【Tensorflow2.x学习笔记】- 神经网络
1.感知机
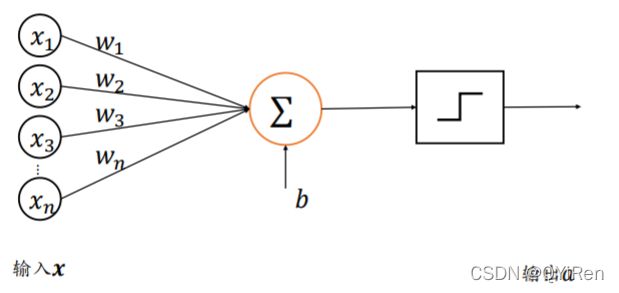
感知机模型结构如下所示,接受长度为n的一维向量
,每个输入节点通过权值为wi,i∈[1,n],的连接汇集为变量z,即:
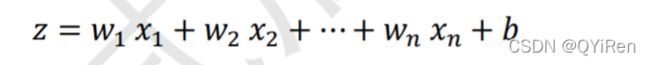
b称为感知机的偏置(bias);
一维向量 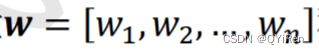 称为感知机的权值(Weight);
称为感知机的权值(Weight);
z称为感知机的净活性值(Net Activation);
向量模式:
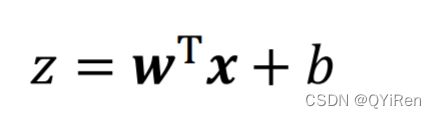
通过在线性模型后添加激活函数后得到活性值a:
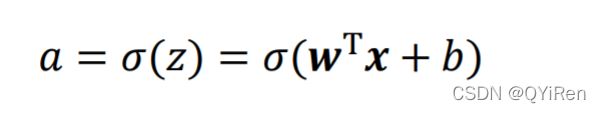
激活函数可以是阶跃函数:阶跃函数只有0、1两种数值
当z<0时输出0,代表类别0;
当z>=0时输出0,代表类别1;
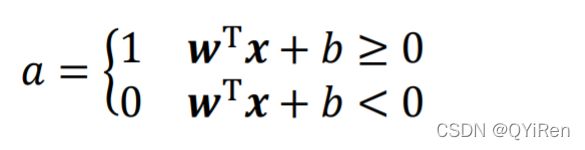
也可以是符号函数:
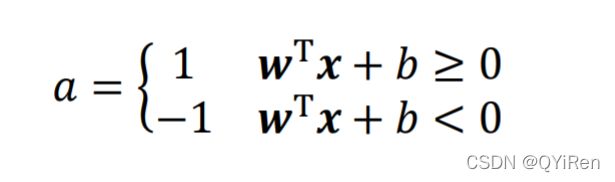
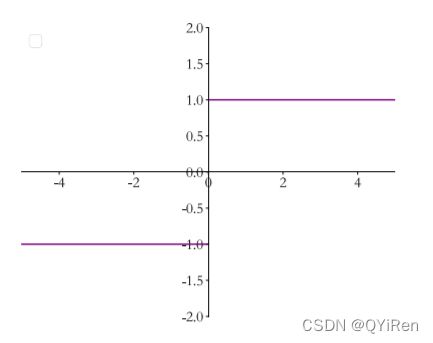
添加激活函数之后,感知机可以用来完成二分类任务。
阶跃函数和符号函数在z=0处是不连续的(不可导),其他位置导数为0,无法利用梯度下降法对参数进行优化。
感知机学习算法:

感知机是线性模型,并不能处理线性不可分问题。
2.全连接层
①全连接层
堆叠多个神经元实现多输入 、多输出的网络层结构,如下所示,并行堆叠2个神经元,即替换了激活函数的感知机,构成3个输入节点、2个输出节点的网络层。
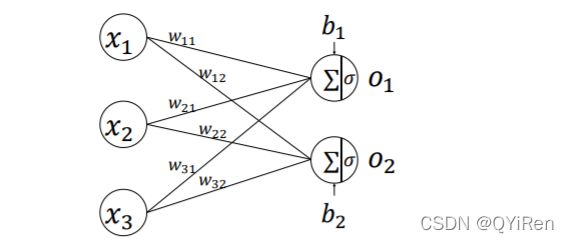
第一个输出节点的输出为:
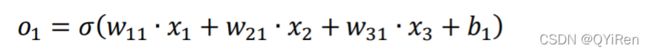
第一个输出节点的输出为:
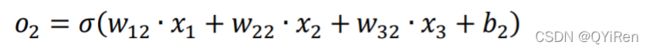
整个网络层可以通过矩阵关系表达:
输入矩阵X的shape:[b,din],b为样本数量,din为输入节点数;
权值矩阵W的shape:[din,dout],din为输入节点数,dout为输出节点数;
偏置b的shape:[dout],dout为输出节点数;

如果是2个样本:

每个输出节点与全部的输入节点相连接,这种网络层叫做全连接层(Fully-connectd Layer),或者稠密连接层
②张量方式实现
在 TensorFlow 中,要实现全连接层,只需要定义好权值张量和偏置张量,并利用 TensorFlow 提供的批量矩阵相乘函数 tf.matmul()即可完成网络层的计算。
例如,创建输入 矩阵为 = 2个样本,每个样本的输入特征长度为in = 784,输出节点数为out = 256,故 定义权值矩阵的 shape 为[784,256],并采用正态分布初始化;偏置向量的 shape 定义 为[256],在计算完@后相加即可,最终全连接层的输出的 shape 为[2,256],即 2 个样本的特征,每个特征长度为 256,代码实现如下:

③2层方式实现
全连接层本质上是矩阵的相乘和相加运算,实现并不复杂。
但是作为最常用的网络层之一,TensorFlow 中有更高层、使用更方便的层实现方式:
layers.Dense(units, activation)。
通过 layer.Dense 类,只需要指定输出节点数 Units 和激活函数类型 activation 即可。
注意:输入节点数会根据第一次运算时的输入 shape 确定,同时根据输入、输出节点数 自动创建并初始化权值张量和偏置张量,因此在新建类 Dense 实例时,并不会立即创 建权值张量和偏置张量,而是需要调用 build 函数或者直接进行一次前向计算,才能完成网络参数的创建。其中 activation 参数指定当前层的激活函数,可以为常见的激活函数或 自定义激活函数,也可以指定为 None,即无激活函数。例如:
上述通过一行代码即可以创建一层全连接层 fc,并指定输出节点数为 512,输入的节点数在fc(x)计算时自动获取,并创建内部权值张量和偏置张量。
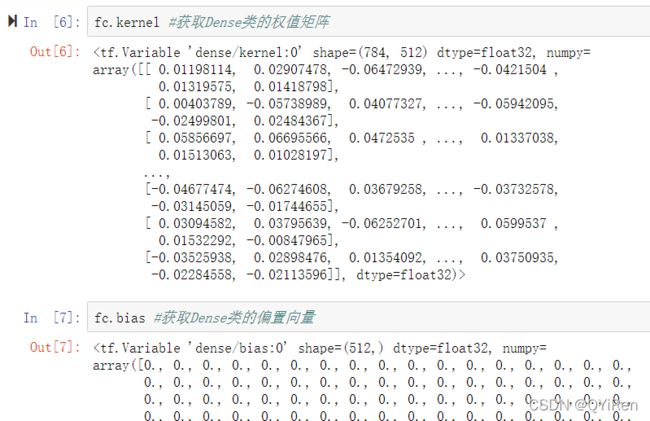
可以通过类内部的成员名 kernel 和 bias 来获取权值张量和偏置张量对象:
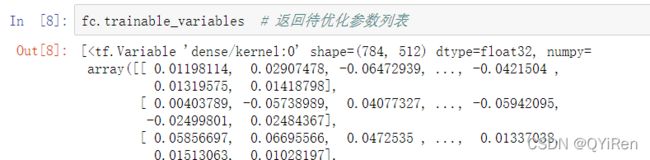
在优化参数时,需要获得网络的所有待优化的张量参数列表,可以通过类的 trainable_variables 来返回待优化参数列表,代码如下:
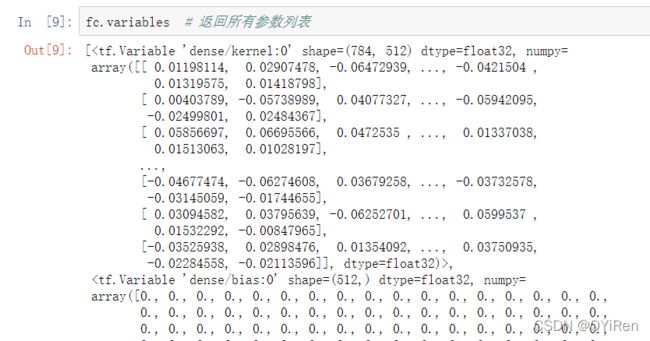
实际上,网络层除了保存了待优化张量列表 trainable_variables,还有部分层包含了不 参与梯度优化的张量,如后续介绍的 Batch Normalization 层,可以通过 non_trainable_variables 成员返回所有不需要优化的参数列表。如果希望获得所有参数列 表,可以通过类的 variables 返回所有内部张量列表,例如:
对于全连接层,内部张量都参与梯度优化,故 variables 返回的列表与 trainable_variables 相 同。
利用网络层类对象进行前向计算时,只需要调用类的__call__方法即可,即写成 fc(x) 方式便可,它会自动调用类的__call__方法,在__call__方法中会自动调用 call 方法,这一设定由 TensorFlow 框架自动完成,因此用户只需要将网络层的前向计算逻辑实现在 call 方 法中即可。对于全连接层类,在 call 方法中实现(@ + )的运算逻辑,非常简单,最后返回全连接层的输出张量即可。
3.神经网络
①神经网络
通过层层堆叠全连接层,保证前一层的输出节点数与当前层的输入节点数匹配,即可堆叠出任意层数的网络。我们把这种由神经元相互连接而成的网络叫做神经网络。
如图所示,通过堆叠 4 个全连接层,可以获得层数为 4 的神经网络,由于每层均为全连接层,称为全连接网络。
其中第 1~3 个全连接层在网络中间,称之为隐藏层 1、2、 3;
最后一个全连接层的输出作为网络的输出,称为输出层;
隐藏层 1、2、3 的输出节点数分别为[256,128,64],输出层的输出节点数为 10。
②张量方式实现
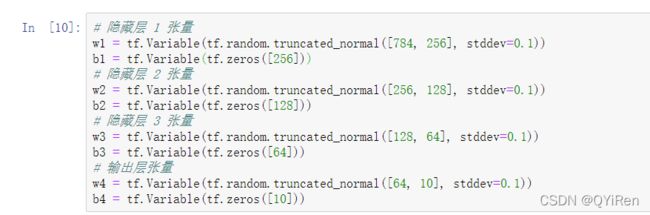
对于多层神经网络,以上图网络结构为例,需要分别定义各层的权值矩阵和偏置向量。
有多少个全连接层,则需要相应地定义数量相当的和,并且每层的参数只能用 于对应的层,不能混淆使用。
上图的网络模型实现如下:
在计算时,只需要按照网络层的顺序,将上一层的输出作为当前层的输入即可,重复 直至最后一层,并将输出层的输出作为网络的输出,代码如下:
在使用 TensorFlow 自动求导功能计算梯度时,需要将前向计算过程放置在 tf.GradientTape()环境中,从而利用 GradientTape 对象的 gradient()方法自动求解参数的梯 度,并利用 optimizers 对象更新参数。
③2层方式实现
对于常规的网络层,通过层方式实现起来更加简洁高效。首先新建各个网络层类,并 指定各层的激活函数类型:
对于这种数据依次向前传播的网络,也可以通过 Sequential 容器封装成一个网络大类对象,调用大类的前向计算函数一次即可完成所有层的前向计算,使用起来更加方便,实现如下:


④优化目标
神经网络从输入到输出的计算过程叫做前向传播(Forward Propagation)或前向计算。
神经网络的前向传播过程,也是数据张量(Tensor)从第一层流动(Flow)至输出层的过程,即从输入数据开始,途径每个隐藏层,直至得到输出并计算误差,这也是 TensorFlow 框架名字由来。
前向传播的最后一步就是完成误差的计算:
其中 (∙)代表了利用参数化的神经网络模型,(∙)称之为误差函数,用来描述当前网络的预测值()与真实标签之间的差距度量,比如常用的均方差误差函数。
ℒ称为网络的误差 (Error,或损失 Loss),一般为标量。
我们希望通过在训练集train上面学习到一组参数使得训练的误差ℒ最小:
上述的最小化优化问题一般采用误差反向传播(Backward Propagation,简称 BP)算法来求解 网络参数的梯度信息,并利用梯度下降(Gradient Descent,简称 GD)算法迭代更新参数:为学习率
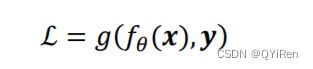
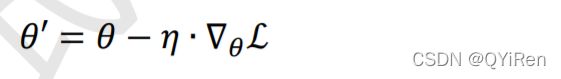
从另一个角度来理解神经网络,它完成的是特征的维度变换的功能,比如 4 层的 MNIST 手写数字图片识别的全连接网络,它依次完成了784 → 256 → 128 → 64 → 10的特 征降维过程。原始的特征通常具有较高的维度,包含了很多底层特征及无用信息,通过神经网络的层层特征变换,将较高的维度降维到较低的维度,此时的特征一般包含了与任务 强相关的高层抽象特征信息,通过对这些特征进行简单的逻辑判定即可完成特定的任务, 如图片的分类。
4.激活函数
①Sigmoid
Sigmoid 函数也叫 Logistic 函数,定义为:
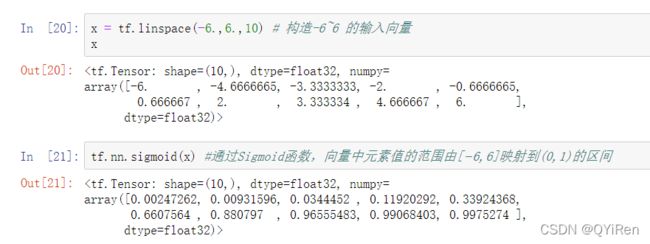
它的一个优良特性就是能够把 ∈ 的输入“压缩”到 ∈ (0,1)区间;
这个区间的数值在机器学习常用来表示以下意义:
❑ 概率分布 :(0,1)区间的输出和概率的分布范围[0,1]契合,可以通过 Sigmoid 函数将输出转译为概率输出;
❑ 信号强度:一般可以将 0~1 理解为某种信号的强度,如像素的颜色强度,1 代表当前通 道颜色最强,0 代表当前通道无颜色;抑或代表门控值(Gate)的强度,1 代表当前门控全部开放,0 代表门控关闭;
Sigmoid 函数连续可导,可以直接利用梯度下降算法优化网络参数
在 TensorFlow 中,可以通过 tf.nn.sigmoid 实现 Sigmoid 函数,代码如下:
缺点:容易出现梯度弥散现象,Sigmoid 函数在输入值较大或较小时容易出现梯度值接近于 0 的现象,称为梯度弥散现象。出现梯度弥散现象时,网络参数长时间得不到更新, 导致训练不收敛或停滞不动的现象发生,较深层次的网络模型中更容易出现梯度弥散现象。
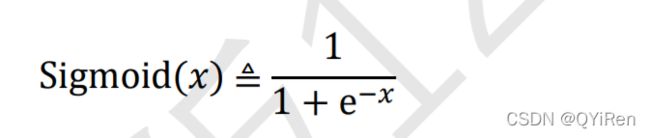

②ReLU
ReLU(REctified Linear Unit,修正线性单元)激活函数,定义:
函数图像:
ReLU 对小于 0 的值全部抑制为 0,对于正数则直接输出。
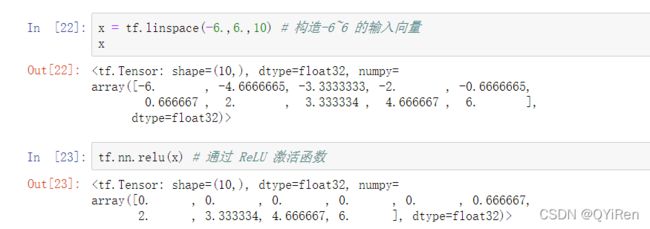
在 TensorFlow 中,可以通过 tf.nn.relu 实现 ReLU 函数,代码如下:
除了可以使用函数式接口 tf.nn.relu 实现 ReLU 函数外,还可以像 Dense 层一样将 ReLU 函数作为一个网络层添加到网络中,对应的类为 layers.ReLU()类。一般来说,激活 函数类并不是主要的网络运算层,不计入网络的层数。
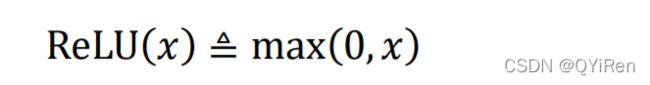

③LeakyReLU
ReLU 函数在 < 0时导数值恒为 0,也可能会造成梯度弥散现象,为了克服这个问 题,LeakyReLU 函数被提出,LeakyReLU 的表达式为:
其中为用户自行设置的某较小数值的超参数,如 0.02 等。当 = 0时,LeayReLU 函数退 化为 ReLU 函数;当 ≠ 0时, < 0处能够获得较小的导数值,从而避免出现梯度弥散现象。
在 TensorFlow 中,可以通过 tf.nn.leaky_relu 实现 LeakyReLU 函数,代码如下:
其中 alpha 参数代表
tf.nn.leaky_relu 对应的类为 layers.LeakyReLU,可以通过 LeakyReLU(alpha)创建 LeakyReLU 网络层,并设置参数,像 Dense 层一样将 LeakyReLU 层放置在网络的合适位置。
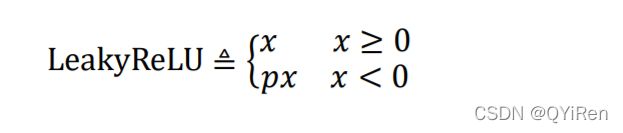

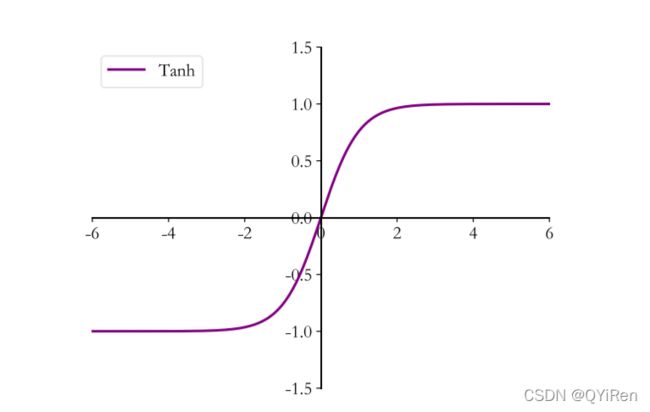
④Tanh
Tanh 函数能够将 ∈ 的输入“压缩”到(−1,1)区间,定义为:
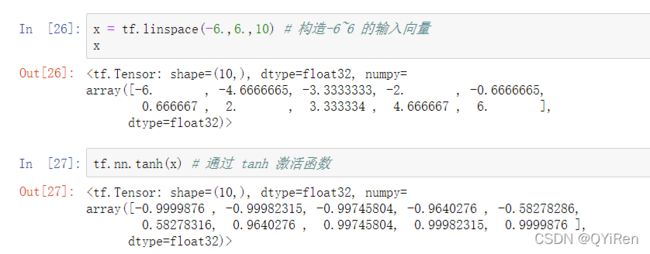
tanh 激活函数可通过 Sigmoid 函数缩放平移后实现,函数曲线如图所示:
在 TensorFlow 中,可以通过 tf.nn.tanh 实现 tanh 函数,代码如下:可以看到向量元素值的范围被映射到(−1,1)之间。
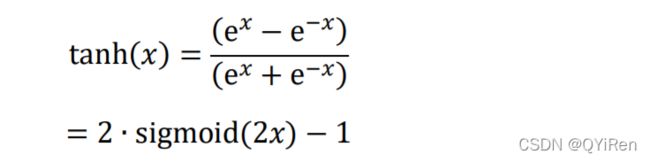
5.输出层设计
网络的最后一层的设计,它除了和所有的隐藏层一样,完成维度变换、特征提取的功能,还作为输出层使用,需要根据具体的任务场景来决定是否使用激活函数,以及使用什么类型的激活函数等。
常见的几种输出类型包括:
❑ ∈ 输出属于整个实数空间,或者某段普通的实数空间,比如函数值趋势的预 测,年龄的预测问题等。
❑ ∈ [0,1] 输出值特别地落在[0, 1]的区间,如图片生成,图片像素值一般用[0, 1]区间 的值表示;或者二分类问题的概率,如硬币正反面的概率预测问题。
❑ ∈ [0, 1], = 1 输出值落在[0,1]的区间,并且所有输出值之和为 1,常见的如 多分类问题,如 MNIST 手写数字图片识别,图片属于 10 个类别的概率之和应为 1。
❑ ∈ [−1, 1] 输出值在[-1, 1]之间
①普通实数空间
这一类问题比较普遍,像正弦函数曲线预测、年龄的预测、股票走势的预测等都属于 整个或者部分连续的实数空间,输出层可以不加激活函数。
误差的计算直接基于最后一层 的输出和真实值进行计算,如采用均方差误差函数度量输出值与真实值之间的距离:其中代表了某个具体的误差计算函数,例如 MSE 等。
②[0,1]区间
输出值属于[0,1]区间也比较常见,比如图片的生成、二分类问题等。
在机器学习中, 一般会将图片的像素值归一化到[0,1]区间,如果直接使用输出层的值,像素的值范围会分 布在整个实数空间。为了让像素的值范围映射到[0,1]的有效实数空间,需要在输出层后添 加某个合适的激活函数,其中 Sigmoid 函数刚好具有此功能。
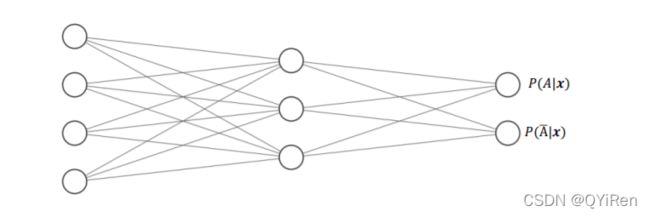
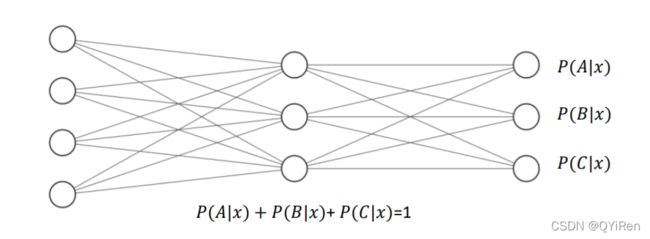
同样地,对于二分类问题,如硬币的正反面的预测,输出层可以只设置一个节点, 表示某个事件 A 发生的概率(A|),为网络输入。如果我们利用网络的输出标量表示正 面事件出现的概率,那么反面事件出现的概率即为1 − ,网络结构如图所示:
对于二分类问题,除了可以使用单个输出节点表示事件 A 发生的概率(A|)外,还可以分别预测(A|)和(A̅|),并满足约束 (A|) + (A̅|) = 1:

③[0,1]区间,和为1
输出值 ∈ [0,1],且所有输出值之和为 1,这种设定以多分类问题最为常见。
可以通过在输出层添加 Softmax 函数实现。Softmax 函数定义为:
Softmax 函数不仅可以将输出值映射到[0,1]区间,还满足所有的输出值之和为 1 的特性。
如:
在 TensorFlow 中,可以通过 tf.nn.softmax 实现 Softmax 函数,代码如下:
与 Dense 层类似,Softmax 函数也可以作为网络层类使用,通过类 layers.Softmax(axis=-1) 可以方便添加 Softmax 层,其中 axis 参数指定需要进行计算的维度。
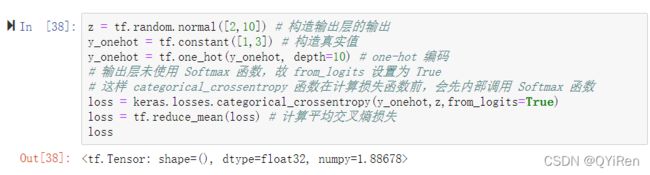
在 Softmax 函数的数值计算过程中,容易因输入值偏大发生数值溢出现象;在计算交 叉熵时,也会出现数值溢出的问题。为了数值计算的稳定性,TensorFlow 中提供了一个统 一的接口,将 Softmax 与交叉熵损失函数同时实现,同时也处理了数值不稳定的异常,一 般推荐使用这些接口函数,避免分开使用 Softmax 函数与交叉熵损失函数。
函数式接口为 tf.keras.losses.categorical_crossentropy(y_true, y_pred, from_logits=False),其中 y_true 代表了 One-hot 编码后的真实标签,y_pred 表示网络的预测值,当 from_logits 设置为 True 时, y_pred 表示须为未经过 Softmax 函数的变量 z;当 from_logits 设置为 False 时,y_pred 表示 为经过 Softmax 函数的输出。为了数值计算稳定性,一般设置 from_logits 为 True,此时 tf.keras.losses.categorical_crossentropy 将在内部进行 Softmax 函数计算,所以不需要在模型中显式调用 Softmax 函数,例如:
除了函数式接口,也可以利用 losses.CategoricalCrossentropy(from_logits)类方式同时实 现 Softmax 与交叉熵损失函数的计算,from_logits 参数的设置方式相同。例如:



④[-1,1]
如果希望输出值的范围分布在(−1,1)区间,可以简单地使用 tanh 激活函数,实现如下:

输出层的设计具有一定的灵活性,可以根据实际的应用场景自行设计,充分利用现有激活函数的特性。
6.误差计算
常见的误差函数 有均方差、交叉熵、KL 散度、Hinge Loss 函数等,其中均方差函数和交叉熵函数在深度学习中比较常见,均方差函数主要用于回归问题,交叉熵函数主要用于分类问题。
①均方误差函数(MSE)
均方差(Mean Squared Error,简称 MSE)误差函数把输出向量和真实向量映射到笛卡尔坐标系的两个点上,通过计算这两个点之间的欧式距离(准确地说是欧式距离的平方)来衡量两个向量之间的差距:
MSE 误差函数的值总是大于等于 0,当 MSE 函数达到最小值 0 时,输出等于真实标签, 此时神经网络的参数达到最优状态。
在 TensorFlow 中,可以通过函数方式或层方式实现 MSE 误差计算。如:
MSE 函数返回的是每个样本的均方差,需要在样本维度上再次平均来获得平均样本的均方差,实现如下:
通过层方式实现,对应的类为 keras.losses.MeanSquaredError(),和其他层的类一 样,调用__call__函数即可完成前向计算,代码如下:




②交叉熵误差函数
信息学中熵(Entropy)的概念:1948 年,Claude Shannon 将热力学中熵的概念引入到信息论中,用来衡量信息的不确定度。熵在信息学科中也叫信息熵,或者香农熵。熵越大,代表不确定性越大,信息量也就越大。某个分布()的熵定义为:
例子:对于 4 分类问题,如果某个样本的真实标签是第 4 类,那么标签的 One-hot 编码为[0,0,0,1],即这张图片的分类是唯一确定的,它属于第 4 类的概率(为 4|) = 1,不确定性为 0,它的熵可以简单的计算为:
−0 ∙ log2 0 − 0 ∙ log2 0 − 0 ∙ log2 0 − 1 ∙ log2 1 = 0
也就是说,对于确定的分布,熵为 0,不确定性最低。
如果它预测的概率分布是[0.1,0.1,0.1,0.7],它的熵可以计算为:
−0.1 ∙ log2 0.1 − 0.1 ∙ log2 0.1 − 0.1 ∙ log2 0.1 − 0.7 ∙ log2 0.7 ≈ 1.356
分类问题的 One-hot 编码的分布就是熵为 0 的典型例子
在 TensorFlow 中 间,我们可以利用 tf.math.log 来计算熵
基于熵引出交叉熵(Cross Entropy)的定义:
通过变换,交叉熵可以分解为的熵()和与的 KL 散度(Kullback-Leibler Divergence)的和:
KL定义为:
KL 散度是 Solomon Kullback 和 Richard A. Leibler 在 1951 年提出的用于衡量 2 个分布之间 距离的指标。 = 时,(||)取得最小值 0,与之间的差距越大,(||)也越 大。需要注意的是,交叉熵和 KL 散度都不是对称的,即:
交叉熵可以很好地衡量 2 个分布之间的“距离”。特别地,当分类问题中 y 的编码分布 采用 One-hot 编码时:() = 0,此时:
退化到真实标签分布与输出概率分布之间的 KL 散度上。
根据 KL 散度的定义,我们推导分类问题中交叉熵的计算表达式:
其中为 One-hot 编码中为 1 的索引号,也是当前输入的真实类别。可以看到,ℒ只与真实 类别上的概率有关,对应概率越大,(||)越小。当对应类别上的概率为 1 时,交叉 熵(||)取得最小值 0,此时网络输出与真实标签完全一致,神经网络取得最优状态。
因此最小化交叉熵损失函数的过程也是最大化正确类别的预测概率的过程。
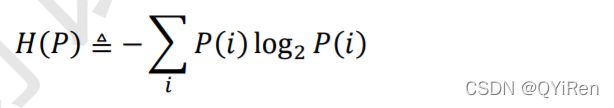

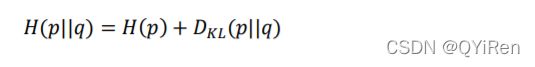

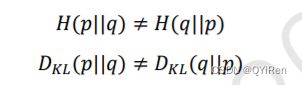
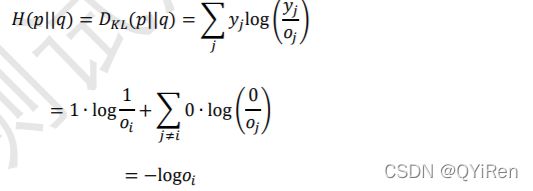
7.神经网络类型
①卷积神经网络(CNN)
如何识别、分析并理解图片、视频等数据是计算机视觉的一个核心问题,全连接层在 处理高维度的图片、视频数据时往往出现网络参数量巨大,训练非常困难的问题。通过利用局部相关性和权值共享的思想,Yann Lecun 在 1986 年提出了卷积神经网络 (Convolutional Neural Network,简称 CNN)。随着深度学习的兴盛,卷积神经网络在计算机视觉中的表现大大地超越了其它算法模型,呈现统治计算机视觉领域之势。这其中比较流 行的模型有用于图片分类的 AlexNet、VGG、GoogLeNet、ResNet、DenseNet 等,用于目标识别的 RCNN、Fast RCNN、Faster RCNN、Mask RCNN、YOLO、SSD 等。
②循环神经网络(RNN)
除了具有空间结构的图片、视频等数据外,序列信号也是非常常见的一种数据类型, 其中一个最具代表性的序列信号就是文本数据。如何处理并理解文本数据是自然语言处理的一个核心问题。卷积神经网络由于缺乏 Memory 机制和处理不定长序列信号的能力,并不擅长序列信号的任务。循环神经网络(Recurrent Neural Network,简称 RNN)在 Yoshua Bengio、Jürgen Schmidhuber 等人的持续研究下,被证明非常擅长处理序列信号。1997 年,Jürgen Schmidhuber 提出了 LSTM 网络,作为 RNN 的变种,它较好地克服了 RNN 缺乏长期记忆、不擅长处理长序列的问题,在自然语言处理中得到了广泛的应用。基于 LSTM 模型,Google 提出了用于机器翻译的 Seq2Seq 模型,并成功商用于谷歌神经机器翻 译系统(GNMT)。其他的 RNN 变种还有 GRU、双向 RNN 等。
③注意力(机制)网络(AMN)
RNN 并不是自然语言处理的最终解决方案,近年来随着注意力机制(Attention Mechanism)的提出,克服了 RNN 训练不稳定、难以并行化等缺陷,在自然语言处理和图片生成等领域中逐渐崭露头角。注意力机制最初在图片分类任务上提出,但逐渐开始侵蚀 NLP 各大任务。2017 年,Google 提出了第一个利用纯注意力机制实现的网络模型 Transformer,随后基于 Transformer 模型相继提出了一系列的用于机器翻译的注意力网络模 型,如 GPT、BERT、GPT-2 等。在其它领域,基于注意力机制,尤其是自注意力(SelfAttention)机制构建的网络也取得了不错的效果,比如基于自注意力机制的 BigGAN 模型 等。
④图卷积神经网络(GCN)
图片、文本等数据具有规则的空间、时间结构,称为 Euclidean Data(欧几里德数据)。 卷积神经网络和循环神经网络被证明非常擅长处理这种类型的数据。而像类似于社交网络、通信网络、蛋白质分子结构等一系列的不规则空间拓扑结构的数据,它们显得力不从 心。2016 年,Thomas Kipf 等人基于前人在一阶近似的谱卷积算法上提出了图卷积网络 (Graph Convolution Network,GCN)模型。GCN 算法实现简单,从空间一阶邻居信息聚合的角度也能直观地理解,在半监督任务上取得了不错效果。随后,一系列的网络模型相继被提出,如 GAT,EdgeConv,DeepGCN 等。