李宏毅机器学习(八)自编码器(Auto-encoder)
前情提要
什么自监督学习?
做不需要标注资料的任务,比如做填空题,比如预测下一个任务!
这个时候我们只需要对在自监督中训练的模型进行fine-tune就可以用在下游任务中了!
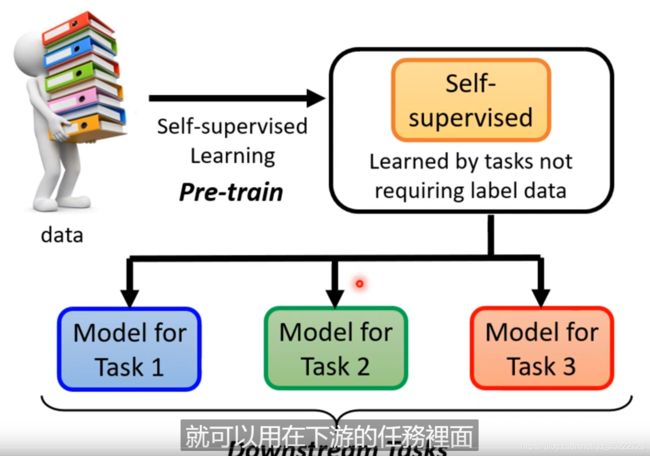
但是在不需要标注的数据之前呢,在BERT、self-supervised learning之前有一个工具叫做Auto-Encoder! 也是不需要标注的数据的。
Auto-Encoder
怎么运作的?
它是一个无监督的,不需要任何标注资料的任务! 目的就是让图片经过中间的网络后和最终的目标尽可能的相似! 和Cycle GAN中的方法是一样的! 中间的Vector叫做Embedding、Representation,code!都是指的是同一件事! 这有什么用呢? 我们要使用的中间的这个Vector,它不再是原来图片的高维向量(比如100 * 100维度的图片, 如果是RGB那么就是3万维度),而经过Encoder 压缩之后的低维向量,这个向量往往是10维,100维等。 同时Encoder的输出也叫做瓶颈层,叫做BottleNeck,因为我们输入的是宽维度的向量,但是最终输出的是低纬度向量! 同时这也叫做Dimension reduction。 也可以叫做pre-train
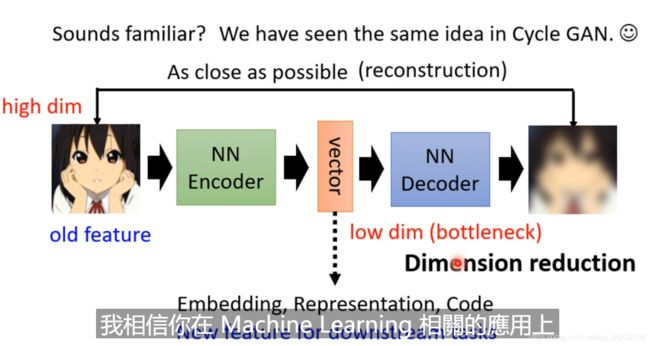
Dimension reduction方法有PCA、t-SNE,它们不是深度学习!
Why Auto-encoder?
为什么Auto-encoder能获取存储图片信息的低维度的向量呢? 这些向量怎么就能代表这个图片呢?
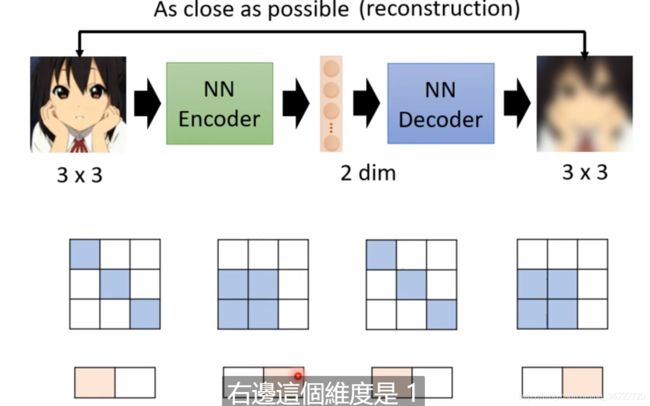
因为图片的变化看起来大,但是却很小。图片的变化类型是有限的, 我们只需要记录这几种变化类型就可以!就仿佛上图中四个3*3大小的图片, 只有两种类型! 所以我们只需要记录这两种变化类型就行了, 01和10就够了!
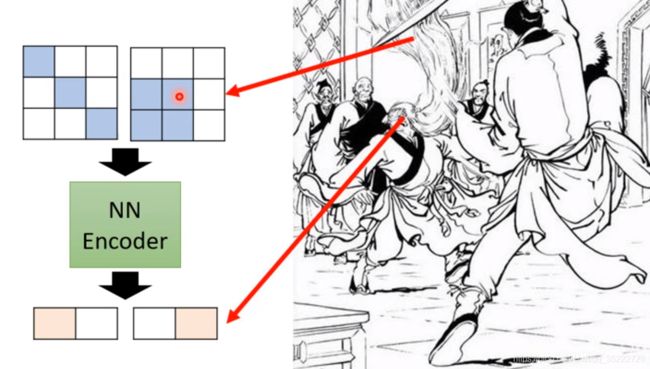
就仿佛神雕侠侣中樊一翁,它的胡子虽然变化多,但是只是表象,头的可变化的类型很少! 我们只需要预判了它的头的变化就可以了。
Auto-encoder 并不是一个新的idea
原来的方法并没有深度学习的概念,要分块进行训练的!
De-noising Auto-encoder
给原图片添加噪音, 然后还是让它恢复到原来的图片,那么这个encoder必须有能力来去除噪音!
这在BERT中也有相同的应用! 比如添加mask! 所以我们可以说BERT就是一个添加了噪音的Auto-encoder! 当然Decoder不一定是一个Linear层,也可以自己定义哦!
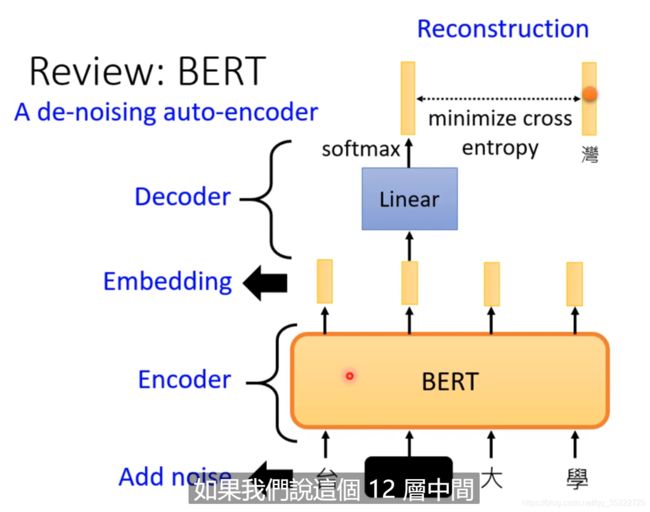
Feature Distangle
Distangle: 就是把原来纠缠在一起的东西解开来!
下面的各种特征都在这里面,但是我们并不知道哪些特征代表了哪些资讯!
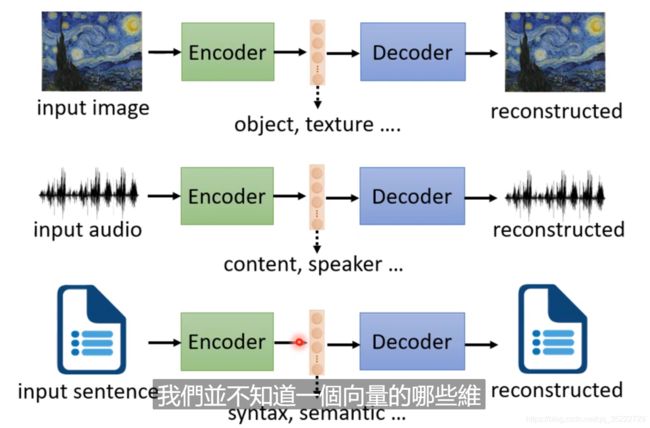
所以我们是不是可以分解出特征来,比如前五十维度表示内容信息,后五十维度表示的是说话人的信息等等!当然feature Distangle也是有很多的办法来去做的!
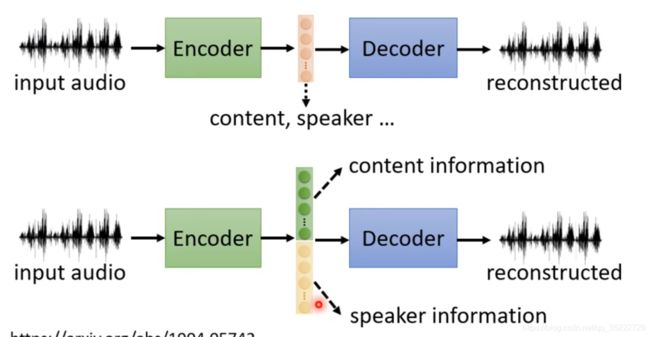
这是有办法做的,下边的就是方法了!每一个dimension就代表了一个资讯!

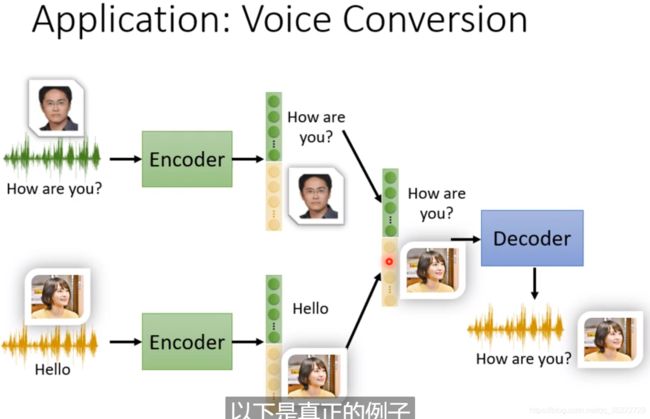
Application: Voice Conversion
Voice Conversion:语音转换!就是柯南的领结变声器!
在过去都是有监督学习,在采集样本时候需要Speaker A 和 Speaker B录制相同的语音,这样才能完成模型的训练! 但是现在我们可能不再需要一模一样的录制了!

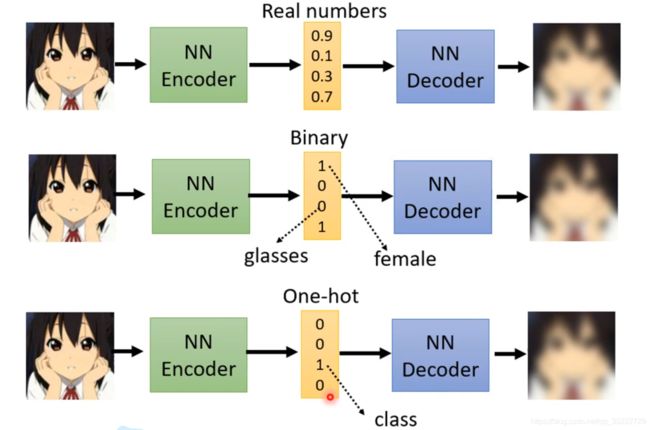
Discrete Representation
向量的表示有三种可能性: Real Numbers、Binary和One-hot! 比如Binary中某一个值就代表了是不是的问题, 是男的还是女的?戴眼镜了吗? 而One-hot也代表了分类任务,比如0-9手写体的识别!
例子:VQVAE(Vector Quantized Variational Auto-encoder)
Codebook中是一系列向量,是学习出来的数据! 同时也是预定义的向量! 我们需要的就是计算Encoder出的向量和Codebook中的相似度,相似度最高的那个向量就作为Decoder的输入! 类似于Self-attention! 当然也可以用在语音识别中,在语音识别中,codebook中的向量完全可以代表kk音标!

Text as Representation
我们可不可以embedding出文字,而不是向量呢? 该文字经过Decoder后会得到整个文章! 而该sequence就是文章的核心和摘要! 这是一个seq2seq2seq的auto-encoder, 而这个任务仅仅需要一大堆的文件拉进行训练这个模型。但是这是不行的,因为Decoder会发明自己的暗号,中间生成的文字是看不懂的文字! 这要怎么办呢? 这个时候就可以添加一个Discriminator,Discriminator是可以分出输出是不是真汉字的,所以Discriminator可以判断中间的单词是不是问题。这样就可以添加双向限制, 既能生成文章, 又可以判断出是不是汉字! 这就是CycleGAN
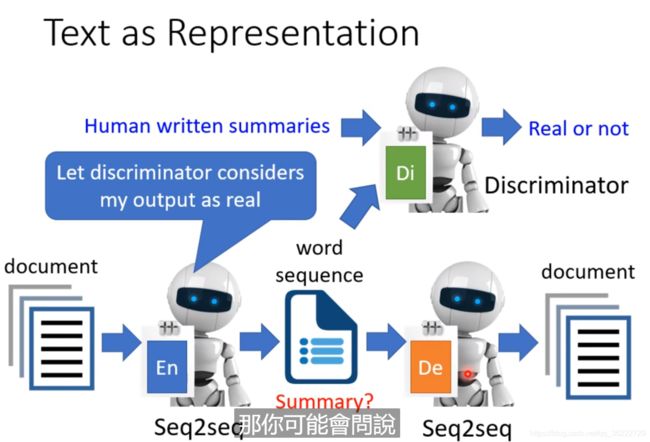
我们就硬Train!
Tree as Embedding
Application
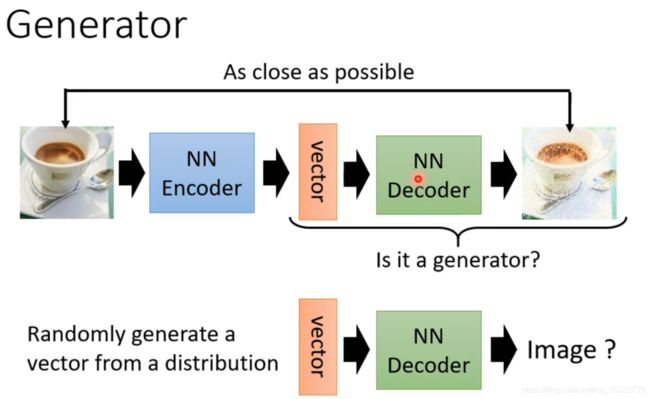
Generator
我们可以将Decoder作为Generator! 我们通过模型训练之后得到Decoder!
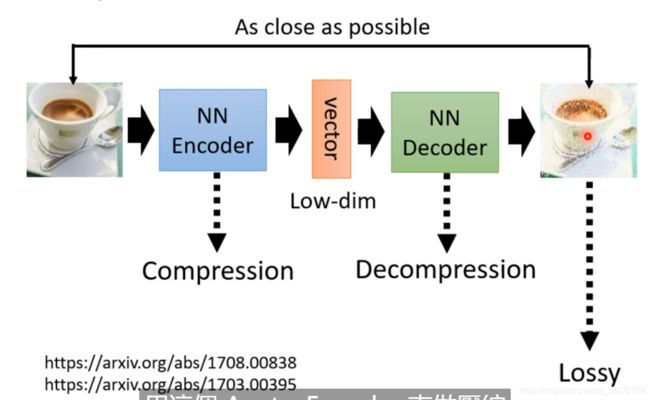
Compression
如果图片太大了,我们可以把Encoder当作压缩器来生成低维向量! 而Decoder做的事情Decompression,但是这样得出的图片是有失真的!
Anomaly(Outlier、Novelty) Detection
检查输入的x和训练数据是不是一样!
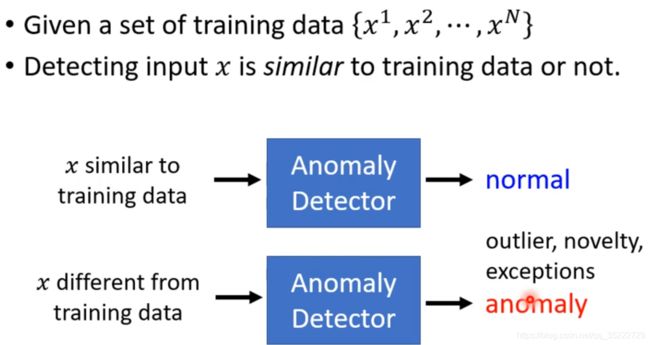
但是我们的x正确不正确完全取决于训练数据!

欺诈检测: 训练数据,正确的信用卡交易
网络的侵入检测: 黑客检测,连入是不是正常的
细胞检测:是不是一个癌细胞?
和分类任务的区别: 分类任务是需要大量正反样本的,而且其中很多错误的样本就混在了正样本里。 但是现实中是很难收集很多的负样本的! 再比如人脸识别,这肯定不能收集所有的负样本啊,只能是收集正样本!
这是一个one-class问题,而不是二分类问题! 这就需要Auto-encoder登场了!
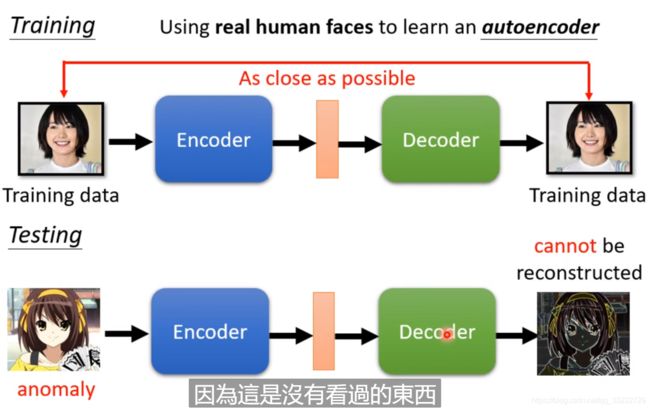
人脸检测
我们检测是不是真人的人脸,而不是二次元的,那么我们就可以通过搜集一堆的人脸图片,通过将它们encoder和Decoder,如果能合成真人图片,那么就是真人!
如果输入的是二次元图片,那么在经过encoder和decoder后是合成不了正常的图片的!
More about Anomaly Detection:
