Self-attention(李宏毅2022
模型的输出:
类型一:一对一(Sequence Labeling)。e.g. 词性标注;语音辨识简化版,标注phonon;社交网络图,判断节点会否购买商品。--->Self-attention
类型二:多对一。e.g. sentiment analysis,语者辨识,判断分子特性
类型三:由模型自己决定(seq2seq)。e.g. 翻译、语音识别
第四节 2021 - 自注意力机制(Self-attention)(上)_哔哩哔哩_bilibili
self attention想要解决的问题:
此前,我们network的input都是一个向量,输出可能是一个数值或者一个类别。但是假设我们需要输入的是一排向量,并且向量的个数可能会发生改变,这个时候要怎么处理。

例子:
比如文字处理的时候:

将单词表示为向量的方法:One-hot Encoding。我们可以用很长的一个向量,来表示世界上所有的东西,但是这里有一个问题,它假设所有的词汇都是没有关系的,比如猫和狗,都是动物,但是这样没有办法把它分类在一起,没有语义的资讯。
另一个方法是Word Embedding:我们给每个词汇一个向量,这个向量里有语义的信息。如果将Word Embedding画出来,就会发现同类的单词就会聚集。
网路上可以载到Word Embedding,会给每个词汇一个向量,一个句子就是一排长度不一的向量

取一段语音信号作为window,把其中的信息描述为一个向量(frame帧),滑动这个窗口就得到这段语音的所有向量
有各式各样的做法可以用一个向量来描述一小段25millisecond里面的语音讯号
每个window移动10ms,古圣贤都试过了,
Graph:
①社交网络的每个节点就是一个人,节点之间的关系用线连接。每一个人就是一个向量
②分子上的每个原子就是一个向量(每个元素可用One-hot编码表示),分子就是一堆向量


2. 模型的输出

类型一:一对一(又叫Sequence Labeling)
每个输入向量对应一个输出标签。
文字处理:词性标注。
语音处理:一段声音信号里面有一串向量,每个向量对应一个音标。(作业二,语音辨识简化版)
图像处理:在社交网络中,比如给一个图片,机器要决定每一个节点的特性,比如说这个人会不会买某一个商品。

类型二:多对一
多个输入向量对应一个输出标签。
sentiment analysis,语者辨识(作业四),给出分子的结构, 判断亲水性or毒性...

类型三:由模型自己决定(又叫seq2seq任务,作业五)
不知道应该输出多少个标签,机器自行决定。
翻译:语言A到语言B,单词字符数目不同
语音识别
Sequence Labeling
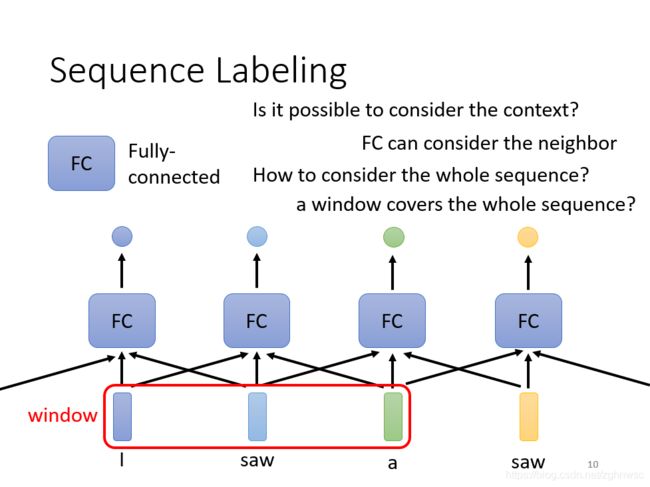
我们可以用fully conneted network(FC),各个击破,每个向量分别输入FC,
但是这样会有瑕疵,比如输入I saw a saw(锯子),这两个saw,对于FC(fully conneted network,全连接网络,下同)来说,是一模一样的,但是实际上它们一个是v.,一个是n。
让FC考虑上下文,把这几个向量前后串起来,一起丢到FC里面。(作业二)
但如果今天我们有某个任务,不是考虑一个window就可以解决的,而是要考虑整个sequence才能解决的话,怎么办。如果开一个大的Window,我们输入的sequence是有长有短,那FC就需要非常多的参数,不止是很难训练,而且很容易过拟合。
更好的方法来考虑整个input sequence的资讯,----> self-attention的技术。
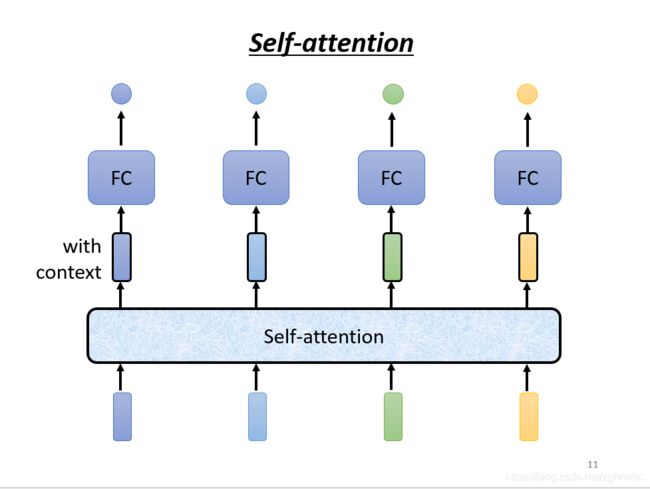
self-attention会把一整个sequence的资讯都吃进去,然后你输入几个向量,它就输出几个向量,这里用黑色的框框,表示它不是普通的向量,是考虑了一整个sequence的向量。
self-attention也可以和FC交替使用,用self-attention来处理整个sequence的资讯,FC来专注处理某一个位置的资讯。
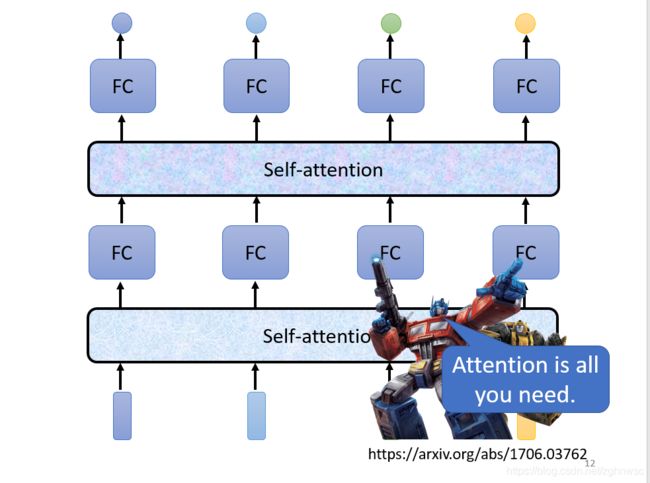
关于self-attention最知名的文章《Attention is all you need》,Google 根据自注意力机制 在 paper中提出了 Transformer 架构。
self-attention是怎么运作的呢?
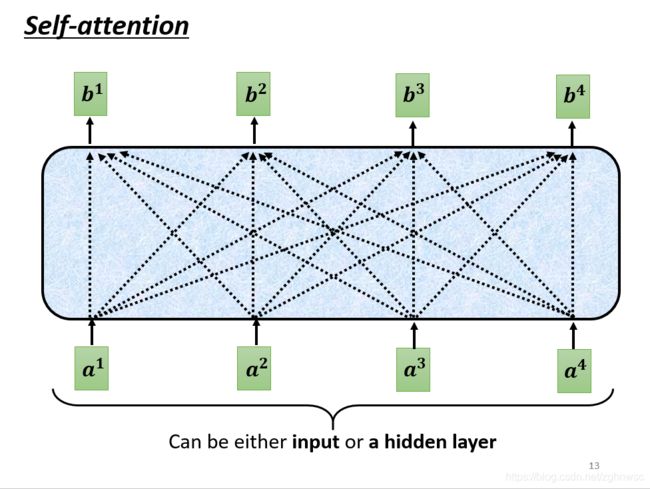
self-attention的input就是一串的向量,这个向量可能是整个网络的input,也可能是某个hidden layer的output,所以我们用a来表示它,代表前面它可能做过一些处理。
output一排b向量,这里的每一个b都是考虑了所有的a以后才生成出来的。
那么怎么产生b1这个向量呢?
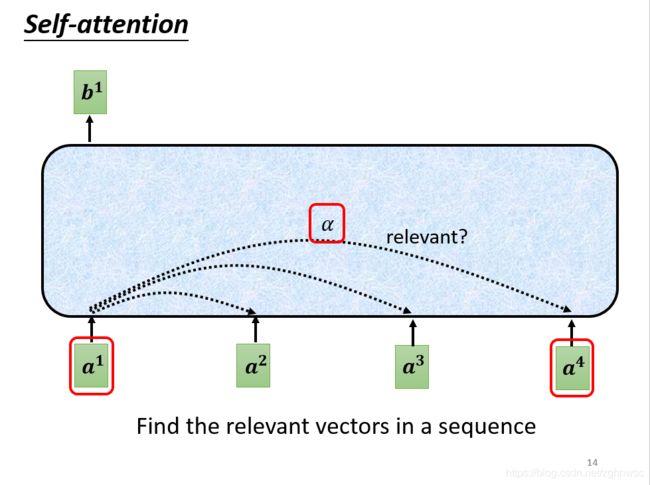
第一个步骤:根据a1找出这个sequence里面和a1相关的其他向量
我们要做self-attention目的就是为了要考虑整个sequence,但是又不希望把整个sequence所有的资讯包在一个window里面,所以我們有一個特別的機制:根據a1這個向量、找出整個Sequence裡面、到底哪些部分对于 決定a1的Class/数值时,是需要用到的資訊
每一个向量和a1关联的程度,我们用一个数值α来表示。
那么这个α是怎么产生的呢?计算attention的模组。

这个模组,就是拿两个向量a1和a4作为输入,然后输出的是一个α。
怎么计算这个数值,有各种不同的做法,比较常见的有dot-product。(用在Transformer里的方法,当今最常用的,)
把输入的两个向量,分别乘上两个不同的矩阵,得到q和k向量。再把他们做element-wise的相乘(就是对应数值相乘),再全部加起来,得到一个scalar,就是α。
这是一种计算的方式,还有其他的方式,比如additive,就是把他们分别乘以一个矩阵,再加起来,再经过一个激活函数,最后经过一个transfor,最后得到一个α。
那么怎么把它套用在self-attention里面呢?
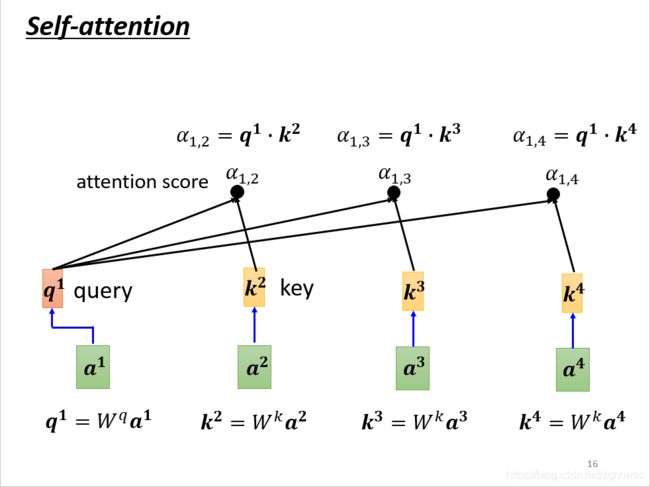
这里就是把a1和a2、a3、a4分别去计算他们之间的关联性。
就是把a1乘上Wq得到q1,叫做query。(搜索引擎的搜索关键字)
a2、a3、a4都乘以一个Wk得到一个k2,叫做key。
再把q1和k2算inner-product得到α。α1,2就表示,query是1提供的,key是2提供的,就表示1和2之间的关联性。也叫attention score。
接下来就以此类推,
(实际操作中,a1也会计算和自己的关联性,就是算出来一个α1,1)
(自己和自己算关联性的话,是不是相当于加一个额外的约束,优化训练)

算完关联性之后,会做一个soft-max。跟前面的分类的soft-max是一模一样的。
(softmax就是把多个数值标准化到0~1之间,分类问题里面是根据这个可能更好的看出最后是分到哪一类里面,相当于增强最大可能的项)
(也可以用别的,不一定非要用soft-max)
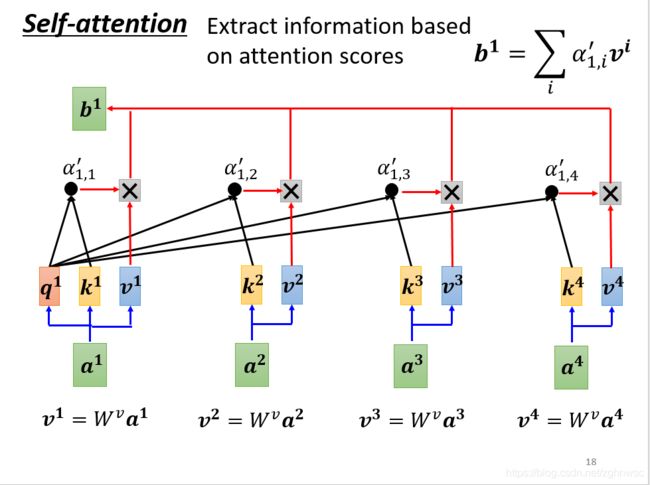
接下来我们要根据这个关联性![]() ,来抽取sequence里重要的资讯。
,来抽取sequence里重要的资讯。
我们会把a1~a4这里面每一个向量,乘上Wv得到一个新的向量,用v1、v2、v3、v4表示。
接下来,把v1~v4每一个都乘上α’,然后加起来得到b。可以想见如果某一个关联性很强,![]() 值很大,那么weighted sum之后,b1的值就可能会更加接近v2
值很大,那么weighted sum之后,b1的值就可能会更加接近v2
谁的attention分数最大,谁的v就会dominant你抽出来的结果
总结:所以这里我们就讲了,怎么从一整个sequence得到一个b1.
注意,b1到b4并不需要依序产生,他们是一次同时被计算出来的。

注意力系数计算1:
- 阶段1:根据Query和Key计算两者的相似性或者相关性
- 阶段2:对第一阶段的原始分值进 行归一化处理
- 阶段3:根据权重系数对Value进行加权求和,得到Attention Value
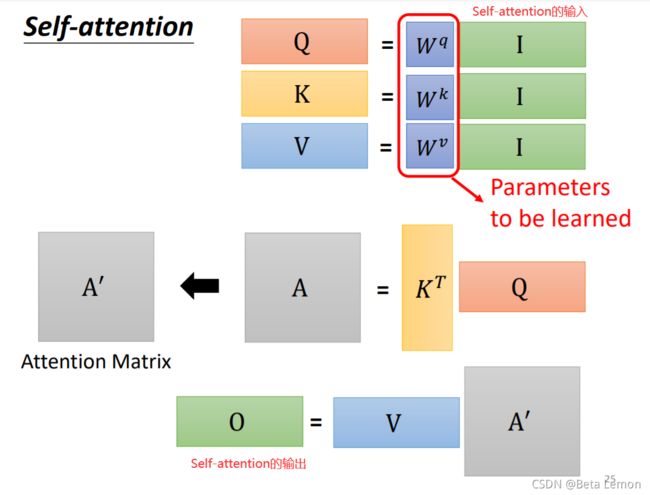
Multi-head Self-Attention

Self-Attention有一个使用非常广泛的的进阶版Multi-head Self-Attention,
如 翻译、语音辨识,用比较多的head 可以得到比较好的结果,具体使用多少个head(hyperparameter)。
在Self-Attention中,我们是用q 去找相关的k。但是 ”相关“这件事情,有很多种不同的定义,有很多不同的形式。也许我们应该有多个q,不同的q 负责不同种类的相关性。
我们先得到q再乘以另外两个矩阵,得到两个不同的q,这就是产生了多个“头”。
接下来做self-attention,就是把1这类一起做,把2这类一起做,
然后得到bi1和bi2,再通过一个transform,也就是再乘上一个矩阵,然后得到bi。再送往下一层
Positional Encoding
Self-attention少了一个也许很重要的资讯,”位置“。每一个位置操作都是一模一样的。但实际上,有一些位置的信息是很重要的,比如动词不容易放在句首。
塞进”位置“的资讯:加入 Positional Encoding 的技术。
为每一个位置设定一个vector,叫做positional vector位置向量,ei,然后把ei加到ai上面。

最早的transformer用的ei,如图,每一个column,就代表一个ei,人为设定的hand-crafted,会产生很多问题。比如我定义向量的时候它的长度只有128,但是sequence有129怎么办呢?
不过在transformer的论文中是没有这个问题的,它是通过某个规则产生的,一个神奇的sin、cos函数。其实不一定要这么产生,这个位置向量,是一个仍然待研究的问题,有各种各样不同的方法,目前还不知道那种方法最好。甚至可以让机器根据资料去自己学习出来。

这是一篇去年的论文,很新的论文,里面就是比较和提出了新的positional encoding

BERT6 模型也用到了自注意力机制(NLP领域)
Self-attention 还可以用在除NLP以外的问题上:语音处理,图像处理。
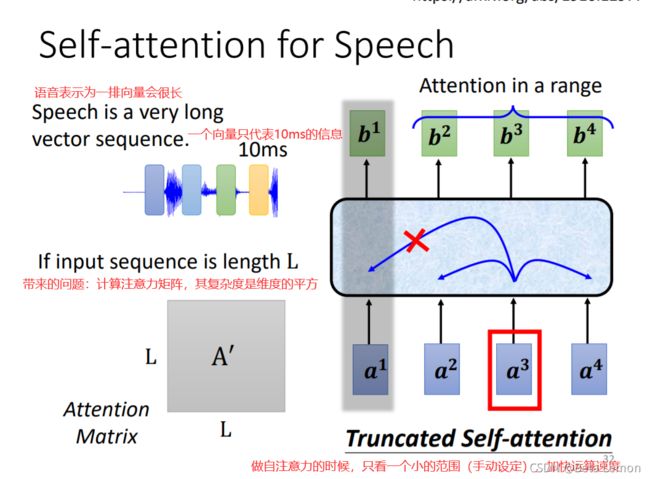
用在speech中需要做些小改动,Truncated Self-attention,不要看一整句话,只看一个小范围(超参数),why?取決於你對這個問題的理解,也許我們要辨識這個位置有什麼樣的phonon、有什麼樣的內容,我們並不需要看整句話,只要看這句話 跟它前後一定範圍之內的資訊,其實就可以判斷了
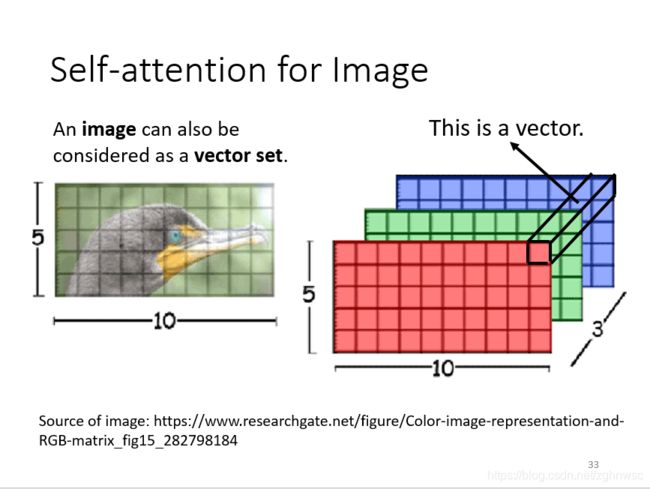
我们之前所讲的,self-attention适用的范围,是在输入是一排向量的时候(vector set)
在做CNN的时候,一张图片可看做一个很长的向量。它也可看做是一个vector set,
一张图片可以看作是一个tensor,大小是5x10x3,可以把每一个位置的pixel,看成是一个三维向量,整张图片就是5x10个向量。
这里有两个把self-attention用在图像处理上的例子。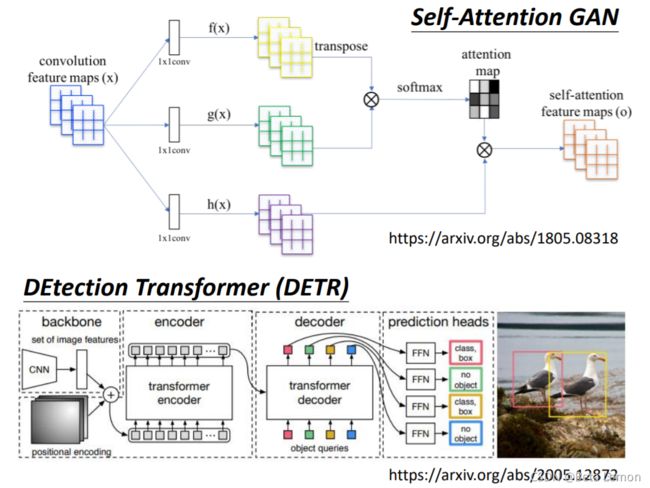
那么用self-attention和用CNN处理图片有什么区别和联系呢?

如果我们用self-attention来处理图片,其中一个1产生query,用其他的像素产生key,那我们在做内积的时候,是考虑到整张图片的。但是如果我们是用filter的话,只考虑receptive field范围里面的资讯,那么CNN就可以看作是一种简化版的self-attention。
对于CNN来说,我们要划定receptive field,每个neuron只考虑receptive field里面的资讯,而它的范围的大小,是人为决定的。
对于self-attention来说,我们用attention去找出相关的pixel,就好像receptive field是自动被学出来的。network 自己決定,receptive field 的形狀長什麼樣子,network 自己決定,以這個 pixel 為中心,哪些 pixel 是相關的

如图是,19年1月发的一篇论文,它会用数学关系严格的证明,self-attention是更flexible的CNN。self-attention只要设定合适的参数,可以做到和CNN一模一样的事情。
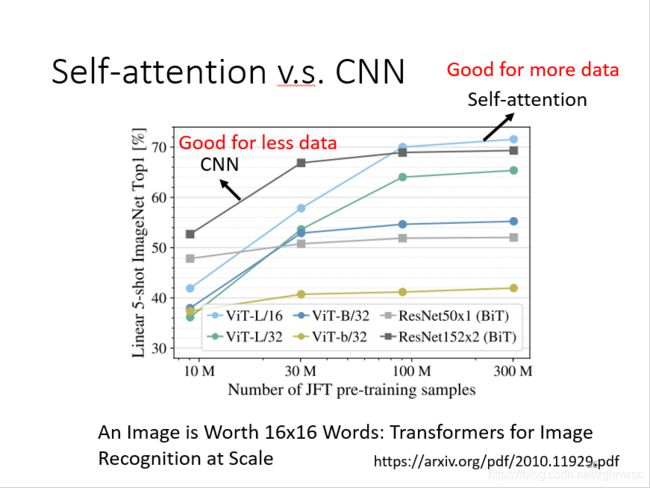
如图,谷歌发的一篇论文,是把self-attention用在图像处理,一张图片拆成16x16个patch,然后它就把每一个patch看成是一个word,(因为self-attention比较常用在NLP上面),”一张图价值16x16个文字“。
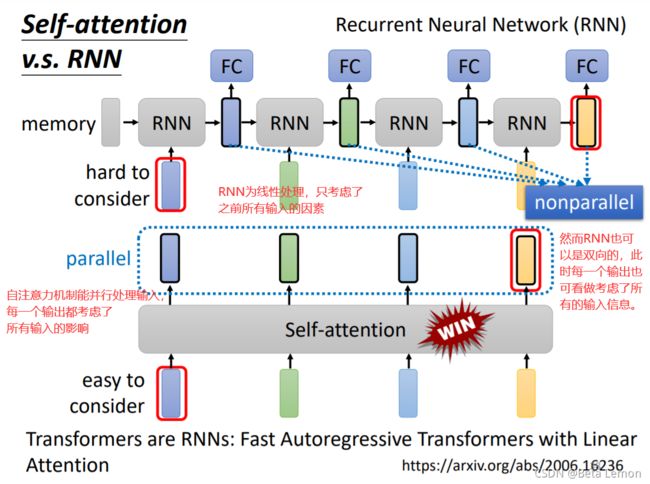
RNN是一个记忆机制
区别:
假設我們把 RNN 跟 Self-attention 的 output 拿來做對比的話、就算你用 bidirectional双向 的 RNN、還是有一些差別的
對 RNN 來說、假設最右邊這個黃色的 vector、要考慮最左邊的這個輸入、那它必須要把最左邊的輸入呢、存在 memory 裡面、然後接下來都不能夠忘掉、一路帶到最右邊、才能夠在最後一個時間點被考慮
但對 Self-attention 來說沒有這個問題、天涯若比鄰、你可以從非常遠的 vector、輕易地抽取資訊
還有另外一個更主要的不同是、RNN 是沒有辦法平行化的、所以在運算速度上、Self-attention 更有效率
因此。如今 很多的应用逐渐把RNN的架构改为Self-attention架构。
3. 应用于图论(GNN)
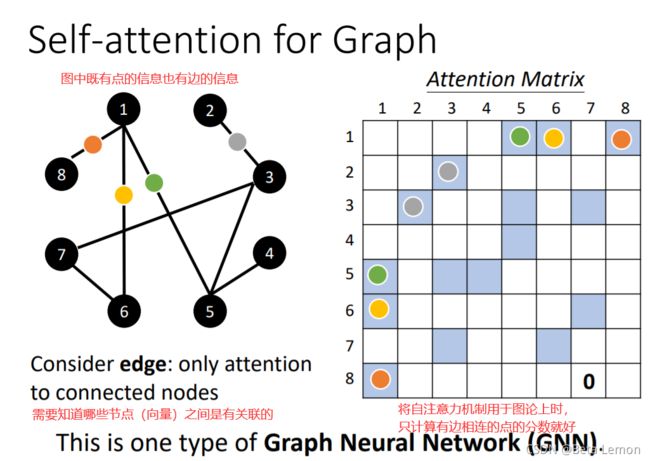
self-attention也可以用在GNN上面,在做attention matrix的时候,只需要计算有edge相连的node就好。
當我們把 Self-attention用在Graph 上面的時候、有什麼樣特別的地方呢
在 Graph 上面呢、每一個 node 可以表示成一個向量,但我們不只有每一個 node的資訊、還有 edge 的資訊、我們知道哪些 node 之間是有相連的
那之前我們在做 Self-attention 的時候、所謂的關聯性是 network 自己找出來的、
但是現在 edge 的資訊 已經暗示了我們、node 跟 node 之間的關聯性
所以今天當你把 Self-attention用在 Graph 上面的時候、你有一個選擇是你在做Attention Matrix 計算的時候、可以只計算有 edge 相連的 node 就好
那如果兩個 node 之間沒有相連、那其實很有可能就暗示我們、這兩個 node 之間沒有關係、直接把它設為 0 就好了
因為這個 Graph 往往比如說是人為根據某些 domain knowledge 建出來的、那 domain knowledge 告訴我們說、這兩個向量彼此之間沒有關聯、我們就沒有必要再用機器去學習這件事情
那其實當我們把 Self-attention、按照我們這邊講的這種限制、用在 Graph 上面的時候、其實就是一種 Graph Neural Network( GNN)、現在也是一個很 fancy 的題目、這邊水也是很深,那我不會說 Self-attention 就要囊括了 所有 GNN 的各種變形了、但把 Self-attention 用在 Graph 上面、是某一種類型的 Graph Neural Network
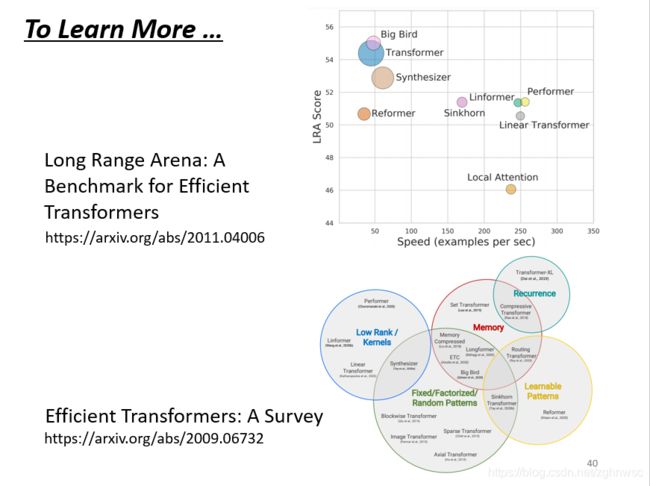
self-attention有非常非常多的变形。可以看一篇 paper 叫做Long Range Arena、裡面比較了各種不同的 Self-attention 的變形
它的一个问题就是,运算量非常大,因此如何优化其计算量是未来的重点。
Self-attention 最早是 用在 Transformer 上面
有人說廣義的 Transformer、指的就是 Self-attention
那所以後來各式各樣的Self-attention 的變形都叫做是xxformer
可以看到說呢、往右代表它運算的速度、所以有很多各式各樣新的 xxformer、它們的速度會比原來的 Transformer 快、但是快的速度帶來的就是 performance 變差(縱軸)
那到底什麼樣的 Self-attention才能夠真的又快又好、這仍然是一個尚待研究的問題
如果你對 Self-attention想要進一步研究的話、還可以看一下Efficient Transformers: A Survey 這篇 paper、裡面會跟你介紹 各式各樣 Self-attention 的變形 ( 这个是谷歌学术的transformer的一个综述,一直更新哒)
参考: (61条消息) 李宏毅《深度学习》- Self-attention 自注意力机制_Beta Lemon的博客-CSDN博客_self-attention
(61条消息) 李宏毅机器学习2021笔记—self-attention(下)_zghnwsc的博客-CSDN博客
2022 - 各式各样神奇的自注意力机制 (Self-attention) 变型_哔哩哔哩_bilibili
1. self-attention的痛点

一个长度为N的句子,会得到N个key和N个query。然后做dot-product,得到attention matrix。痛点在于计算这个N×N的attention matrix计算量可能会非常惊人。所以有一系列方法加速这个计算过程

注意:
Self-attention 往往只是一个巨大network的其中一个module,(如 在transformer中),
当N很小的时候,单纯增加self-attention的运算效率可能并不会对整个网络的计算效率有太大的影响。因此,提高self-attention的计算效率从而大幅度提高整个网络的效率的前提是:N特别大的时候,比如做图像识别(影像处理、image processing)。
2. skip some calculations with human knowledge

如何加快self-attention的求解速度呢?根据上述分析可以知道,影响self-attention机制的瓶颈 就是Attention Matrix的计算(N x N)。-
比较直观的想法是也许没必要把这个matrix所有值都计算出来,有些值可能可以靠一些domain knowledge确定
2.1. local attention / truncated attention

-比如有些问题在做attention时,并不需要看整个句子,而只需要看”邻居“。
-所以就强制让离vector一定距离的其他vectors的attention score为0
-这种attention叫做local attention或truncated attention。这样做每个vector只能看到它临近的几个vectors,和CNN没啥区别。
-所以local attention是一个可以加速运算的方法,但他不一定可以给你非常好的结果。
2.2. stride attention

有人说只看邻居不好,那就看比较远一点的邻居,比如说在每一个位置,我们不是看相邻位置的资讯,而是跳两格,这样就可以看到比较大的范围,
-Stride attention就是把邻居设置得远一点,完全由自己决定应该隔多少个vector计算attention score
-上图中,绿色格子代表要计算attention weight,灰色表示设为0
2.3. global attention
local attention和Stride attention都是以某一个位置作为中心,看左右两边发生什么,
-如果要看一整个sequence发生什么事,可以用global attention
-global attention的一种做法是直接assign原始sequence中的某几个vectors为global attention里的special token。比如把sequence开头的CLS token或结尾的END token当作special token
-另一个做法是直接加几个special token
-No attention between non-special token

那我们假设呢这个input sequence里面头两个位置就是special token。每个row代表query,每个列代表key。special token要attend到所有人,也被所有人attend。
2.4. 融合各种attention方式(多个头,各自采取一种attention方式)

到底哪种attention最好呢?小孩子才做选择...
self-attention里有multiple head,我们可以设定多个不同的head,让每个head做不同的事,有的head是local attention,有的head是global attention...这样就不需要做选择了。看下面几个例子:
-很多知名的self-attention的变形就是将多种attention方式融合在一起
- Longformer就是组合了上面的三种attention
- Big Bird是知名的self-attention的变形,这篇paper其实就是Longformer+random attention,就是在Longformer基础上随机选择attention赋值,进一步提高计算效率
7. data-driven方式决定attention weight的取舍

-前面的变体都是人为设定哪里需有attention weight,哪里没有attention weight
-但也许人为设定并不是最佳选择,有没有办法用data-driven方式来呢?
对于Attention Matrix来说,如果某些位置值非常小,我们可以直接把这些位置置0,这样对实际预测的结果也不会有太大的影响。也就是说我们只需要找出Attention Matrix中attention的值相对较大的值。
-这样的话怎么快速估算出哪些位置的值非常小/非常大呢?
8. clustering方式

-Reformer和routing transformer用了类似的方法,都属于clustering方式
-第一步先把query和key聚类。
根据query和key相近的程度做 聚类,比较近的就分类在一起,比较远的就属于不同的cluster
clustering的计算量大?有很多可以加速的方法,这里采取一个估测法,不是非常准确,但非常快速,
-Reformer和routing transformer就采用了不同的clustering方式来加速计算

-聚类完后,我们只计算归为同一个类别的query和key之间的attention score,其他位置的attention score直接设置为0(不在同一个cluster,代表他们不像,距离远,设为0)
-目前为止,让某些位置的attention weight为0的方式都是基于人类的假设(即使是clustering也是人为假设相似的query和key之间才要算attention weight)
-那有没有办法让要不要计算attention weight直接学出来呢?
9. learnable patterns——Sinkhorn Sorting Network

有可能的。
-一个方法是Sinkhorn Sorting Network,直接用一个network来决定哪些位置要算attention。
它直接预测哪些地方要不要计算attention,产生一个1-0矩阵,图中深色位置是1,代表要计算attention weight,浅色位置是0,代表不计算
-Sinkhorn Sorting Network做法是learn另外一个network来决定这个1-0矩阵。
-how? input一个sequence,然后呢你把input sequence的每个位置的vector,通过一个network产生一个vector,这个vector跟sequence长度一致,拼起来就产生一个N×N的矩阵。目标是:把这个矩阵变成attention matrix。但是后者是1-0矩阵、前者是continuous的,这就是这篇network的重点,他用一个很特别的办法来解,而且这个过程是可微分的,所以最后这个NN是和整个network一起train出来的,
真的比原来快?有一个细节是:比如10个vector共用同一个column(NN产生的矩阵 解析度比较低10x10,再放大到100x100)
10. Linformer

-Linformer发现,很多时候我们并不需要一个完整的N×N的attention matrix。Matrix中很多部分是redundant。
-那我们能不能把重复资讯拿掉,产生一个比较小的matrix,就可以加速计算了

-linformer的做法如下
,从N个key中选出K个具有代表的key,
每个key都和query计算attention太多了,很多key都是很像的,是冗员,
然后计算 N×K的matrix
接下来怎么用这个attention matrix计算 self-attention layer的output?
每个key对应一个value vector,
把K个key(黄色vectors)对第一个query算出来的attention weight(红色框)对这个K个value(蓝色vectors)做weighted sum得到第一个位置的output(绿色vector),
-why不对query进行挑选? 因为如果query减少了,output sequence length也会变小。这种做法对于sequence中每个位置都需要output的情况是不适用的。
-那么怎么挑选出有代表性的keys呢?

有不同的做法,这里介绍两种方法,
-Compressed Attention这篇paper,是用CNN扫过整个句子,得到较短的output当作有代表性的keys
-Linformer是直接乘上N×K矩阵,做线性变化。
(d x N) * (N x K) ---> (d x K),本质是,K个vector都是N个vector的linear combination
11. 改进attention计算的矩阵过程,加速计算

回想一下,其实attention整个过程就是一连串矩阵的相乘,那这个过程中有没有可以减少运算量的部分?
-attention计算过程的回归
-Q和K的维度d必须一样(要做dot product),而V的维度d‘可以不等于d
-现在,我们先忽略softmax这个操作

-暂时忽略softmax后,输出O可以当成是三个矩阵相乘

上述过程是可以加速的。如果先V*K^T再乘Q的话相比于K^T*Q再乘V结果是相同的,但是计算量会大幅度减少。
附:线性代数关于这部分的说明
(算法导论动态规划章节,矩阵链乘法)

(李老师教的课: 线性代数 CV NLP 机器学习(综合) 大概这四个吧)



而(d+d')N^2>>2*d'*d*N,所以通过改变运算顺序就可以大幅度提升运算效率。
现在我们把softmax拿回来。原来的self-attention是这个样子,以计算b1为例:

如果我们可以将exp(q*k)转换成两个映射相乘的形式,那么可以对上式进行进一步简化:
分母部分化简

分子化简

将括号里面的东西当做一个向量, 用 ![]() 做weighted sum,
做weighted sum,
M个向量组成M维的矩阵,在乘以φ(q1),得到分子。

用图形化表示如下:

由上面可以看出 分子蓝色的矩阵 和 分母黄色的vector ,其实跟位置 ,b1中的1是没有关系的。也就是说,当我们算b2、b3...时,蓝色的矩阵和黄色的vector不需要再重复计算。

综上,self-attention还可以用另一种方法来看待。这个计算的方法跟原来的self-attention计算出的结果一模一样,但是运算量会大幅度减少。
操作方法:
简单来说,先找到一个转换的方式φ(),首先将k进行转换,然后拿出φ(k)第一个的位置的element拿出来和v1,-v4做weighted sum,得到M个的vector。
注意:需要确保k和q通过φ()这个转换之后dimension是一样的。
之后的计算过程如图:


-做完weighted sum后,得到a1所对应的输出b1的分子部分,再计算分母部分就得出b1

理解:v1,-v4做weighted sum 是要找寻重要的template。整个sequence里总共M个重要的template,接下来每个位置的输出就是拿这些template做linear combination
那么exp(q.k)怎么拆解成φ(q).φ(k),φ到底如何选择呢?不同的文献有不同的做法:

12. 真的需要q和v来计算attention matrix吗?

接下来进一步思考,在计算self-attention的时候一定需要q和k做inner product吗?不一定。
self-attention是 先把input sequence每个位置产生一个value vector,拿normalize之后的attention做weighted sum,
在Synthesizer文献里面,对于attention matrix不是通过q和k得到的,
attention matrix怎么来?Synthesizer里面有两个版本,一个版本 和Sinkhorn Sorting Network很像,拿a1,-a4产生这个matrix,还有一个更神奇的版本,把这个matrix当作network一部分,作为网络参数学习得到。
问题,那不是input 不同的sequence,attention 的weight都是一样的了?对(因为network参数不会随着input变化),但是performance不会变差。这也引发一个思考,attention的价值到底是什么?
更进一步,处理sequence一定要用attention吗?可不可以尝试把attention丢掉?有没有attention-free的方法?
过去人们已经丢掉了recurrent,接下来人们要丢掉attention
下面有几个用MLP的方法用于代替attention来处理sequence。MLP就是一般的fully connected network

13. sumary

这张图是long range arena,就是self-attention 有个benchmark的corpus,
圈圈越大,代表用到的memory越多(计算量越大)。
-纵轴表示效果好坏(越高越好),横轴表示速度(越大越快)