基于神经网络的机器阅读理解综述学习笔记
基于神经网络的机器阅读理解综述学习笔记
一、机器阅读理解的任务定义
1、问题描述
机器阅读理解任务可以形式化成一个有监督的学习问题:给出三元组形式的训练数据(C,Q,A),其中,C 表示段落,Q 表示与之相关的问题,A 表示对应的答案。我们的目标是学习一个预测器 f,能够将相关段落 C 与问题 Q作为输入,返回一个对应的答案 A 作为输出:
f : ( C , Q ) → A f:(C,Q)\rightarrow A f:(C,Q)→A
一般地,我们将段落表示为 C={w1C,w2C,w3C,…,wmC} ,将问题表示为 Q={w1Q,w2Q,w3Q,…,wmQ} ,其中,m 和 n 分别为段落 C 的长度和问题 Q 的长度,所有 w 都属于预先定义的词典V。由于数据集的类型不同,问题和答案会被表示成不同的形式, 6 种类型中具有代表性的数据集:CBT、SciQ、SquAD、CoQA、NarrativeQA以及HotpotQA。具体地,可以将数据集定义为以下 6 种类型。
- 完形填空:在这类数据集中,机器的目标是根据问题和当前段落,从预定义的选项集合ࣛ中选出正确答案 a,并填入问题的空白处;
- 多项选择:在这类数据集中,机器的目标是根据问题和当前段落信息,从包含正确答案的 k(k 一般为 4)个设定的选项集合A={a1,…,ak}中选出正确答案 a,a 可以是一个单词、一个短语甚至一个句子;
- 抽取式:也可称为跨距预测类型数据集(span prediction),在这类数据集中,机器的目标是根据问题在当前段落中找到正确的答案跨距,因此在这类数据集中,我们可以将答案表示为(astart,aend),其中,1≤astart≤aend≤m;
- 会话:在这类数据集中,目标与机器进行交互式问答,因此,答案可以是文本自由形式(free-text form),即可以是跨距形式,可以是“不可回答”形式,也可以是“是/否”形式等等;
- 生成式:在这类数据集中,问题的答案都是人工编辑生成的(human manual generated),不一定会以片段的形式出现在段落原文中,机器的目标是阅读给出段落的摘要甚至全文,之后根据自身的理解来生成问题的答案;
- 多跳推理:在这类数据集中,问题的答案无法从单一段落或文档中直接获取,而是需要结合多个段落进行链式推理才能得到答案。因此,机器的目标是在充分理解问题的基础上从若干文档或段落中进行多步推理,最终返回正确答案。
2、评价指标
机器阅读理解中对于模型的评价指标主要由数据集的类型决定。
-
对于完形填空和多项选择类型的任务,由于答案都是来源于已经给定的选项集合,因此使用Accuracy 这一指标最能直接反映模型的性能,即,在问题数据中模型给出的正确答案数 n 占总问题 m 的百分比:
A c c u r a c y = n m Accuracy=\frac{n}{m} Accuracy=mn -
对于抽取式和多跳推理类型的任务,需要对模型预测的答案字符串和真实答案进行比对,因此一般使用 Rajpurkar 等人提出的 **Exact Match(EM)**和 F1 值,以及两者结合得到最终的联合 EM 和 F1 值(joint EM,F1) 。
-
EM 是指数据集中模型预测的答案与标准答案相同的百分比;
-
F1 值是指数据集中模型预测的答案和标准答案之间的平均单词的覆盖率,P 代表准确率(precision),R 代表召回率(recall);
-
(joint EM,F1):
F 1 = 2 × P × R ( P + R ) F1=\frac{2\times P\times R}{(P+R)} F1=(P+R)2×P×R
-
-
对于会话类型的任务,由于其答案是文本自由形式,因此并没有一种通用的评价指标,该类任务的评价指标主要由数据集本身决定。
-
对于生成式类型的任务,由于答案是人工编辑生成的,而机器的目标是使生成的答案最大限度地拟合人工生成的答案,因此该类任务一般使用机器翻译任务中常用的 BLEU-4和 Rouge-L两种指标。
-
BLEU 的本质是依靠计算共现词频率来判断机器生成答案和人工编辑答案的相似或接近程度,在这里,BLEU-4 指的是采用四元精度(4-gram precision)对原始的 BLEU 算法进行改进后的版本(N=4),其中,BP 是惩罚因子:
P n = ∑ C ∈ { C a n d i d a t e s } ∑ n − g r a m ∈ C C o u n t c l i p ( n − g r a m ) ∑ C ~ ∈ { C a n d i d a t e s } ∑ n − g r a m ′ ′ ∈ C ~ C o u n t c l i p ( n − g r a m ′ ′ ) P_n=\frac{\sum\limits_{C\in \{Candidates\}}\sum\limits_{n-gram\in C}Count_{clip}(n-gram)}{\sum\limits_{\tilde{C}\in \{Candidates\}}\sum\limits_{n-gram''\in \tilde{C}}Count_{clip}(n-gram'')} Pn=C~∈{Candidates}∑n−gram′′∈C~∑Countclip(n−gram′′)C∈{Candidates}∑n−gram∈C∑Countclip(n−gram)B P = { 1 , c > r e 1 − r c , c ⩽ r BP=\left\{\begin{array}{rcl}1,c>r\\ e^{1-{\frac{r}{c}}},c\leqslant r \end{array}\right. BP={1,c>re1−cr,c⩽r
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log P n ) BLEU=BP\cdot \exp(\sum\limits_{n=1}^{N}w_n\log P_n) BLEU=BP⋅exp(n=1∑NwnlogPn)
-
Rouge-L 是采用了最长公共子序列(longest common subsequence,简称 LCS)的 Rouge 的一种改进版本,其中,X 表示长度为 m 的正确答案,Y 为模型生成的长度为 n 的答案 :
R l c s = L C S ( X , Y ) m R_{lcs}=\frac{LCS(X,Y)}{m} Rlcs=mLCS(X,Y)P l c s = L C S ( X , Y ) n P_{lcs}=\frac{LCS(X,Y)}{n} Plcs=nLCS(X,Y)
F l c s = ( 1 + β ) 2 R l c s P l c s R l c s + β 2 P l c s F_{lcs}=\frac{(1+\beta)^2R_{lcs}P_{lcs}}{R_{lcs}+\beta ^2P_{lcs}} Flcs=Rlcs+β2Plcs(1+β)2RlcsPlcs
-
二、基于神经网络的机器阅读理解架构
基于端到端神经网络的机器阅读理解模型大都采用如下图所示的 4 层架构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
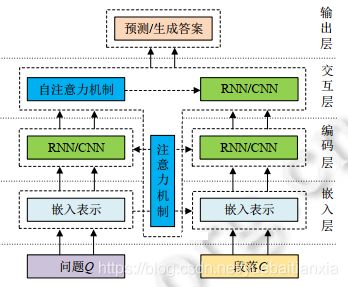
- 嵌入层:通过字符、词、上下文和特征级别的嵌入方法将段落 C 和问题 Q 表示为 d 维的词向量作为模型的输入;也有一些模型在嵌入层采用注意力机制将问题的词向量信息融入段落的词向量之中作为段落的最终输入;
- 编码层:使用循环或卷积神经网络对段落和问题序列进行编码,用以提取内部特征;之后采用注意力机制生成问题感知的段落表示或段落感知的问题表示;
- 交互层:通过自注意力机制捕捉融合了问题(段落)信息的段落(问题)单词之间的信息;最后通过循环或卷积神经网络解码形成最终表示;
- 输出层:根据最终任务(数据集)类型的不同,输出层将会有不同的表示方式。
1、嵌入层(embedding layer)
- 字符嵌入(character embedding):字符嵌入用来获取一个单词在字符级别的向量表示,采用 char-level 的词向量能够在一定程度上缓解文本中出现未登录词(out-of-vocabulary,简称OOV)的问题。
- 词嵌入(word embedding) :词向量能够基于单词的分布式假设,从大规模无标签的文本语料库中学习获得。在机器阅读理解任务中,使用最多的是 Word2Vec、GloVe 以及 Fasttext 这 3 种单词级别的嵌入模型 :
- Word2Vec词向量本质上是利用一个浅层的神经网络模型在大规模数据集上进行训练得到的结果,该模型具体可以分为连续词袋模型(continuous bag-of-word,简称 CBoW)以及跳跃元语法模型(skip-gram)两种:前者是从上下文对目标单词的预测中学习词向量;后者则相反,是从目标单词对其上下文的预测中学习词向量;
- GloVe 词向量 :为了填补 Word2Vec 的局限性,提出了一种结合局部上下文窗口和全局矩阵分解方法的全局对数双线性回归模型(global log-bilinaer regression model),即 GloVe 模型;
- Fasttext 词向量本质上是 Fasttext 快速文本分类算法的副产物,该模型的提出,旨在解决 Word2Vec 和GloVe 模型忽略单词内部结构,从而导致词的形态学特征缺失的问题;
- 上下文嵌入(contextualized embedding) :将词的表征扩展到上下文级别,将每个单词表示为整个输入句子的函数映射,即根据当前的句子来体现一个词在特定上下文的语境里面该词的语义表示,使其动态地蕴含句子中上下文单词的特征,从而提高模型的性能。目前较为流行的用于上下文级别嵌入的模型有 CoVe、ELMo 以及 BERT等预训练模型。
- 特征嵌入(feature embedding) :特征嵌入本质上就是将单词在句子中的一些固有特征表示成低维度的向量,包括单词的位置特征(position)、词性特征(POS)、命名实体识别特征(NER)、完全匹配特征(em)以及标准化术语频率(NTF)等等,一般会通过拼接的方式将其与字符嵌入、词嵌入、上下文嵌入一起作为最后的词表征。
2、编码层(encoder layer)
编码层的目的是将已经表示为词向量的 Tokens(词的唯一标记单位)通过一些复合函数进一步学习其内在的特征与关联信息,机器阅读理解中常用循环神经网络(recurrent neural networks,简称 RNNs)及其变体对问题和段落进行建模编码,也有一些模型使用卷积神经网络(convolutional neural network,简称 CNN)进行特征提取。
- 循环神经网络(RNN/LSTM/GRU):循环神经网络是神经网络的一种,主要用来处理可变长度的序列数据。不同于前馈神经网络,RNNs 可以利用其内部的记忆来处理任意时序的输入序列,这使得它更容易处理机器阅读理解数据集中的问题和段落序列。
- 长短期记忆网络(long short-term memory,简称 LSTM) :为了优化传统 RNN 模型的性能(例如解决 RNN 出现的梯度消失问题),研究者们提出了许多 RNN 的变体,其中比较著名且常用的变体有 LSTM 和门控循环单元(gated recurrent unit,简称 GRU)。在 MRC 甚至整个 NLP 领域的应用中,LSTM 是最具有竞争性且使用最为广泛的RNN 变体。
- 卷积神经网络(CNN) 利用 CNN 模型善于提取文本局部特征的优点,同时采用自注意力机制来弥补 CNN 模型无法对句子中单词的全局交互信息进行捕捉的劣势。 但总体而言,CNN 模型在 MRC 任务中仍使用较少。
3、交互层(interaction layer)
交互层是整个神经阅读理解模型的核心部分,它的主要作用是负责段落与问题之间的逐字交互,从而获取段落(问题)中的单词针对于问题(段落)中的单词的加权状态,进一步融合已经被编码的段落与问题序列。
-
注意力机制(attention mechanism)
交互层主要采用注意力机制,在自然语言处理领域,该机制最早由 Sutskever 等人在 2014 年应用于Sequence-to-Sequence 模型(Seq2Seq);随后,Luong 等人和 Bahdanau 等人将其应用于机器翻译领域并获得极大的成功;这之后,注意力机制被广泛应用于各种 NLP 任务中,包括机器阅读理解任务。
如下图所示:在 MRC 任务中,一般使用注意力机制来融合“段落和问题”的信息。图左为以段落-问题为例的注意力矩阵表示,图右为注意力矩阵中每一行注意力值(即段落中每一单词对问题的注意力)的详细计算方法,具体地,可以分为以下 3 步:
-
将段落 C 中的单词 Cj,j=1,…,m 和问题 Q 中的每一个单词 Q1,…,Qi,…,Qn 进行相似度计算,得到权重Sj1,…,Sji,…,Sjn,其中,相似度函数可以有多种选择,常用的有点积 dot、双线性映射 bilinear 以及多层感知机 MLP:
S j i = { f d o t ( C j , Q i ) = C j T Q i f b i l i n e a r ( C j , Q i ) = C j T W Q i f M L P ( C j , Q i ) = V T tanh ( W C C j + W Q Q i ) S_{ji}=\left\{\begin{array}{rcl}f_{dot}(C_j,Q_i)&=&C^T_jQ_i\\ f_{bilinear}(C_j,Q_i)&=&C^T_jWQ_i\\f_{MLP}(C_j,Q_i)&=&V^T\tanh(W^CC_j+W^QQ_i) \end{array}\right. Sji=⎩⎨⎧fdot(Cj,Qi)fbilinear(Cj,Qi)fMLP(Cj,Qi)===CjTQiCjTWQiVTtanh(WCCj+WQQi) -
使用 Softmax 函数对权重进行归一化处理,得到αj1,…,αji,…,αjn:
α j i = s o f t m a x ( S j i ) = exp ( S j i ) ∑ i = 1 n exp ( S j i ) \alpha_{ji}=softmax(S_{ji})=\frac{\exp(S_{ji})}{\sum^n_{i=1}\exp(S_ji)} αji=softmax(Sji)=∑i=1nexp(Sji)exp(Sji) -
将归一化后的权重和相应的问题 Q 中的单词 Qi 进行加权求和,得到序列 ,即问题-感知的段落表示:
C j ^ = A t t e n t i o n ( C j , Q ) = ∑ i = 1 n α j i Q i \hat{C_j}=Attention(C_j,Q)=\sum^n_{i=1}\alpha_{ji}Q_i Cj^=Attention(Cj,Q)=i=1∑nαjiQi

-
-
自注意力机制(self-attention mechanism)
Vaswani 等人提出了自注意力机制(self-attention mechanism),并基于多头自注意力机制(multi-head self-attention)提出了 Transformer 模型架构,该架构用注意力机制完全替代了 RNN 模型,使得整个模型的参数大大减少并且弥补了 RNN 模型并行性差的缺点。
4、输出层(output layer)
输出层主要用来实现答案的预测与生成,根据具体任务来定义需要预测的参数。
- 针对抽取式任务,神经阅读理解模型需要从某一段落中找到一个子片段(span or sub-phrase)来回答对应问题,这一片段将会以在段落中的首尾索引的形式表示,因此,模型需要通过获取起始和结束位置的概率分布来找到对应的索引。
- 针对完形填空任务,神经阅读理解模型需要从若干个答案选项中选择一项填入问句的空缺部分,因此,模型首先需要计算出段落针对问题的注意力值,然后通过获取选项集合中候选答案的概率预测出正确答案。
- 针对多项选择任务,神经阅读理解模型需要从 k 个选项中选出正确答案,因此,模型可以先通过 BiLSTM将每一个答案进行编码得到 ai,之后与 u 进行相似度对比,预测出正确的答案。
- 针对生成式任务,由于答案的形式是自由的(free-form),可能在段落中能找到,也可能无法直接找到而需要模型生成,因此,模型的输出不是固定形式的,有可能依赖预测起止位置的概率(与抽取式相同),也有可能需要模型产生自由形式的答案(类似于 Seq2Seq)。
- 针对会话类和多跳推理任务,由于只是推理过程与抽取式不同,其输出形式基本上与抽取式任务相同,有些数据集还会预测“是/否”、不可回答以及“能否成为支持证据”的概率。
- 针对开放域的阅读理解,由于模型首先需要根据给定问题,从例如 Wikipedia 上检索多个相关文档(包含多个段落),再从中阅读并给出答案。
5、BERT预训练模型
Devlin 等人提出了将ELMo 和 GPT 模型结合的 BERT 预训练模型。采用遮蔽语言模型(masked LM)的方法来解决完全双向编码机制隐含的“自己看见自己”的问题,同时,采用连续句子预测(next sentence prediction)的方法将模型的适用范围从单词级别扩展到句子级别,这两项创新也使得 BERT 预训练模型能够充分利用并挖掘海量的语料库信息,从而大幅度提升包括机器阅读理解在内的 11 项下游任务的性能。
-
Transformer 架构由 6 个相同的编码-解码模块组成,其中,每个编码模块包括了自注意力模块(self attention)和前向神经网络模块(feed forward neural network),每个解码模块包括了自注意力模块、编码-解码注意力模块(encoder-decoder attention)和前向神经网络模块,而其中,自注意力模块采用了多头注意力机制(multiheaded attention),即采用 h 个不同的自注意力进行集成,多次并行地通过缩放点积(scaled dot-product)来计算注意力值,如下列公式与下图所示,其中,dk 为 K 的维度:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k V ) Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}}V) Attention(Q,K,V)=softmax(dkQKTV)M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中
h e a d i = A t t e n t i o n ( Q W i Q K W i K V W i V ) head_i=Attention(QW_i^QKW_i^KVW_i^V) headi=Attention(QWiQKWiKVWiV)

Transformer 架构的两个优势:
- 由于 Transformer 架构不需要循环处理单词序列,因此训练速度比 RNN 结构快很多;
- 采用自注意力机制不仅能够让句子中单词与单词之间产生关联,还能通过权重系数计算出哪些单词之间的关联性更大,提高了模型的可解释性。
Transformer 架构另一个里程碑式的创新之处在于:为基于海量未标记语料训练的预训练模型的构建提供了支持,进而使研究者们只需在对应的下游任务中微调预训练模型就能达到较好的效果。其中最具代表性的应用就是通过基于 Transformer 架构的预训练模型来提升词表达能力:通过自注意力机制,可以在一定程度上反映出一句话中不同单词之间的关联性以及重要程度,再通过训练来调整每个词的重要性(即权重系数),由此来获得每个单词的表达。由于这个表达不仅仅蕴含了该单词本身,还动态地蕴含了句子中其他单词的关系,因此相比于普通的词向量,通过上述预训练模型得到的上下文词表达更为全面。
-
遮蔽语言模型 :Devlin 等人受完形填空任务的启发,提出了采用 Masked LM 的方式来训练模型。他们将输入 Tokens 中的 15%进行随机遮蔽处理,用[MASK]标记替代;进一步地,他们为了解决预训练模型中若完全使用[MASK]标记则会导致后续任务不能很好地进行模型微调的问题(因为后续任务微调中并不会出现[MASK]这一标记),进行了如下图所示的改变。

通过上述变化,使得 Transformer 架构不知道哪个单词需要被预测,哪个单词已经被替换。因此,BERT 不仅解决了完全双向模型“自己看见自己”的问题,还“被迫”地保证了每一个输入 Token 都能保持分布式的上下文表征状态。
-
连续句子预测 :连续句子预测任务主要是为了让模型能够学习连续的文本片段之间的关系,以加入句子级别的表征能力。具体地说,对于每次从训练集中选取的两个连续句子 A 和 B,Devlin 等人将句子 B 做以下处理:在训练时,输入模型的第 2 个句子 B 会以 50%的概率从全部文本中随机选取替换,剩下 50%的概率选取第 1 个句子 A 的后续的文本,即保持原句不变。
-
综上所述,BERT 模型的提出,对于机器阅读理解任务来说,除了为建立更高性能的模型提供新的思路以外,更是证明了一个好的预训练模型在 MRC 任务中的重要性。因此,未来 MRC 模型的建立可以从以下两方面展开:
- 加入上下文嵌入作为表征。将 BERT 预训练模型得到的词的上下文表征结合静态词嵌入方法,共同作为嵌入层的结果,以此来提高模型性能,这也是目前 BERT 模型最广泛的使用方法;
- 优化 BERT 模型。由于单一的 BERT 模型对于需要复杂推理的任务处理起来相对薄弱,因此我们可以在 BERT 模型的基础上进行结构优化,提高模型对问题与段落内在关系的推理能力,由此来处理更为复杂、推理难度更大的 MRC 数据集。
三、数据集及神经网络模型相关研究
1、MRC 主要数据集以及模型发展时间线
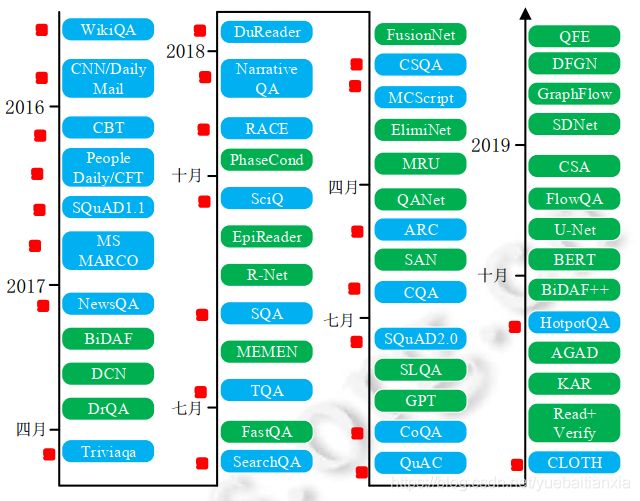
如下图所示(蓝色为数据集,绿色为模型),在最近 3 年的时间里,MRC领域的发展就已经取得了惊人的成绩(所有数据集和模型都已经以论文形式发表在国际会议或 arXiv 上,截至日期为 2019.7.18)。
2、数据集分类与分析
从 2015 年至今,国内外已经公布了许多专门用于机器阅读理解的数据集,本文选取最具有代表性的 24 个中英文数据集进行对比分析,各个数据集的属性见下表:

3、神经网络模型分析
机器阅读理解数据集难度的不断提升,也推动着神经阅读理解模型的发展。本文选取了 27 个具有代表性的神经阅读理解模型,并按时间线顺序进行了归纳对比,见下表:
其中:
-
所有模型都是原论文中的基本模型;
-
应用场景包含了原论文中提到的数据集以及特定数据集发布时使用该模型作为 Baseline 的场景;
-
上下文在这里指的是预训练词向量的上下文嵌入,不包括网络结构中对问题和文章的上下文编码;
-
CNN 在这里特指架构中使用的神经网络模型,不包含 Char-Level 嵌入中使用的 CNN。

词向量表示
模型的不同词向量表示对性能的改变(部分)见下表:

神经网络模型
每一种模型的创新点以及在数据集上的性能归纳于下表:

四、总结与研究展望
1、问题与挑战
- 模型缺乏深层次的推理能力,现有模型仅仅是做到了更完善、更复杂的浅层次匹配,对于段落与问题之间内在蕴意的深层推理能力仍非常薄弱;
- 模型的鲁棒性与泛化能力太差,在段落末尾加入一些无关句子(distracting sentence),这些句子与问题会有一些单词重叠但不影响答案的正确性,这时,当前的模型性能就会急剧下降近一半;而当这些句子是不符合语法的单词序列时,模型的性能会进一步下降,这说明,现有的模型鲁棒性太差,一旦数据集带有噪声,其性能就会急剧下降,导致无法将该模型部署到实际应用中;
- 对于模型来说,是表征重要还是架构重要,我们究竟该如何平衡两者之间的关系,在利用好 BERT 的同时思考如何优化网络架构,从而进一步提升基于 BERT 的模型的性能,而不是仅仅把 BERT 当成提高模型性能的唯一方法?这在未来仍然是一个问题;
- 模型的可解释性太差 , 现有模型对最后答案的预测并没有提供充分的理论依据,即目前端到端神经网络的黑盒模型弊端在神经阅读理解模型中仍然存在,这会降低模型使用者对其的信任程度,从而难以在例如医学、法律这些敏感领域进行实际应用部署。
2、未来研究方向
-
构建更贴近人类自然语言习惯的数据集;
-
构建兼具速度与性能的模型;
-
在训练中融入对抗实例,以提高模型的鲁棒性与泛化能力:
未来研究中,我们需要考虑如何在训练过程中加入对抗实例以提高模型的鲁棒性,从而使模型在具有噪声的数据集上也能保持一定的性能;此外,如何将迁移学习(transfer learning)和多任务学习(multi-task learning)应用到神经网络模型中,构建跨数据集的高性能模型,也是未来的研究方向;
-
提高模型的可解释性,未来研究中,我们可以在构建数据集时加入支持证据,让模型在每一次预测时提供相关证明;此外,尝试在构建模型时加入原理生成模块(rationales generating),让模型在预测答案之前优先给出对应的理由,也是未来的研究方向。
3、个人认为发展重点——多跳推理
多跳推理类别数据集是最近 1 年才兴起的,其代表为 Yang 等人在 2018 年 9 月 25日提出的 HotpotQA 数据集。与其他数据集的区别是:
- HotpotQA 中问题的答案需要模型从多个支持段落中找到相关句子并进行推理得到;
- 增加了新的评价指标 F1(sup),用以评价模型找到正确支持证据的能力,这一点非常重要,因为现有模型最大的不足就是缺乏可解释性,即知道答案却不知如何知道答案,提供支持证据可以让机器更加接近人类的思维。因此在未来的研究中,多跳推理任务必然会成为国内外机器阅读理解研究的趋势。
参考文献
[1] 顾迎捷,桂小林,李德福,等.基于神经网络的机器阅读理解综述[J].软件学报,2020(7):2095-2126.