《You Only Look One-level Feature》论文阅读
文章下载:
You Only Look One-level Feature.pdf

摘要
本篇论文重新讨论了特征金字塔网络(FPN)对于 one-stage 检测器的作用,并指出,在目标检测问题中,FPN的成功分治法(divide-and-conquer)而非多尺度特征融合。从优化的角度来讲,我们引入了一种替代方法来解决该问题,而不是采用复杂的特征金字塔 —— 仅仅使用 one-level 的特征来做检测。基于这种简单而又有效的方法,我们提出了 You Only Look One-Level Feature (YOLOF)。在我们的方法中,有两个关键点 —— Dilated Encoder膨胀编码器 和 Uniform Matching均匀匹配,这两个关键点带来了相当可观的性能提升。在COCO基准上的大量实验也证明了YOLOF的高效性。在我们的YOLOF中,起到特征金字塔作用的RetinaNet取得了加快2.5倍速度的结果。对于 608*608 大小的图片,YOLOF 能够在 2080Ti 上以 60 fps 的速度达到 44.3mAP,比 YOLOv4快了 13%。代码链接为:https://github.com/megvii-model/YOLOF
1. Introduction
特征金字塔已成为 one-stage 和 two-stage 方法中基础的方法组成。创建特征金字塔的流行方法就是通过特征金字塔网络 FPN,该网络主要有两个优点:
- 多尺度特征融合:通过融合低分辨率特征与高分辨率特征来获取更好的特征描述;
- 分治 divide-and-conquer:根据目标的尺度大小进行不同水平的目标检测;
我们通常认为 FPN 受益于多尺度特征融合,从而引发了一系列手动设计复杂融合方法的研究,或者是通过神经架构搜索算法来获取融合方法。但是这种看法忽略了分治的作用,因此也就少有去研究这两点是如何共同对 FPN 起作用的,也就有可能阻碍进一步的新发现。
本篇文章研究了 FPN 的两个关键点在 one-stage 检测器当中的影响。我们使用RetinaNet,通过分离多尺度特征融合与分治来设计了实验。具体来讲,我们将 FPN 当作了一个多输入输出编码器(MiMo),其从主干网 backbone 中对多尺度特征进行编码,并为解码端(detection head)提供特征描述。我们通过控制输入输出进行了各种组合之间的比较:多输入多输出MiMo、单输入多输出SiMo、多输入单输出MiSo、单输入单输出SiSo。
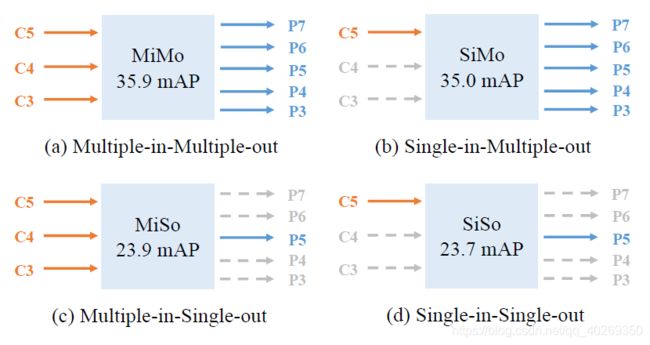
图1:四种不同输入输出在 COCO 验证集上的结果比较。其中,我们将 RetinaNet 作为基准模型;C3、C4、C5分别表示主干网络 backbone 分别在8倍、16倍、32倍下采样率下的特征输出。P3到P7则表示用于最终检测的特征层级(feature levels)。上述结果都使用相同的主干网络 ResNet-50。其中MiMo的结构和 RetinaNet 中的 FPN 结构相同。编码器的详细结构见图8
从图中可以看到,对于SiMo编码器来说,它只有一个输入特征因此也就没有特征融合,但是也取得了与MiMo相当的结果。与之相比,MiSo与SiSo则减少了很多的mAP,都大于12个的mAP。这种现象表明两个事实:
- C5特征携带了足够的上下文信息,使之可以在多种尺度上进行目标检测,也就使得 SiMo有着不错的结果;
- 多尺度特征融合的收益远不如分治法的收益,因此多尺度特征融合也就并非 FPN 的获益点。
再进行进一步的思考,分治法与目标检测当中的优化问题有关。它将复杂的检测问题分解为多个目标尺度的子问题,以此来推动优化过程。
以上这些分析揭示出,FPN成功的必不可少的因素是它在目标检测优化问题当中的解决方法。其中分治法 divide-and-conquer 就是一种很好的方法。但是这也带来了 memory burdens,降低了检测器的性能,使得 one-stage 检测器的结构复杂化,比如 RetinaNet。鉴于C5特征就已经包含了足够的用来检测的上下文信息,我们为优化问题提出了一个简单的方式。
我们提出的 You Only Look One-Level Feature (YOLOF) 方法仅仅使用了一个 C5 特征(采用32倍的下采样率)用来检测目标。为了弥补 SiMo 编码器与 MiMo 编码器之间的性能差距,我们首先很好地设计了编码器的结构,使之能够在多种尺度范围上,提取出目标的多尺度上下文信息,以弥补相对于多特征输入的缺失;然后,我们使用均匀匹配机制,来解决在单一特征上,由稀疏锚框导致的正向锚框不平衡的问题(we apply a uniform matching mechanism to solve the imbalance problem of positive anchors raised by the sparse anchors in the single feature)。
在没有引入其它花里胡哨的功能的情况下,YOLOF 利用起到特征金字塔功能的RetinaNet,取得了相近的结果,但却提升了2.5倍的速度。而在单个特征的时候,YOLOF 也达到了最近提出的 DETR 方法的表现性能,并且同时提升了 7 倍的速度。在图片大小限制为 608*608 以及其他一些技术的情况【Yolov4,Swa object detection】下,YOLOF 在 2080Ti 上以 60 fps 的速度获得了 44.3mAP 的成绩,这个结果比 YOLOV4 快了 14%。简而言之,本篇文章的主要贡献如下:
- 在稠密目标检测任务的优化问题中,FPN 网络中收益最大的部分是分治法 divide-and-conquer,而非多尺度特征融合multi-scale feature fusion;
- 我们提出了一个简单且有效,并且未使用特征金字塔网络 FPN 的基准方法 YOLOF。在该方法中,我们提出两个关键点:Dilated Encoder 和 Uniform Matching,用来弥补 SiMo编码器 和 MiMo 编码器之间的性能表现差距;
- 在 COCO 基准上的大量实验也表明了上述提到的两个部分的重要性。并且,我们还比较了 RetinaNet、DETR、YOLOv4 之间的表现差异。最终的结果表明,我们的方法在GPU上运行时,在相同结果性能的情况下还可以有更快的速度。
2. Related Works
Multiple-level feature detectors
对于目标检测问题,应用多种(尺度)特征是一种比较传统的方法。创建多种(尺度)特征的典型方法可以总结为图像金字塔方法和特征金字塔方方法。基于检测器的图像金字塔方法,比如 DPM,在预学习阶段控制检测。在基于CNN的检测器中,图像金字塔方法也受到了研究者们的青睐,由于它在开箱即用的情况下也可以获得更高的性能表现。然而,图像金字塔并不是唯一能够获得多种(尺度)特征的方式;在CNN模型中,使用特征金字塔是更加有效且自然的方式。SSD 利用多尺度特征,在不同尺度的目标上,对每一种尺度进行目标检测。FPN 则仿照 SSD 和 UNet 的方式,通过将浅层特征与深层特征结合的方式,创建语义丰富的特征金字塔。在这些研究工作之后,又有多个研究工作继承了 FPN,并且专注于如何获取更好的特征表达。FPN 也就成为了一种基础的组成部件,并决定了现代检测器的结构与表现。同时,它也被应用于一些流行的 one-stage 检测器,比如 RetinaNet,FCOS 以及他们的一些变体。另外一种获取特征金字塔方法路线,是使用多分支空洞卷积。与以上研究工作不同,我们的方法是一种单一特征的检测器。
Single-level feature detectors
在早期,R-CNN 系列与 R-FCN 方法只在单一特征上提取 RoI 特征,然而他们的性能表现落后于相同作用的多种特征方法。此外,在 one-stage 检测器中,YOLO 和 YOLOv2 仅仅使用了主干网络的最后一层输出特征。他们的速度也就因此变得非常快,但是却不得不承受在检测上的性能表现衰减。CornerNet 和 CenterNet 也跟随了这样的步伐,在使用单一特征的情况下,通过应用 4 倍的下采样率,在检测所有目标任务上取得了更好的结果。我们知道,使用高分辨率的特征图来进行检测,会带来大量的内存消耗,并且对进一步的扩展任务也很不友好。因此,近来,DETR 引入了 transformer 来进行检测任务,结果显示在仅仅使用单个 C5 特征的情况下取得了目前最优的性能结果。由于完全的 anchor-free 机制以及 transformer learning phase,DETR 需要一个长期的训练阶段以进行融合。这种长期的训练,对进一步的优化提升来说,非常复杂冗长。与上述提到的研究工作不同,我们研究了多层次检测的工作机制。从优化的角度来讲,我们为广泛应用的 FPN 提供了一种非传统的解决方案。并且,YOLOF 更快并取得了可观的性能表现;因此,YOLOF 可以为快速且精确的检测器,作为一个简单的基准对比。
3. Cost Analysis of MiMo Encoders
像第一部分提到的那样,FPN 在稠密目标检测任务中的成功,要归功于它在优化问题上的解决方案。然而,多层次特征范式会不可避免地使检测器变复杂,并带来内存负担,减慢检测器的速度。在这一部分,我们进行了 MiMo 编码器性能消耗上的定量研究工作。
我们基于 RetinaNet 和 ResNet-50 设计了一些实验。具体来说,我们将检测任务流程,规范化为三个关键部分结合起来的流水线:骨干网络 backbone、编码器、解码器,如下图2所示。

图 2 检测任务流水线表示。在本篇文章中,我们将检测任务规范化为三部分组成的流水线:1. 骨干网络backbone;2. 编码器,接收骨干网络的输出并编码检测需要的特征描述;3. 解码器,主要进行目标分类与回归任务并生成最终的预测框。在这里,图中编码器的颜色与图1中一致。
在进行这样的规范化之后,图 3 展示了各个部分的 FLOPs,如下所示。
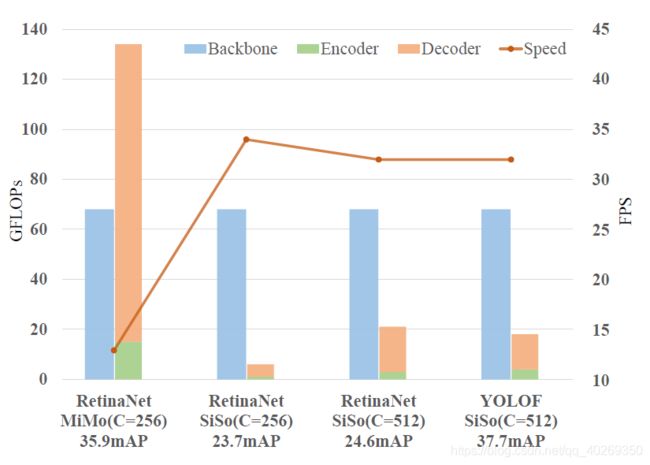
图 3 在 COCO 数据集上,应用了 MiMo 和 SiSo 编码器的模型在 FLOPs、精确度 accuracy、速度 speed 之间的比较。由于解码器的 FLOPs 受编码器输出的影响,在图中我们就将编码器和解码器的 FLOPs 堆叠在了一起,以便更好地理解编码器在 FLOPs 方面上的影响。所有的模型都使用了相同的骨干网络 ResNet-50。所有的 FLOPs 都是使用 COCO val2017 数据集中前 100 个边长小于 800 的图片测量出来的。FPS 则是在 2080Ti 上将 batcj-size 设置为 1 之后,根据 Detectron2 得到的全部纯推理计算时间。另外,在图中,C 表示模型中编码器和解码器的通道数量。
相对于 SiSo 编码器,MiMo 编码器带来了更高的内存负担,足足有 134GFLOPs,而 SiSo 只有 6GFLOPs。此外,带有 MiMo 编码器的检测器速度也比 SiSo 编码器的检测器更慢,其之间的对比为 13 FPS vs 34 FPS。这种慢速,是由于带有 MiMo 编码器的检测器会在高分辨率特征图上进行目标检测,比如会使用 C3 特征,它只有 8 倍的下采样率。鉴于以上发现的 MiMo 编码器的弊端,我们力求找到一种可替代的方式,来解决检测中的优化问题,同时保持检测器简单、准确、快速的特性。
4. Method
基于上述提到的目标,以及 C5 特征包含足够用于检测任务的上下文信息的发现,我们尝试使用简单的 SiSo 编码器来代替复杂的 MiMo 编码器。但这种替换,并不容易;从图 3 可以看到替换之后性能表现有大幅下跌。鉴于这种情况,我们仔细分析了 SiSo 编码器与 MiMo 编码器之间的性能差异原因。我们发现 SiSo 编码器中的两个问题导致了这种性能下降。首先,第一个问题就是,匹配到 C5 特征感受野的缩放范围受限,这就导致在多种尺度上的目标检测性能受到阻碍;第二个问题就是,由单特征上的稀疏锚导致的 positive anchors 的不平衡问题。接下来我们将具体讨论这两个问题,并给出我们的解决方案。
4.1 Limited Scale Range
在完全不同的多个尺度上识别目标物体是目标检测任务中的一个基础挑战。一种可行的解决方案便是补充上多层次(尺度)特征。在那些使用了 MiMo 或者 SiMo 编码器的检测器当中,他们使用不同大小的感受野(P3 - P7)生成多层级的特征;并以与目标尺度相匹配的感受野大小去进行目标检测。然而,单层级特征的设定改变了这种做法。SiSo 编码器仅有一个输出特征,并且感受野还是固定大小的。如图 4a 中展示的那样,C5 特征的感受野仅能够覆盖有限的尺度范围,如果目标的尺度与感受野大小不匹配,就会导致很差的结果。为了在使用 SiSo 编码器的情况下依然能够检测出全部目标,我们必须找到一种方式,来生成多种不同大小感受野的输出特征的方式,以弥补特征多样性的不足。

图 4 一个简单的,能够展示目标尺度,与单一特征能够覆盖的尺度范围,之间的关系。图中的坐标轴表示尺度范围。a 表示特征的感受野仅能够覆盖有限的尺度范围;b 表示扩大的尺度范围能够使得特征覆盖大的目标,但是却错失了小的目标;c 表示了所有尺度都能够被多感受野的特征覆盖。
我们首先通过堆叠标准空洞卷积的方式,来扩大 C5 特征的感受野大小。尽管这样操作之后,其所能够覆盖的尺度范围在一定程度上已经扩大了,但是它仍然不能覆盖全部的目标尺度;因为这个扩大的过程,将原本的尺度范围也乘上了一个大于 1 的因子。这种情况就像图 4b 中展示的那样,相较于图 4a,整体的尺度范围平移到了较大的一边。然后,我们通过原始尺度范围与扩大后的尺度范围之间相关联的那些特征,将两者结合起来,就得到了能够覆盖全部目标尺度的多类感受野大小的输出特征,像图 4c 中所示。上述这些操作能够通过构建带有 3*3 空洞卷积层的残差块来实现。
Dilated Encoder
基于以上的初步设计,我们设计了名为 Dilated Encoder 的 SiSo 编码器,如图 5 所示。它包含两个部分:Projector 和 Residual Blocks。Projector 层首先通过一个 1x1 的卷积层来减小通道的维数,然后通过一个 3x3 的卷积层来修复语义上下文信息,这与 FPN 中一样。在此之后,我们堆叠了 4 个带有不同空洞大小的 3x3 卷积层的残差块,来生成带有多种感受野大小的输出特征,以覆盖全部目标尺度。
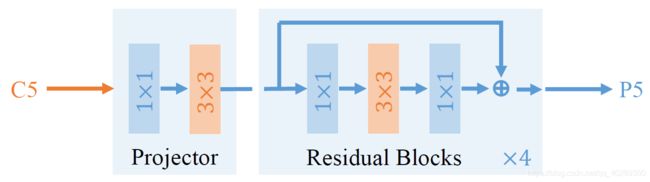
图 5 Dilated Encoder 结构图示。在图中,1x1 和 3x3 表示 1x1 和 3x3 的卷积层;x4 表示 4 个连续的残差块。在这个残差块中的全部卷积层都跟着一个 batchnorm 层和一个 ReLU 层,而在 Projector 中,仅仅使用了卷积层和 batchnorm 层。
Discussion
在目标检测领域,空洞卷积是一种司空见惯的扩大感受野的策略。像第二部分提到的那样,TridentNet 就利用了空洞卷积来生成多尺度特征。它通过多分支结构和权重共享机制,解决了目标检测中的尺度变化问题,这与我们的单层级特征设定很不相同。此外,Dilated Encoder 一个一个地堆叠了不带共享权重的空洞残差块。尽管 DetNet 也是应用了连续多个空洞残差块,但它的目的是维持特征的空间分辨率并保持骨干网络输出的更多细节信息,而我们的目的则是让骨干网络生成多种类感受野大小的特征。Dilated Encoder 的设计使得我们可以通过单层级特征来检测全部的目标,而不像 TridentNet 和 DetNet 那样使用多层级特征。
4.2 Imbalance Problem on Positive Anchors
positive anchors 的定义对目标检测任务中的优化问题有着至关重要的意义。在基于 anchor 的检测器当中,定义 positive 的策略由锚与真值框之间的 IoUs 决定。在 RetinaNet 中,如果锚和真值框之间最大的 IoU 比阈值 0.5 更大,那么这个锚框就被设定为正值框(positive anchor)。我们将这种定义方式称为最大 IoU 匹配原则 Max-IoU matching。
在 MiMo 编码器当中,锚框以一种稠密的方式在多个层级上进行了预定义,然后配合真值框在目标尺度上生成相关的正值锚框(positive anchor)。基于分治法机制,最大 IoU 匹配机制使得各个尺度上的真值框都能够生成足够数量的正值锚框(positive anchor)。然而,当我们将这种方法应用到 SiSo 编码器上去的时候,生成的锚框的数量,相比于 MiMo 编码器大幅度减少,大约从 100k 减少到 5k,从而导致了锚框稀疏问题;紧接着,当应用最大 IoU 匹配方法的时候,稀疏锚框便进一步导致了匹配问题,如图 6 所示。大的真值框会比小的真值框生成更多的正值锚框,这也就导致了正值锚框的不平衡问题。这种不平衡就进一步导致了,检测器会偏向于大的真值框,而忽略小的真值框。

图 6 在单一特征情况下,各种匹配方法所生成的正值锚框数量的情况展示。该图主要为了显示生成的正值锚框的平衡性。由大的真值框经过最大 IoU 匹配得到的正值锚框,会在目标尺度之间导致不平衡的问题。ATSS 则在训练过程中通过自适应地采样正值锚框来解决这个不平衡的问题。另外,Top1 方法和我们的方法则应用了均匀匹配的方法,使得生成的正值锚框不管是在小目标、中等目标还是大目标尺度上,都有着平衡的表现。
Uniform Matching
为了解决正值锚框的这种不平衡问题,我们提出了一种均匀匹配 Uniform Matching 策略:为每一个真值框挑选 k 个最近的锚框作为正值锚框,这一操作就使得所有的真值框都能均匀地匹配到相同数量的正值锚框,并忽略真值框的大小差异,像图 6 中所示那样。正值样本数量上的平衡也就确保了全部真值框在训练时都平等地起到作用。此外,参考最大 IoU 匹配方法,我们在均匀匹配方法中,也设置了一个 IoU 阈值,来过滤掉 IoU 大于 0.7 的负值锚框以及 IoU 小于 0.15 的正值锚框。
Discussion: relation to other matching methods
时至今日,使用 topk 方法进行匹配操作已不是新颖操作。ATSS 首先在 L \mathcal{L} L 特征层级,为每个真值框挑选 topk 个锚框,然后在 k × L \mathcal{k} \times \mathcal{L} k×L 个候选框中,通过动态 IoU 阈值的方式,采样正值锚框。然而 ATSS 注重自适应的定义正值框和负值框,而我们的均匀匹配方法注重与在稀疏锚框的情况下,在正值锚框上的平衡问题。尽管有多种方法在这一方面已经达到了平衡的效果,但是这些匹配方法却并不是专门为了这种不平衡问题专门设计的。比如,YOLO 和 YOLOv2 利用最匹配的元胞或者锚框来对真值框进行匹配;DETR 和 End-to-end people detection in crowded scenes 则应用了 Hungarian 算法来进行匹配操作。这些方法可以看作是图 6 中的 top1 方法,也就是我们的均匀匹配方法的一种特例。更重要的是,这种 learning-to-match 方法,比如说FreeAnchor、PAA,和我们提出的均匀匹配的方法之间的区别便是,前者根据当前学习状态,自适应地将锚框分为正值锚框和负值锚框,而均匀匹配方法则是固定的,没有自适应变化,不跟随训练过程而进一步适应。均匀匹配方法的提出,是为了强调在 SiSo 编码器设计上导致的正值锚框的不平衡问题。图 6 中的相关对比和 表 5e 中的结果都展示了在 SiSo 编码器当中的不平衡问题。
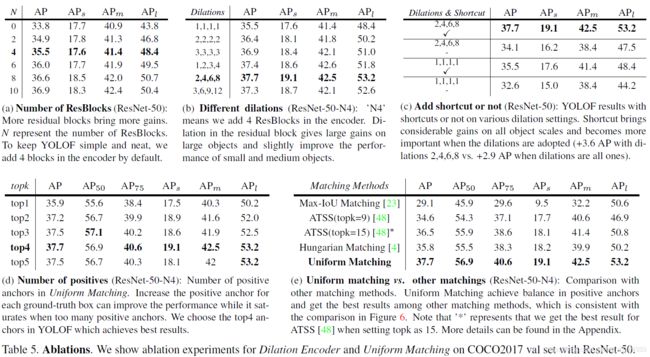
表 5
4.3 YOLOF
基于上述提到的方案,我们提出了一种只利用单层级特征的快速且直观的检测框架,命名为 YOLOF。我们将 YOLOF 规范化为三个部分:骨干网络 backbone,编码器和解码器。其框架结构如下图所示。
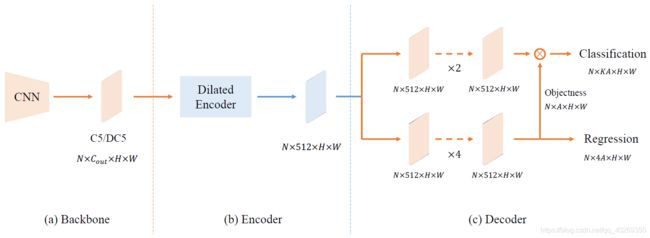
图 9 YOLOF 框架图。主要包含三个部分:骨干网络、编码器、解码器。图中的 “C5/DC5” 表示带有 32/16 下采样率的骨干网络的输出特征;“ C o u t C_{out} Cout” 表示特征的通道数。在编码器和解码器中,我们将特征图的通道数设定为 512。 H × W H \times W H×W 表示特征图的高和宽。
Backbone
我们在 YOLOF 的骨干网络中,应用了 ResNet 和 ResNeXt。所有的模型都在 ImageNet 进行了预训练。骨干网络的输出是一个都带有 32 倍下采样率的、2048 个通道的 C5 特征图。为了与其他检测器进行公平地比较,骨干网络中所有的 batchnorm 层都默认冻结。
Encoder
对于图 5 所示的编码器,我们首先根据 FPN,在骨干网络之后加入了两个投影层(一个 1x1 的卷积层和一个 3x3 的卷积层),以生成 512 通道的特征图。然后,为了使编码器输出的特征能够覆盖各种尺度上的全部目标,我们加入了残差块,其中包含了三个连续的卷积层:第一个 1x1 的卷积层以 4 倍的比率减少通道数,然后 3x3 的空洞卷积层则用来扩大感受野,最后一个 1x1 的卷积层则用来恢复通道数。
Decoder
对于解码器来说,我们使用了 RetinaNet 的主要结构,其包含了两个平行的功能特异模块:分类模块和回归模块,如图 9 所示。我们仅做了两个轻微的改动。首先,我们依照 DETR 中 FFN 的结构设计,使两个模块的卷积层数量不相同。在回归任务模块中,在 batch normalization 层之后有 4 个卷积层和 ReLU 层,而在分类任务模块中则只有两个卷积层。第二个改动就是,我们依照 Autoassign 中的方式,在回归任务模块中,为每个锚框加了一个不带直接监督的隐含目标预测。最后所有预测的分类分数都通过乘上这个隐含目标的分类输出得到。
Other Detail
像上文提到的那样,YOLOF 中预定义的锚框比较稀疏,这样也就降低了锚框与真值框之间的匹配质量。我们在图像上加入了一个随机平移操作,来规避这个问题。这个操作会使图像随机向上下左右四个方向平移最大 32 个像素,以便向图像中的目标位置加入噪声,增加真值框与高质量锚框匹配到的可能性。此外,我们还发现,在使用单层级特征的时候,锚框中心点平移上的限制性对最终的分类结果也会有帮助。我们便使全部锚框在平移时需要小于 32 像素。
5. Experiments
我们在 MS COCO 上验证了我们的模型 YOLOF,并与 RetinaNet 和 DETR 进行了比较。我们还开展了 YOLOF 中各个组件的消融实验,并给出了详细的量化结果与分析。最后,为了给出在单层级特征检测方面进一步研究灵感,为我们还提供了误差分析,并展示了相对于 DETR 来说,YOLOF 的薄弱之处。
Implementation Details
YOLOF 在 8 卡 GPU 上进行训练,mini-batch 设定为 64 个图片,每张 GPU 分配 8 张图片,采用同步梯度下降法进行训练。所有模型的初始学习率设定为 0.12。此外,根据 DETR,我们为骨干网络设定了更小的学习率,仅有基础学习率的 1/3,也就是 0.04。为了一开始就稳定训练过程,我们将起步阶段的迭代次数增加到 500 到 1500。对于训练阶段,由于我们增加了 batch size,the “ 1 × 1 \times 1×” schedule setting in YOLOF is a total of 22:5k iterations and with base learning rate decreased by 10 in the 15k and the 20k iteration。其他的训练计划则根据 Detectron2 的规则进行调整。对于模型的推断阶段,我们则利用阈值为 0.6 的 NMS,来对结果进行后处理。对于其他的超参数,我们则参照了 RetinaNet 中的设定。
5.1 Comparison with previous works
Comparison with RetinaNet
为了有一个公平的比较,我们让 RetinaNet 和 YOLOF 在以下几个方面保持一致:真值框与预测框之间的损失 IoU、加入隐含目标预测、在 head 部分中使用 group normalization layers。结果如表 1 所示。所有 “ 1 × 1 \times 1×” 的模型都是由 800 × 1333 800 \times 1333 800×1333 大小的图像训练而来的。首先,我们给出了在 Detectron2 训练下的 RetinaNet 的结果;然后,给出了增强后的 RetinaNet (带有 “+” )的结果,其设置与 YOLOF 相同;最后,我们展示了 YOLOF 的结果。得益于单层级特征,YOLOF 在 FLOPs 方面的性能表现比 RetinaNet+ 还要优 57%(如图 3 所示),并且还有 2.5 倍的加速效果。又由于 C5 特征 32 倍的下采样率,在小目标物体上,YOLOF 的表现就比 RetinaNet+ 较差(-3.1);然而,由于编码器中空洞残差块的加入,YOLOF 在大尺度目标上则有着更好的表现(+3.3)。RetinaNet+ 与将 ResNet-101 作为骨干网络的 YOLOF 有着相似的表现。尽管在相同的骨干网络下,YOLOF 在小尺度目标上的表现并不如 RetinaNet+,但是当使用 ResNeXt 作为骨干网络时,在相同速度下依然能够匹配小尺度目标。此外,为了证明我们的方法在目标检测领域,同当前其他技术仍有可比性与互补性,我们在表 1 中的最后两行展示了在多尺度图像上以及长期训练的结果。最后,进行多尺度测试后,我们获得了 47.1 mAP 的结果,在小尺度目标上也取得了 31.8 mAP 的结果。

表 1 与 RetinaNet 对比结果
Comparison with DETR
DETR 是近来使用 transformer 来做目标检测的检测器。这项技术在 COCO 数据集上取得了惊人的性能表现,同时也首次证明了,仅仅使用单一的 C5 特征,其也能够取得同传统的多层级特征的检测器相当的结果。基于这种情况,有人预计那些捕捉全局依赖的层,比如 transformer 层,能够在单层级特征中获取不错的结果。然而,我们的发现显示了有局部卷积层的卷积网络也能够达到这一目标。在表 2 中,我们对比了 DETR 的全局层和 YOLOF 的局部卷积层。结果显示,两者表现差不多,并且,在 AP 的表现上,YOLOF 在深层网络上的收益要比 DETR 更高,ResNet-50 降低了 0.4,ResNet-101 提高了 0.2。有趣的是,我们还发现 YOLOF 在小尺度目标上的表现要比 DETR 更好,而大尺度目标的表现则要差一些。这样的结果与上文关于局部与全局的讨论一致。更重要的是,相较于 DETR,YOLOF 更快,大约有 7 倍的速度,这也就使得 YOLOF 比 DETR 更适合作为单层级检测器的基准测试程序。
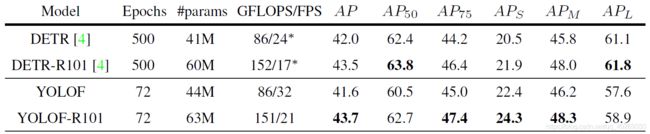
表 2 在COCO2017验证集上与 DETR 的比较。我们基于骨干网络 ResNet-50 和 ResNet-101 开展了对比实验。为了公平起见,YOLOF 在 “ 6 × 6 \times 6×” 的情况下进行多尺度训练,大约 72 个 epoch。对于 DETR 的 FPS 项来说, ∗ * ∗ 表示我们依照原文章中提到的方法在 2080Ti 上重新测量的结果。
Comparison with YOLOv4
YOLOv4 是一个既快速又准确的多层级特征检测器。它结合了许多优异技术达到了一个目前最优结果的状态。因为我们的目的主要是为单层级检测器创造一个简单且快速的基准程序,所以在 BoF 技术方面的调查就不在我们此次工作的范围之内。因此我们并没有期望得到一个严格一致的性能对比。为了将 YOLOF 与 YOLOv4 进行对比,我们使用了 YOLOv4 中的数据增广方法,采用了三段式的训练流程,并适当修改训练配置,并在骨干网络的最后一部分加入了膨胀系数(表 3 中的 YOLOF-DC5)。更多模型细节与训练配置参见附录。如表 3 中所示,YOLOF-DC5 在提高了 0.8 mAP 的情况下,还要比 YOLOv4 快 13%。但是在小尺度目标上,YOLOF-DC5 的表现就不如 YOLOv4 的结果,但是在大尺度目标上,YOLOF-DC5 的表现则与 YOLOv4 拉开了较大的差距,有 7.1 mAP 的差距。以上结果表明,单层级特征检测器有很大的潜力,同时在速度与精确度两方面取得目前最好的效果。

表 3 在 COCO test-dev 数据集上,同 YOLOv4 的对比。我们采用 “ 15 × 15 \times 15×” (184 个 epoch) 来训练 YOLOF-DC5,并将之与 YOLOv4 进行比较。在表中, † \dag † 表示 YOLOF-DC5 的 FPS 采用 YOLOv4 中的方式进行测量。它与表 1、2 中用到的方法不同。在 YOLOv4 中,作者将卷积层和 batch normalization 层融合在了一起,然后测量半精度浮点模型的推理时间。 ∗ * ∗ 表示我们从官方仓库中得到的 YOLOv4 在 2080 Ti 上的速度。官方仓库是:https://github.com/AlexeyAB/darknet#geforce-rtx-2080-ti
5.2 Ablation Experiments
我们开展了多个 YOLOF 的消融实验以进行分析。我们首先对我们提出的两项技术进行了总体得得实验分析。然后,我们对每个部分开展了详细的消融实验。结果如表4、5 所示,接下来进行详细讨论分析。

表 4 骨干网络为 ResNet-50 时,Dilated Encoder 和 Uniform Matching 的影响。这两个模块使得原始的单特征检测器性能提高了 16.6 mAP。我们需要注意,21.1 mAP 的结果并不是 bug,这比图 1 和图 3 中展示的 SiSo编码器的结果(23.7 mAP)还要差一些,是因为 YOLOF 中解码器的设计 —— 它在分类模块中仅有两个卷积层。
Dilated Encoder and Uniform Matching
表 4 显示了 Dilated Encoder 和 Uniform Matching 对 YOLOF 来说都是必须存在的,这两者能够带来相当高的性能提升。具体来说,Dilated Encoder 在大尺度目标上有着显著的性能提升(从 43.8 mAP 提升到了 53.2 mAP),但对小尺度目标和中等尺度目标的提升则不明显。这也表明了,有限的尺度范围对于 C5 特征来说,是一个很严峻的问题。而我们的 Dilated Encoder 就为这个问题提供了简单且有效的解决方案。此外,在小尺度目标和中等尺度目标上,不使用 Uniform Matching 的情况下性能大幅下降,差不多有 10 mAP 之多;而对于大尺度目标来说,影响则不是很大,只有 3 左右。这种结果,与前文所分析的正值锚框不平衡的问题,相一致。正值锚框受大尺度目标影响决定,也就使得在小尺度目标和中等尺度目标上的表现较差。最后,当我们将 Dilated Encoder 和 Uniform Matching 都移除之后,单特征检测器的性能表现跌落到了 20 mAP 左右,像图 1 和图 3 中展示的那样。
Number of ResBlock
在 YOLOF 的 SiSo 编码器当中,我们堆叠了一些残差块。表 5a 中的结果表明残差块堆叠越多,在大尺度目标上就会收获更多的性能提升;这是因为残差块数量的增加提升了特征尺度范围。尽管我们发现残差块越多性能越好,并且没有出现性能下降的情况,我们仍然选择了堆叠 4 个残差块,以保持 YOLOF 的简单与整洁。
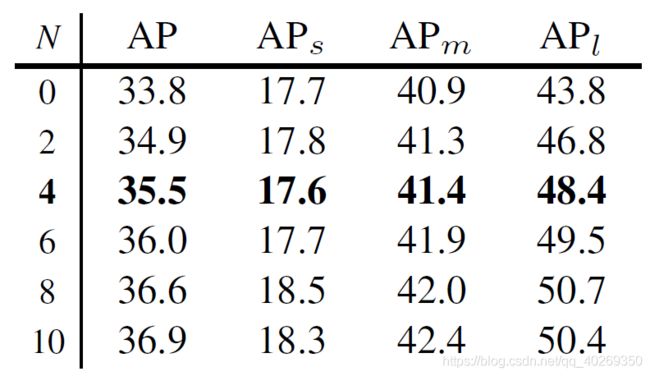
表 5a ResNet-50 中,Number of ResBlocks 残差块越多,带来的增益越高**。 N N N** 表示残差块的数量。为了保持 YOLOF 的简单与整洁,我们默认在编码器当中加入 4 个残差块。
Different dilations
根据前面 4.1 章节的分析,为了使 C5 特征能够覆盖大尺度特征,我们将残差块中标准的 3*3 卷积层替换为了同等效果的空洞卷积层。表 5b 展示了残差块中不同空洞大小的结果。残差块中空洞卷积的引入,提升了 YOLOF 的性能表现,但是空洞系数太大又会使得性能提升饱和。我们猜测,是因为 2、4、6、8 的空洞系数,已经足够匹配图像中所有目标的尺度了。

表 5b Different dilations,骨干网络为 ResNet-50-N4:“N4” 表示我们在编码器中加入了 4 个残差块。残差块中的空洞系数使得检测器在大尺度目标上获得了很大的增益,而在小尺度目标和中等尺度目标上收益较小。
Add shortcut or not
表 5c 展示了在 Dilated Encoder 中,shortcut起着不可或缺的作用。如果残差块中不使用shortcut 技术,各种目标尺度上的性能表现都会下降。根据 4.1 章节的分析,shortcut 技术会将不同的尺度范围结合起来。A largely and densely paved scale range covered by the feature is the critical factor for detecting all objects in a single-level feature manner。
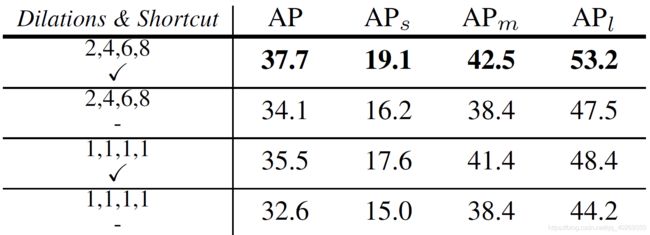
表 5c 骨干网络为 ResNet-50,Add shortcut or not:在两种不同的空洞系数的情况下,是否加入 shortcut 的不同的结果。shortcut 在小、中、大尺度目标上均带来了相当多的性能增益,因此在使用空洞卷积的情况下显得更重要了。全 1 时提升了 2.9 mAP,为 2、4、6、8 时提升了 3.6 mAP.
Number of positives
表 5d 展示了在真值框生成不同数量正值锚框 positive anchors 的情况下的比较。直观来讲,正值锚框越多,性能表现越好,因为给的样本越多,学习起来就越容易。因此,在我们提出的均匀匹配方法中,我们依照经验,来一点一点增加真值框生成的正值锚框的数量。如表 5d 中所展示的那样,超参数 k k k 在大于 1 的时候,在性能表现上有着很好的鲁棒性,这也就说明了 YOLOF 中最重要的就是均匀匹配方法。最后,在均匀匹配方法中,我们将超参数设定为了 4 来达到最优结果。
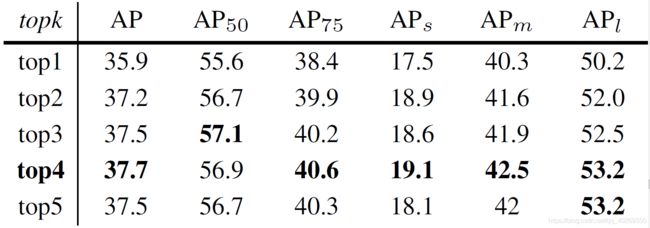
表 5d 骨干网络为 ResNet-50-N4,Number of positives:均匀匹配方法中正值锚框数量对性能表现的影响。正值锚框数量的增加,能够提升性能,但太多的话就会性能饱和甚至下降。在 YOLOF 中,我们选择 4 个正值锚框来达到一个最优表现。
Uniform Matching v s . vs. vs. other matchings
在 YOLOF 中,我们将均匀匹配方法同其它匹配方法也进行了比较,结果如表 5e 所示。均匀匹配策略能够取得最好的结果,并同时兼顾了如图 6 中所示的不平衡的问题。值得注意的是,Hungarian matching 策略可大致看作是 top1 策略,该策略可参考表 5d,因此 Hungarian matching 与 top1 策略有着相近的表现。这两者之间的区别就是,Hungarian matching 策略中一个锚框仅能匹配一个目标物体,而 Top1 并没有限制;试验结果表明,这一点区别并不重要。源 ATSS 中提到 Top9 的选择是最优的,而我们发现 top15 在单层级特征上有着更好的表现。在应用 top15 的情况下,ATSS 取得了 36.5 mAP 的好成绩,然而依旧落后均匀匹配方法 1.2 mAP。
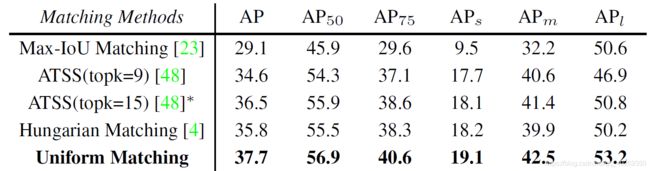
表 5e Uniform matching vs. other matchings (ResNet-50-N4):均匀匹配与其他匹配方法的比较。均匀匹配在正值锚框上达到了平衡的效果,并且相较于其他匹配方法有着最好的结果,这也与图 6 展示的一致。需要注意, ∗ * ∗ 表示在 ATSS 中,topk=15 时才是最优结果。更多细节参考附录。
5.3 Error Analysis
本章节我们对 YOLOF 开展误差分析,以为将来单层级特征检测器的研究提供思路灵感。我们使用 TIDE 工具来比较 YOLOF 和 DETR。如图 7 所示,DETR 比 YOLOF 有着更大的定位误差,这一点可能与 DETR 的回归机制有关。DETR 在回归时采取完全无锚框的方式,并在整张图像上全局地预测目标位置,这也就导致定位的困难。相比之下,YOLOF 依赖于预定义的锚框,这也就导致 YOLOF 在预测阶段,比 DETR 有着更高的丢失误差。根据 4.2 章节的分析,YOLOF 的锚框比较稀疏,且在推理阶段不够灵活。直观来讲,就是真值框附近没有高质量的预定义锚框。因此,在 YOLOF 中引入无锚框机制可能会缓解这个丢失误差的问题,这一点也将会在未来的工作中开展。
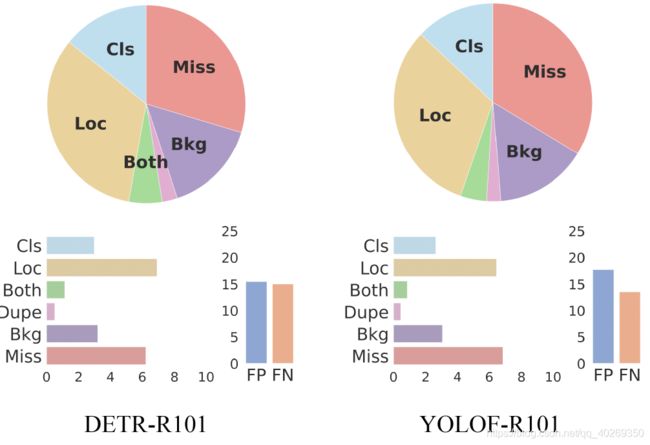
图 7 DETR-R101 和 YOLOF-R101 之间的误差分析。根据 TIDE 的结果,本图展示了六种误差:Cls 为 classiffication error 分类误差;Loc 为 localization error 定位误差;Both 为 分类定位误差;Dupe 为 duplicate predictions error 重复预测误差;Bkg 为 background error 背景误差;Miss 为 missing error 丢失误差。饼状图展示了各种误差之间的占比关系,柱状图展示了误差的绝对量。FP 和 FN 表示 False positive 和 False Negative。
6. Conclusion
在本次研究工作中,我们发现了 FPN 的成功,要归功于稠密目标检测任务中优化问题的分治法 divide-and-conquer 解决方案。鉴于 FPN 使得网络结构变得很复杂,且带来了内存负担,减慢检测器速度,我们提出了一种不使用 FPN 的,简单且高效的方法来处理这一优化问题,并命名为 YOLOF。我们通过与 RetinaNet 和 DETR 进行平等对比实验证明了它的有效性。我们希望 YOLOF 能够成为一种基准测试程序,并且还提供了在未来单特征检测器研究中的一些灵感。
Appendix A: More Details
Detailed Structures of All Encoders
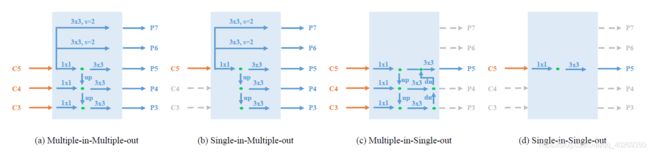
图 8 MiMo、SiMo、MiSo、SiSo 编码器的详细结构
在图 8 中,我们提供了四种不同编码器生成输出的详细过程。这四种编码器的输入输出数量不同:
- The Multiple-in-Multiple-out encoder:接收骨干网络输出的三种层级的特征输出,并输出五种层级特征。MiMo 编码器的结构和 RetinaNet 中的 FPN 结构相同;
- Single-in-Multiple-out:仅仅使用 C5 特征作为输入;由于再没有其他输入,这里移除了为 C3、C4 设计的 1*1 的卷积层;
- Multiple-in-Single-out:接收三个输入特征而仅生成一个输出特征 P5。为了完全利用到输入的三个特征,这里使用了同 PANet 相似的结构;
- Single-in-Single-out:这里移除了所有其他的卷积层而仅仅保留 C5 的卷积层。
Network Architecture of YOLOF
图 9 展示了 YOLOF 的详细结构。YOLOF 使用单特征进行目标检测,这非常简单。我们的方法由三个部分组成:骨干网络、编码器、解码器。详细组成在 4.3 章节。

图 9 YOLOF 框架图。主要包含三个部分:骨干网络、编码器、解码器。图中的 “C5/DC5” 表示带有 32/16 下采样率的骨干网络的输出特征;“ C o u t C_{out} Cout” 表示特征的通道数。在编码器和解码器中,我们将特征图的通道数设定为 512。 H × W H \times W H×W 表示特征图的高和宽。
Training Time & Memory
本章节主要比较 YOLOF、DETR 以及 RetinaNet+ 之间的训练时间与训练内存占用。如表 6 所示,由于长训练策略,DETR 在 8 张 2080Ti 上需要对 COCO 数据集训练 112.5 小时,而 YOLOF 和 RetinaNet+ 仅需要 4.5 小时以及 9.8 小时。至于内存占用方面,YOLOF 需要的最少,这也就意味着 YOLOF 的 batch size 可以设置得更大,训练得更快。

表 6 三种不同模型之间内存占用以及训练时间占用。所有的训练,都在 8 张 2080 Ti 上进行。
More Implementation Detail
YOLOF 的默认训练配置为:mini-batch 设置为 64,既每张 GPU 8 张图片,初始学习率为 0.12。而对于 ResNeXt-101 来说,batch size 为 32,每张 GPU 4 张图片,初始学习率为 0.06。在多尺度训练中,DETR 使用随机裁切加重置大小的方法来模拟大图像。在 YOLOF 中,我们则只是简单的将图像放大到大图像大小。在多尺度训练中,我们根据 HTC 的方法,通过在 [400, 1400] 中随机采样的方式,来讲图像的最长边控制到不超过 1600 像素。
Detailed Setting to Compare with YOLOv4
为了赶上 YOLOv4 的性能表现,我们首先将空洞残差块的数量由 4 增加到了 8。然后根据实验结果,调整空洞残差块的空洞系数。最终我们发现, [ 1 ; 2 ; 3 ; 4 ; 5 ; 6 ; 7 ; 8 ] [1; 2; 3; 4; 5; 6; 7; 8] [1;2;3;4;5;6;7;8] 的效果最好。然后,我们依照 YOLOv4,参考其数据增广方法,并采用 CSPDarkNet-53 作为骨干网络,替换掉所有的 batch normalization 层,并在编码器中使用 LeakyReLu 作为激活函数,在解码器中使用 ReLU 作为激活函数。根据表 9 的结果,YOLOF-DC5 的表现要比 YOLOF 更好(YOLOF-DC5 的性能表现参考表 3)。因此本部分我们采用 YOLOF-DC5 作为基准。然后,我们先将整个模型的初始学习率设定为 0.04。为了训练出最终的模型,我们将训练过程分为了三段:第一段,将 YOLOF-DC5 的训练设为了 “ 9 × 9 \times 9×”;第二段,将负值锚框的阈值从 0.75 增加到了 0.8,并基于上一步的结果,进行 “ 3 × 3 \times 3×” 的训练;最后,根据 SWA 中的方法再进行 “ 3 × 3\times 3×” 的训练。表 3 中的结果就是这样得来的。

表 9 YOLOF-DC5 使用把不同骨干网络后在 COCO 验证集上的结果。 ∗ * ∗ 表示由于 2080Ti 显存的限制,我们在 ResNet-101 网络上设置 batch size 为 32,每张 GPU 4 张图像。如果每张 GPU 8 张图像或者应用 SyncBN,则会有更高的性能表现。
Appendix B: Additional Experimental Results
Number of Anchors
在 RetinaNet 网络中,锚框是在 3232 到 512512 范围上,从多种层级的特征(P3 - P7)上分别生成的。在每一层级的特征上,RetinaNet 都会使用大小为 { 2 0 , 2 1 / 3 , 2 2 / 3 } \{2^0, 2^{1/3}, 2^{2/3} \} {20,21/3,22/3} 且长宽比率为 { 0.5 , 1 , 2 } \{ 0.5, 1, 2 \} {0.5,1,2} 的锚框。然而在 YOLOF 当中,我们仅有一种特征来放置锚框。为了覆盖全部目标的尺度,我们还在单特征图中加入了 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \{ 32^2, 64^2, 128^2, 256^2, 512^2 \} {322,642,1282,2562,5122} 大小区域的锚框,且大小为 1,长宽比率为 1,并在每个位置生成 5 个锚框。此外,我们还调查了 YOLOF 中,更多锚框产生的影响。根据 RetinaNet 中的方式,我们在每个位置生成了大小为 { 2 0 , 2 1 / 3 , 2 2 / 3 } \{ 2^0, 2^{1/3}, 2^{2/3} \} {20,21/3,22/3} 、长宽比率为 { 0.5 , 1 , 2 } \{ 0.5, 1, 2 \} {0.5,1,2} 的,45 个锚框。结果如表 7 所示。结果显示,长宽比并不影响最终表现。因此我们就默认选择了最小的。

表 7 YOLOF 中不同情况锚框下的结果。
Hyper-parameter of ATSS
我们还提供了 ATSS 中,不同 k 值所产生的不同结果。结果显示,源论文中,k = 9 对于 YOLOF 来说并不是最优选择。根据实验结果,本文中我们将 k 设定为 15。
Results with Dilated C5
本文展示了使用 C5 特征,YOLOF 也可以表现出很好的效果。为了进一步提高 YOLOF 的性能,我们使用高分辨率的特征图来进行目标检测。参考 DETR 中的方式,we construct a backbone with dilation and without stride on its last stage。骨干网络的输出命名为 DC5,下采样率为 16 倍。在表 9 中,分别展示了在骨干网络为 ResNet-50 和 ResNet-101 的情况下,在 COCO 验证集上 YOLOF-DC5 的结果。YOLOF-DC5 比原始的 YOLOF 有着更高的性能表现,但是速度却更慢,这是因为DC5 特征的分辨率比 C5 的更高。YOLOF-DC5 所做的改动如下:锚框变小,每个位置便生成了 6 个( { 16 , 32 , 64 , 128 , 256 , 512 } \{ 16,32,64,128,256,512 \} {16,32,64,128,256,512}),然后将 topk 从 4 增加到 8,并将正值锚框 positive anchor 的阈值从 0.15 增加到了 0.1。其他配置与 YOLOF 相同。