R生成三线表
R生成三线表
- table1包
-
-
- 测试数据生成
- 制作三线表
-
- Tableone包
-
-
- 加载包 探索数据类型
- 数据整理分类
- 构建Table函数
- Tableone函数细节
-
主要基于table1 或tableone 包
table1包
测试数据生成
data=data.frame(
性别=sample(c("男","女"), 1000,replace=T),
年龄=round(rnorm(1000,50, 15)),
民族= sample(c("汉族","壮族","其他"),1000,replace=T),
身高= round(rnorm(1000,170, 5)),
体重= round(rnorm(1000,75, 5)),
收缩压= round(rnorm(1000,130, 15)),
舒张压= round(rnorm(1000,90, 5)),
身体状况= sample(c("优","中","差"), 1000,replace=T),
高血压= sample(c("是","否"), 1000,replace=T),
吸烟= sample(c("是","否"), 1000,replace=T),
喝酒= sample(c("是","否"), 1000,replace=T)
)
head(data)
#运行内容
性别 年龄 民族 身高 体重 收缩压 舒张压 身体状况 高血压 吸烟 喝酒
1 女 65 壮族 176 67 149 82 差 否 否 否
2 女 84 其他 177 73 137 92 差 是 是 是
3 男 75 其他 168 82 111 90 优 是 是 否
4 男 67 其他 171 76 152 93 差 是 是 否
5 男 67 壮族 172 73 118 83 优 否 否 是
6 男 44 壮族 168 82 141 83 优 是 否 是
制作三线表
基本三线表, 分类变量默认以 例数(占比%),连续变量以均数(标准差)或者中位数[最小、最大]表示
pacman::p_load(table1) #加载table1包
# ~ 后面接需要统计描述的列,| 表示分组
# 按是否患有高血压分组统计 性别、年龄、民族、身高情况
table1(~性别+年龄+民族+身高|高血压,data = data)

考虑统计检验(卡方检验、t检验)
#———————————————————————————————————————————— 定义检验函数
# 这两个主要是实现卡方检验和t检验,若是需要用到非参数检验、方差分析需要自己定义
pvalue <- function(x, ...) {
y <- unlist(x)
g <- factor(rep(1:length(x), times=sapply(x, length)))
if (is.numeric(y)) {
# 数值型数据用t-test(两组比较)
p <- t.test(y ~ g)$p.value
} else {
# 因子型数据用卡方
p <- chisq.test(xtabs(~y+ g))$p.value
}
c("", sub("<", "<", format.pval(p, digits=3, eps=0.001)))
}
statistic <- function(x, ...) {
y <- unlist(x)
g <- factor(rep(1:length(x), times=sapply(x, length)))
if (is.numeric(y)) {
statistic <- t.test(y ~ g)$statistic
} else {
statistic <- chisq.test(xtabs(~y+ g))$statistic
}
c("",round(statistic,3))
}
#———————————————————————————————————————————— 三线表
# 输出带有统计检验的三线表
# 分别比较是否患有高血压两组之间所有特征的差异~
table1(~.|高血压,data = data, extra.col=list( 'statistic'=statistic,'P-value'=pvalue), overall=F)
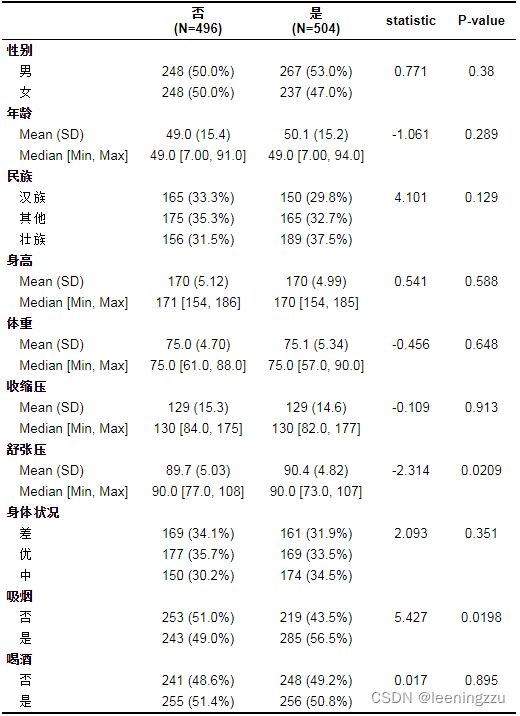
table1输出的结果格式是html格式的,可用浏览器打开,然后复制到word或者excel中。也直接导出保存为csv格式,导出时格式可能略微有点不同。
out=table1(~.|高血压,data = data, extra.col=list( 'statistic'=statistic,'P-value'=pvalue), overall=F)
write.csv(out, "d:/out.csv",row.names = F)
Tableone包
加载包 探索数据类型
pacman::p_load(tableone)#1.加载R包
rm(list = ls()) #2.清理运行环境
str(data) #3.查看数据数据性质
names(data) #4.提取变量的名字
#运行内容
'data.frame': 1000 obs. of 11 variables:
$ 性别 : chr "女" "女" "男" "男" ...
$ 年龄 : num 65 84 75 67 67 44 50 64 44 47 ...
$ 民族 : chr "壮族" "其他" "其他" "其他" ...
$ 身高 : num 176 177 168 171 172 168 169 165 164 163 ...
$ 体重 : num 67 73 82 76 73 82 82 79 69 83 ...
$ 收缩压 : num 149 137 111 152 118 141 131 118 123 135 ...
$ 舒张压 : num 82 92 90 93 83 83 90 91 91 91 ...
$ 身体状况: chr "差" "差" "优" "差" ...
$ 高血压 : chr "否" "是" "是" "是" ...
$ 吸烟 : chr "否" "是" "是" "是" ...
$ 喝酒 : chr "否" "是" "否" "否" ...
> names(data) #4.提取变量的名字
[1] "性别" "年龄" "民族" "身高" "体重" "收缩压" "舒张压" "身体状况" "高血压" "吸烟" "喝酒"
数据整理分类
myVars的()中输入想要在Table 1出现的变量
myVars <- c("性别","年龄","民族","身高",
"体重","收缩压", "舒张压","身体状况","高血压",
"吸烟","喝酒")
catVars的()内指明上述中哪些是分类变量
catVars <- c("性别","民族","身体状况","高血压",
"吸烟","喝酒")
指定非正态分布连续变量变量
nonvar <- c("收缩压","舒张压") #此为举例
假如有T<5变量应使用Fisher精确检验,本文数量大,无需Fisher精确检验
exactvars <- c("a", "b") #此为举例
catDigits = 2, contDigits = 3, pDigits = 4,修改连续变量小数位数为2位,分类变量百分比位数为3位,调整小数位数为4位;
构建Table函数
table <- CreateTableOne(vars = myVars, #条件1
factorVars = catVars,#条件2
strata = "高血压", #条件4 用于分为两个类别
data = data, #原始数据
addOverall = TRUE );table#条件6加入overall
table1<- print(table, #构建的table函数(带条件1.2.3)
nonnormal = nonvar,#条件4
#exact = exactvars,#条件5
catDigits = 2,contDigits = 3,pDigits = 4, #附加条件
showAllLevels=TRUE, #显示所有变量
quote = FALSE, # 不显示引号
noSpaces = TRUE, # #删除用于对齐的空格
printToggle = TRUE) #展示输出结果
write.csv(table1, "E:/Rworkplace//table1.csv",row.names = F)
Tableone函数细节
table <- CreateTableOne(
vars, #指定哪些变量是Table 1需要汇总的变量
strata,#指定进行分类的变量,不写则只出Overall列
data,# 变量的数据集名称
factorVars,#指定哪些变量为分类变量,指定的变量应是vars参数中的变量
includeNA = FALSE,#为TRUE则将缺失值作为因子处理,仅对分类变量有效
test = TRUE,#默认为TRUE,当有2个或多个组时,自动进行组间比较
testApprox = chisq.test,#默认卡方检验
argsApprox = list(correct = TRUE),# 进行连续校正的chisq.test
testExact = fisher.test,#进行fisher精确检验
argsExact = list(workspace = 2 * 10^5),# 指定fisher.test分配的内存空间
testNormal = oneway.test, # 连续变量为正态分布进行的检验,默认为oneway.test,两组时相当于t检验
argsNormal = list(var.equal = TRUE), # 假设为等方差分析
testNonNormal = kruskal.test,# 默认为Kruskal-Wallis秩和检验
argsNonNormal = list(NULL),#传递给testNonNormal中指定的函数的参数的命名列表
smd = TRUE,#如果为TRUE(如默认值)并且有两个以上的组,则将计算所有成对比较的标准化均值差。
addOverall = FALSE#仅在分组时使用)将整个列添加到表中。Smd和p值计算仅使用分层的列阵进行。
);table
table1<- print(
x, #CreateTableOne()的 <- 前的名字(x=table)
catDigits = 1, #连续变量小数位1位
contDigits = 2,#分类变量保留2位
pDigits = 3,#p值保留3位
quote = FALSE,#默认值为FALSE。如果为TRUE
#,则包括行名和列名在内的所有内容都用引号引起来,以便您可以轻松地将其复制到Excel。
missing = FALSE,#是否显示丢失的数据信息
explain = TRUE,#显示百分比时是否在变量名称中添加解释,即(%)添加到变量名称中。
printToggle = TRUE,#如果为FALSE,则不输出
test = TRUE,#是否显示p值。默认为TRUE。
smd = FALSE,#是否显示标准化均值差异。默认为FALSE。如果存在多个对比,则显示所有可能的标准化均值差的平均值。
noSpaces = FALSE,#是否删除为对齐而添加的空格。
padColnames = FALSE,#是否用空格填充列名以居中对齐。默认值为FALSE。如果noSpaces = TRUE,则不进行
varLabels = FALSE,#是否用从labelled :: var_label()函数获得的变量标签替换变量名。
format = c("fp", "f", "p", "pf")[1],#默认值为“ fp”频率(百分比)。您也可以选择仅“ f”频率,“仅p”百分比和“ pf”百分比(频率)。
showAllLevels = FALSE,#是否显示所有级别。
cramVars = NULL,#字符向量,用于指定两个级别的分类变量,对于这两个级别的变量,应在一行中显示两个级别。
dropEqual = FALSE,#是否删除“ =第二级名称”描述,指示为两级分类变量显示哪个级别。
exact = NULL,#字符向量,用于指定p值应为精确测试值的变量。
nonnormal = NULL,#字符向量,用于指定p值应为非参数检验的变量的变量。
minMax = FALSE#对于非正态变量,是否使用[min,max]而不是[p25,p75]。默认值为FALSE。
)
相比之下 table1包输出的html格式的表格更为简洁 好看
参考两篇公众号文章:
1.你的时间应该用在更重要的事情上–table1
2.R语言|4. 轻松绘制临床基线表Table 1