YOLOv5、v7改进之三十五:引入NAMAttention注意力机制
前 言:作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!
解决问题:之前改进增加了很多注意力机制的方法,包括比较常规的SE、CBAM等,本文加入NAMAttention注意力机制,该注意力机制了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局调度机制,通过减少信息缩减和放大全局交互表示来提高深度神经网络的性能,提高检测效果。
基本原理:
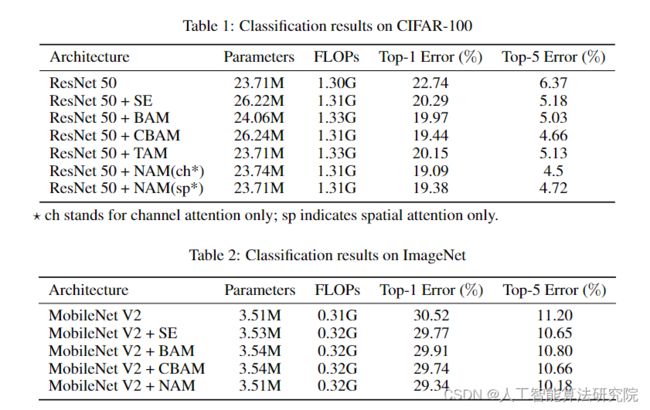
识别不太显著的特征是模型压缩的关键。然而,在革命性注意机制中,它还没有被研究过。在这项工作中,我们提出了一种新的基于归一化的注意模块(NAM),它可以抑制不太显著的权重。它对注意模块应用了权重稀疏性惩罚,从而使它们在保持相似性能的同时,计算效率更高。与Resnet和Mobilenet上的其他三种注意机制的比较表明,我们的方法具有更高的准确性。

将NAM与ResNet和MobileNet的SE、BAM、CBAM和TAM的性能进行比较。我们在一个集群上使用四个Nvidia Tesla V100 GPU评估每种方法。我们首先在CIFAR-100上运行ResNet50(Krizhevsky等人[2009]),并使用与CBAM相同的预处理和训练配置(Woo等人[2018]),p为0.0001。表1中的比较表明,仅使用通道或空间注意力的NAM优于其他四种注意机制。然后我们在ImageNet上运行MobileNet(Deng等人[2009]),因为它是图像分类基准的标准数据集之一。我们将p设置为0.001,其余配置与CBAM相同。表中的比较表明,结合信道和空间注意的NAM优于计算复杂度相似的其他三种NAM。
添加方法:
第一步:确定添加的位置,作为即插即用的注意力模块,可以添加到YOLOv5网络中的任何地方。
第二步:common.py构建GAMAttention模块。部分代码如下,关注文章末尾,私信后领取。
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
#x = torch.sigmoid(x) * residual #
return x
class NAMAttention(nn.Module):
def __init__(self, channels, out_channels=None, no_spatial=True):
super(NAMAttention, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out1 第三步:yolo.py中注册 NAMAttention模块
elif m is NAMAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]第四步:修改yaml文件,本文以修改backbone为例,将原C3模块后加入该模块。
# YOLOv5 backbone
backbone:
# [from, number, module, args] # [c=channels,module,kernlsize,strides]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, NAMAttention, [1024,1024]], #9
[-1, 1, SPPF, [1024,5]], #10
]第五步:将train.py中改为本文的yaml文件即可,开始训练。
结 果:本人在遥感数据集上进行实验,有涨点效果。需要请关注留言。
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。