained networks. We automatically select a subset ![]() from F, which can best distinguish between real and fake distribution.
from F, which can best distinguish between real and fake distribution.
Our training procedure consists of creating an ensemble of the original discriminator D and discriminators ![]() based on the feature space of selected off-the-shelf models.
based on the feature space of selected off-the-shelf models.![]() is a shallow trainable network over the frozen pretrained features.
is a shallow trainable network over the frozen pretrained features.
这种方法有两个好处:
1、在预训练的特征上训练一个浅层分类器是使深度网络适应小规模数据集的常见方法,同时可以减少过拟合。
也就是说只要把预训练模型的参数固定住,再在顶层加入轻量级的分类网络就可以提供稳定的训练过程。
比如上面实验中的Ours曲线,可以看到验证集的准确率相比StyleGAN2-ADA要提升不少。
2、最近也有一些研究证明了,深度网络可以捕获有意义的视觉概念,从低级别的视觉线索(边缘和纹理)到高级别的概念(物体和物体部分)都能捕获。
建立在这些特征上的判别器可能更符合人类的感知能力。
并且将多个预训练模型组合在一起后,可以促进生成器在不同的、互补的特征空间中匹配真实的分布。
为了选择效果最好的预训练网络,研究人员首先搜集了多个sota模型组成一个「模型银行」,包括用于分类的VGG-16,用于检测和分割的Swin-T等。
然后基于特征空间中真实和虚假图像的线性分割,提出一个自动的模型搜索策略,并使用标签平滑和可微分的增强技术来进一步稳定模型训练,减少过拟合。
具体来说,就是将真实训练样本和生成的图像的并集分成训练集和验证集。
对于每个预训练的模型,训练一个逻辑线性判别器来分类样本是来自真实样本还是生成的,并在验证分割上使用「负二元交叉熵损失」测量分布差距,并返回误差最小的模型。
一个较低的验证误差与更高的线性探测精度相关,表明这些特征对于区分真实样本和生成的样本是有用的,使用这些特征可以为生成器提供更有用的反馈。
研究人员我们用FFHQ和LSUN CAT数据集的1000个训练样本对GAN训练进行了经验验证。
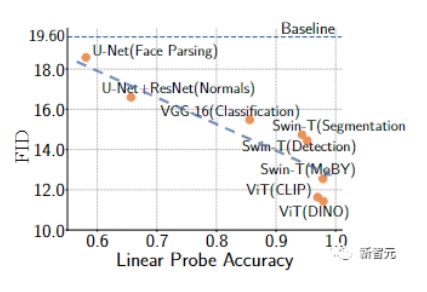

结果显示,用预训练模型训练的GAN具有更高的线性探测精度,一般来说,可以实现更好的FID指标。
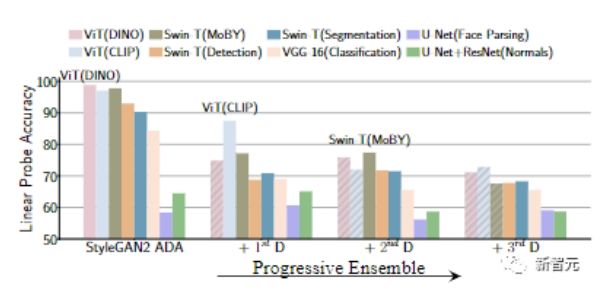
为了纳入多个现成模型的反馈,文中还探索了两种模型选择和集成策略
1)K-fixed模型选择策略,在训练开始时选择K个最好的现成模型并训练直到收敛;
2)K-progressive模型选择策略,在固定的迭代次数后迭代选择并添加性能最佳且未使用的模型。
实验结果可以发现,与K-fixed策略相比,progressive的方式具有更低的计算复杂度,也有助于选择预训练的模型,从而捕捉到数据分布的不同。例如,通过progressive策略选择的前两个模型通常是一对自监督和监督模型。
文章中的实验主要以progressive为主。
最终的训练算法首先训练一个具有标准对抗性损失的GAN。


给定一个基线生成器,可以使用线性探测搜索到最好的预训练模型,并在训练中引入损失目标函数。
在K-progressive策略中,在训练了与可用的真实训练样本数量成比例的固定迭代次数后,把一个新的视觉辅助判别器被添加到前一阶段具有最佳训练集FID的快照中。
在训练过程中,通过水平翻转进行数据增强,并使用可微分的增强技术和单侧标签平滑作为正则化项。
还可以观察到,只使用现成的模型作为判别器会导致散度(divergence),而原始判别器和预训练模型的组合则可以改善这一情况。
最终实验展示了在FFHQ、LSUN CAT和LSUN CHURCH数据集的训练样本从1k到10k变化时的结果。


在所有设置中,FID都能获得显著提升,证明了该方法在有限数据场景中的有效性。
为了定性分析该方法和StyleGAN2-ADA之间的差异,根据两个方法生成的样本质量来看,文中提出的新方法能够提高最差样本的质量,特别是对于FFHQ和LSUN CAT


当我们逐步增加下一个判别器时,可以看到线性探测对预训练模型的特征的准确性在逐渐下降,也就是说生成器更强了。

总的来说,在只有1万个训练样本的情况下,该方法在LSUN CAT上的FID与在160万张图像上训练的StyleGAN2性能差不多。
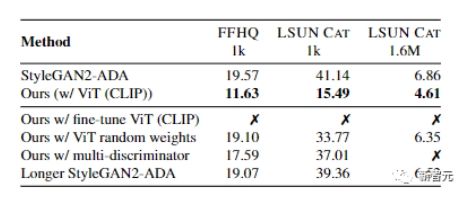

而在完整的数据集上,该方法在LSUN的猫、教堂和马的类别上提高了1.5到2倍的FID。

CMU联手Adobe:GAN模型迎来预训练时代,仅需1%的训练样本-51CTO.COM