(InceptionV2/V3)Rethinking the Inception Architecture for Computer Vision--Christian Szegedy
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, & Zbigniew Wojna (2016). Rethinking the Inception Architecture for Computer Vision computer vision and pattern recognition.
- 0、摘要
- 1、引入
- 2、通用设计原则
-
- 2.1 避免表征瓶颈
- 2.2 特征数据越多收敛越快
- 2.3 可以降维(压缩特征维度数)来减少计算量
- 2.4 网络的深度和宽度(特征维度数)要做到平衡
- 3、基于大滤波器尺寸分解卷积
-
- 3.1 分解到更小的卷积
- 3.2 非对称卷积的空间分解
- 4、利用辅助分类器
- 5、有效的网格尺寸减少
- 6、Inception-V2
- 7、使用LabelSmooth对模型进行正则化
- 8、低分辨率输入的性能
- 9、实验结果
-
- 9.1 改动带来的效果
- 9.2(单模型)与其他模型的比较
- 9.3(Ensemble模型)与其他模型的比较
- 10、总结
本文在GoogleNet(Inception-V1)的基础上同时提出了Inception-v2(第6节)/v3(第9节),本文的主要内容是发现如果你什么都不懂就对之前Inception的结构进行改动,不仅可能会增大参数量,并且效果也会不稳定,所以作者提出了多种优化方法,并且按照这一套合理的规则来优化Inception结果是最可靠的。
最终根据这些原则和方法,在GoogleNet之上优化出了Inception-V2,然后Inception-V2+一些trick就得到了Inception-V3,通过与其他模型相比,性能拔尖(效果好,计算量低)
从下图看到ILSVRC2014上GoogleNet得了第一,然后第二年优化GoogleNet的Inception-V3得了第三(MSRA是微软亚洲研究院,是因为ResNet加持得了第一)
(ILSVRC2014:)
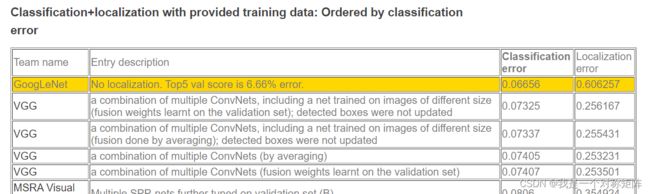
(ILSVRC2015:)
0、摘要
从2014年其CNN成了主流,大家都通过增大模型来直接提高效果,但是计算效率在各种应用场景成了限制因素,所以作者通过适当的分解卷积和正则化等方式充分有效利用增加的计算(个人理解是既然增加参数不可避免,那么如何让增加的参数能够最大提升模型的性能)。(GoogLeNet首次出现在2014年ILSVRC 比赛中获得冠军。这次的版本通常称其为Inception V1,就是同时有多个支路的经典结构)。
然后作者在ILSVRC2012分类挑战赛的验证集上评估了他们的方法并超越了当时最先进的方法:单模型的error是21.2%的top1和5.6%的top5,而ensemble四个模型的error是17.3%的top1和3.5%的top5。
1、引入
这部分主要讲了GooleNet(Inception V1)的好处,然后又指出其缺点,并给出优化建议
在2014 ILSVRC分类挑战赛上,GooleNet夺得第一名(top5 error:6.656%),VGGNet夺得了第二名(top5 error:7.325%),它两都取得了类似的高性能。虽然VGGNet结构简介,但是计算成本很高,需要大量的计算。而GoogleNet的Inception结构则被设计为在内存和计算有限的情况下也能表现良好(VGGNet参数量大概是GoogleNet参数量的36倍)。
这样看来GoogleNet不仅轻量而且效果好,但是问题是Inception 结构的复杂性让网络难以修改,如果单纯的放大架构则违背了设计初衷(资源有限,放大架构则计算量变大了),而GoogleNet又没有讲为什么要这样设计,所以在用GoogleNet解决新任务时,没法进行有效的改动。
所以作者提出了一些优化原则(当然在其他网络设计上也有意义),在修改GoogleNet时应当遵守这些指导原则保持模型的高质量。
2、通用设计原则
2.1 避免表征瓶颈
特别是在网络前面要避免。所谓的表征瓶颈就是中间某层对特征在空间维度进行较大比例的压缩(空间维度可以指尺寸WH或者通道数C,比如pooling层就可以存在尺寸层面的剧烈减小,通道方面比如从1000突降到10通道)。如果存在表征瓶颈可能会导致特征丢失,但是比如pooling不可或缺但是可以通过一些优化方式减少损失
2.2 特征数据越多收敛越快
这一块不理解为什么,只能从网上摘抄一些理解。
相互独立的特征越多,输入的信息分解的越彻底,所产生的网络将训练更快
相互独立的特征越多,输入的信息就被分解的越彻底,分解的子特征间相关性低,子特征内部相关性高,把相关性强的聚集在了一起会更容易收敛。这点就是Hebbin原理:fire together, wire together。规则2和规则1可以组合在一起理解,特征越多能加快收敛速度,但是无法弥补Pooling造成的特征损失,Pooling造成的representational bottleneck要靠其他方法来解决。
Hebbin 赫布原理
2.3 可以降维(压缩特征维度数)来减少计算量
GoogleNet中提出使用1x1卷积先降维再特征提取。不同维度的信息有相关性,则在降维时其损失会很小(类似压缩算法,如果存在相关性则能够更大限度压缩),利用相关性也能恢复出原有的信息
2.4 网络的深度和宽度(特征维度数)要做到平衡
通过平衡每个阶段的滤波器数量和网络的深度可以达到最佳性能。增加网络的宽度和深度可以有助于更高质量的网络。然而如果并行增加则可以达到恒定计算量的最佳改进。因此计算预算应该在网络的深度和宽度之间平衡分配。
3、基于大滤波器尺寸分解卷积
GoogleNet的大部分初始收益来源于大量使用降维(然后3x3卷积就会减少很多计算量),这可以被看作有效分解卷积的特例
3.1 分解到更小的卷积
比如可以使用两个3x3卷积代替一个5x5的卷积,参数量降低到原来的(2x3x3)/(5x5)=0.72倍
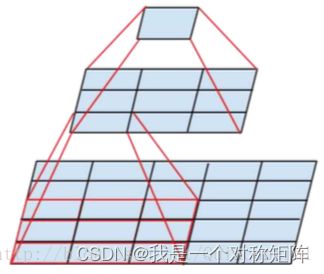
3.2 非对称卷积的空间分解
实际上就是将3x3卷积分解为13卷积和31卷积,参数量从9降低到6
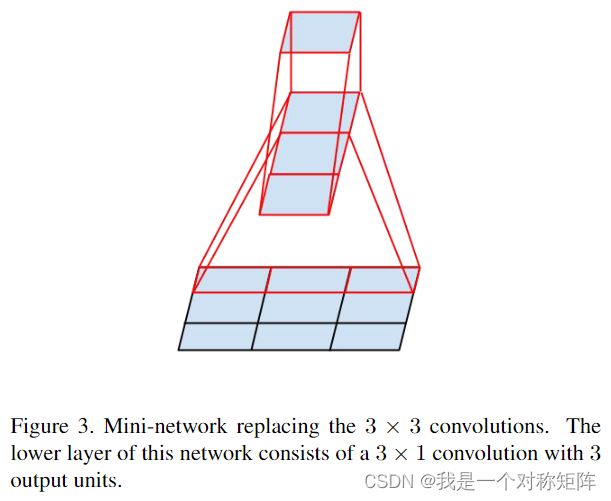
首先按上图的分解比分解成两个2x2卷积要好,因为按上图分解要省33%,而两个2x2卷积仅生11%。
其次这种不对称空间分解最适合在中间层使用(格子在12~20之间)。在这个层面将7x7分解1x7和7x1卷积也可以获得很好的效果
下图从左到右依次是原始Inception模块、用3x3替换5x5卷积、用1x3和3x1卷积替代3x3卷积的示意图(后面介绍inceptionv2结构时会用到图5、图6、图7)

还有根据原则2.2设计的模块

4、利用辅助分类器
在GoogleNet(InceptionV1)中加入了两个辅助分类器,一个靠近输入端,一个靠近输出端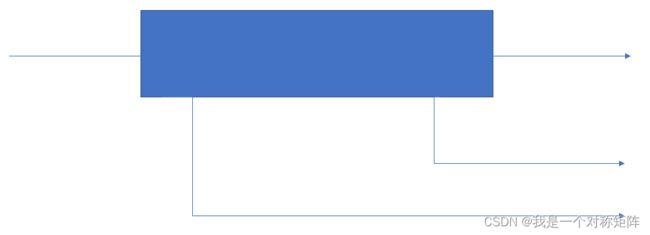
两个辅助分类器只在训练时用,在预测时不用,其用法如下代码:
# 训练时网络输出三个值,分别与gt计算loss,并按权重计算总的loss
logits,aux_logits2,aux_logits1 = net(images.to(device))
loss0 = loss_function(logits,labels.to(device))
loss1 = loss_function(aux_logits1,labels.to(device))
loss2 = loss_function(aux_logits2,labels.to(device))
loss = loss0+loss1*0.3+loss2*0.3
当初V1作者想的是用三个loss的加权和作为总loss,这样计算梯度时就可以分别直接推向三个分支,其中就有推向较低层的梯度,使其立即有用。
但是本文作者实验发现,在训练早期有没有辅助分类器都一样,但是当训练接近结束时,有辅助分类器的开始超越没有辅助分类器的网络。
还通过实验发现,偏低层的辅助分类器不要对最终结果没有影响,这意味着当初设计低层辅助分类器是为了发展低层特征这一想法可能是错的。相反,作者认为辅助分类器充当正则化器,因为如果辅助分类器是有BN或Dropout层,网络的主分类器性能会更好。(这也为猜测BN是一种正则化提供了一个微弱的支持证据)
总之三个结论:
- 辅助分类器在后期才有作用
- 低层特征旁的分类器没用
- 辅助分类器起作用应当是充当了正则化功能(特别是含BN或Dropout层效果更好)
5、有效的网格尺寸减少
网格其实就是特征图的尺寸,在2.1节说过要避免尺寸突然变化的表征瓶颈,所以要慢慢变化。
但是想pooling层是不可避免地,但是显然直接使用会产生表征瓶颈(比如50x50–>25x25),因此为了缓解pooling带来的负面影响,我们需要牢记一个原则:当尺寸减少一般时特征图要增加一般(32x50x50–>64x25x25)。
要满足这个原则,常规想到的方法可能就是下面两种方法(inception块可以看作是升维操作),如果是左边这个方法,一开始的pooling就违背了2.1的表征瓶颈,所以不行。如果是右边,先升维再pooling,虽然符合要求但是计算量增大了,也不尽人意。

于是作者设计了一个并行的结构,核心思想就是右图,通过conv(stride=2)和pool(stride=2)分别降采样,然后将两个concat在一起,就实现了降采样的同时升维,在保证计算量的同时避免了表征瓶颈 )
)
6、Inception-V2
通过上面的点我们提出一个新的架构。

首先注明一下所谓的传统也就是在GoogleNet之上的改动
figure5:将5x5卷积替换为2个3x3卷积
figure6:将3x3卷积替换为1x3和3x1卷积
figure7:使用并行1x3和3x1卷积
- 将传统的7x7卷积替换为3个3x3卷积(即开头的三个)
- 在35x35处是三个传统的Inception模块
- 从35x35到17x17就使用了第5节的有效网格减少思想
- 从17x17到8x8也使用了有效网格减少思想
总之只要遵守第2节的原则,网络的质量就会稳定变化。虽然我们的网络有42层深度,但我们的计算成本只比GoogLeNet高2.5左右,效率仍然比VGGNet高很多。
7、使用LabelSmooth对模型进行正则化
这没什么好说的
8、低分辨率输入的性能
这部分主要是探究低分辨率输入的性能,作者尝试将输入图片的尺寸缩放到三个尺寸,相应的为了网络能够正常接受也改动了网络开始的部分,比如尺寸小的就舍弃pooling,具体操作:
- 229x229的输入使用stride=2的maxpooling
- 151x151的输入使用stride=1的maxpooling
- 79x79的输入不使用maxpooling
这三个网络参数基本一致,结果如下: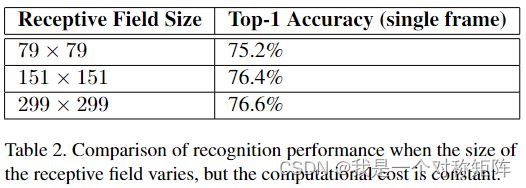
可以看出结果接近,但是低分辨率训练时间更长。如果看到低分辨率觉得简单尝试减少网络尺寸,那么效果会剧烈下降。
9、实验结果
9.1 改动带来的效果
表3显示了识别性能的实验结果。
每一行都是在前一行的基础上新加的功能,所以效果也是越来越好。
Factorized 7 × 7包括一个将第一个7 × 7卷积层分解成3 × 3卷积层序列的变化。
BN-auxiliary是指辅助分类器的全连通层也是批量归一化的版本,而不仅仅是卷积。
Inception-v3就是最后一行,也就是inception-v2的结构加上各种trick就是所谓的inception-v3

9.2(单模型)与其他模型的比较

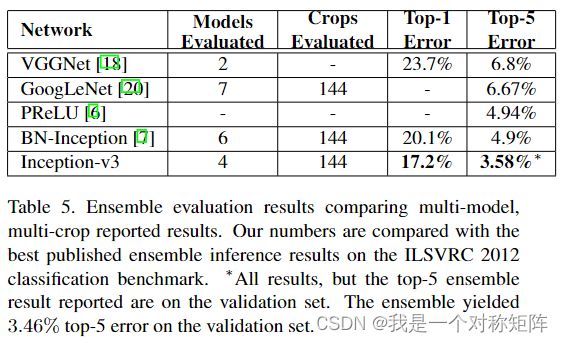
9.3(Ensemble模型)与其他模型的比较
10、总结
效果好,计算量小,还提供一堆优化原则。