【DETR源码解析】三、Transformer模块
目录
- 前言
- 一、Transformer整体结构
- 二、TransformerEncoder
-
- 2.1、TransformerEncoderLayer
- 三、TransformerDecoder
-
- 3.1、TransformerDecoderLayer
- Reference
前言
最近在看DETR的源码,断断续续看了一星期左右,把主要的模型代码理清了。一直在考虑以什么样的形式写一写DETR的源码解析。考虑的一种形式是像之前写的YOLOv5那样的按文件逐行写,一种是想把源码按功能模块串起来。考虑了很久还是决定按第二种方式,一是因为这种方式可能会更省时间,另外就是也方便我整体再理解一下吧。
我觉得看代码就是要看到能把整个模型分功能拆开,最后再把所有模块串起来,这样才能达到事半功倍。
另外一点我觉得很重要的是:拿到一个开源项目代码,要有马上配置环境能够正常运行Debug的能力,并且通过解析train.py马上找到主要模型相关的内容,然后着重关注模型方面的解析,像一些日志、计算mAP、画图等等代码,完全可以不看,可以省很多时间,所以以后我讲解源码都会把无关的代码完全剥离,不再讲解,全部精力关注模型、改进、损失等内容。
这一节主要讲一下DETR的Transformer部分,包括Encoder和Decoder两个部分,主要涉及models/transformer.py文件。
Github注释版源码:HuKai97/detr-annotations
一、Transformer整体结构
先看下调用接口:
def build_transformer(args):
return Transformer(
d_model=args.hidden_dim,
dropout=args.dropout,
nhead=args.nheads,
dim_feedforward=args.dim_feedforward,
num_encoder_layers=args.enc_layers,
num_decoder_layers=args.dec_layers,
normalize_before=args.pre_norm,
return_intermediate_dec=True,
)
直接调用Transformer类:
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
"""
d_model: 编码器里面mlp(前馈神经网络 2个linear层)的hidden dim 512
nhead: 多头注意力头数 8
num_encoder_layers: encoder的层数 6
num_decoder_layers: decoder的层数 6
dim_feedforward: 前馈神经网络的维度 2048
dropout: 0.1
activation: 激活函数类型 relu
normalize_before: 是否使用前置LN
return_intermediate_dec: 是否返回decoder中间层结果 False
"""
# 初始化一个小encoder
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
# 创建整个Encoder层 6个encoder层堆叠
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
# 初始化一个小decoder
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
# 创建整个Decoder层 6个decoder层堆叠
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
# 参数初始化
self._reset_parameters()
self.d_model = d_model # 编码器里面mlp的hidden dim 512
self.nhead = nhead # 多头注意力头数 8
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
"""
src: [bs,256,19,26] 图片输入backbone+1x1conv之后的特征图
mask: [bs, 19, 26] 用于记录特征图中哪些地方是填充的(原图部分值为False,填充部分值为True)
query_embed: [100, 256] 类似于传统目标检测里面的anchor 这里设置了100个 需要预测的目标
pos_embed: [bs, 256, 19, 26] 位置编码
"""
# bs c=256 h=19 w=26
bs, c, h, w = src.shape
# src: [bs,256,19,26]=[bs,C,H,W] -> [494,bs,256]=[HW,bs,C]
src = src.flatten(2).permute(2, 0, 1)
# pos_embed: [bs, 256, 19, 26]=[bs,C,H,W] -> [494,bs,256]=[HW,bs,C]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
# query_embed: [100, 256]=[num,C] -> [100,bs,256]=[num,bs,256]
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
# mask: [bs, 19, 26]=[bs,H,W] -> [bs,494]=[bs,HW]
mask = mask.flatten(1)
# tgt: [100, bs, 256] 需要预测的目标query embedding 和 query_embed形状相同 且全设置为0
# 在每层decoder层中不断的被refine,相当于一次次的被coarse-to-fine的过程
tgt = torch.zeros_like(query_embed)
# memory: [494, bs, 256]=[HW, bs, 256] Encoder输出 具有全局相关性(增强后)的特征表示
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
# [6, 100, bs, 256]
# tgt:需要预测的目标 query embeding
# memory: encoder的输出
# pos: memory的位置编码
# query_pos: tgt的位置编码
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
# decoder输出 [6, 100, bs, 256] -> [6, bs, 100, 256]
# encoder输出 [bs, 256, H, W]
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
仔细分析这个类会发现,我们虽然暂时不了解模型的细节部分,但是模型的主体框架已经定义出来了。整个Transformer其实就是输入经过Backbone输出的特征图src(降维到256)、src_key_padding_mask(记录特征图每个位置是否是被pad的,pad的就不需要计算注意力)和位置编码pos到TransformerEncoder中,而TransformerEncoder其实是由TransformerEncoderLayer组成的;然后再输入encoder的输出、mask、位置编码和query编码到TransformerEncoder中,而TransformerEncoder是由TransformerDecoderLayer组成的。
所以,下面分为TransformerEncoder和TransformerDecoder两个模块来了解Transformer具体细节组成。
二、TransformerEncoder
这个部分就是调用_get_clones函数,复制6份TransformerEncoderLayer类,然后前向传播依次输入这6个TransformerEncoderLayer类,不断的计算特征图的自注意力,并不断的增强特征图,最终得到最强的(信息最多的)特征图output:[h*w, bs, 256]。值得注意的是,整个TransformerEncoder过程特征图的shape是不变的。
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
# 复制num_layers=6份encoder_layer=TransformerEncoderLayer
self.layers = _get_clones(encoder_layer, num_layers)
# 6层TransformerEncoderLayer
self.num_layers = num_layers
self.norm = norm # layer norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
"""
src: [h*w, bs, 256] 经过Backbone输出的特征图(降维到256)
mask: None
src_key_padding_mask: [h*w, bs] 记录每个特征图的每个位置是否是被pad的(True无效 False有效)
pos: [h*w, bs, 256] 每个特征图的位置编码
"""
output = src
# 遍历这6层TransformerEncoderLayer
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
# 得到最终ENCODER的输出 [h*w, bs, 256]
return output
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
2.1、TransformerEncoderLayer
encoder结构图:

Encoder Layer = multi-head Attention + add&Norm + feed forward + add&Norm,重点在于multi-head Attention。
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
"""
小encoder层 结构:multi-head Attention + add&Norm + feed forward + add&Norm
d_model: mlp 前馈神经网络的dim
nhead: 8头注意力机制
dim_feedforward: 前馈神经网络的维度 2048
dropout: 0.1
activation: 激活函数类型
normalize_before: 是否使用先LN False
"""
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
# 这个操作是把词向量和位置编码相加操作
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
"""
src: [494, bs, 256] backbone输入下采样32倍后 再 压缩维度到256的特征图
src_mask: None
src_key_padding_mask: [bs, 494] 记录哪些位置有pad True 没意义 不需要计算attention
pos: [494, bs, 256] 位置编码
"""
# 数据 + 位置编码 [494, bs, 256]
# 这也是和原版encoder不同的地方,这里每个encoder的q和k都会加上位置编码 再用q和k计算相似度 再和v加权得到更具有全局相关性(增强后)的特征表示
# 每用一层都加上位置编码 信息不断加强 最终得到的特征全局相关性最强 原版的transformer只在输入加上位置编码 作者发现这样更好
q = k = self.with_pos_embed(src, pos)
# multi-head attention [494, bs, 256]
# q 和 k = backbone输出特征图 + 位置编码
# v = backbone输出特征图
# 这里对query和key增加位置编码 是因为需要在图像特征中各个位置之间计算相似度/相关性 而value作为原图像的特征 和 相关性矩阵加权,
# 从而得到各个位置结合了全局相关性(增强后)的特征表示,所以q 和 k这种计算需要+位置编码 而v代表原图像不需要加位置编码
# nn.MultiheadAttention: 返回两个值 第一个是自注意力层的输出 第二个是自注意力权重 这里取0
# key_padding_mask: 记录backbone生成的特征图中哪些是原始图像pad的部分 这部分是没有意义的
# 计算注意力会被填充为-inf,这样最终生成注意力经过softmax时输出就趋向于0,相当于忽略不计
# attn_mask: 是在Transformer中用来“防作弊”的,即遮住当前预测位置之后的位置,忽略这些位置,不计算与其相关的注意力权重
# 而在encoder中通常为None 不适用 decoder中才使用
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
# add + norm + feed forward + add + norm
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before: # False
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos) # 默认执行
有几个很关键的点(和原始transformer encoder不同的地方):
- 为什么每个encoder的q和k都是+位置编码的?如果学过transformer的知道,通常都是在transformer的输入加上位置编码,而每个encoder的qkv都是相等的,都是不加位置编码的。而这里先将q和k都会加上位置编码,再用q和k计算相似度,最后和v加权得到更具有全局相关性(增强后)的特征表示。每一层都加上位置编码,每一层全局信息不断加强,最终可以得到最强的全局特征;
- 为什么q和k+位置编码,而v不需要加上位置编码?因为q和k是用来计算图像特征中各个位置之间计算相似度/相关性的,加上位置编码后计算出来的全局特征相关性更强,而v代表原图像,所以并不需要加位置编码;
三、TransformerDecoder
Decoder结构和Encoder的结构类似,也是用_get_clones复制6份TransformerDecoderLayer类,然后前向传播依次输入这6个TransformerDecoderLayer类,不过不同的,Decoder需要输入这6个TransformerDecoderLayer的输出,后面这6个层的输出会一起参与损失计算。
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
# 复制num_layers=decoder_layer=TransformerDecoderLayer
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers # 6
self.norm = norm # LN
# 是否返回中间层 默认True 因为DETR默认6个Decoder都会返回结果,一起加入损失计算的
# 每一层Decoder都是逐层解析,逐层加强的,所以前面层的解析效果对后面层的解析是有意义的,所以作者把前面5层的输出也加入损失计算
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
"""
tgt: [100, bs, 256] 需要预测的目标query embedding 和 query_embed形状相同 且全设置为0
在每层decoder层中不断的被refine,相当于一次次的被coarse-to-fine的过程
memory: [h*w, bs, 256] Encoder输出 具有全局相关性(增强后)的特征表示
tgt_mask: None
tgt_key_padding_mask: None
memory_key_padding_mask: [bs, h*w] 记录Encoder输出特征图的每个位置是否是被pad的(True无效 False有效)
pos: [h*w, bs, 256] 特征图的位置编码
query_pos: [100, bs, 256] query embedding的位置编码 随机初始化的
"""
output = tgt # 初始化query embedding 全是0
intermediate = [] # 用于存放6层decoder的输出结果
# 遍历6层decoder
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
# 6层结果全部加入intermediate
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
# 默认执行这里
# 最后把 6x[100,bs,256] -> [6(6层decoder输出),100,bs,256]
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0) # 不执行
3.1、TransformerDecoderLayer
decoder layer 结构图:
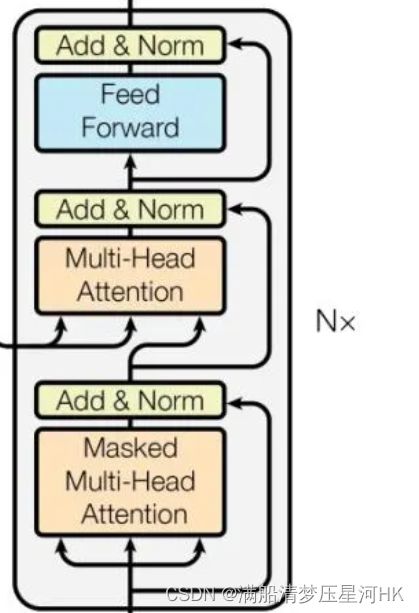
decoder layer = Masked Multi-Head Attention + Add&Norm + Multi-Head Attention + add&Norm + feed forward + add&Norm。关键点在于两个Attention层,搞懂这两层的原理、区别是理解Decoder的关键。
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
"""
tgt: 需要预测的目标 query embedding 负责预测物体 用于建模图像当中的物体信息 在每层decoder层中不断的被refine
[100, bs, 256] 和 query_embed形状相同 且全设置为0
memory: [h*w, bs, 256] Encoder输出 具有全局相关性(增强后)的特征表示
tgt_mask: None
memory_mask: None
tgt_key_padding_mask: None
memory_key_padding_mask: [bs, h*w] 记录Encoder输出特征图的每个位置是否是被pad的(True无效 False有效)
pos: [h*w, bs, 256] encoder输出特征图的位置编码
query_pos: [100, bs, 256] query embedding/tgt的位置编码 负责建模物体与物体之间的位置关系 随机初始化的
tgt_mask、memory_mask、tgt_key_padding_mask是防止作弊的 这里都没有使用
"""
# 第一个self-attention的目的:找到图像中物体的信息 -> tgt
# 第一个多头自注意力层:输入qkv都和Encoder无关 都来自于tgt/query embedding
# 通过第一个self-attention 可以不断建模物体与物体之间的关系 可以知道图像当中哪些位置会存在物体 物体信息->tgt
# query embedding + query_pos
q = k = self.with_pos_embed(tgt, query_pos)
# masked multi-head self-attention 计算query embedding的自注意力
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
# add + norm
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# 第二个self-attention的目的:不断增强encoder的输出特征,将物体的信息不断加入encoder的输出特征中去,更好地表征了图像中的各个物体
# 第二个多头注意力层,也叫Encoder-Decoder self attention:key和value来自Encoder层输出 Query来自Decoder层输入
# 第二个self-attention 可以建模图像 与 物体之间的关系
# 根据上一步得到的tgt作为query 不断的去encoder输出的特征图中去问(q和k计算相似度) 问图像当中的物体在哪里呢?
# 问完之后再将物体的位置信息融合encoder输出的特征图中(和v做运算) 这样我得到的v的特征就有 encoder增强后特征信息 + 物体的位置信息
# query = query embedding + query_pos
# key = encoder输出特征 + 特征位置编码
# value = encoder输出特征
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
# ada + norm + Feed Forward + add + norm
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
# [100, bs, 256]
# decoder的输出是第一个self-attention输出特征 + 第二个self-attention输出特征
# 最终的特征:知道图像中物体与物体之间的关系 + encoder增强后的图像特征 + 图像与物体之间的关系
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
总结下decoder在干嘛:
- 从Encoder的最终输出,我们得到了增强版的图像特征memory,以及特征的位置信息pos;
- 自定义了图像当中的物体信息tgt,初始化为全0,以及图像中的物体位置信息query_pos,随机初始化;
- 第一个self-attention:qk=tgt+query_pos,v=tgt,计算图像中物体与物体的相关性,负责建模图像中的物体信息,最终得到的tgt1,是增强版的物体信息,这些位置信息包含了物体与物体之间的位置关系;
- 第二个self-attention:q=tgt+qyery_pos,k=memory+pos,v=memory,以物体的信息tgt作为query,去图像特征memory中去问(计算他们的相关性),问图像中物体在哪里呢?问完之后再将物体的位置信息融入到图像特征中去(v),整个过程是负责建模图像特征与物体特征之间的关系,最后得到的是更强的图像特征tgt2,包括encoder输出的增强版的图像特征+物体的位置特征。
- 最后把tgt1 + tgt2 = Encoder输出的增强版图像特征 + 物体信息 + 物体位置信息,作为decoder的输出;
疑问一
有的人可能疑问,为什么这里定义的物体信息tgt,初始化为全0,物体位置信息query_pos,随机初始化,但是可以表示这么复杂的含义呢?它明明是初始化为全0或随机初始化的,模型怎么知道的它们代表的含义?这其实就和损失函数有关了,损失函数定义好了,通过计算损失,梯度回传,网络不断的学习,最终学习得到的tgt和query_pos就是这里表示的含义。这就和回归损失一样的,定义好了这四个channel代表xywh,那网络怎么知道的?就是通过损失函数梯度回传,网络不断学习,最终知道这四个channel就是代表xywh。
疑问二
为什么这里要将tgt1 + tgt2做为decoder的输出呢?不是单独的用tgt1或者tgt2呢?
-
首先tgt1代表图像中的物体信息 + 物体的位置信息,但是他没有太多的图像特征,这是不行的,最后预测效果肯定不好(预测物体类别肯定不是很准);
-
其次tgt2代表的encoder增强版的图像特征 + 物体的位置信息,它缺少了物体的信息,这也是不行的,最后的预测效果肯定也不好(预测物体位置肯定不是很准);
所以两者相加的特征作为decoder的输出,去预测物体的类别和位置,效果最好。
Reference
官方源码: https://github.com/facebookresearch/detr
b站源码讲解: 铁打的流水线工人
知乎【布尔佛洛哥哥】: DETR 源码解读
CSDN【在努力的松鼠】源码讲解: DETR源码笔记(一)
CSDN【在努力的松鼠】源码讲解: DETR源码笔记(二)
知乎CV不会灰飞烟灭-【源码解析目标检测的跨界之星DETR(一)、概述与模型推断】
知乎CV不会灰飞烟灭-【源码解析目标检测的跨界之星DETR(二)、模型训练过程与数据处理】
知乎CV不会灰飞烟灭-【源码解析目标检测的跨界之星DETR(三)、Backbone与位置编码】
知乎CV不会灰飞烟灭-【源码解析目标检测的跨界之星DETR(四)、Detection with Transformer】
知乎CV不会灰飞烟灭-【源码解析目标检测的跨界之星DETR(五)、loss函数与匈牙利匹配算法】
知乎CV不会灰飞烟灭-【源码解析目标检测的跨界之星DETR(六)、模型输出与预测生成】