论文阅读《M3VSNet: Unsupervised Multi-metric Multi-view Stereo Network》
论文地址:M3VSNet: Unsupervised Multi-metric Multi-view Stereo Network
一 、摘要
有监督学习训练过程的ground true数据很难获得,为此提出基于自监督学习的多尺度MVSNet;为了增强模型的鲁棒性,提出了基于像素层级和特征层级的损失函数;同时在点云中增加了法向量一致性约束来提升模型的性能;
- 提出一个多尺度无监督网络,该网络能脱离数据标签的限制;
- 提出多尺度损失函数,不仅只考虑像素级别的匹配,此外,在预测三维点云中加入了法向深度一致性,以提高估计深度图的准确性和连续性。
二、网络结构

网络结构主要包含三个部分:多尺度特征聚合、基于方差的匹配代价计算、3D U-Net正则化;在生成初始深度图后,引入新的法向深度一致性,考虑到法向与局部表面切线的正交性,对其进行细化。更重要的是,我们构建了多度量损失,包括像素损失和特征损失。
2.1 金字塔特征聚合
传统的MVSNet的特征图为原图尺寸的 1 4 \frac{1}{4} 41,这种操作会造成纹理信息丢失;为此,使用特征金字塔来融合不同尺度的特征,使特征包含浅层纹理信息与深层语义信息;

2.2 匹配代价体构建与3D U-Net正则化
参考MVSNet,将源视图的特征warp到参考视图,基于方差构建匹配代价体;然后基于3D U-Net构建匹配代价体,最后基于期望的形式计算初始深度图;
三、 Normal-depth Consistency
初始深度图中还存在一些误匹配的点,为此引入了基于法向与局部表面切线正交性的法向深度一致性来进一步提升深度图的质量;可分为两个步骤。首先,利用正交性与深度信息计算法线。然后根据投影关系,由法向深度和初始深度推断出细化深度。该模块配合3D U-Net,在二维和三维空间共同细化深度,提高深度的准确性和连续性。

如图所示,对于初始深度图中的每一个像素 p i p_{i} pi,取其8邻域像素来计算法向量;其邻域像素可以表示为 p i x p_{ix} pix、 p i y p_{iy} piy,如果预测的深度 Z i Z_{i} Zi与内参矩阵 K K K 已知,则归一化法向量可以使用以下的方式求得:
将点 p i p_{i} pi反投影到相机坐标系得到三维坐标:
P i = K − 1 Z i p i (1) P_{i}=K^{-1}Z_{i}p_{i}\tag{1} Pi=K−1Zipi(1)
将中心点与邻域点求叉积,得到法向量:
N i ~ = P i P i x → × P i P i y → (2) \widetilde{N_{i}}=\overrightarrow{P_{i} P_{i x}} \times \overrightarrow{P_{i} P_{i y}}\tag{2} Ni =PiPix×PiPiy(2)
将所有的法向量求平均,得到一个平均值作为这个邻域的法向量:
N i = 1 8 ∑ i = 1 8 ( N i ~ ) (3) N_{i}=\frac{1}{8} \sum_{i=1}^{8}\left(\widetilde{N_{i}}\right)\tag{3} Ni=81i=1∑8(Ni )(3)
过程如图所示:
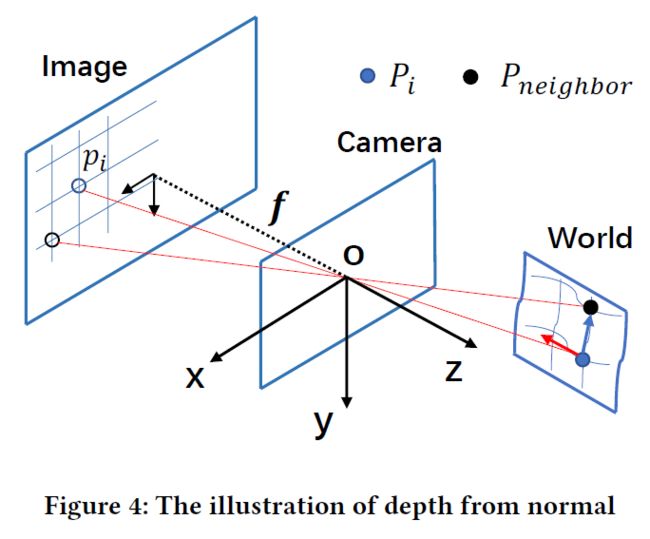
对于中心点反投影到相机坐标系下的三维点 P i P_{i} Pi ,其法向量表示为 N ⃗ i ( n x , n y , n z ) \vec{N}_{i}\left(n_{x}, n_{y}, n_{z}\right) Ni(nx,ny,nz) , P i P_{i} Pi 的深度为 Z i Z_{i} Zi ,对于其邻域点 P n e i g h b o r P_{neighbor} Pneighbor 的深度值为 Z n e i g h b o r Z_{neighbor} Zneighbor,由几何关系可得: N ⃗ ⊥ P i P neighbor → \vec{N} \perp \overrightarrow{P_{i} P_{\text {neighbor }}} N⊥PiPneighbor ,反之,由中心点的法向量、深度和相机内参的信息可以推断邻域点的深度 Z n e i g h b o r Z_{neighbor} Zneighbor:
( K − 1 Z i ⋅ p i − K − 1 Z n e i g h b o r ⋅ p n e i g h b o r ) [ n x n y n z ] = 0 (4) \left(K^{-1} Z_{i }\cdot p_{i}-K^{-1} Z_{n e i g h b o r }\cdot p_{n e i g h b o r}\right)\left[\begin{array}{l} n_{x} \\ n_{y} \\ n_{z} \end{array}\right]=0\tag{4} (K−1Zi⋅pi−K−1Zneighbor⋅pneighbor)⎣⎡nxnynz⎦⎤=0(4)
对于深度聚合,考虑到某些边缘区域或不规则曲面的法向量不连续性,使用参考视图的梯度图来对邻域像素点的深度进行加权,权重定义如下:
w i = e − α 1 ∣ ∇ I i ∣ (5) w_{i}=e^{-\alpha_{1}\left|\nabla I_{i}\right|}\tag{5} wi=e−α1∣∇Ii∣(5)
w i w_{i} wi的数值决定于 p i p_{i} pi与 p n e i g h b o r p_{neighbor} pneighbor两点之间的梯度,梯度越大,权重越小,最后的聚合深度值由邻域像素的深度值加权聚合而来:
Z ~ n e i g h b o r = ∑ i = 1 8 w i ′ Z n e i g h b o r (6) \widetilde{Z}_{n e i g h b o r}=\sum_{i=1}^{8} w_{i}^{\prime} Z_{n e i g h b o r}\tag{6} Z neighbor=i=1∑8wi′Zneighbor(6)
w i ′ = = w i ∑ i = 1 8 w i (7) w_{i}^{\prime}==\frac{w_{i}}{\sum_{i=1}^{8} w_{i}}\tag{7} wi′==∑i=18wiwi(7)
四、损失函数
为了得到更好的模型,文中提出了一个多尺度损失函数,该损失函数同时考虑了特征级别的匹配与像素级别的匹配;像素级别的匹配考虑了对应图像中的纹理信息而特征级的匹配考虑了图像的语义信息;
对于参考图像 I r e f I_{ref} Iref 与源图像 I s r c I_{src} Isrc ,参考视图到源视图的投影矩阵为 T T T ,从参考视图点 p ( x i , y i ) p(x_{i}, y_{i}) p(xi,yi) ,其在源视图中的对应像素 p ′ ( x i ′ , y i ′ ) p^{\prime}(x_{i}^{\prime}, y_{i}^{\prime}) p′(xi′,yi′)计算方式如下:
p i ′ = K T ( K − 1 Z ~ i p i ) (8) p_{i}^{\prime}=K T\left(K^{-1} \widetilde{Z}_{i} p_{i}\right)\tag{8} pi′=KT(K−1Z ipi)(8)
不妨记公共区域为 I s r c ′ I_{src}^{\prime} Isrc′ ,从参考图像到源视图可以用双线性插值采样得:
I s r c ′ = I s r c ( p i ′ ) (9) I_{src}^{\prime} =I_{src}(p_{i}^{\prime})\tag{9} Isrc′=Isrc(pi′)(9)
遮挡区域像素在 I s r c ′ I_{src}^{\prime} Isrc′ 的值为0,用掩码 M M M 来筛选出两个视图之间的共视点,同时考虑像素与特征级别的损失函数如式10所示:
L = ∑ ( γ 1 L pixel + γ 2 L feature ) (10) L=\sum\left(\gamma_{1} L_{\text {pixel }}+\gamma_{2} L_{\text {feature }}\right)\tag{10} L=∑(γ1Lpixel +γ2Lfeature )(10)
4.1 像素级损失
光度一致性损失:
L photo = 1 m ∑ ( ( I r e f − I s r c ′ ) + ( ∇ I r e f − ∇ I s r c ′ ) ) ⋅ M (11) L_{\text {photo }}=\frac{1}{m} \sum\left(\left(I_{r e f}-I_{s r c}^{\prime}\right)+\left(\nabla I_{r e f}-\nabla I_{s r c}^{\prime}\right)\right) \cdot M\tag{11} Lphoto =m1∑((Iref−Isrc′)+(∇Iref−∇Isrc′))⋅M(11)
结构一致性损失:
L S S I M = 1 m ∑ 1 − S ( I r e f , I s r c ′ ) 2 ⋅ M (12) L_{S S I M}=\frac{1}{m} \sum \frac{1-S\left(I_{r e f}, I_{s r c}^{\prime}\right)}{2} \cdot M\tag{12} LSSIM=m1∑21−S(Iref,Isrc′)⋅M(12)
平滑损失:
L smooth = 1 n ∑ ( e − α 2 ∣ ∇ I ref ∣ ∣ ∇ Z ~ i ∣ + e − α 3 ∣ ∇ 2 I ref ∣ ∣ ∇ 2 Z ~ i ∣ ) (13) L_{\text {smooth }}=\frac{1}{n} \sum\left(e^{-\alpha_{2}\left|\nabla I_{\text {ref }}\right|}\left|\nabla \widetilde{Z}_{i}\right|+e^{-\alpha_{3}\left|\nabla^{2} I_{\text {ref }}\right|}\left|\nabla^{2} \widetilde{Z}_{i}\right|\right)\tag{13} Lsmooth =n1∑(e−α2∣∇Iref ∣∣∣∣∇Z i∣∣∣+e−α3∣∇2Iref ∣∣∣∣∇2Z i∣∣∣)(13)
其中 n n n 为有效像素的数量,即像素级别的损失函数如式14所示:
L pixel = λ 1 L photo + λ 2 L SSIM + λ 3 L smooth (14) L_{\text {pixel }}=\lambda_{1} L_{\text {photo }}+\lambda_{2} L_{\text {SSIM }}+\lambda_{3} L_{\text {smooth }}\tag{14} Lpixel =λ1Lphoto +λ2LSSIM +λ3Lsmooth (14)
4.1 特征级损失
像素级的匹配在无纹理或者重复纹理区域往往得不到理想的效果,为此提出特征级的损失函数,充分考虑了图像中的语义信息;为此,使用一个预训练好的VGG16模型来获取不同层的特征;
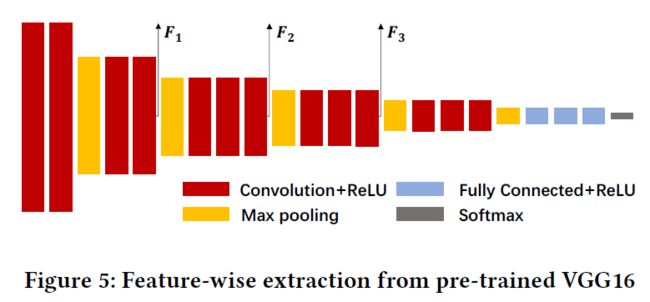
与像素级别损失类似,只是将像素的RGB值换为提取得到的深度特征向量:
F s r c ′ = F s r c ( p i ′ ) (15) F_{s r c}^{\prime}=F_{s r c}\left(p_{i}^{\prime}\right)\tag{15} Fsrc′=Fsrc(pi′)(15)
在特征领域,深度特征拥有更大的感受野,因此在一些不理想区域的不匹配问题也会进一步得到缓解,损失如式16所示:
L F = 1 m ∑ ( F r e f − F s r c ′ ) ⋅ M (16) L_{F}=\frac{1}{m} \sum\left(F_{r e f}-F_{s r c}^{\prime}\right) \cdot M\tag{16} LF=m1∑(Fref−Fsrc′)⋅M(16)
考虑了不同尺度的特征,最后特征级的损失函数如式17所示:
L feature = β 1 L F 8 + β 2 L F 15 + β 3 L F 22 (17) L_{\text {feature }}=\beta_{1} L_{F_{8}}+\beta_{2} L_{F_{15}}+\beta_{3} L_{F_{22}}\tag{17} Lfeature =β1LF8+β2LF15+β3LF22(17)