【CS231n assignment 2022】Assignment 3 - Part 3,Transformer
前言
- 博客主页:睡晚不猿序程
- ⌚首发时间:2022.8.19
- ⏰最近更新时间:2022.8.19
- 本文由 睡晚不猿序程 原创,首发于 CSDN
- 作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
相关文章目录 :
- 【CS231n assignment 2022】Assignment 2 - Part 1,全连接网络的初始化以及正反向传播
- 【CS231n assignment 2022】Assignment 2 - Part 2,优化器,批归一化以及层归一化
- 【CS231n assignment 2022】Assignment 3 - Part 1,RNN
- 【CS231n assignment 2022】Assignment 3 - Part 2,LSTM
文章目录
- 前言
- 1. 内容简介
- 2. Transformer
-
- 2.1 Transformer 结构
- 2.2 多头注意力机制
- 2.3 小总结
- 3. Transformer for Image Captioning
-
- 3.1 Transformer: Multi-Headed Attention
- 3.2 Positional Encoding
- 3.3 Transformer for Image Captioning
- 3. 总结、预告
1. 内容简介
上一次作业我们完成了 RNN 以及其变种 LSTM,在这次作业中我们将会完成 Transformer,这也是最近几年在 CV 领域用的非常广泛的模型。
2. Transformer
要完成作业,首先需要理解模型,笔者为了理解 Transformer,在作业做到这里之前就已经有看了很多的视频和博客讲述 Transformer 和它的各种变种了,笔者在这里会很感性的讲述一下 Transformer ,因为作者感觉,在作业解答博客中插入大段大段的理论解读不是很现实
2.1 Transformer 结构
首先我们先来看一下 Transformer 的结构图

我愿意称这张图为:Transformer——从入门到直接放弃
我用嘴巴来讲一下这个结构:
首先,Transformer 最开始是应用在 NLP 中的,他的论文《Attention is all you need》中,使用 Transformer 来进行不同语言的翻译,在翻译任务中,一般会采取编码器-解码器的结构,和我们上次的两个作业类似
- 编码器(左):把输入的词语变成词向量,然后将其编码
- 解码器(右):输入编码信息,然后进行解码,然后输出
Transformer,也就是变形金刚,变形金刚 ~ 随时变形状 ~ ~
我们可以把他想象成,我们输入一个句子,这个句子输入编码器,编码器会把他打散成为零件,接着零件被丢给解码器,解码器会通过说明书,把零件重新组装成句子
我们可以把他脑补成擎天柱变成大卡车的过程~
2.2 多头注意力机制
我这里的描述都会非常的感性,非常浅薄,如果要深入学习,一定要去查阅相关文章!!!
首先我们来讲一下注意力机制,一般来说都会有三个向量来表示,也就是 Q,K,V(Querry,Key,Value),我们可以把数据库的思想放到这里,我们要查询的东西为Q,它的关键字(主键)Key,其值为 Value
Transformer 中,编码器解码器的多头注意力有些许的区别,我先进行讲解然后补充,首先是编码器的
输入数据进行词嵌入转化成向量,然后进行位置嵌入,到这里输入数据就准备完毕了,准备输入的编码器
接下来注意力机制(单头):
- 进行线性变换,有三个线性变换,把输入分别变成了Q,K,V矩阵
- Q,K矩阵计算相关性,得到一个和 V 大小相同的矩阵
- 得到的矩阵和 V 进行相乘,得到经过注意力机制的输出
注意力可以让模型明白,翻译的时候,要更关注哪一部分的信息,比如翻译:“ Xiaoming,he like dog”,翻译 he 的时候,模型可能会更关注”Xiaoming“,因为此时 he 代指小明。让模型可以完成这种操作,就是依靠注意力机制
多头注意力:
多头注意力是单头注意力的拓展,单头注意力只有三个线性变换参数,也就是 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV,用来生成三个矩阵
而多头注意力也是有三个线性变换,但是每个线性变换用一组参数来生成多个矩阵,比如论文中提出的多头注意力机制,每个变换由8个参数组成,生成8个矩阵,最后矩阵进行拼接,得到最后的注意力输出
讲人话:用只用一个参数来进行映射,也就是说我只用一个工人来干活,有可能不靠谱,如果我用八个工人来干活,那么一个不靠谱那也就无所谓啦
带 mask 的多头注意力:
这个是解码器中需要的,因为我们在训练的时候,我们是把整个训练数据一次性输入进去的
这时候,训练解码器时,一整个句子输入进去,会导致解码器看到原先不应该看到的数据
- 因为翻译的时候,解码器应该是串行运行的,应该通过上一次的输出和当前的输入判断下一个输入
- 但是训练时候是并行的,我们一次性输入的句子如果送入注意力机制,那么就会出现错误,因为编码器提前看到了答案,这就麻烦了
- 所以我们要把接下来的输入遮盖掉,也就是利用一个上三角矩阵来掩盖
2.3 小总结
我在这里对 Transformer 做了一个感性又简短的总结,如果有哪里讲解有问题请大家一定要 tt 我
菜鸡作者也不知道自己的理解会不会有偏差
但是,总而言之,这是一个必须掌握的模型
3. Transformer for Image Captioning
我们正式开始我们的作业吧!手撸 Tr
好吧这次不用手撸了,这次我们大部分都会用到 Pytorch 来实现 Tr 的主要部分
我们在之前的实验可以看出,RNN 非常的强力,但是训练比较慢(因为它的训练是串行的)并且在训练长序列的数据的时候很难。Tr 一下子解决了这两个痛点:
- 并行训练
- 可以学习一个长序列的问题
好了,让我们开始吧
3.1 Transformer: Multi-Headed Attention
一上来我们就要完成多头注意力机制,首先先阅读一下作业给的详解吧~
这里的多头注意力机制继承了nn.Module类,我们现在来看一下它的初始化参数
def __init__(self, embed_dim, num_heads, dropout=0.1):
"""
Construct a new MultiHeadAttention layer.
Inputs:
- embed_dim: Dimension of the token embedding
- num_heads: Number of attention heads
- dropout: Dropout probability
"""
super().__init__()
assert embed_dim % num_heads == 0
# We will initialize these layers for you, since swapping the ordering
# would affect the random number generation (and therefore your exact
# outputs relative to the autograder). Note that the layers use a bias
# term, but this isn't strictly necessary (and varies by
# implementation).
self.key = nn.Linear(embed_dim, embed_dim)
self.query = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.proj = nn.Linear(embed_dim, embed_dim)
self.attn_drop = nn.Dropout(dropout)
self.n_head = num_heads
self.emd_dim = embed_dim
self.head_dim = self.emd_dim // self.n_head
- 三个线性变换 query,key,value以及最后输出的线性变换 proj
- 一个 Dropout 层
attn_drop - 使用的头数
n_head - 词向量的维度
emd_dim - 每个头的维度
head_dim
知道了这些,我们开始完善前向传播,先来看一下相关信息
def forward(self, query, key, value, attn_mask=None):
"""
Calculate the masked attention output for the provided data, computing
all attention heads in parallel.
In the shape definitions below, N is the batch size, S is the source
sequence length, T is the target sequence length, and E is the embedding
dimension.
N:批次大小
S:原句子长度
T:目的句子长度
E:嵌入维度(类似隐藏状态)
Inputs:
- query: Input data to be used as the query, of shape (N, S, E)
- key: Input data to be used as the key, of shape (N, T, E)
- value: Input data to be used as the value, of shape (N, T, E)
- attn_mask: Array of shape (S, T) where mask[i,j] == 0 indicates token
i in the source should not influence token j in the target.
Returns:
- output: Tensor of shape (N, S, E) giving the weighted combination of
data in value according to the attention weights calculated using key
and query.
"""
N, S, E = query.shape
N, T, E = value.shape
# Create a placeholder, to be overwritten by your code below.
output = torch.empty((N, S, E))
############################################################################
# TODO: Implement multiheaded attention using the equations given in #
# Transformer_Captioning.ipynb. #
# A few hints: #
# 1) You'll want to split your shape from (N, T, E) into (N, T, H, E/H), #
# where H is the number of heads. #
# 2) The function torch.matmul allows you to do a batched matrix multiply.#
# For example, you can do (N, H, T, E/H) by (N, H, E/H, T) to yield a #
# shape (N, H, T, T). For more examples, see #
# https://pytorch.org/docs/stable/generated/torch.matmul.html #
# 3) For applying attn_mask, think how the scores should be modified to #
# prevent a value from influencing output. Specifically, the PyTorch #
# function masked_fill may come in handy. #
############################################################################
- 输入为 q,k,v 三个张量,以及遮盖张量(我们可以知道qkv三个张量是相同的)
- 它给出了提示
- 把张量从(N,T,E)划分为(N,T,H,E/H)会更加的方便
- 使用
torch.matmul函数可以进行批量矩阵乘法,比如(N,H,T,E/H)乘以(N,H,E/H,T)可以产生一个(N,H,T,T)的张量,接下来我们就要用到这个啦 - 使用 pytorch 的
masked_fill函数来进行遮盖
有了以上的提示,我们略加思考就可以写出多头注意力了
def forward(self, query, key, value, attn_mask=None):
"""
Calculate the masked attention output for the provided data, computing
all attention heads in parallel.
In the shape definitions below, N is the batch size, S is the source
sequence length, T is the target sequence length, and E is the embedding
dimension.
N:批次大小
S:原句子长度
T:目的句子长度
E:嵌入维度(类似隐藏状态)
Inputs:
- query: Input data to be used as the query, of shape (N, S, E)
- key: Input data to be used as the key, of shape (N, T, E)
- value: Input data to be used as the value, of shape (N, T, E)
- attn_mask: Array of shape (S, T) where mask[i,j] == 0 indicates token
i in the source should not influence token j in the target.
Returns:
- output: Tensor of shape (N, S, E) giving the weighted combination of
data in value according to the attention weights calculated using key
and query.
"""
N, S, E = query.shape
N, T, E = value.shape
# Create a placeholder, to be overwritten by your code below.
output = torch.empty((N, S, E))
############################################################################
# TODO: Implement multiheaded attention using the equations given in #
# Transformer_Captioning.ipynb. #
# A few hints: #
# 1) You'll want to split your shape from (N, T, E) into (N, T, H, E/H), #
# where H is the number of heads. #
# 2) The function torch.matmul allows you to do a batched matrix multiply.#
# For example, you can do (N, H, T, E/H) by (N, H, E/H, T) to yield a #
# shape (N, H, T, T). For more examples, see #
# https://pytorch.org/docs/stable/generated/torch.matmul.html #
# 3) For applying attn_mask, think how the scores should be modified to #
# prevent a value from influencing output. Specifically, the PyTorch #
# function masked_fill may come in handy. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
Q = self.query(query)
K = self.key(key)
V = self.value(value)
Q = Q.reshape((N, S, self.n_head, self.head_dim)).permute(0, 2, 1, 3)
K = K.reshape((N, T, self.n_head, self.head_dim)).permute(0, 2, 1, 3)
V = V.reshape((N, T, self.n_head, self.head_dim)).permute(0, 2, 1, 3) # (N,H,T,E/H)
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / math.sqrt(self.head_dim) # (N,H,T,T)
if attn_mask is not None:
energy.masked_fill_(attn_mask == 0, -math.inf)
attention = torch.softmax(energy, dim=3)
attention = self.attn_drop(attention)
output = torch.matmul(attention, V) # (N,H,T,E/H)
output = output.permute(0, 2, 1, 3).contiguous() # (N,T,H,E/H)
output = output.reshape((N, S, self.emd_dim))
output = self.proj(output)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return output
代码详解
- 多头注意力的八个头被放在一个大矩阵里面,所以只需要计算一次,但是需要我们手动把八个头给划分出来
- 划分出来八个头,使用
torch.matmul进行批量矩阵乘法,计算出相关性 - 使用
masked_fill_函数(这里的"_"表示修改自身)来进行填充,attn_mask==0的位置就是需要填充的位置,填充进负无穷大,后面使用 softmax 就会得到零 - 八个头进行拼接的时候,需要先用
permute进行维度交换,然后才进行拼接,不然会出错 - 拼接完成后,经过最后的线性变换后输出
编写代码完成,来看一下最后得出的结果
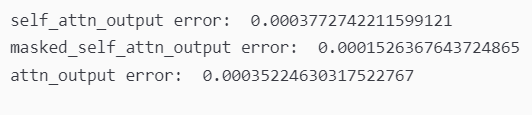
误差在范围内,正确
3.2 Positional Encoding
在这里我们要完成 Tr 的位置嵌入相关代码
作者对每个词向量都进行了位置嵌入,使用的公式如下:
{ sin ( i ⋅ 1000 0 − j d ) j是偶数 cos ( i ⋅ 1000 0 − ( j − 1 ) d ) otherwise \begin{cases} \text{sin}\left(i \cdot 10000^{-\frac{j}{d}}\right) & \text{j是偶数} \\ \text{cos}\left(i \cdot 10000^{-\frac{(j-1)}{d}}\right) & \text{otherwise} \\ \end{cases} ⎩ ⎨ ⎧sin(i⋅10000−dj)cos(i⋅10000−d(j−1))j是偶数otherwise
这样子会得到一个位置向量,接下来把他和输入的X进行相加,得到经过位置嵌入的输出
我们可以使用列表推导来完成位置嵌入矩阵的初始化
class PositionalEncoding(nn.Module):
"""
Encodes information about the positions of the tokens in the sequence. In
this case, the layer has no learnable parameters, since it is a simple
function of sines and cosines.
"""
def __init__(self, embed_dim, dropout=0.1, max_len=5000):
"""
Construct the PositionalEncoding layer.
Inputs:
- embed_dim: the size of the embed dimension
- dropout: the dropout value
- max_len: the maximum possible length of the incoming sequence
"""
super().__init__()
self.dropout = nn.Dropout(p=dropout)
assert embed_dim % 2 == 0
# Create an array with a "batch dimension" of 1 (which will broadcast
# across all examples in the batch).
pe = torch.zeros(1, max_len, embed_dim)
############################################################################
# TODO: Construct the positional encoding array as described in #
# Transformer_Captioning.ipynb. The goal is for each row to alternate #
# sine and cosine, and have exponents of 0, 0, 2, 2, 4, 4, etc. up to #
# embed_dim. Of course this exact specification is somewhat arbitrary, but #
# this is what the autograder is expecting. For reference, our solution is #
# less than 5 lines of code. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
index = [i for i in range(max_len)]
even_ind = [i for i in range(embed_dim)if i % 2 == 0]
odd_ind = [i for i in range(embed_dim)if i % 2 != 0]
pe[:, :, even_ind] = torch.tensor(
[[math.sin(i*pow(10000, -j/embed_dim))for j in even_ind]for i in index])
pe[:, :, odd_ind] = torch.tensor(
[[math.cos(i*pow(10000, -(j-1)/embed_dim))for j in odd_ind]for i in index])
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
# Make sure the positional encodings will be saved with the model
# parameters (mostly for completeness).
self.register_buffer('pe', pe)
接着修改前向传播代码,将位置嵌入的值加上去就可以啦
def forward(self, x):
"""
Element-wise add positional embeddings to the input sequence.
Inputs:
- x: the sequence fed to the positional encoder model, of shape
(N, S, D), where N is the batch size, S is the sequence length and
D is embed dim
Returns:
- output: the input sequence + positional encodings, of shape (N, S, D)
"""
N, S, D = x.shape
# Create a placeholder, to be overwritten by your code below.
output = torch.empty((N, S, D))
############################################################################
# TODO: Index into your array of positional encodings, and add the #
# appropriate ones to the input sequence. Don't forget to apply dropout #
# afterward. This should only take a few lines of code. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
pe_x = x+self.pe[:, 0:S, 0:D]
output = self.dropout(pe_x)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return output
代码验证
![]()
误差范围内,完美
3.3 Transformer for Image Captioning
在这里我们就要完成完全的 Tr了,我们打开文件cs231n/classifiers/transformer.py ,查看CaptioningTransformer 类
我们需要完善前向传播算法
def forward(self, features, captions):
"""
Given image features and caption tokens, return a distribution over the
possible tokens for each timestep. Note that since the entire sequence
of captions is provided all at once, we mask out future timesteps.
Inputs:
- features: image features, of shape (N, D)
- captions: ground truth captions, of shape (N, T)
Returns:
- scores: score for each token at each timestep, of shape (N, T, V)
"""
N, T = captions.shape
# Create a placeholder, to be overwritten by your code below.
scores = torch.empty((N, T, self.vocab_size))
############################################################################
# TODO: Implement the forward function for CaptionTransformer. #
# A few hints: #
# 1) You first have to embed your caption and add positional #
# encoding. You then have to project the image features into the same #
# dimensions. #
# 2) You have to prepare a mask (tgt_mask) for masking out the future #
# timesteps in captions. torch.tril() function might help in preparing #
# this mask. #
# 3) Finally, apply the decoder features on the text & image embeddings #
# along with the tgt_mask. Project the output to scores per token #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
caption_embed = self.positional_encoding(self.embedding(captions))
img_vec = self.visual_projection(features)
mask = torch.ones((T, T), dtype=bool)
mask = torch.tril(mask)
img_vec = torch.unsqueeze(img_vec, 1)
output = self.transformer(caption_embed, img_vec, mask)
scores = self.output(output)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return scores
代码解析
- 首先观察提示,我们先将句子转化成词向量,然后把图片特征转化成图片限量
- mask可以通过
torch.tril函数转化成下三角矩阵 - 要给图片向量增加一个维度
到这里我们就完成了 Tr 的主要部分了,接下来进行模型的验证,用小数据来让他过拟合
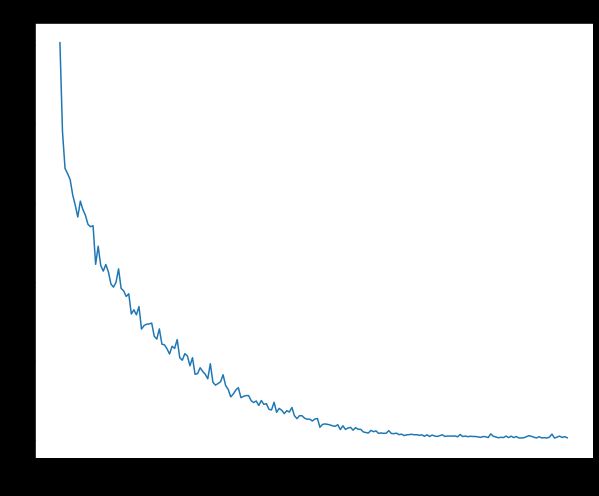
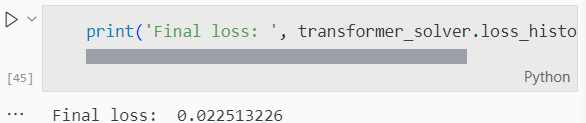
我们可以看出最后得到的损失小于0.03
接下来我们再测试一下它的性能,发现训练数据拟合的不错,但是验证数据就不太行了
3. 总结、预告
在这次作业中,我们成功实现了 Tr 的关键部分,作业二的部分博主打算等作业三部分更新完成再补全iai
接下来将会实现 GANs 的部分啦