【推荐算法】从零开始做推荐(四)——python Keras框架 利用Embedding实现矩阵分解TopK推荐
前言
推荐系统的评价指标在不同类型的推荐场景下,选用的不同。有些推荐的评价指标并非完全出自推荐系统,而是从搜索算法,信息检索,机器学习等相关领域沿用过来,因此网上有些对评价指标的解释并非完全以推荐系统的角度进行,这让我会在学习的时候产生困惑,特此做出一些整理,力求完全用推荐系统的角度解释,并给出计算的具体流程。
目录
- 前言
- 矩阵分解与Embedding的关系
- Keras框架介绍
- 核心算法
- 有效性验证
- 训练
- 测试
- Main函数
- 实验结果
- 进阶!灵魂拷问
- 完整代码
如果你对本系列(未写完,持续更新中)感兴趣,可接以下传送门:
本系列的数据集:【推荐算法】从零开始做推荐(一)——认识数据
本系列的评价指标:【推荐算法】从零开始做推荐(二)——推荐系统的评价指标,计算原理与实现样例
【推荐算法】从零开始做推荐(三)——传统矩阵分解的TopK推荐实战
【推荐算法】从零开始做推荐(四)——python Keras框架 利用Embedding实现矩阵分解TopK推荐
【推荐算法】从零开始做推荐(五)——贝叶斯个性化排序矩阵分解 (BPRMF) 推荐实战
【推荐算法】从零开始做推荐(六)——贝叶斯性化排序矩阵分解 (BPRMF) 的Tensorflow版
矩阵分解与Embedding的关系
自词向量(Word2Vec)推出以来,各种嵌入(Embedding)方法层出不穷,推荐系统也有部分文章借用Embedding思想进行推荐,Embedding是一种思想,可以理解为提特征的手段,万物皆可Embedding,下面我们来引入这种思想到推荐算法里。
在NLP领域里,我们将词转化为K维度的词向量,再用词向量去做更为复杂的NLP任务,如简单的寻找相关词里,就可以直接用词向量进行相似度计算直观得到。而在推荐系统的场景里,我们有用户和项目两个主体,假如能将用户和项目嵌入到同一空间中,再计算相似性,不就直接完成了推荐目的了吗?
在矩阵分解中,我们同样也是将User和Item分开,User的每一行,代表用户的嵌入向量,Item的每一列代表项目的嵌入向量,两者都在K维空间中,而矩阵乘法的本质就是向量的点积,即User的每一行点乘Item的每一列,而点积a·b = |a||b|cosθ,不就是在计算相似度吗?
到现在你就会发现,原来矩阵分解就是Embedding的一种,二者殊途同归。那么利用神经网络的框架来实现矩阵分解也就带来了可能,整体框架如下图所示。
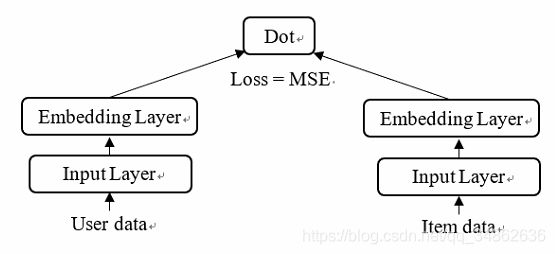
Keras框架介绍
Keras是一种搭建神经网络的框架,它封装得很好,简便易用,对于新手来讲还是十分友好的。它主要包括两种模型,其一为序列式模型,即一步步往后走,一条路走到黑;另一种为函数式模型,适合多输入;我们的输入包括User和Item,因此,使用的是函数式模型。
核心算法
本文最初的实现参照了这篇文章,但文中方法有人提出未加正则,且分解出来是负数。针对这两个问题,进行改进从而得到如下代码:
def Recmand_model(num_user,num_item,d):
K.clear_session()
input_uer = Input(shape=[None,],dtype="int32")
model_uer = Embedding(num_user,d,input_length = 1,
embeddings_constraint=non_neg() #非负,下同
)(input_uer)
Dropout(0.2)
model_uer = BatchNormalization()(model_uer)
model_uer = Reshape((d,))(model_uer)
input_item = Input(shape=[None,],dtype="int32")
model_item = Embedding(num_item,d,input_length = 1,
embeddings_constraint=non_neg()
)(input_item)
Dropout(0.2)
model_item = BatchNormalization()(model_item)
model_item = Reshape((d,))(model_item)
out = Dot(1)([model_uer,model_item]) #点积运算
model = Model(inputs=[input_uer,input_item], outputs=out)
model.compile(loss= 'mse', optimizer='sgd')
model.summary()
return model
关于非负,指的是分解后的两个矩阵每个值都要非负,实现起来比较简单,Embedding层刚好有进行约束的参数,但思想上还存在一定模糊,电影评分是处于[1-5]的,预测评分为什么一定要非负?负数是否可以代表该用户不喜欢该项目?由于推荐结果实际上只与分值的大小排序有关,非负还是否一定更好?
除此以外,还尝试了神经网络的一些trick,加了dropout防止过拟合,加了BatchNormalization更易靠近最优解。下面是Keras的结构图,一目了然。
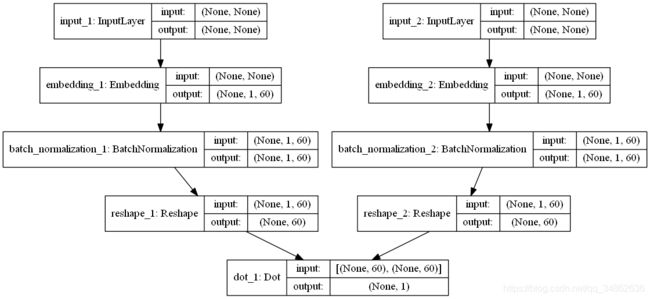
有效性验证
同样我们先看核心算法是不是真的能完成矩阵分解,结果如下,非零值与原矩阵接近,完成验证。下附验证代码。

'''
Created on Fri Oct 18 15:08:00 2019
@author: YLC
'''
import os
import numpy as np
import pandas as pd
import time
import math
from keras import Model
import keras.backend as K
from keras.layers import Embedding,Reshape,Input,Dot,Dense,Dropout,concatenate
from keras.models import load_model
from keras.utils import to_categorical
from keras import regularizers
from keras.constraints import non_neg
def Recmand_model(num_user,num_item,d):
K.clear_session()
input_uer = Input(shape=[None,],dtype="int32")
model_uer = Embedding(num_user,d,input_length = 1,
embeddings_constraint=non_neg() #非负,下同
)(input_uer)
Dropout(0.2)
model_uer = BatchNormalization()(model_uer)
model_uer = Reshape((d,))(model_uer)
input_item = Input(shape=[None,],dtype="int32")
model_item = Embedding(num_item,d,input_length = 1,
embeddings_constraint=non_neg()
)(input_item)
Dropout(0.2)
model_item = BatchNormalization()(model_item)
model_item = Reshape((d,))(model_item)
out = Dot(1)([model_uer,model_item]) #点积运算
model = Model(inputs=[input_uer,input_item], outputs=out)
model.compile(loss= 'mse', optimizer='sgd')
model.summary()
return model
def train(num_user,num_item,train_data,d,step):
model = Recmand_model(num_user,num_item,d)
train_user = train_data[:,0]
train_item = train_data[:,1]
train_x = [train_user,train_item]
train_y = train_data[:,2]
model.fit(train_x,train_y,batch_size = 4,epochs = step)
model.save("./MFmodel.h5")
def test(num_user,num_item,R):
model = load_model('./MFmodel.h5')
nR = np.zeros([num_user,num_item])
for i in range(num_user):
for j in range(num_item):
nR[i][j] = model.predict([[i],[j]])
return nR
def cal_e(R,nR):
e = 0
cnt = 0
for i in range(len(R)):
for j in range(len(R[0])):
if(R[i][j]!=0):
cnt = cnt + 1
e = e + math.pow(R[i][j]-nR[i][j],2)
e = 1.0 * e/cnt
return e
def RtransT(R):
user = [u for u in range(len(R))]
item = [i for i in range(len(R[0]))]
Table = []
for i in user:
for j in item:
if R[i][j]!= 0:
Table.append([i,j,R[i][j]])
Table = np.array(Table)
return Table
def NMF(R,d,step):
T = RtransT(R)
M=len(R)
N=len(R[0])
train(M,N,T,d,step)
nR = test(M,N,R)
e = cal_e(R,nR)
return e,nR
if __name__ == '__main__':
R=[
[5,2,0,3,1],
[0,2,1,4,5],
[1,1,0,2,4],
[2,2,0,5,0]
]
R=np.array(R)
dimension = 3
step = 2000
e,nR = NMF(R,dimension,step)
print('-----原矩阵R:------')
print(R)
print('-----近似矩阵nR:------')
print(nR)
print('e is:',e)
训练
模型的构建有三个参数,用户数、项目数和嵌入向量的维度,而模型的输入为训练集的用户记录数据、项目记录数据和真实评分。batch_size是批处理参数,epochs是模型的迭代次数,h5为HDF5文件格式。
def train(all_user,all_item,train_data,d):
num_user = max(all_user) + 1
num_item = max(all_item) + 1
model = Recmand_model(num_user,num_item,d)
train_user = train_data['user'].values
train_item = train_data['item'].values
train_x = [train_user,train_item]
# train_data['rating'] = 1 #不用评分
train_y = train_data['rating'].values
model.fit(train_x,train_y,batch_size = 128,epochs = 8)
plot_model(model, to_file='./NN MF/NNMF.png',show_shapes=True) #输出框架图
model.save("./NN MF/MFmodel.h5")
测试
同(三)一样,加入推荐新项目的限制。
def test(train_data,test_data,all_item,k):
model = load_model('./NN MF/MFmodel.h5')
PRE = 0
REC = 0
MAP = 0
MRR = 0
AP = 0
HITS = 0
sum_R = 0
sum_T = 0
valid_cnt = 0
stime = time.time()
test_user = np.unique(test_data['user'])
for user in test_user:
# user = 0
visited_item = list(train_data[train_data['user']==user]['item'])
# print('访问过的item:',visited_item)
if len(visited_item)==0: #没有训练数据,跳过
continue
per_st = time.time()
testlist = list(test_data[test_data['user']==user]['item'].drop_duplicates()) #去重保留第一个
testlist = list(set(testlist)-set(testlist).intersection(set(visited_item))) #去掉访问过的item
if len(testlist)==0: #过滤后为空,跳过
continue
valid_cnt = valid_cnt + 1 #有效测试数
poss = {}
for item in all_item:
if item in visited_item:
continue
else:
poss[item] = float(model.predict([[user],[item]]))
# print(poss)
# print("对用户",user)
rankedlist,test_score = topk(poss,k)
# print("Topk推荐:",rankedlist)
# print("实际访问:",testlist)
# print("单条推荐耗时:",time.time() - per_st)
AP_i,len_R,len_T,MRR_i,HITS_i= cal_indicators(rankedlist, testlist)
AP += AP_i
sum_R += len_R
sum_T += len_T
MRR += MRR_i
HITS += HITS_i
# print(test_score)
# print('--------')
# break
etime = time.time()
PRE = HITS/(sum_R*1.0)
REC = HITS/(sum_T*1.0)
MAP = AP/(valid_cnt*1.0)
MRR = MRR/(valid_cnt*1.0)
p_time = (etime-stime)/valid_cnt
print('评价指标如下:')
print('PRE@',k,':',PRE)
print('REC@',k,':',REC)
print('MAP@',k,':',MAP)
print('MRR@',k,':',MRR)
print('平均每条推荐耗时:',p_time)
with open('./Basic MF/result_'+dsname+'.txt','w') as f:
f.write('评价指标如下:\n')
f.write('PRE@'+str(k)+':'+str(PRE)+'\n')
f.write('REC@'+str(k)+':'+str(REC)+'\n')
f.write('MAP@'+str(k)+':'+str(MAP)+'\n')
f.write('MRR@'+str(k)+':'+str(MRR)+'\n')
f.write('平均每条推荐耗时@:'+str(k)+':'+str(p_time)+'\n')
Main函数
与(三)不同,这里取 d = 60 d=60 d=60。
if __name__ == '__main__':
dsname = 'ML100K'
dformat = ['user','item','rating','time']
all_user,all_item,train_data,test_data = getUI(dsname,dformat) #第一次使用需取消注释
d = 60 #隐因子维度
steps = 10
k = 10
train(all_user,all_item,train_data,d)
test(train_data,test_data,all_item,k)
实验结果
先看ML100K的结果。
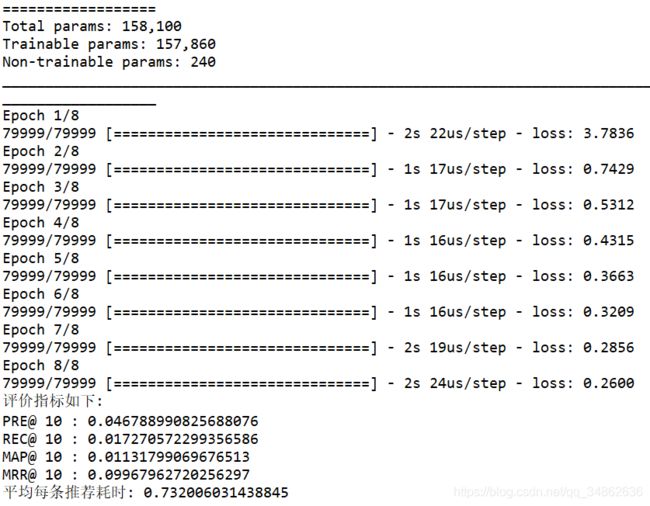
再看ML1M的结果。
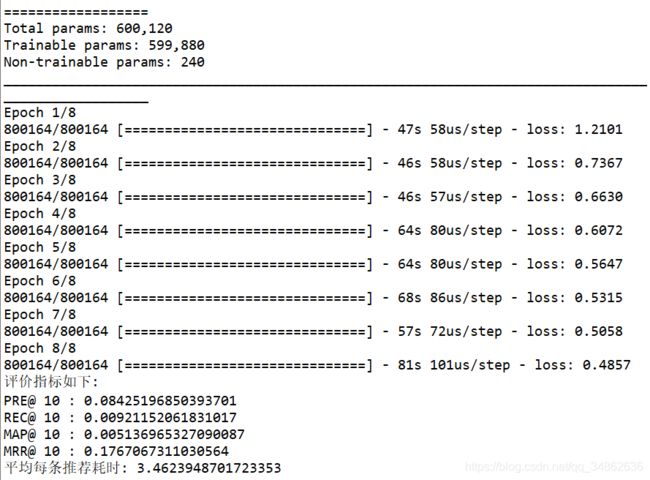
进阶!灵魂拷问
拷问1. 利用神经网络做矩阵分解(下称NNMF(Neural Network Matrix Factorization))与传统矩阵分解相比,哪种更好?
从实验结果上来看,Basic MF会更好。以下为传统矩阵分解的实验结果。但从个人观点,NNMF的潜力更大。相比于传统矩阵分解的过程,利用神经网络做矩阵分解有以下好处:
1).NNMF训练的时耗远低于Basic MF。因为NNMF是直接嵌入,不需要构建矩阵,且神经网络的优化器什么的都是现成的。
2).NNMF吃神经网络的红利。理论上任何有利于神经网络的技术都可以用过来,比如本文用到的Dropout、BN等。
那为什么效果会差呢?个人认为一方面是参数没有调到最优,另一方面是数据量不够,众所周知,神经网络是数据驱动的。不过在本次试验中,两者的差距并非很大。

拷问2. 评分矩阵和0-1矩阵在此实验中效果如何?
以下为0-1矩阵的。明显基本没有效果,不过如果数据量够大的话还是有机会。

完整代码
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 18 15:08:00 2019
@author: YLC
"""
import os
import numpy as np
import pandas as pd
import time
import math
from keras import Model
import keras.backend as K
from keras.layers import Embedding,Reshape,Input,Dot,Dense,Dropout,concatenate,BatchNormalization
from keras.models import load_model
from keras.utils import plot_model,to_categorical
from keras import regularizers
from keras.constraints import non_neg
from keras import optimizers
def getUI(dsname,dformat): #获取全部用户和项目
st = time.time()
train = pd.read_csv(dsname+'_train.txt',header = None,names = dformat)
test = pd.read_csv(dsname+'_test.txt',header = None,names = dformat)
data = pd.concat([train,test])
all_user = np.unique(data['user'])
all_item = np.unique(data['item'])
train.sort_values(by=['user','item'],axis=0,inplace=True) #先按时间、再按用户排序
if os.path.exists('./NN MF'):
pass
else:
os.mkdir('./NN MF')
train.to_csv('./NN MF/train.txt',index = False,header=0)
test.to_csv('./NN MF/test.txt',index = False,header=0)
et = time.time()
print("get UI complete! cost time:",et-st)
return all_user,all_item,train,test
def topk(dic,k):
keys = []
values = []
for i in range(0,k):
key,value = max(dic.items(),key=lambda x: x[1])
keys.append(key)
values.append(value)
dic.pop(key)
return keys,values
def cal_indicators(rankedlist, testlist):
HITS_i = 0
sum_precs = 0
AP_i = 0
len_R = 0
len_T = 0
MRR_i = 0
ranked_score = []
for n in range(len(rankedlist)):
if rankedlist[n] in testlist:
HITS_i += 1
sum_precs += HITS_i / (n + 1.0)
if MRR_i == 0:
MRR_i = 1.0/(rankedlist.index(rankedlist[n])+1)
else:
ranked_score.append(0)
if HITS_i > 0:
AP_i = sum_precs/len(testlist)
len_R = len(rankedlist)
len_T = len(testlist)
return AP_i,len_R,len_T,MRR_i,HITS_i
def Recmand_model(num_user,num_item,d):
K.clear_session()
input_uer = Input(shape=[None,],dtype="int32")
model_uer = Embedding(num_user,d,input_length = 1,
embeddings_constraint=non_neg() #非负,下同
)(input_uer)
Dropout(0.2)
model_uer = BatchNormalization()(model_uer)
model_uer = Reshape((d,))(model_uer)
input_item = Input(shape=[None,],dtype="int32")
model_item = Embedding(num_item,d,input_length = 1,
embeddings_constraint=non_neg()
)(input_item)
Dropout(0.2)
model_item = BatchNormalization()(model_item)
model_item = Reshape((d,))(model_item)
out = Dot(1)([model_uer,model_item]) #点积运算
model = Model(inputs=[input_uer,input_item], outputs=out)
model.compile(loss= 'mse', optimizer='sgd')
model.summary()
return model
def train(all_user,all_item,train_data,d):
num_user = max(all_user) + 1
num_item = max(all_item) + 1
model = Recmand_model(num_user,num_item,d)
train_user = train_data['user'].values
train_item = train_data['item'].values
train_x = [train_user,train_item]
# train_data['rating'] = 1 #不用评分
train_y = train_data['rating'].values
model.fit(train_x,train_y,batch_size = 128,epochs = 8)
plot_model(model, to_file='./NN MF/NNMF.png',show_shapes=True) #输出框架图
model.save("./NN MF/MFmodel.h5")
def test(train_data,test_data,all_item,k):
model = load_model('./NN MF/MFmodel.h5')
PRE = 0
REC = 0
MAP = 0
MRR = 0
AP = 0
HITS = 0
sum_R = 0
sum_T = 0
valid_cnt = 0
stime = time.time()
test_user = np.unique(test_data['user'])
for user in test_user:
# user = 0
visited_item = list(train_data[train_data['user']==user]['item'])
# print('访问过的item:',visited_item)
if len(visited_item)==0: #没有训练数据,跳过
continue
per_st = time.time()
testlist = list(test_data[test_data['user']==user]['item'].drop_duplicates()) #去重保留第一个
testlist = list(set(testlist)-set(testlist).intersection(set(visited_item))) #去掉访问过的item
if len(testlist)==0: #过滤后为空,跳过
continue
valid_cnt = valid_cnt + 1 #有效测试数
poss = {}
for item in all_item:
if item in visited_item:
continue
else:
poss[item] = float(model.predict([[user],[item]]))
# print(poss)
# print("对用户",user)
rankedlist,test_score = topk(poss,k)
# print("Topk推荐:",rankedlist)
# print("实际访问:",testlist)
# print("单条推荐耗时:",time.time() - per_st)
AP_i,len_R,len_T,MRR_i,HITS_i= cal_indicators(rankedlist, testlist)
AP += AP_i
sum_R += len_R
sum_T += len_T
MRR += MRR_i
HITS += HITS_i
# print(test_score)
# print('--------')
# break
etime = time.time()
PRE = HITS/(sum_R*1.0)
REC = HITS/(sum_T*1.0)
MAP = AP/(valid_cnt*1.0)
MRR = MRR/(valid_cnt*1.0)
p_time = (etime-stime)/valid_cnt
print('评价指标如下:')
print('PRE@',k,':',PRE)
print('REC@',k,':',REC)
print('MAP@',k,':',MAP)
print('MRR@',k,':',MRR)
print('平均每条推荐耗时:',p_time)
with open('./Basic MF/result_'+dsname+'.txt','w') as f:
f.write('评价指标如下:\n')
f.write('PRE@'+str(k)+':'+str(PRE)+'\n')
f.write('REC@'+str(k)+':'+str(REC)+'\n')
f.write('MAP@'+str(k)+':'+str(MAP)+'\n')
f.write('MRR@'+str(k)+':'+str(MRR)+'\n')
f.write('平均每条推荐耗时@:'+str(k)+':'+str(p_time)+'\n')
if __name__ == '__main__':
dsname = 'ML100K'
dformat = ['user','item','rating','time']
all_user,all_item,train_data,test_data = getUI(dsname,dformat) #第一次使用需取消注释
d = 60 #隐因子维度
steps = 10
k = 10
train(all_user,all_item,train_data,d)
test(train_data,test_data,all_item,k)