2020.10.20读 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
- 1. 背景信息
- 2.方法
-
-
- 2.1 回顾PointNet
- 2.2 层级点集特征学习
- 2.3 在非均匀点采样密度下的鲁棒特征学习
- 2.4 点云分割中的点特征传播
-
- 3. 读后感
1. 背景信息
- 输入数据:原始点云
- PointNet++ 是PointNet的改进版本, PointNet中实现点云排序不变性是通过提取global feature完成的,显然,这对于局部信息没有好的提取能力。 PointNet++通过利用PointNet层级嵌套,实现了提取local feature的能力。
3. 亮点:
(1)利用递归PointNet构建层级结构,在度量空间内实现了对点云细粒度pattern的识别,提高了网络对复杂场景的可概括性。
(2)受限于传感器能力,实际获取的点云都是采样密度不均匀的,本文作者提出了两种新颖的方法处理这个问题,使得网络能够自适应地学习局部区域应该capture的scale(适应不同的采样密度)。这两种新颖方法是Multi-scale grouping(MSG)和Multi-resolution grouping(MRG).
2.方法

获取的点云不同区域稀疏性有差别。

2.1 回顾PointNet
![]()

2.2 层级点集特征学习
- 层级结构由多个集合抽象层(set abstraction levels)构建, 每一个抽象层都处理一个点集,抽象特征,然后产生一个具有更少元素的新的集合。
- 一个set abstraction level处理一个 N ∗ ( d + C ) N*(d+C) N∗(d+C)的矩阵,其中N是点的数量,d是指d维坐标,C是指C维点特征。输出一个 N ′ ∗ ( d + C ′ ) N'*(d+C') N′∗(d+C′)的矩阵,其中 N ′ N' N′是下采样之后的点数,d是指d维坐标, C ′ C' C′是指 C ′ C' C′维点特征.
- 每一个set abstraction level都由三个关键层组成:(1)Sampling layer, (2) Grouping layer, (3) PointNet layer
(1)Sampling layer
给定输入点集:
利用迭代FPS选择一个子点集:
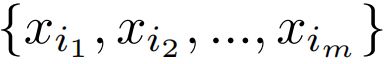
具体的,FPS逻辑如下:
一开始,找个seed点(一般是质心)放在已经选中的点集中,确定要选的点数K,然后每一轮,都执行如下三步选择出一个点,直到已经选中的点集中数量=K
1)对于任意一个剩余点,计算该点到已经选中的点集中所有点的距离
2)取最小值,作为该点到已经选中点集的距离
3)计算出每个剩余点到当前已经选中的点集的距离后,取距离最大的那个点。
(2) grouping layer
输入到该层的是一个 N ∗ ( d + C ) N*(d+C) N∗(d+C)的点集和一个 N ′ ∗ d N'*d N′∗d的质心集,该层输出一个 N ′ ∗ K ∗ ( d + C ) N'*K*(d+C) N′∗K∗(d+C)的点集,其中K是质心点的邻居个数,K是随着group自适应变化的,但是作者也说了,不用担心,在下一层pointNet中这些变化的K都会被转换为一个固定长度的local region feature vector.
grouping layer有两种查询方式:一种是半径球查询(r固定),上限点数是K,作者建议采用这种方法,因为这更能趋向于局部特征,更具有通用性。另一种是KNN查询。
实际上,为了保证半径球查询能够自适应点云采样密度,在下一小节中,会展开作者提供的两种策略:MSG和MRG
(3)PointNet layer
输入到该层的是 N ′ ∗ K ∗ ( d + C ) N'*K*(d+C) N′∗K∗(d+C)的矩阵,代表 N ′ N' N′个local点区域。输出数据是 N ′ ∗ ( d + C ′ ) N'*(d+C') N′∗(d+C′)矩阵,其中 C ′ C' C′代表PointNet提取出来的 C ′ C' C′维点特征。
Note: 在作用PointNet layer之前对每个local区域中的点都做了相对坐标变换:每个group中的点都相对质心做变换,转换为相对质心的相对坐标,这样可以获得局部点之间的关系,更有利于学习。
![]()
其中i表示K个local region中的第i个,j表示d维坐标中的第j维,x(j)_hat表示质心点。
2.3 在非均匀点采样密度下的鲁棒特征学习

当输入采样密度变化时,网络会学习从不同尺度的local region中自适应地结合特征。每一个abstraction level 提取多个scale的local patterns并且根据局部点密度智能地结合他们。
有两种类型地自适应不同尺度的特征结合方法:MSG和MRG
1. Multi-scale grouping (MSG)
思路很朴素,就是取不同稀疏度生成不同scale的region,计算他们的特征然后把他们的特征concat起来。
具体地,作者采用对输入点云进行不同dropout ratio的随机dropout来实现,dropout ratio在[0,p]之间,为了不对dropout太过分产生没有意义的空点集,p被设置为0.95. 作者解释dropout ratio可以实现点云具有变化的稀疏性,随机dropout实现了点云稀疏性变化的均匀性。
Note:这里我一开始根据Figure 3(a)理解成了,取不同球半径生成不同scale的region,根据作者的dropout描述,这样理解是不对的。
2. Multi-resolution grouping (MRG)
上面的MSG方法的计算量很大。作者提出MRG作为替代方法,在后面的实验结果中,发现MSG比MRG效果要好一些,但是时间成本很高。
在Figure 3(b)中,在第i个层级 L i L_{i} Li中的region feature是由两个vectors concatenate而来的, 左边的vector是通过一个set abstraction level从低一级的 L i − 1 L_{i-1} Li−1的子区域中提取出来的,右边的vector是利用single PointNet直接处理在local region中的所有原始点而得来的。
如果local region density很低,那么left权重应该被设置低一些,right权重应该被设置的高一些。
如果local region density很高,那么left权重应该被设置高一些,right权重应该被设置的低一些。
这些都是由网络来学习的,满足自适应性。
2.4 点云分割中的点特征传播
在语义分割中,要求输入点的数量与输出点的数量相等。而set abstraction level会实现点的数量降采样,为了解决这个问题,作者采用了基于距离的插值和skip link concation来解决这个问题。
如Figure 2右上角所示,前一层的 ( N 2 , d + C 2 ) (N_{2},d+C_{2}) (N2,d+C2)通过
1.插值,变成了 ( N 1 , d + C 2 ) (N_{1},d+C_{2}) (N1,d+C2)
2.skip link concatenation,变成了 ( N 1 , d + C 2 + C 1 ) (N_{1},d+C_{2}+C{1}) (N1,d+C2+C1)
3.unit pointnet(FC+ReLU), 进行简单的特征融合,变成了 ( N 1 , d + C 3 ) (N_{1},d+C_{3}) (N1,d+C3)
直到生成最后的 ( N , k ) (N,k) (N,k),其中k表示语义分割的标签。
插值过程:

插值公式:
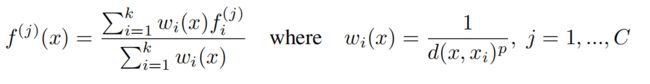
这里一般设置成p=2,k=3(三点插值法)
实验和结果部分略
3. 读后感
1. PointNet++ 通过层级结构具有了强大的对点云细节捕获的能力,根据作者描述,这是受CNN层级结构的启发。 一个好的idea从一个领域迁移到另一个领域,然后work的很好,就是普通意义的创新,而这需要博闻强识+灵活的思维。
2. 为了解决点云中稀疏性不同的问题,作者提出MSG和MRG来解决它。MSG的思想很朴素,用dropout对input的点云生成不同稀疏度的点云,分别提取特征进行特征向量串联。MRG的多分辨率,在我看来是比较粗糙的,作者只提取了 L i − 1 L_{i-1} Li−1层和raw点云的特征进行串联,可能是更多的考虑了速度的问题吧。
4. 不同的度量方法用在不同的数据上效果有差异,在刚性物体上,利用欧式距离度量效果就会很好,在非刚性物体(比如动物,一匹马)上,相应的利用测地距离度量效果会更好。如在3维人体姿态识别或者其他跟非刚性物体识别的任务中,应该考虑测地距离度量。