基于深度学习的特征提取和匹配方法介绍
点击上方“AI算法修炼营”,选择加星标或“置顶”
标题以下,全是干货
作者:黄浴
知乎链接:https://zhuanlan.zhihu.com/p/112114806
本文已由作者授权转载,未经允许,不得二次转载。
计算机视觉需要图像预处理,比如特征提取,包括特征点,边缘和轮廓之类。以前做跟踪和3-D重建,首先就得提取特征。特征点以前成功的就是SIFT/SURF/FAST之类,现在完全可以通过CNN模型形成的特征图来定义。
特征提取
• Discriminative learning of deep convolutional feature point descriptors【1】
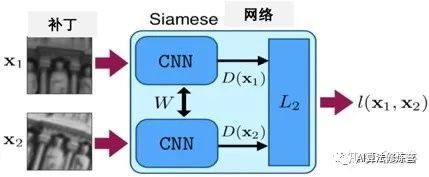
该方法通过卷积神经网络(CNN)学习鉴别式补丁表示,特别是训练具有成对(非)相应补丁的Siamese网络。在训练和测试期间它使用L2距离,提出了一种128-D描述符,其欧几里德距离反映了补丁相似性,并且可作任何涉及SIFT的替代。
如图所示,用一个Siamese网络来学习这样的描述符,其中非线性映射由CNN表示,它对对应或非对应补丁对优化。补丁通过模型提取描述符然后计算其L2范数,作为图像描述符的标准相似性度量。而目标是学习一个描述符,在其空间中让非对应的补丁相隔甚远,而在对应的补丁紧密相连。
考虑每个图像块xi具有索引pi,该索引pi唯一地标识从给定视点大致投影到2D图像块的3D点,而目标函数定义如下:
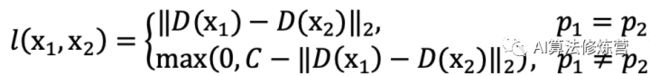
其中p1,p2分别是投影到x1,x2的3D点索引。
这里下表给出的是三层网络架构:64×64输入在第3层中产生128维输出。每个卷积层由四个子层组成:滤波器层,非线性层,池化层和归一化层。

非线性层,使用双曲线切线单元(Tanh)池化层使用L2池化,归一化很重要,这里使用减法归一化,在第一和二层之后用高斯核减去5×5邻域的加权平均值。
• Learned Invariant Feature Transform【2】
LIFT是一种深度网络架构,实现了完整的特征点检测、朝向估计和特征描述,如图所示。

下图是以Siamese架构为基础的整个特征检测和描述流水线。为了训练网络,采用图中的四分支Siamese结构。每个分支包含三个不同CNN,一个检测器、一个朝向估计器和一个描述子。使用四联(quadruplets)图像补丁。每个包括:图像块P1和P2对应于同样3D点的不同视图,图像块P3包含不同3D点的投影,图像块P4不包含任何显着特征点。在训练期间,每个四联第i个补丁Pi将通过第i个分支。
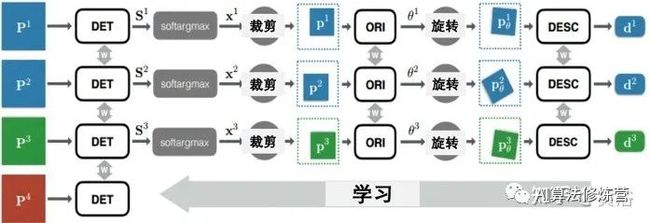
为了实现端到端可微分,每个分支的组件连接如下:
1) 给定输入图像块P,检测器提供得分图S;
2) 在得分图S上执行soft argmax 并返回单个潜在特征点位置x。
3) 用空间变换器层裁剪(Spatial Transformer layer Crop)提取一个以x为中心的较小的补丁p(如图5-3), 作为朝向估计器的输入。
4) 朝向估计器预测补丁方向θ。
5) 根据该方向第二个空间变换器层(图中的Rot)旋转p产生pθ。
6) pθ送到描述子网络计算特征向量d。
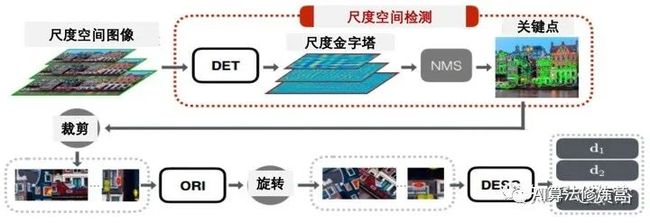
最后的运行结构如图所示。由于朝向估计器和描述子只在局部最大值进行评估,将检测器解耦并在传统NMS的尺度空间中运行,以获得其他两个组件的建议。
最后看LIFT和SIFT结果比较的例子,如图所示。

特征匹配
MatchNet【3】
MatchNet由一个深度卷积网络组成,该网络从补丁中提取特征,并由三个全连接层组成网络计算所提取特征之间的相似性。
如图是MatchNet训练时的网络架构(图C),联合学习将补丁映射到特征表示的特征网络(图 A)和将特征对映射到相似性的测度网络(图 B)。输出尺寸由(高×宽×深)给出。PS是卷积和池化层的补丁大小; S是步幅。层类型:C=卷积,MP=最大池化,FC=全连接。因为填充卷积层和池化层,故输出高度和宽度是输入除以步幅的值。对FC层,大小B,F选自:B∈{64,128,256,512},F∈{128,256,512,1024}。除FC3外,所有卷积层和FC层用ReLU激活,输出用Softmax归一化。
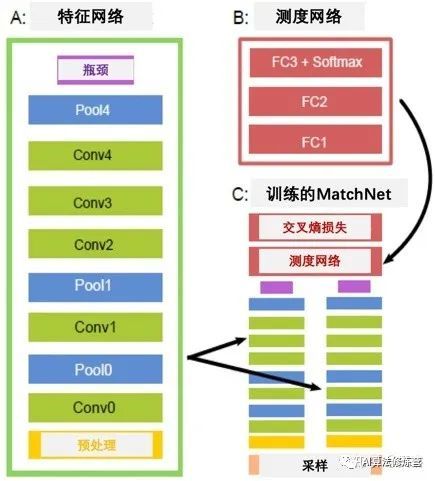
下图是MatchNet预测的流水线图,网络拆解为并行的特征网络和测度网络。分两个阶段使用特征网络和测度网络:首先为所有补丁生成特征编码,然后将这些特征配对并推送它们通过测度网络获得分数。

UCN【4】
通用对应网络(Universal Correspondence Network,UCN)用于几何和语义匹配的视觉对应,包括从刚性运动到类内形状或外观变化等不同场景。深度测度学习过程,直接学习来保留几何或语义相似性的特征空间。一种卷积空间变换器(convolutional spatial transformer,CST)模拟传统特征(如SIFT)的补丁归一化,可显著提高类内形状变化语义对应(semantic correspondences)的准确性。
如图是UCN和传统方法的比较:各种类型的视觉对应问题需要不同的方法,例如用于稀疏结构的SIFT或SURF,用于密集匹配的DAISY或DSP,用于语义匹配的SIFT flow或FlowWeb。UCN准确有效地学习几何对应、致密轨迹或语义对应的度量空间。

下图是UCN系统概述:网络是全卷积的,由一系列卷积、池化、非线性和卷积空间变换器组成,还有通道L2归一化和对应对比损失函数。作为输入,网络采用图像对应点的一对图像和坐标(蓝色:正,红色:负)。对应于正样本点(来自两个图像)的特征被训练为彼此更接近,而对应于负样本点的特征被训练为相隔一定距离。在最后L2归一化之前和FCNN之后,设置一个卷积空间变换器来归一化补丁或考虑更大的上下文信息。

下图是视觉对应的对比损失函数示意图:需要三个输入,从图像中提取的两个密集特征及其坐标,和用于正负对应对的表。损失函数计算公式如下
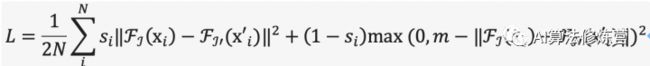
其中s=1位正对应对,而s=0为负对应对。

如图比较卷积空间变换器和其他方法的比较:(a)SIFT标准化旋转和缩放;(b)空间变换器将整个图像作为输入来估计变换;(c)卷积空间变换器对特征进行独立变换。

DGC-Net(Dense Geometric Correspondence Network)
是一种基于CNN实现从粗到细致密像素对应图(pixel correspondence map)的框架,它利用光流法的优势,并扩展到大变换,提供密集和亚像素精确的估计。训练数据来自合成的变换,也应用于相机姿态估计的问题。
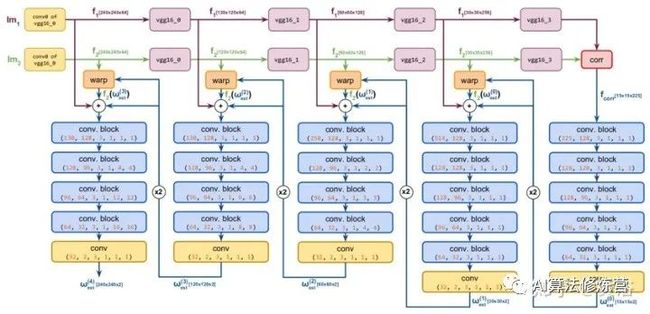
如图所示,一对输入图像被馈入由两个预训练的CNN分支组成的模块,这些分支构成一个特征金字塔。相关层从金字塔的粗层(顶)获取源图像和目标图像的特征图,并估计它们之间的成对相似性。然后,对应图(correspondence map)解码器获取相关层(correlation layer)的输出并直接预测该金字塔在特定层的像素对应关系。最后,以迭代方式细化估计。

为了在特征空间中创建输入图像对的表示,构造了一个有两个共享权重分支的Siamese神经网络。分支用在ImageNet训练的VGG-16架构,并在最后的池化层截断,然后进行L2归一化。在每个分支的不同部分提取特征fs,ft创建具有5-层特征金字塔(从顶部到底部),其分辨率是[15×15, 30×30, 60×60, 120×120, 240×240],在网络训练过程的其余时间固定CNN分支的权重。
为估计两个图像之间的相似性,计算源图像和目标图像的标准化特征图之间的相关体积。不同于光流法,直接计算全局相关性并在相关层前后做L2标准化以强烈减少模糊匹配(见图所示)。
将相关层输出送到5个卷积块(Conv-BN-ReLU)组成的对应图解码器,估计特征金字塔特定层l 的2D致密对应域ω(l)est。这是参数化估计,图中每个预测像素位置属于宽度和高度归一化的图像坐标区间[-1,1]。也就是说,上采样在(l-1)层的预测对应域,让第l层源图像的特征图变形到目标特征。最后,在上采样域,变形源fs(ω(l)est)和目标ft(l)的特征沿着通道维度拼接在一起,并相应地作为输入提供给第l级的对应图解码器。
解码器中每个卷积层被填充以保持特征图的空间分辨率不变。此外,为了能够在金字塔的底层捕获更多空间上下文信息,从l = 3开始,将不同的空洞(dilation)因子添加到卷积块以增加感受野。特征金字塔创建者、相关层和对应图解码器的分层链一起组成CNN架构,称为DGC-Net。
给定图像对和地面实况像素相关映射ωgt,定义分层目标损失函数如下:

其中||.||1是估计的对应图和GT对应图之间的L1距离,M(l)gt 是GT二值掩码(匹配掩码),表示源图像的每个像素在目标是否具有对应关系。
除了DGC-Net生成的像素对应图之外,还直接预测每个对应的置信度。具体来说,通过添加匹配(matchability)分支来修改DGC-Net结构。它包含四个卷积层,输出了概率图(参数化为sigmoid函数),标记预测对应图每个像素的置信度,这样架构称为DGC + M-Net。把此问题作为像素分类任务,优化一个二值交叉熵(BCE),其中逻辑损失(logits loss)定义为:

最终的损失为:
更多的DGC-Net网络细节见图所示。
而DGC+M-Net的一些网络细节见图所示。

参考文献
1. E. Simo-Serra et al., “Discriminative learning of deep convolutional feature point descriptors”. ICCV 2015
2. K Yi et al.,“Learned Invariant Feature Transform”, arXiv 1603.09114, 2016
3. X Xu et al.,“MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching”, CVPR 2015
4.
C Choyet al., “Universal Correspondence Network”,NIPS 2016
目标检测系列秘籍一:模型加速之轻量化网络秘籍二:非极大值抑制及回归损失优化秘籍三:多尺度检测秘籍四:数据增强秘籍五:解决样本不均衡问题秘籍六:Anchor-Free视觉注意力机制系列Non-local模块与Self-attention之间的关系与区别?视觉注意力机制用于分类网络:SENet、CBAM、SKNetNon-local模块与SENet、CBAM的融合:GCNet、DANetNon-local模块如何改进?来看CCNet、ANN
语义分割系列一篇看完就懂的语义分割综述最新实例分割综述:从Mask RCNN 到 BlendMask超强视频语义分割算法!基于语义流快速而准确的场景解析CVPR2020 | HANet:通过高度驱动的注意力网络改善城市场景语义分割
基础积累系列卷积神经网络中的感受野怎么算?
图片中的绝对位置信息,CNN能搞定吗?理解计算机视觉中的损失函数深度学习相关的面试考点总结
自动驾驶学习笔记系列 Apollo Udacity自动驾驶课程笔记——高精度地图、厘米级定位 Apollo Udacity自动驾驶课程笔记——感知、预测 Apollo Udacity自动驾驶课程笔记——规划、控制自动驾驶系统中Lidar和Camera怎么融合?
竞赛与工程项目分享系列如何让笨重的深度学习模型在移动设备上跑起来基于Pytorch的YOLO目标检测项目工程大合集目标检测应用竞赛:铝型材表面瑕疵检测基于Mask R-CNN的道路物体检测与分割
SLAM系列视觉SLAM前端:视觉里程计和回环检测视觉SLAM后端:后端优化和建图模块视觉SLAM中特征点法开源算法:PTAM、ORB-SLAM视觉SLAM中直接法开源算法:LSD-SLAM、DSO视觉SLAM中特征点法和直接法的结合:SVO
2020年最新的iPad Pro上的激光雷达是什么?来聊聊激光SLAM