【HRNet】《Deep High-Resolution Representation Learning for Human Pose Estimation》

CVPR-2019
代码:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 5 Experiments
-
- 5.1 Datasets
- 5.2 COCO Key-point Detection
- 5.3 MPII Human Pose Estimation
- 5.4 Application to Pose Tracking
- 5.5 Ablation Study
- 6 Conclusion(own) / Future work
- 附录:作者的演讲
1 Background and Motivation
2D Human Pose Estimation 是对 human anatomical key-points 进行定位,在动作识别,人机交互,动画(animation)等方面有许多应用
最近 SOTA 的方法采用的是 CNN,遵循 high-to-low resolution 然后 raise the resolution 的流程,比如 Hourglass(对称的),dilated convolution(ResNet stage 5 中)
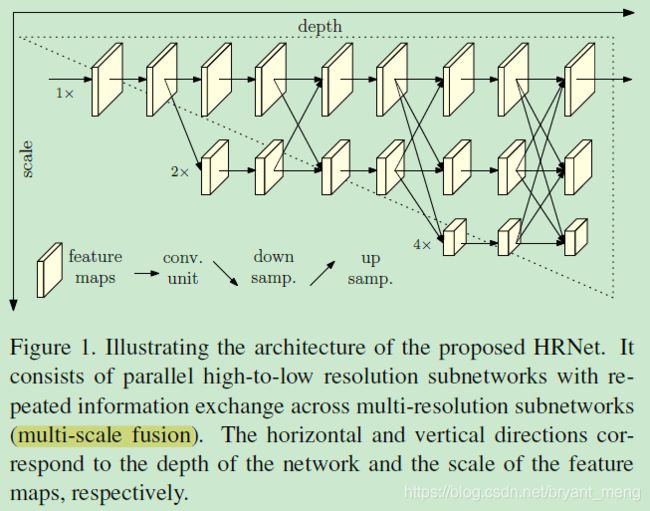
作者提出 HighResolution Net (HRNet),可以在网络整个流程中都 maintain high resolution representations


可以看到分辨率一直很坚挺
好处是 more accurate and spatially more precise
2 Related Work
传统方法基于
- probabilistic graphical model
- pictorial structure model(图结构模型)
深度学习方法
- regressing the position of keypoints
- estimating keypoint heatmaps
- High-to-low and low-to-high(前后过程 Symmetric, 前面过程 heavy 后面 light, Combination with dilated convolutions)
- Multi-scale fusion
- Intermediate supervision(Inception)

3 Advantages / Contributions
提出 HRNet 主干网络来做人体关键点检测,让网络一直保持了高分辨率 representation,有利于更精确的关键点定位!
在 COCO / MPII 人体姿态估计数据集上表现惊艳
4 Method
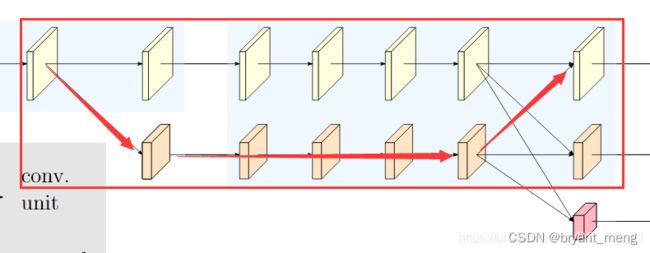
1) Sequential multi-resolution sub-networks
传统的主干网络结构,随着网络的深入,空间分辨率不断的下降
N 11 N_{11} N11 → N 22 N_{22} N22→ N 33 N_{33} N33→ N 44 N_{44} N44
N s r N_{sr} Nsr 表示 s s s-th stage,分辨率是原来的 1 2 r − 1 \frac{1}{2^{r-1}} 2r−11
2)Parallel multi-resolution sub-networks
作者的主干网络
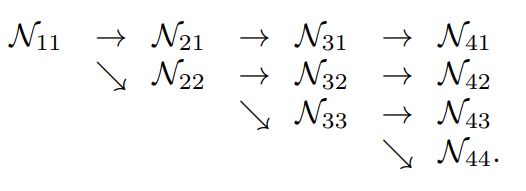
4 个并行的 sub-networks
3) Repeated multi-scale fusion
以上述并行多分辨率子网络的第三个 stage 为例(在 block 之间进行 fusion)
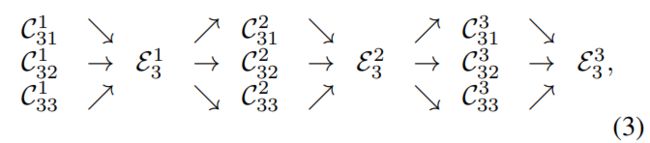
- C s r b C_{sr}^{b} Csrb 表示 s s s-th stage, b b b-th block,分辨率是原来的 1 2 r − 1 \frac{1}{2^{r-1}} 2r−11
- ε s b \varepsilon_{s}^{b} εsb 表示对应的 exchange unit
下图更细节的展示了 ε s b \varepsilon_{s}^{b} εsb 操作
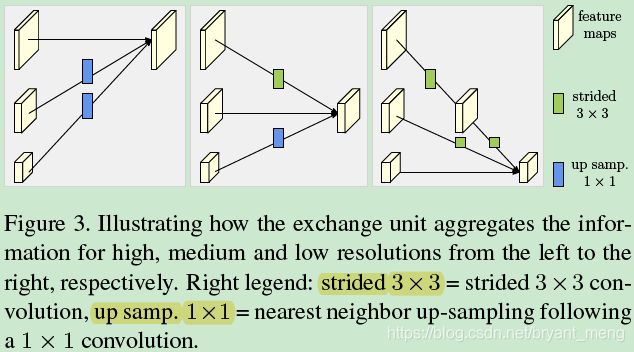
-
下采样
one strided 3×3 convolution with the stride 2 for 2× down-sampling
two consecutive strided 3 × 3 convolutions with the stride 2 for 4× down-sampling -
上采样
simple nearest neighbor sampling following a 1 × 1 convolution for aligning the number of channels
公式化表达如下
输入 { X 1 , X 2 , . . . , X s } \{X_1,X_2,...,X_s\} {X1,X2,...,Xs}
输出 { Y 1 , Y 2 , . . . , Y s } \{Y_1,Y_2,...,Y_s\} {Y1,Y2,...,Ys},分辨率和通道数(文中为 widths)同输入
每次输出都是对输入的一种 aggregation
Y k = ∑ i = 1 s a ( X i , k ) Y_k = \sum_{i=1}^{s} a(X_i,k) Yk=i=1∑sa(Xi,k)
其中 a ( X i , k ) a(X_i,k) a(Xi,k) 表示把输入 X X X 的分辨率 i i i 变为 k k k(通过上采样或者下采样)
交换 unit 一顿操作后,最后会多生成出一个 parallel subnet,
Y s + 1 : Y s + 1 = a ( Y s , s + 1 ) Y_{s+1}: Y_{s+1} = a(Y_s,s+1) Ys+1:Ys+1=a(Ys,s+1)
分辨率倍率+1,小了一个 level
4) Heat-map estimation
损失为预测的 heat-map 和 GT 的 heat-map 的 mean squared error,
GT 的 heat-map 产生方式为,1 像素标准差的 2D gaussian
下面以均值为 6,方差为 2 的例子为例,可视化下 GT(单点)
import numpy as np
import matplotlib.pyplot as plt
sigma = 2
kernel_size = 6
size = 2 * kernel_size + 1 # 2*6 +1 = 13
x = np.arange(0, size, 1, np.float32) # (13,) 0~12
y = x[:, np.newaxis] # (13,1)
x0 = y0 = size // 2 # 6
# The gaussian is not normalized, we want the center value to equal 1
x,y = np.meshgrid(x,y)
g = np.exp(- ((x - x0) ** 2 + (y - y0) ** 2) / (2 * sigma ** 2)) # (13,13)
g2 = g[kernel_size:,kernel_size:]
g3 = g[kernel_size:,:kernel_size+1]
g4 = g[:kernel_size+1,kernel_size:]
g5 = g[:kernel_size+1,:kernel_size+1]
plt.subplot(3,3,1)
plt.imshow(g2,cmap=plt.cm.jet) # 设置为热力图
plt.subplot(3,3,3)
plt.imshow(g3,cmap=plt.cm.jet) # 设置为热力图
plt.subplot(3,3,5)
plt.imshow(g,cmap=plt.cm.jet) # 设置为热力图
plt.subplot(3,3,7)
plt.imshow(g4,cmap=plt.cm.jet) # 设置为热力图
plt.subplot(3,3,9)
plt.imshow(g5,cmap=plt.cm.jet) # 设置为热力图
plt.show()
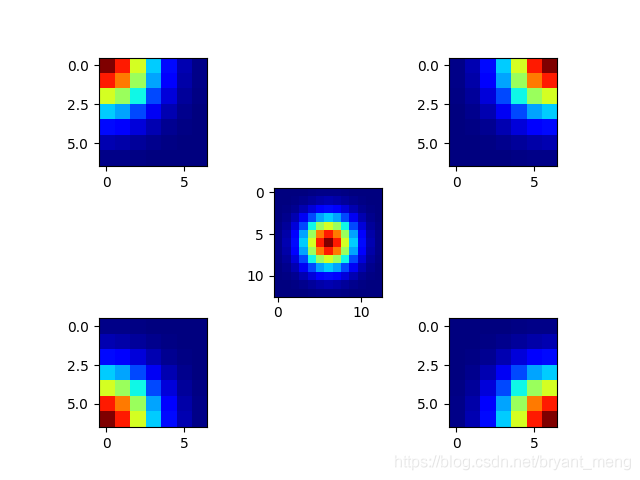
注意下 GT 为边界的时候,GT的情况
5) Network instantiation
4 stage 4 parallel sub-networks
第 1 个 stage 有 4 个 residual units(bottleneck)
第 2 个 stage 有 1 exchange block
第 3 个 stage 有 4 exchange block
第 4 个 stage 有 3 exchange block
一个 exchange block 包含 4 个 residual units,整个网络共 8 个 exchange block
作者搭建了通道数不同的两种大小的网络,HRNet-W32 and HRNet-W48,区别是最后 3 个 stage 的网络的通道数,一个是 64,128,256,一个是 96,192,384
5 Experiments
5.1 Datasets
- COCO keypoint detection dataset
over 200,000 images and 250,000 person instance,17 keypoints- train 2017:57K images and 150K person instance
- val 2017:5000 images
- test-dev 2017:20K images
17 个关键点
"keypoints": [
"nose",
"left_eye",
"right_eye",
"left_ear",
"right_ear",
"left_shoulder",
"right_shoulder",
"left_elbow",
"right_elbow",
"left_wrist",
"right_wrist",
"left_hip",
"right_hip",
"left_knee",
"right_knee",
"left_ankle",
"right_ankle"
]
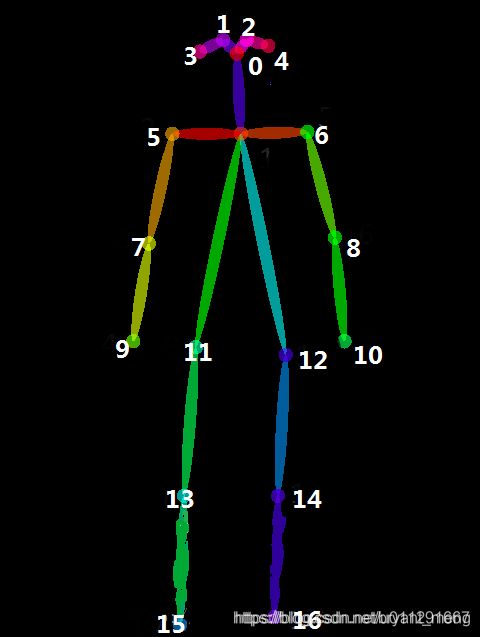
图片来自 COCO Dataset person_keypoints.json 解析
- MPII Human Pose dataset
25 K images with 40K subjects,12K for testing and remaining for training
16 个关键点
{
0 - r ankle,
1 - r knee,
2 - r hip,
3 - l hip,
4 - l knee,
5 - l ankle,
6 - pelvis, # 骨盆(hip 中间)
7 - thorax, # 胸部(shoulder 中间)
8 - upper neck, # 上颈部
9 - head top, # 头顶
10 - r wrist,
11 - r elbow,
12 - r shoulder,
13 - l shoulder,
14 - l elbow,
15 - l wrist }
其中 6、7、8 在计算 metric 的时候被 mask 掉了

手和脚上的 12 个关键点同 COCO,区别是 MPII 的 6-9,
- PoseTrack dataset
略
5.2 COCO Key-point Detection
1) Evaluation metric
评价指标是基于的 Object Key-point Similarity (OKS,相当于目标检测中的 IoU)
公式如下
O K S = ∑ i e x p ( − d i 2 / 2 s 2 k i 2 ) δ ( v i > 0 ) ∑ i δ ( v i > 0 ) OKS = \frac{\sum_i exp(-d_i^2 / 2 s^2k_i^2) \delta(v_i > 0)}{\sum_i \delta(v_i > 0)} OKS=∑iδ(vi>0)∑iexp(−di2/2s2ki2)δ(vi>0)
- d i d_i di 是 GT key-points 和预测的 key-points 之间的 Euclidean distance
- v i v_i vi 是 visibility faly
- k i k_i ki 是 constant 来 controls falloff(控制衰减,高斯分布中的 σ \sigma σ)
- s s s 是 object scale
更细节的解释可以参考(MS COCO 目标检测 、人体关键点检测评价指标)
2)Training
更据人的大小,crop 周围区域,形成 4:3 比例,然后 resize 成 256×192 or 384×288 的网络输入
data augmentation
- random rotation (-45,45)
- random scale (0.65,1.35)
- flipping
- half body data augmentation
3)Testing
两步走,detect the person instance using a person detector,and then predict detection keypoints
作者用论文 《Simple Baselines for Human Pose Estimation and Tracking》中方法(https://github.com/microsoft/human-pose-estimation.pytorch)来检测人,
flipping 的时候,会 avg flipping 图像和原图像生成的 heatmaps
4)Results on the validation set

作者网络 can benefit from
- ImageNet pre-train
- increasing the channels
- increasing the input size
5)Results on the test-dev set
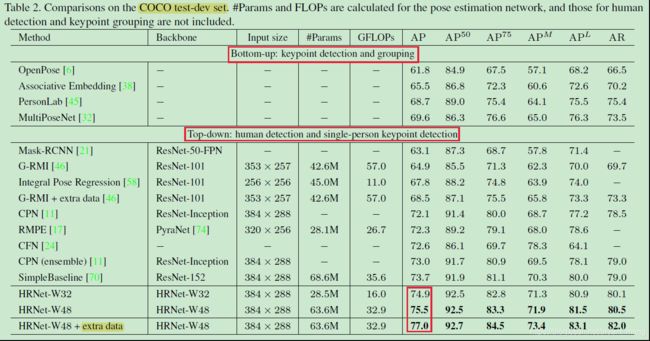
significantly better than bottom-up approaches

上述描述来自 人体关键点检测(姿态估计)简介+分类汇总
extra datasets 是 AI challenger
5.3 MPII Human Pose Estimation
1)Training
除了输入为 256×256,其余同在 MS COCO 上实验一样
2)Testing
同 MS COCO 数据集上的测试,只是,两步走中第一步,不 detected person boxes,而是 adopt the standard testing strategy to use the provided person boxes(a six-scale pyramid testing procedure is performed)
3)Evaluation metric
(head-normalized probability of correct keypoint) PCKh,细节可以参考 【HPM Block】《Binarized Convolutional Landmark Localizers for Human Pose Estimation and Face Alignment with Limited Resources》(ICCV-2017) 中的相关介绍
头部距离是 GT head bbox 斜对角线 60% 的长度
eg:
P C K h @ 0.5 : e r r o r 0.6 ∗ h e a d _ d i s t a n c e < 0.5 [email protected]:\frac{error}{0.6*head\_distance} < 0.5 PCKh@0.5:0.6∗head_distanceerror<0.5
还有个衡量起来更全面的评价指标,叫 [email protected],类似 AP 与 AP50 的关系,定义如下
M e a n @ 0.1 : P C K h @ 0.1 [email protected]: [email protected] Mean@0.1:PCKh@0.1~ P C K h @ 0.5 [email protected] PCKh@0.5,step is 0.01
3)Results on the test set
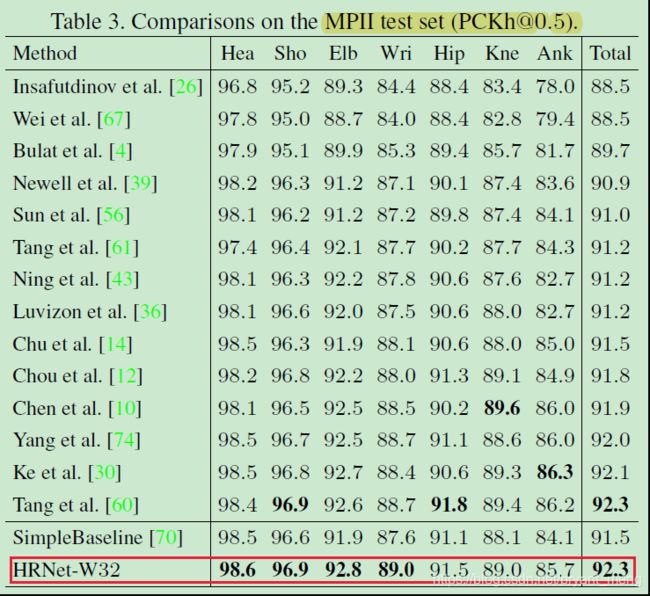

5.4 Application to Pose Tracking
略
5.5 Ablation Study
在 256×192 分辨率下
1)Repeated multi-scale fusion

充分交互效果最好
2)Resolution maintenance
分辨率的影响
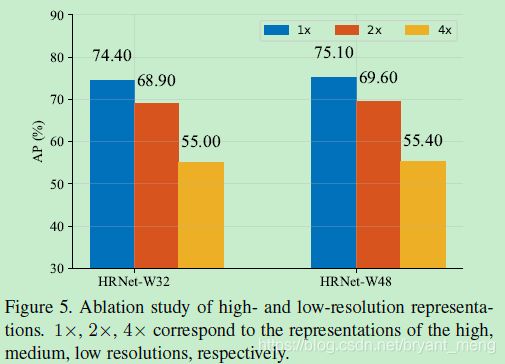
input size 的影响
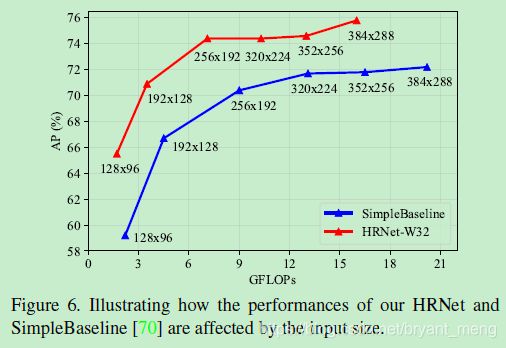
最后来感受下算法的魅力
6 Conclusion(own) / Future work
- Human pose estimation, a.k.a. key-point detection
- MPII 上测试,参考《Learning feature pyramids for human pose estimation》
- 《Simple Baselines for Human Pose Estimation and Tracking》先检测人,然后再关键点检测
- 注意下消融实验中 Resolution maintenance 的描述,阐述了 Fig 设计的 “苦衷”
- 未来工作,以更 light way 的方式来 investigation on aggregating multi-resolution representations
附录:作者的演讲
以下内容来自 HRNet:打通多个视觉任务的全能Backbone
HRNet是微软亚洲研究院的王井东老师领导的团队完成的,打通图像分类、图像分割、目标检测、人脸对齐、姿态识别、风格迁移、Image Inpainting、超分、optical flow、Depth estimation、边缘检测等网络结构。

完整演讲内容来自 微软亚洲研究院王井东:下一代视觉识别的通用网络结构是什么样的?
串联变并联
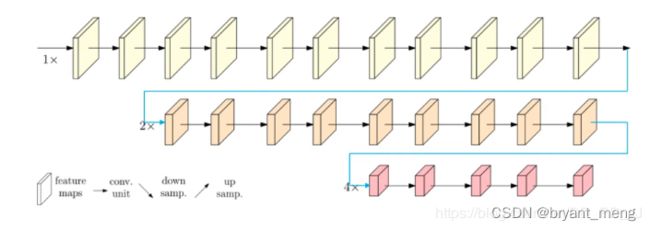

灵活应对各种任务
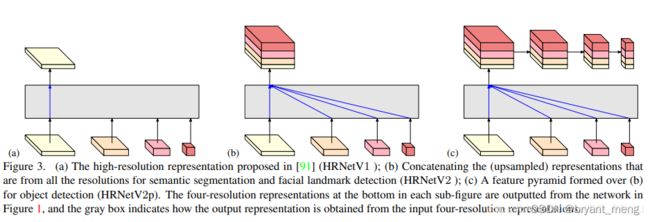
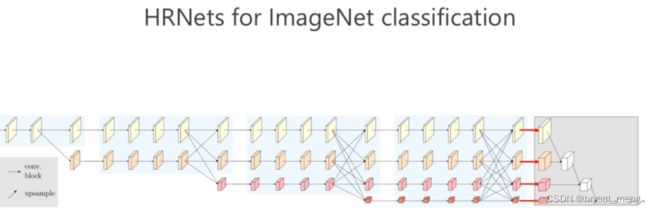
a )图展示的是HRNetV1的特征选择,只使用分辨率最高的特征图。
b) 图展示的是HRNetV2的特征选择,将所有分辨率的特征图(小的特征图进行upsample)进行concate,主要用于语义分割和面部关键点检测。
c) 图展示的是HRNetV2p的特征选择,在HRNetV2的基础上,使用了一个特征金字塔,主要用于目标检测网络。
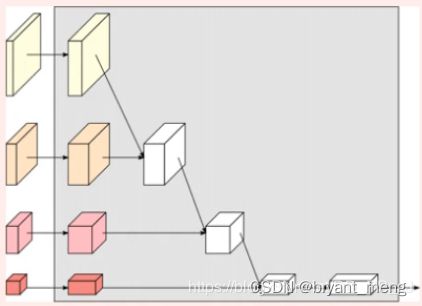
d)图展示的也是HRNetV2,采用上图的融合方式,主要用于训练分类网络。
也即
senet是hrnet的一个特例,hrnet不仅有通道注意力,同时也有空间注意力-- akkaze-郑安坤
啊,这……