【YOLOv2】《YOLO9000:Better, Faster, Stronger》


CVPR-2017
部分整理参考 YOLO:YOLOv1,YOLOv2,YOLOv3,TinyYOLO,YOLOv4,YOLOv5详解
文章目录
- 1 Background and Motivation
- 2 Advantages / Contributions
- 3 Method
-
- 3.1 Better
-
- 3.1.1 Batch normalization
- 3.1.2 High Resolution Classifier
- 3.1.3 Convolutional With Anchor Boxes
- 3.1.4 Dimension Clusters
- 3.1.5 Direct location prediction
- 3.1.6 Fine-Grained Features
- 3.1.7 Multi-Scale Training
- 3.1.8 Further Experiments
- 3.2 Faster
- 3.3 Stronger
- 4 Conclusion(own)
1 Background and Motivation
目前的目标检测数据集与其他视觉任务数据集如分类和 tagging 相比还是很有限的!
目标检测标注成本太高,数据集难以大规模的扩充!
作者提出 combine 分类和目标检测数据集的方法,配合设计的 joint training algorithm,实现了能检测 9000 个类别的目标检测器 YOLOv2(stronger)
YOLOv2 的结构基于 YOLOv1 改进,会 better and Faster
2 Advantages / Contributions
-
PASCAL VOC 上比 SSD 和 faster RCNN 更快更强(COCO 上 mAP.5 有一定竞争力)
-
未知类别的目标检测性能显著提升
3 Method
1)升级 YOLO -> YOLO v2
YOLO 缺点定位不准,recall 较低
2)dataset combination method(WordTree)
Our method uses a hierarchical view of object classification that allows us to combine distinct datasets together.
3)joint training algorithm
We also propose a joint training algorithm that allows us to train object detectors on both detection and classification data.
用检测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性
3.1 Better
3.1.1 Batch normalization
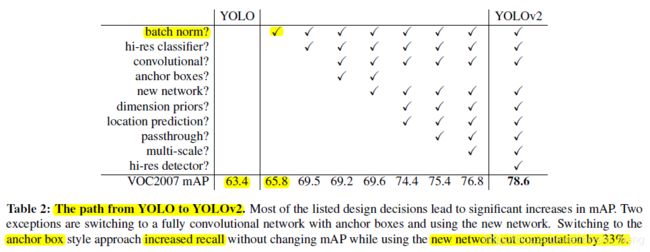
2% 的提升
3.1.2 High Resolution Classifier

原来 1)224×224分辨率跑 ImageNet 上预训练,2)448x448 跑 detection
现在在 1)和2)之间 fine tune the classification network at the full 448×448 resolution for 10 epochs on ImageNet
结果提升 4 个点
3.1.3 Convolutional With Anchor Boxes
1)把 fc 换成 conv 来预测 bbox
2)借鉴 Faster RCNN 的 RPN anchor 那套,anchor 数量 more than a thousand,比原来 7×7×2 多得多,在每个 grid 预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度
3)448 输入改为 416(输出 13×13,为奇数,这样能确保有一个 cell 中心,因为很多大目标 tend to occupy the center of the image,一个中心比四个中心要好——网络好学一点)
4)去掉一个 pooling 维持 feature 的 high resolution(原来是 448->7,64 down sampling,现在 416->13,32 倍)


区别于 YOLOv1 每个 priors 都有 class probability and objectness
mAP 69.5 掉到了 69.2,recall 从 81% 提升到了 88%
3.1.4 Dimension Clusters
K-means clustering on the training set bounding boxes to automatically find good priors.
通过 k-means 聚类找比较好的 anchor priors(aspect ratio 和 scale)
聚类的距离计算方式为

因为简单的使用 Euclidean distance 会受 bbox 的 scale 影响

anchor 为 5 有较好的 recall vs complexity trade-off
下面对比了 faster rcnn 和 cluster prior 的效果,同数量下 cluster 比较猛

3.1.5 Direct location prediction
我们先回顾下 RCNN 的 bbox 预测

G _ G\_ G_ 是网络预测出的 bbox 在原图中的位置, P _ P\_ P_ 是设定好的 anchor, d _ ( P ) d\_(P) d_(P) 是网络 prediction 出的基于 anchor 的 offset
d _ ( P ) d\_(P) d_(P) 的约束力不够,任意位置的 anchor P,都可以负责预测 bbox
(This formulation is unconstrained so any anchor box can end up at any point in the image, regardless of what location predicted the box)
这使得网络早期的训练会变得 instability
作者给 d _ ( P ) d\_(P) d_(P) 加了个约束,限制 offset 的范围只能在一个 cell 的长宽内,而不是整个原图的 h w 内
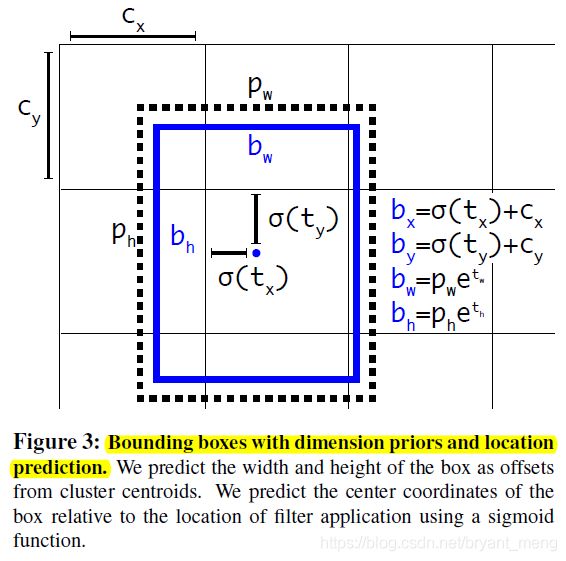

这里的 b _ b\_ b_ 就是 RCNN 公式中的 G _ G\_ G_, p _ p\_ p_ 对应 P _ P\_ P_, t _ t\_ t_ 对应 d _ ( p ) d\_(p) d_(p)
c x c_x cx 和 c y c_y cy 是当前 grid 的左上角到整张图像左上角的距离

dimension priors(cluster) 配合 location predictions 比 anchor boxes 好了 5%
3.1.6 Fine-Grained Features
来一条 pass through
26 × 26 × 512 -> 13 × 13 × 2048 concatenate 到 13 × 13 分辨率的特征图上
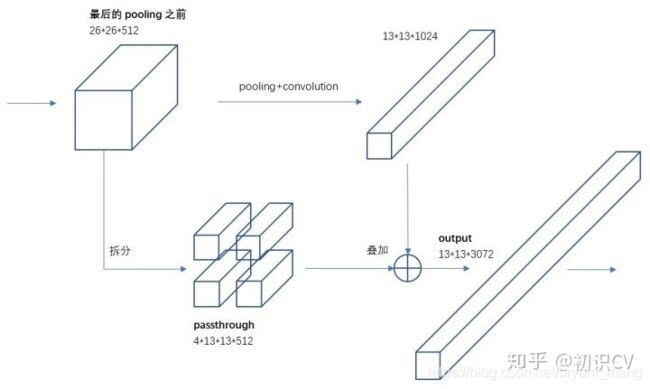
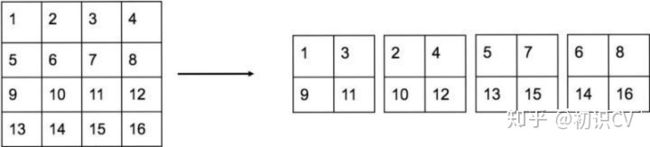
具体拆分方法如下
看看效果

有一个点的 提升
3.1.7 Multi-Scale Training
每10个Batch,网络会随机地选择一个新的图片尺寸
320 × 320 ~ 608 × 608

VOC 2007 上和别的方法对比下

速度精度都超越了 SSD
3.1.8 Further Experiments
VOC 12

COCO

还是 SSD 比较猛,YOLOV2 AP.5 有一战之力
3.2 Faster
Darknet-19

YOLOV1 的 backbone 8.52 billion operations,88% top5 acc on ImageNet
YOLOV2 的 backbone Darknet-19 5,58 billion operations 91.2% top5 (224 分辨率)
448 分辨率 fine tune 后 top5 升到了 93.3%
3.3 Stronger
Stronger 指的是识别的更多的意思
合并目标检测和分类数据集,难点在于,目标检测的 label 比较 general(狗),分类的 label 更 wider and deeper(二哈,中华田园犬)
1)Dataset combination with WordTree
从 WordNet graph 中抽出来 WordNet tree
dog
- hunting dog
- terrier
- Norfolk terrier
- Yorkshire terrier

好处 Performance degrades gracefully on new or unknown object categories
- terrier

例如,如果网络看到一张狗的图片,但不确定它是哪种狗,它仍然会以较高的置信度预测出“狗”,但置信度较低的分布在 hyponyms (具体某种品种的狗)中。
2)Joint classification and detection
目标检测数据集 propagate full YOLOv2 loss
分类数据集 propagate loss from the classification specific parts of architecture
计算类别概率的方式如下

某个节点的概率值等于该节点到根节点的所有条件概率之积

目标检测时,沿着 tree 走,到叶子节点的概率最大的那个类就是要预测出的类
如果标签是“狗”,assign any error to predictions further down in the tree(预测出“二哈”或者“中华田园犬”都是错的)
缺点

4 Conclusion(own)
- 一个 cell 5 个 anchor box,每个 box (5 + 20) 类
- High Resolution Classifier
- WordTree
- 采用多尺度训练,可以多种输入下共用一个 model