【论文翻译】Fully Convolutional Networks for Semantic Segmentation
论文题目:Fully Convolutional Networks for Semantic Segmentation
论文来源:Fully Convolutional Networks for Semantic Segmentation_2015_CVPR
翻译人:BDML@CQUT实验室
Fully Convolutional Networks for Semantic Segmentation
用于语义分割的全卷积网络
Abstract
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixelsto-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build “fully convolutional” networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet [20], the VGG net [31], and GoogLeNet [32]) into fully convolutional networks and transfer their learned representations by fine-tuning [3] to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional net-work achieves stateof-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes less than one fifth of a second for a typical image.
摘要
卷积网络是可以产生特征层次的强大可视化模型。我们表明,卷积网络本身,经过端到端,像素到像素的训练,在语义分割方面超过了最先进的水平。我们的主要见解是建立“ 全卷积”网络,该网络可接受任意大小的输入,并通过有效的推理和学习产生相应大小的输出。我们定义并详细说明了完全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并阐述了与先前模型的联系。我们将当代分类网络(AlexNet [20]、VGG网络[31]和GoogLeNet [32])改造成完全卷积网络,并通过微调[3]将它们的学习表示转移到分割任务中。然后,我们定义了一个跳跃结构,它将来自深度粗糙层的语义信息与来自浅层精细层的外观信息相结合,以生成准确和详细的分割。我们的全卷积网络实现了对PASCAL VOC(相对于2012年62.2%的平均IU改进率为20%)、NYUDv2和SIFT Flow的最先进的分割,而对于典型的图像,推断时间不到五分之一秒。
1. 解决了输入大小尺寸限制问题
2. 将经典分类网络改造成全卷积网络,开创了语义分割的先河,实现了像素级别(end-to-end)的分类预测
3. 实现了对PASCAL VOC、NYUDv2和SIFT Flow的最先进的分割
4. 主要技术贡献(卷积化、跳跃连接、反卷积)
1.Introduction
Convolutional networks are driving advances in recognition. Convnets are not only improving for whole-image classification [20, 31, 32], but also making progress on local tasks with structured output. These include advances in bounding box object detection [29, 10, 17], part and keypoint prediction [39, 24], and local correspondence [24, 8].
The natural next step in the progression from coarse to fine inference is to make a prediction at every pixel. Prior approaches have used convnets for semantic segmentation [27, 2, 7, 28, 15, 13, 9], in which each pixel is labeled with the class of its enclosing object or region, but with shortcomings that this work addresses.

We show that a fully convolutional network (FCN) trained end-to-end, pixels-to-pixels on semantic segmentation exceeds the state-of-the-art without further machinery. To our knowledge, this is the first work to train FCNs end-to-end (1) for pixelwise prediction and (2) from supervised pre-training. Fully convolutional versions of existing networks predict dense outputs from arbitrary-sized inputs. Both learning and inference are performed whole-image-ata-time by dense feedforward computation and backpropagation. In-network upsampling layers enable pixelwise prediction and learning in nets with subsampled pooling.
This method is efficient, both asymptotically and absolutely, and precludes the need for the compli-cations in other works. Patchwise training is common [27, 2, 7, 28, 9], but lacks the efficiency of fully convolutional training. Our approach does not make use of pre- and post-processing complications, including superpixels [7, 15], proposals [15, 13], or post-hoc refinement by random fields or local class-ifiers [7, 15]. Our model transfers recent success in classification [20, 31, 32] to dense prediction by reinterpreting classification nets as fully convolutional and fine-tuning from their learned representa-tions. In contrast, previous works haveappliedsmallconvnetswithoutsupervisedpre-training [7, 28, 27].
Semantic segmentation faces an inherent tension between semantics and location: global information resolves what while local information resolves where. Deep feature hierarchies encode location and semantics in a nonlinear local-to-global pyramid. We define a skip architecture to take advantage of this feature spectrum that combines deep, coarse, semantic information and shallow, fine, appearance information in Section 4.2 (see Figure 3).
In the next section, we review related work on deep classification nets, FCNs, and recent approaches to semantic segmentation using convnets. The following sections explain FCN design and dense prediction tradeoffs, introduce our architecture with in-network upsampling and multilayer combinations, and describe our experimental framework. Finally, we demonstrate state-of-the-art results on PASCAL VOC 2011-2, NYUDv2, and SIFT Flow.
1.引言
卷积网络正在推动识别技术的进步。卷积网络不仅在改善了整体图像分类[20,31,32],而且还在具有结构化输出的局部任务上也取得了进展。这些进展包括边界框目标检测[29,10,17],部分和关键点预测[39,24],以及局部对应[24,8]。
从粗略推断到精细推理,很自然下一步是对每个像素进行预测。先前的方法已经使用了卷积网络用于语义分割[27,2,7,28,15,13,9],其中每个像素都用其包围的对象或区域的类别来标记,但是存在该工作要解决的缺点。
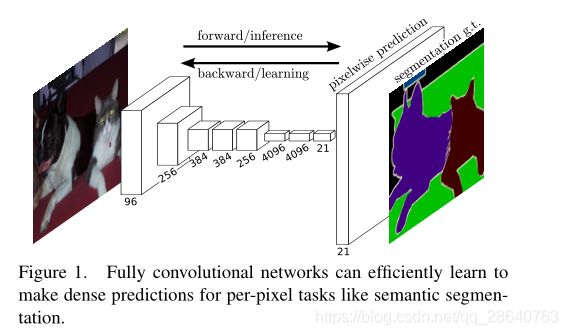
图中21代表PASCAL VOC数据集P,总共 20 个小类(加背景 21 类)
我们表明了在语义分割上,经过端到端,像素到像素训练的完全卷积网络(FCN)超过了最新技术,而无需其他机制。据我们所知,这是第一个从(2)有监督的预训练,端到端训练地FCN(1)用于像素预测。现有网络的完全卷积版本可以预测来自任意大小输入的密集输出。学习和推理都是通过密集的前馈计算和反向传播在整个图像上进行的。网络内上采样层通过子采样池化来实现网络中的像素预测和学习。
这种方法在渐近性和绝对性两方面都是有效的,并且排除了对其他工作中的复杂性的需要。逐块训练是很常见的[27,2,8,28,11],但缺乏完全卷积训练的效率。我们的方法没有利用前后处理的复杂性,包括超像素[8,16],建议[16,14],或通过随机字段或局部分类器进行事后细化[8,16]。我们的模型通过将分类网络重新解释为完全卷积并从其学习的表示中进行微调,将最近在分类任务[19,31,32]中取得的成功转移到密集预测任务。相比之下,以前的工作是在没有经过有监督的预训练的情况下应用了小型卷积网络[7,28,27]。
语义分割面临着语义和位置之间的固有矛盾:全局信息解决了什么,而局部信息解决了什么。 深度特征层次结构以非线性的局部到全局金字塔形式对位置和语义进行编码。 在4.2节中,我们定义了一个跳跃结构来充分利用这种结合了深层,粗略,语义信息和浅层,精细,外观信息的特征谱(请参见图3)。
在下一节中,我们将回顾有关深度分类网,FCN和使用卷积网络进行语义分割的最新方法的相关工作。 以下各节介绍了FCN设计和密集的预测权衡,介绍了我们的具有网络内上采样和多层组合的架构,并描述了我们的实验框架。 最后,我们演示了PASCAL VOC 2011-2,NYUDv2和SIFT Flow的最新结果。
介绍卷积的概念,以及如何过渡到要进行像素预测的一个想法,然后介绍了FCN主要的一些贡献,包括可以任意大小的输入,skip结构等,以及最后的实验结果。
2.Related work
Our approach draws on recent successes of deep nets for image classification [20, 31, 32] and transfer learning [3, 38]. Transfer was first demonstrated on various visual recognition tasks [3, 38], then on detection, and on both instance and semantic segmentation in hybrid proposalclassifier models [10, 15, 13]. We now re-architect and finetune classification nets to direct, dense prediction of semantic seg-mentation. We chart the space of FCNs and situate prior models, both historical and recent, in this framework.
Fully convolutional networks To our knowledge, the idea of extending a convnet to arbitrary-sized inputs first appeared in Matan et al. [26], which extended the classic LeNet [21] to recognize strings of digits. Because their net was limited to one-dimensional input strings, Matan et al. used Viterbi decoding to obtain their outputs. Wolf and Platt [37] expand convnet outputs to 2-dimensional maps of detection scores for the four corners of postal address blocks. Both of these historical works do inference and learning fully convolutionally for detection. Ning et al. [27] define a convnet for coarse multiclass segmentation of C. elegans tissues with fully convolutional inference.
Fully convolutional computation has also been exploited in the present era of many-layered nets. Sliding window detection by Sermanet et al. [29], semantic segmentation by Pinheiro and Collobert [28], and image restoration by Eigen et al. [4] do fully convolutional inference. Fully convolutional training is rare, but used effectively by Tompson et al. [35] to learn an end-to-end part detector and spatial model for pose estimation, although they do not exposit on or analyze this method.
Alternatively, He et al. [17] discard the nonconvolutional portion of classification nets to make a feature extractor. They combine proposals and spatial pyramid pooling to yield a localized, fixed-length feature for classification. While fast and effective, this hybrid model cannot be learned end-to-end.
Dense prediction with convnets Several recent works have applied convnets to dense prediction problems, including semantic segmentation by Ning et al. [27], Farabet et al.[7], and Pinheiro and Collobert [28]; boundary prediction for electron microscopy by Ciresan et al. [2] and for natural images by a hybrid convnet/nearest neighbor model by Ganin and Lempitsky [9]; and image restoration and depth estimation by Eigen et al. [4, 5]. Common elements of these approaches include
• small models restricting capacity and receptive fields;
• patchwise training [27, 2, 7, 28, 9];
• post-processing by superpixel projection, random field regularization, filtering, or local classification [7, 2, 9];
• input shifting and output interlacing for dense output [29, 28, 9];
• multi-scale pyramid processing [7, 28, 9];
• saturating tanh nonlinearities [7, 4, 28]; and
• ensembles [2, 9],
whereas our method does without this machinery. However, we do study patchwise training 3.4 and “shift-and-stitch” dense output 3.2 from the perspective of FCNs. We also discuss in-network upsamp-ling 3.3, of which the fully connected prediction by Eigen et al. [5] is a special case.
Unlike these existing methods, we adapt and extend deep classification architectures, using image classification as supervised pre-training, and fine-tune fully convolutionally to learn simply and eff-iciently from whole image inputs and whole image ground thruths.
Hariharan et al. [15] and Gupta et al. [13] likewise adapt deep classification nets to semantic segmen-tation, but do so in hybrid proposal-classifier models. These approaches fine-tune an R-CNN system [10] by sampling bounding boxes and/or region proposals for detection, semantic segmentation, and instance segmentation. Neither method is learned end-to-end. They achieve state-of-the-art segmen-tation results on PASCAL VOC and NYUDv2 respectively, so we directly compare our standalone, end-to-end FCN to their semantic segmentation results in Section 5.
We fuse features across layers to defineanonlinearlocalto-global representation that we tune end-to-end. In contemporary work Hariharan et al. [16] also use multiple layers in their hybrid model for se-mantic segmentation.
2.相关工作
我们的方法借鉴了最近成功的用于图像分类[20, 31, 32]和迁移学习[3,38]的深度网络。迁移首先在各种视觉识别任务[3,38],然后是检测,以及混合提议分类器模型中的实例和语义分割任务[10,15,13]上进行了演示。我们现在重新构建和微调分类网络,来直接,密集地预测语义分割。我们绘制了FCN的空间,并在此框架中放置了历史和近期的先前模型。
全卷积网络 据我们所知,Matan等人首先提出了将一个卷积网络扩展到任意大小的输入的想法。 [26],它扩展了classicLeNet [21]来识别数字串。因为他们的网络被限制为一维输入字符串,所以Matan等人使用Viterbi解码来获得它们的输出。Wolf和Platt [37]将卷积网络输出扩展为邮政地址块四个角的检测分数的二维图。这两个历史工作都是通过完全卷积进行推理和学习,以便进行检测。 宁等人 [27]定义了一个卷积网络,通过完全卷积推理对秀丽隐杆线虫组织进行粗多类分割。
在当前的多层网络时代,全卷积计算也已经得到了利用。Sermanet等人的滑动窗口检测 [29],Pinheiro和Collobert [28]的语义分割,以及Eigen等人的图像恢复 [4]都做了全卷积推理。全卷积训练很少见,但Tompson等人有效地使用了它 [35]来学习一个端到端的部分探测器和用于姿势估计的空间模型,尽管他们没有对这个方法进行解释或分析。
或者,He等人 [17]丢弃分类网络的非卷积部分来制作特征提取器。它们结合了建议和空间金字塔池,以产生用于一个局部化,固定长度特征的分类。虽然快速有效,但这种混合模型无法进行端到端地学习。
用卷积网络进行密集预测 最近的一些研究已经将卷积网络应用于密集预测问题,包括Ning等[27],Farabet等[7],Pinheiro和Collobert 等[28] ;Ciresan等人的电子显微镜边界预测[2],Ganin和Lempitsky的混合卷积网络/最近邻模型的自然图像边界预测[9];Eigen等人的图像恢复和深度估计 [4,5]。这些方法的共同要素包括:
• 限制容量和感受野的小模型;
• 逐块训练[27, 2, 7, 28, 9];
• 有超像素投影,随机场正则化,滤波或局部分类[7,2,9]的后处理过程;
• 密集输出的输入移位和输出交错[29,28,9];
• 多尺度金字塔处理[7,28,9];
• 饱和tanh非线性[7,4,28];
• 集成[2,9]
而我们的方法没有这种机制。然而,我们从FCN的角度研究了逐块训练3.4节和“移位 - 连接”密集输出3.2节。我们还讨论了网络内上采样3.3节,其中Eigen等人的全连接预测 [6]是一个特例。
与这些现有方法不同,我们采用并扩展了深度分类架构,使用图像分类作为有监督的预训练,并通过全卷积微调,以简单有效的从整个图像输入和整个图像的Ground Truths中学习。
在机器学习中ground truth表示有监督学习的训练集的分类准确性,用于证明或者推翻某个假设。有监督的机器学习会对训练数据打标记,试想一下如果训练标记错误,那么将会对测试数据的预测产生影响,因此这里将那些正确打标记的数据成为ground truth。
Hariharan等人 [15]和Gupta等人 [13]同样使深度分类网适应语义分割,但只在混合建议 - 分类器模型中这样做。这些方法通过对边界框和/或候选域采样来微调R-CNN系统[10],以进行检测,语义分割和实例分割。这两种方法都不是端到端学习的。他们分别在PASCAL VOC和NYUDv2实现了最先进的分割成果,因此我们直接在第5节中将我们的独立端到端FCN与他们的语义分割结果进行比较。
我们融合各层的特征去定义一个我们端到端调整的非线性局部到全局的表示。在当代工作中,Hariharan等人[16]也在其混合模型中使用了多层来进行语义分割。
介绍了FCN中关键部分的全卷积网络和密集预测的研究现状
3.Fully convolutional networks
Each layer of data in a convnet is a three-dimensional array of size h × w × d, where h and w are spatial dimensions, and d is the feature or channel dimension. The first layer is the image, with pixel size h × w, and d color channels. Locations in higher layers correspond to the locations in the image they are path-connected to, which are called their receptive fields.
Convnets are built on translation invariance. Their basic components (convolution, pooling, and acti-vation functions) operate on local input regions, and depend only on relative spatial coordinates. Writ-ing X i j X_{ij} Xijfor the data vector at location (i, j) in a particular layer, and y i j y_{ij} yij for the following layer, these functions compute outputs y i j y_{ij} yij by
y i j = f k s ( { x s i + δ i , s j + δ j } 0 ≤ δ i , δ j ≤ k ) y_{ij} = f_{ks}(\{x_{si+\delta i,sj+\delta j}\}_{0\le \delta i,\delta j \le k}) yij=fks({xsi+δi,sj+δj}0≤δi,δj≤k)
where k is called the kernel size, s is the stride or subsampling factor, and f k s f_{ks} fks determines the layer type: a matrix multiplication for convolution or average pooling, a spatial max for max pooling, or an elementwise nonlinearity for an activation function, and so on for other types of layers.
This functional form is maintained under composition,with kernel size and stride obeying the trans-formation rule
f k s ∘ g k ′ s ′ = ( f ∘ g ) k ′ + ( k − 1 ) s ′ , s s ′ . f_{ks}\circ g_{k's'} = (f\circ g)_{k'+(k-1)s',ss'}. fks∘gk′s′=(f∘g)k′+(k−1)s′,ss′.
While a general deep net computes a general nonlinear function, a net with only layers of this form computes a nonlinear filter, which we call a deep filter or fully convolutional network. An FCN naturally operates on an input of any size, and produces an output of corresponding (possibly resampled) spatial dimensions.
A real-valued loss function composed with an FCN defines a task. If the loss function is a sum over the spatial dimensions of the final layer, l ( x ; θ ) = ∑ i j l ′ ( x i j ; θ ) l(x;θ) =\sum_{ ij}l'(x_{ij};θ) l(x;θ)=∑ijl′(xij;θ), its gradient will be a sum over the gra-dients of each of its spatial components. Thus stochastic gradient descent on l l l computed on whole images will be the same as stochastic gradient descent on l ′ l' l′, taking all of the final layer receptive fields as a minibatch.
When these receptive fields overlap significantly, both feedforward computation and backpropagation are much more efficient when computed layer-by-layer over an entire image instead of independently patch-by-patch.
We next explain how to convert classification nets into fully convolutional nets that produce coarse output maps. For pixelwise prediction, we need to connect these coarse outputs back to the pixels. Section 3.2 describes a trick, fast scanning [11], introduced for this purpose. We gain insight into this trick by reinterpreting it as an equivalent network modification. As an efficient, effective alternative, we introduce deconvolution layers for upsampling in Section 3.3. In Section 3.4 we consider training by patchwise sampling, and give evidence in Section 4.3 that our whole image training is faster and equally effective.
3.全卷积网络
卷积网络中的每一层数据都是大小为h×w×d的三维数组,其中h和w是空间维度,d是特征或通道维度。第一层是有着像素大小为h×w,以及d个颜色通道的图像,较高层中的位置对应于它们路径连接的图像中的位置,这些位置称为其感受野。
卷及网络建立在平移不变性的基础之上。它们的基本组成部分(卷积,池化和激活函数)作用于局部输入区域,并且仅依赖于相对空间坐标。用 X i j X_{ij} Xij表示特定层位置(x,j)处的数据向量, y i j y_{ij} yij表示下一层的数据向量,可以通过下式来计算 y i j y_{ij} yij:
y i j = f k s ( { x s i + δ i , s j + δ j } 0 ≤ δ i , δ j ≤ k ) y_{ij} = f_{ks}(\{x_{si+\delta i,sj+\delta j}\}_{0\le \delta i,\delta j \le k}) yij=fks({xsi+δi,sj+δj}0≤δi,δj≤k)
其中k称为内核大小,s为步长或者子采样因子, f k s f_{ks} fks决定层的类型:用于卷积或平均池化的矩阵乘法,用于最大池化的空间最大值,或用于激活函数的非线性元素,用于其他类型的层等等。
这种函数形式在组合下维护,内核大小和步长遵守转换规则:
f k s ∘ g k ′ s ′ = ( f ∘ g ) k ′ + ( k − 1 ) s ′ , s s ′ . f_{ks}\circ g_{k's'} = (f\circ g)_{k'+(k-1)s',ss'}. fks∘gk′s′=(f∘g)k′+(k−1)s′,ss′.
当一般的深度网络计算一般的非线性函数,只有这种形式的层的网络计算非线性滤波器,我们称之为深度滤波器或完全卷积网络。FCN自然地对任何大小的输入进行操作,并产生相应(可能重采样)空间维度的输出。
由FCN组成的实值损失函数定义了任务。如果损失函数是最终层的空间维度的总和, l ( x ; θ ) = ∑ i j l ′ ( x i j ; θ ) l(x;θ) =\sum_{ ij}l'(x_{ij};θ) l(x;θ)=∑ijl′(xij;θ),它的梯度将是每个空间分量的梯度之和。因此,对整个图像计算的 l l l 的随机梯度下降将与将所有最终层感受野视为小批量的 l ′ l' l′ 上的随机梯度下降相同。
当这些感受野显着重叠时,前馈计算和反向传播在整个图像上逐层计算而不是单独逐块计算时效率更高。
接下来,我们将解释如何将分类网络转换为产生粗输出图的完全卷积网络。对于逐像素预测,我们需要将这些粗略输出连接回像素。第3.2节为此目的引入了一个技巧,即快速扫描[11]。我们通过将其重新解释为等效的网络修改来深入了解这一技巧。作为一种有效的替代方案,我们在第3.3节中介绍了用于上采样的反卷积层。在第3.4节中,我们考虑了通过逐点抽样进行的训练,并在第4.3节中给出了证据,证明我们的整体图像训练更快且同样有效。
3.1. Adapting classifiers for dense prediction
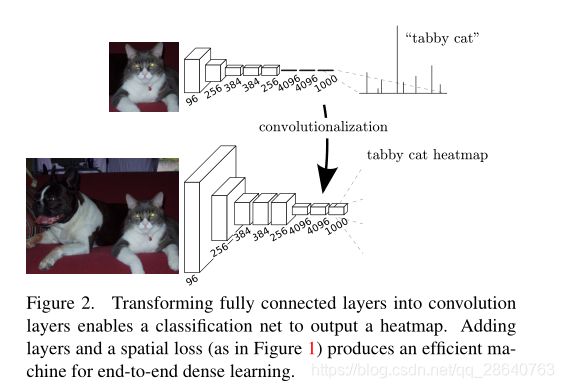
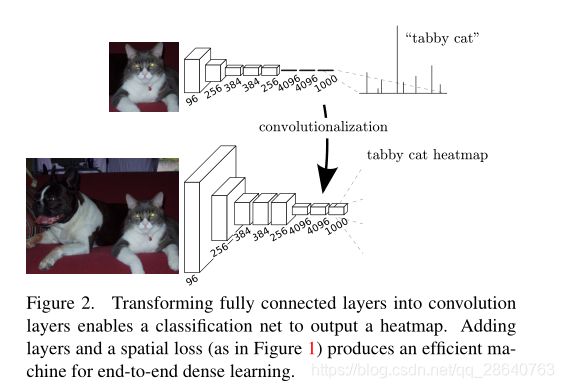
Typical recognition nets, including LeNet [21], AlexNet [20], and its deeper successors [31, 32], ostensibly take fixed-sized inputs and produce non-spatial outputs. The fully connected layers of these nets have fixed dimensions and throw away spatial coordinates. However, these fully connected layers can also be viewed as convolutions with kernels that cover their entire input regions. Doing so casts them into fully convolutional networks that take input of any size and output classification maps. This transformation is illustrated in Figure 2.
Furthermore, while the resulting maps are equivalent to the evaluation of the original net on particular input patches, the computation is highly amortized over the overlapping regions of those patches. For example, while AlexNet takes 1.2 ms (on a typical GPU) to infer the classification scores of a 227×227 image, the fully convolutional net takes 22ms to produce a 10×10 grid of outputs from a 500×500 image, which is more than 5 times faster than the na¨ ıve approach1.
The spatial output maps of these convolutionalized models make them a natural choice for dense problems like semantic segmentation. With ground truth available at every output cell, both the forward and backward passes are straightforward, and both take advantage of the inherent computational efficiency (and aggressive optimization) of convolution. The corresponding backward times for the AlexNet example are 2.4 ms for a single image and 37 ms for a fully convolutional 10 × 10 output map, resulting in a speedup similar to that of the forward pass.
While our reinterpretation of classification nets as fully convolutional yields output maps for inputs of any size, the output dimensions are typically reduced by subsampling. The classification nets sub-sample to keep filters small and computational requirements reasonable. This coarsens the output of a fully convolutional version of these nets, reducing it from the size of the input by a factor equal to the pixel stride of the receptive fields of the output units.
3.1. 调整分类器以进行密集预测
典型的识别网络,包括LeNet [21]、AlexNet [20]及其更深层的后继网络[31、32],表面上接受固定大小的输入并产生非空间输出。这些网络的全连接层具有固定的尺寸并且丢弃了空间坐标。然而,这些完全连接的层也可以被视为具有覆盖其整个输入区域的内核的卷积。这样做将它们转换成完全卷积的网络,该网络可以接受任何大小的输入并输出分类图。这个转换如图2所示。(相比之下,非卷积网,例如Le等人[20]的网络,缺乏这种能力。)
此外,尽管生成的图等效于在特定输入块上对原始网络的评估,但在这些块的重叠区域上进行了高额摊销。例如,虽然AlexNet花费1.2毫秒(在典型的GPU上)来产生 227×227 图像的分类分数,但是全卷积网络需要22毫秒才能从500×500图像中生成10×10的输出网格,比现在的方法快5倍以上。
这些卷积模型的空间输出图使它们成为语义分割等密集问题的自然选择。由于每个输出单元都有可用的Ground Truth,前向和后向传递都很简单,并且都利用了卷积的固有计算效率(和主动优化)。AlexNet示例的相应后向时间对于单个图像是2.4ms,对于完全卷积10×10输出映射是37ms,导致类似于前向传递的加速。
尽管我们将分类网络重新解释为完全卷积,可以得到任何大小的输入的输出图,但输出维度通常通过二次取样来减少。分类网络子采样以保持过滤器较小并且计算要求合理。这使这些网络的完全卷积版本的输出变得粗糙,将其从输入的大小减少到等于输出单元的感受野的像素跨度的因子。
3.2. Shift-and-stitch is filter rarefaction
Dense predictions can be obtained from coarse outputs by stitching together output from shifted versions of the input. If the output is downsampled by a factor of f f f, shift the input x x x pixels to the right and y y y pixels down, once for every ( x x x, y y y) s.t. 0 ≤ x x x, y y y < f f f. Process each of these f 2 f^2 f2inputs, and interlace the outputs so that the predictions correspond to the pixels at the centers of their receptive fields.
Although performing this transformation na¨ ıvely increases the cost by a factor of f 2 f^2 f2, there is a well-known trick for efficiently producing identical results [11, 29] known to the wavelet community as the à trous algorithm [25]. Consider a layer (convolution or pooling) with input stride s, and a subsequent convolution layer with filter weights f i j f_{ij} fij(eliding the irrelevant feature dimensions). Setting the lower layer’s input stride to 1 upsamples its output by a factor of s s s. However, convolving the original filter with the upsampled output does not produce the same result as shift-and-stitch, because the original filter only sees a reduced portion of its (now upsampled) input. To reproduce the trick, rarefy the filter by enlarging it as
f i j ′ = { f i / s , j / s , i f s d i v i d e s b o t h i a n d j ; 0 , o t h e r w i s e , f'_{ij} = \begin{cases} f_{i/s,j/s}, & if s\ divides\ both\ i\ and\ j; \\ 0, & otherwise, \end{cases} fij′={fi/s,j/s,0,ifs divides both i and j;otherwise,
(with i i i and j j j zero-based). Reproducing the full net output of the trick involves repeating this filter enlargement layerby-layer until all subsampling is removed. (In practice, this can be done efficiently by processing subsampled versions of the upsampled input.)
Decreasingsubsamplingwithinanetisatradeoff: thefilters see finer information, but have smaller receptive fields and take longer to compute. The shift-and-stitch trick is another kind of tradeoff: the output is denser without decreasing the receptive field sizes of the filters, but the filters are prohibited from accessing information at a finer scale than their original design.
Although we have done preliminary experiments with this trick, we do not use it in our model. We find learning through upsampling, as described in the next section, to be more effective and efficient, especially when combined with the skip layer fusion described later on.
3.2 移位和拼接是过滤器稀疏
通过输入的不同版本的输出拼接在一起,可以从粗糙的输出中获得密集预测。如果输出被 f f f因子下采样,对于每个( x x x, y y y) ,输入向右移 x x x个像素,向下移 y y y个像素(左上填充),s.t. 0 ≤ x x x, y y y < f f f。
尽管执行这种变换会很自然地使成本增加 f 2 f^2 f2倍,但有一个众所周知的技巧可以有效地产生相同的结果[11,29],小波界称之为à trous算法[25]。考虑一个具有输入步幅 s s s的层(卷积或池化),以及随后的具有滤波器权重 f i j f_{ij} fij的卷积层(省略不相关的特征尺寸)。将较低层的输入步幅设置为1会将其输出向上采样一个系数 s s s。但是,将原始滤波器与向上采样的输出进行卷积不会产生与移位拼接相同的结果,因为原始滤波器只看到其(现在向上采样的)输入的减少部分。要重现该技巧的话,请将过滤器放大为
f i j ′ = { f i / s , j / s , i f s d i v i d e s b o t h i a n d j ; 0 , o t h e r w i s e , f'_{ij} = \begin{cases} f_{i/s,j/s}, & if s\ divides\ both\ i\ and\ j; \\ 0, & otherwise, \end{cases} fij′={fi/s,j/s,0,ifs divides both i and j;otherwise,
(其中 i i i和 j j j从零开始)。再现技巧的完全网络输出涉及逐层重复放大此滤波器,直到删除所有子采样为止。 (实际上,可以通过处理上采样输入的子采样版本来有效地完成此操作。)
减少网络内的二次采样是一个权衡:过滤器看到更精细的信息,但是感受野更小,计算时间更长。移位和拼接技巧是另一种权衡:在不减小滤波器感受野大小的情况下,输出更密集,但是滤波器被禁止以比其原始设计更精细的尺度访问信息。
虽然我们已经用这个技巧做了初步的实验,但是我们没有在我们的模型中使用它。我们发现通过上采样进行学习(如下一节所述)更加有效和高效,尤其是与后面描述的跳跃层融合相结合时。
3.3.Upsampling is backwards strided convolution
Another way to connect coarse outputs to dense pixels is interpolation. For instance, simple bilinear interpolation computes each output y i j y_{ij} yijfrom the nearest four inputs by a linear map that depends only on the relative positions of the input and output cells.
In a sense, upsampling with factor f f f is convolution with a fractional input stride of 1 / f 1/f 1/f. So long as f f f is integral, a natural way to upsample is therefore backwards convolution (sometimes called deconvolution) with an output stride of f f f. Such an operation is trivial to implement, since it simply reverses the forward and backward passes of convolution. Thus upsampling is performed in-network for end-to-end learning by backpropagation from the pixelwise loss.
Note that the deconvolution filter in such a layer need not be fixed (e.g., to bilinear upsampling), but can be learned. A stack of deconvolution layers and activation functions can even learn a nonlinear upsampling.
In our experiments, we find that in-network upsampling is fast and effective for learning dense prediction. Our best segmentation architecture uses these layers to learn to upsample for refined prediction in Section 4.2.
3.3. 上采样是反向跨步的卷积
将粗糙输出连接到密集像素的另一种方法是插值。例如,简单的双线性插值通过一个只依赖于输入和输出单元的相对位置的线性映射,从最近的四个输入计算每个输出 y i j y_{ij} yij。
从某种意义上讲,使用因子 f f f进行上采样是对输入步长为 1 / f 1/f 1/f的卷积。只要 f f f是整数的,那么向上采样的自然方法就是输出步长为 f f f的反向卷积(有时称为反褶积)。这种操作实现起来很简单,因为它只是反转卷积的前进和后退。因此,在网络中进行上采样可以通过像素损失的反向传播进行端到端学习。
注意,这种层中的反卷积滤波器不需要固定(例如,对于双线性上采样),而是可以学习的。反卷积层和激活函数的叠加甚至可以学习非线性上采样。
在我们的实验中,我们发现网络内上采样对于学习密集预测是快速有效的。在第4.2节中,我们的最佳分割架构使用这些层来学习如何对精确预测进行上采样。
3.4.Patchwise training is loss sampling
In stochastic optimization, gradient computation is driven by the training distribution. Both patchwise training and fully convolutional training can be made to produce any distribution, although their relative computational efficiency depends on overlap and minibatch size. Whole image fully convolutional training is identical to patchwise training where each batch consists of all the receptive fields of the units below the loss for an image (or collection of images). While this is more efficient than uniform sampling of patches, it reduces the number of possible batches. However, random selection of patches within an image may be recovered simply. Restricting the loss to a randomly sampled subset of its spatial terms (or, equivalently applying a DropConnect mask [36] between the output and the loss) excludes patches from the gradient computation.
If the kept patches still have significant overlap, fully convolutional computation will still speed up training. If gradients are accumulated over multiple backward passes, batches can include patches from several images.2
Sampling in patchwise training can correct class imbalance [27, 7, 2] and mitigate the spatial correlation of dense patches [28, 15]. In fully convolutional training, class balance can also be achieved by weighting the loss, and loss sampling can be used to address spatial correlation.
We explore training with sampling in Section 4.3, and do not find that it yields faster or better convergence for dense prediction. Whole image training is effective and efficient.
3.4. 逐块训练是采样损失
在随机优化中,梯度计算由训练分布驱动。逐块训练和全卷积训练都可以产生任何分布,尽管它们的相对计算效率取决于重叠和小批量大小。整个图像完全卷积训练与逐块训练相同,其中每一批都包含低于图像(或图像集合)损失的单元的所有感受野。虽然这比批次的均匀采样更有效,但它减少了可能的批次数量。然而随机选择一幅图片中patches可以简单地复现。将损失限制为其空间项的随机采样子集(或者,等效地在输出和损失之间应用DropConnect掩码[36]),将patches排除在梯度计算之外。
patch”, 指一个二维图片中的其中一个小块, 即一张二维图像中有很多个patch. 正如在神经网络的卷积计算中, 图像并不是一整块图像直接同卷积核进行运算, 而是被分成了很多很多个patch分别同卷积核进行卷积运算, 这些patch的大小取决于卷积核的size. 卷积核每次只查看一个patch, 然后移动到另一个patch, 直到图像分成的所有patch都参与完运算. 因为找不到合适的术语,暂不翻译这个词语
如果保留的patches仍然有明显的重叠,全卷积计算仍将加速训练。如果梯度是通过多次向后传播累积的,批次可以包括来自多个图像的patches 2 ^2 2
在逐块训练中采样可以纠正类不平衡[27,7,2]并减轻密集patches的空间相关性[28,15]。在全卷积训练中,也可以通过加权损失来实现类平衡,并且可以使用损失采样来解决空间相关性。
我们在第4.3节中探讨了抽样训练,但没有发现它对密集预测产生更快或更好的收敛。整体形象训练是有效和高效的。
4.Segmentation Architecture
We cast ILSVRC classifiers into FCNs and augment them for dense prediction with in-network upsamp-ling and a pixelwise loss. We train for segmentation by fine-tuning. Next, we add skips between layers to fuse coarse, semantic and local, appearance information. This skip architecture is learned end-to-end to refine the semantics and spatial precision of the output.
For this investigation, we train and validate on the PASCAL VOC 2011 segmentation challenge [6]. We train with a per-pixel multinomial logistic loss and validate with the standard metric of mean pixel inter-section over union, with the mean taken over all classes, including background. The training ignores pixels that are masked out (as ambiguous or difficult) in the ground truth.
4.分割架构
我们将ILSVRC分类器转换成FCN网络,并通过网络内上采样和像素级损失来增强它们以进行密集预测。我们通过微调进行分割训练。接下来,我们在层与层之间添加跳跃结构来融合粗糙的、语义的和局部的外观信息。这种跳跃结构是端到端学习的,以优化输出的语义和空间精度。
在本次调查中,我们在PASCAL VOC 2011分割挑战上进行了训练和验证[6]。我们使用每个像素的多项式逻辑损失进行训练,并通过联合上的平均像素交集的标准度量进行验证,其中包括所有类的平均值,包括背景。训练忽略了在ground truth中被掩盖(如模糊或困难)的像素。
4.1. From classifier to dense FCN
We begin by convolutionalizing proven classification architectures as in Section 3. We consider the AlexNet architecture that won ILSVRC12, as well as the VGG nets and the GoogLeNet which did exceptionally well in ILSVRC14. We pick the VGG 16-layer net, which we found to be equivalent to the 19-layer net on this task. For GoogLeNet, we use only the final loss layer, and improve performance by discarding the final average pooling layer. We decapitate each net by discarding the final classifier layer, and convert all fully connected layers to convolutions. We append a 1 × 1 1\times 1 1×1 convolution with channel dimension 21 to predict scores for each of the PASCAL classes (including background) at each of the coarse output locations, followed by a (backward) convolution layer to bilinearly upsample the coarse outputs to pixelwise outputs as described in Section 3.3. Table 1 compares the preliminary validation results along with the basic characteristics of each net. We report the best results achieved after convergence at a fixed learning rate (at least 175 epochs).
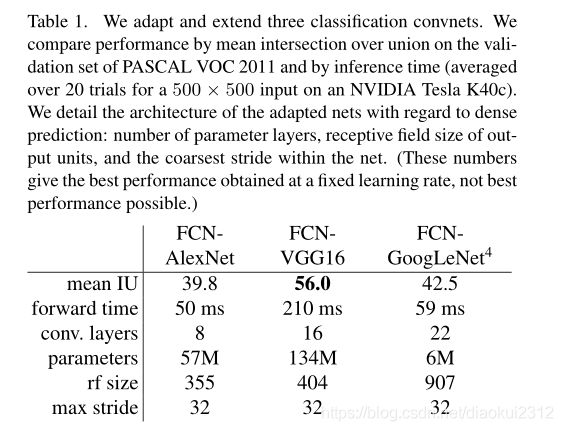
Fine-tuning from classification to segmentation gives reasonable predictions from each net. Even the worst model achieved ~75 percent of the previous best performance.FCN-VGG16 already appears to be state-of-the-art at 56.0 mean IU on val, compared to 52.6 on test [15]. Training on extra data raises FCN-VGG16 to 59.4 mean IU and FCN-AlexNet to 48.0 mean IU on a subset of val7. Despite similar classification accuracy, our implementation of GoogLeNet did not match the VGG16 segmentation result.
4.1 从分类器到密集的FCN
首先,如第3节所述,对经过验证的分类体系进行卷积。我们考虑赢得ILSVRC12的AlexNet体系结构以及在ILSVRC14中表现出色的VGG网络和GoogLeNet。我们选择了VGG 16层网络,我们发现它的效果相当于此任务上的19层网络。对于GoogLeNet,我们仅使用最终的损失层,并通过舍弃最终的平均池化层来提高性能。我们通过舍弃最终的分类器层来使截取每个网络,并将所有全连接层转换为卷积。我们附加一个具有21通道的 1 × 1 1\times 1 1×1 卷积,以预测每个粗略输出位置处每个PASCAL类(包括背景)的分数,然后是一个反卷积层,粗略输出上采样到像素密集输出,如第3.3节所述。表1比较了初步验证结果以及每个网络的基本特征。我们报告了以固定的学习速率(至少175 epochs)收敛后获得的最佳结果。
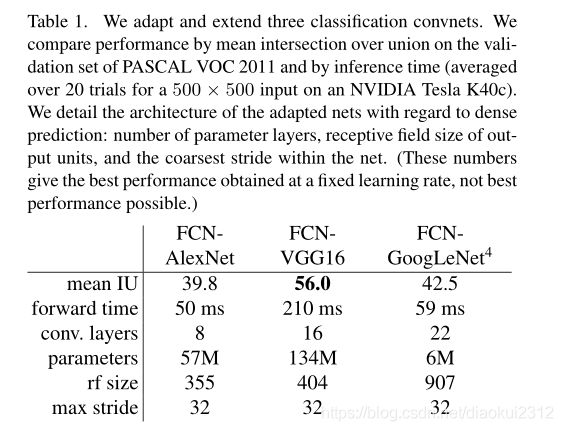
从分类到分割的微调可为每个网络提供合理的预测。即使是最糟糕的模型也能达到以前最佳性能的75%。 分割匹配的VGG网络(FCN-VGG16)已经看起来是最先进的,在val上为56.0平均IU,而在测试中为52.6 [16]。对额外数据的训练能将val的子集上将FCN-VGG16的平均IU提高到59.4,FCN-AlexNet的平均IU提高到48.0。尽管分类准确性相似,但我们对GoogLeNet的实现没有达到VGG16分割结果的效果。
4.2 Combining What and Where
We define a new fully convolutional net for segmentation that combines layers of the feature hierarchy and refines the spatial precision of the output. See Figure. 3.
While fully convolutionalized classifiers fine-tuned to semantic segmentation as shown in Section 4.1, and even score highly on the standard metrics, their output is dissatisfyingly coarse (see Fig. 4). The 32 pixel stride at the final prediction layer limits the scale of detail in the upsampled output.
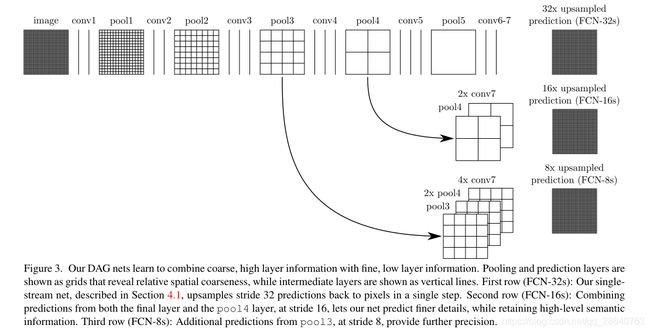
We address this by adding skips [1] that combine the final prediction layer with lower layers with finer strides. This turns a line topology into a DAG, with edges that skip ahead from lower layers to higher ones (Figure 3). As they see fewer pixels, the finer scale predictions should need fewer layers, so it makes sense to make them from shallower net outputs. Combining fine layers and coarse layers lets the model make local predictions that respect global structure. By analogy to the jet of Koenderick and van Doorn [19], we call our nonlinear feature hierarchy the deep jet.
We first divide the output stride in half by predicting from a 16 pixel stride layer. We add a 1 × 1 convolution layer on top of pool4 to produce additional class predictions. We fuse this output with the predictions computed on top of conv7 (convolutionalized fc7) at stride 32 by adding a 2× upsampling layer and summing6both predictions (see Figure 3). We initialize the 2× upsampling to bilinear inter-polation, but allow the parameters to be learned as described in Section 3.3. Finally, the stride 16 predictions are upsampled back to the image. We call this net FCN-16s. FCN-16s is learned end-to-end, initialized with the parameters of the last, coarser net, which we now call FCN-32s. The new parameters acting on pool4 are zeroinitialized so that the net starts with unmodified predictions. The learning rate is decreased by a factor of 100.
Learning this skip net improves performance on the validation set by 3.0 mean IU to 62.4. Figure 4 shows improvement in the fine structure of the output. We compared this fusion with learning only from the pool4 layer, which resulted in poor performance, and simply decreasing the learning rate without adding the skip, which resulted in an insignificant performance improvement without improving the quality of the output.

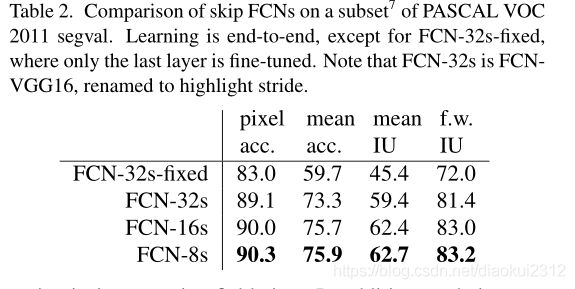
We continue in this fashion by fusing predictions from pool3 with a 2× upsampling of predictions fused from pool4 and conv7, building the net FCN-8s. We obtain a minor additional improvement to 62.7 mean IU, and find a slight improvement in the smoothness and detail of our output. At this point our fusion improvements have met diminishing returns, both with respect to the IU metric which empha-sizes large-scale correctness, and also in terms of the improvement visible e.g. in Figure 4, so we do not continue fusing even lower layers.
Refinement by other means Decreasing the stride of pooling layers is the most straightforward way to obtain finer predictions. However, doing so is problematic for our VGG16-based net. Setting the pool5 stride to 1 requires our convolutionalized fc6 to have kernel size 14 × 14 to maintain its receptive field size. In addition to their computational cost, we had difficulty learning such large filters. We attem-pted to re-architect the layers above pool5 with smaller filters, but did not achieve comparable perfor-mance; one possible explanation is that the ILSVRC initialization of the upper layers is important.
Anotherwaytoobtainfinerpredictionsistousetheshiftand-stitch trick described in Section 3.2. In limited experiments, we found the cost to improvement ratio from this method to be worse than layer fusion.
4.3结合什么和在哪里结合
我们定义了一个用于分割的新的全卷积网络,它结合了特征层次结构的各层,并细化了输出的空间精度。参见图3。
尽管完全卷积分类器可以按照如4.1中说明进行微调,甚至这些基础网络在标准指标上得分很高,但它们的输出却令人不尽如人意(见图4)。最终预测层的32像素步幅限制了上采样输出中的细节尺度。
我们通过添加跳跃结构[51]来解决此问题,该跳跃结构融合了最终预测层与具有更加精细步幅的较低层。这将线拓扑变成DAG,其边缘从较低层跳到叫高层(图3)。因为他们看到的像素更少,更精细的尺度预测应该需要更少的层,因此从较浅的网络输出是有意义的。结合精细层和粗糙层可以让模型做出符合全局结构的局部预测。与肯德尔里克和范·多恩[19]的覆盖相似 [19],我们将非线性特征层次称为深覆盖。
我们首先通过从16像素步幅层进行预测,将输出步幅分成两半。我们在pool4的顶部添加了1 × 1卷积层,以产生额外的类别预测。我们通过增加一个2倍的上采样层并将两个预测相加,将此输出与在步幅为32的conv7(卷积fc7)上计算的预测相融合(见图3)。我们将2倍上采样初始化为双线性插值,但允许按照第3.3节所述学习参数。最后,将步幅16预测上采样回到图像。我们称这个网络为FCN-16。FCN-16s是端到端学习的,用最后一个较粗网络的参数初始化,我们现在称之为FCN-32s。作用于pool4的新参数被初始化为零,因此网络从未修改的预测开始。学习率降低了100倍。
学习这个skip网络可以将验证集上的性能提高平均IU3.0到62.4。图4显示了输出精细结构的改进。我们将这种融合仅与来自pool4层的学习进行了比较,这导致性能较差,并且仅在不添加跳过的情况下降低了学习速度,从而在不提高输出质量的情况下导致了微不足道的性能改进。

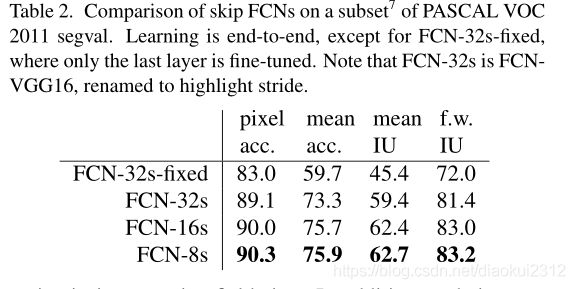
我们继续以这种方式将pool3的预测与融合了pool4和conv7的2x上采样预测相融合,建立网络FCN-8s。我们获得了一个小的额外改进,平均IU达到62.7,并且我们的输出的平滑度和细节略有改善。至此,我们的融合改进遇到了收益递减的问题,无论是在强调大规模正确性的IU度量方面,还是在可见的改进方面,例如,所以在图4中,我们不会继续融合更低的层。
通过其他方式进行细化 减少池化层的步幅是获得更精细预测的最直接方法。但是,这样做对我们基于VGG16的网络来说是个问题。将pool5层设置为具有步幅1要求我们的卷积化fc6具有14×14的内核大小以便维持其感受野大小。除了计算成本之外,我们还难以学习如此大的过滤器。我们尝试用较小的过滤器重新构建pool5之上的层,但是没有成功实现相当的性能;一种可能的解释是,从上层的ILSVRC初始化很重要。
ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。
获得更好预测的另一种方法是使用3.2节中描述的shift-and-stitch技巧。在有限的实验中,我们发现这种方法的改进成本比层融合更差。
4.3 Experimental Framework
Optimization We train by SGD with momentum. We use a minibatch size of 20 images and fixed learning rates of 1 0 − 3 10^{-3} 10−3, 1 0 − 4 10^{-4} 10−4, and 5 − 5 5^{-5} 5−5for FCN-AlexNet, FCN-VGG16, and FCN-GoogLeNet, respectively, chosen by line search. We use momentum 0.9, weight decay of 5 − 4 5^{-4} 5−4or 2 − 4 2^{-4} 2−4, and doubled learning rate for biases, although we found training to be sensitive to the learning rate alone. We zero-initialize the class scoring layer, as random initialization yielded neither better performance nor faster convergence. Dropout was included where used in the original classifier nets.
Fine-tuning We fine-tune all layers by backpropagation through the whole net. Fine-tuning the output classifier alone yields only 70% of the full finetuning performance as compared in Table 2. Training from scratch is not feasible considering the time required to learn the base classification nets. (Note that the VGG net is trained in stages, while we initialize from the full 16-layer version.) Fine-tuning takes three days on a single GPU for the coarse FCN-32s version, and about one day each to upgrade to the FCN-16s and FCN-8s versions.
More Training Data The PASCAL VOC 2011 segmentation training set labels 1112 images. Hariharan et al. [14] collected labels for a larger set of 8498 PASCAL training images, which was used to train the previous state-of-theart system, SDS [15]. This training data improves the FCNVGG16 validation score7by 3.4 points to 59.4 mean IU.
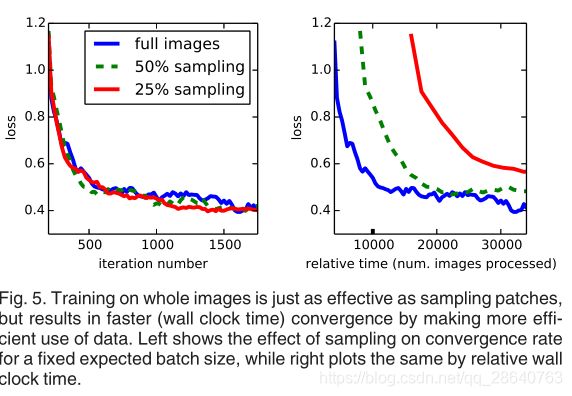
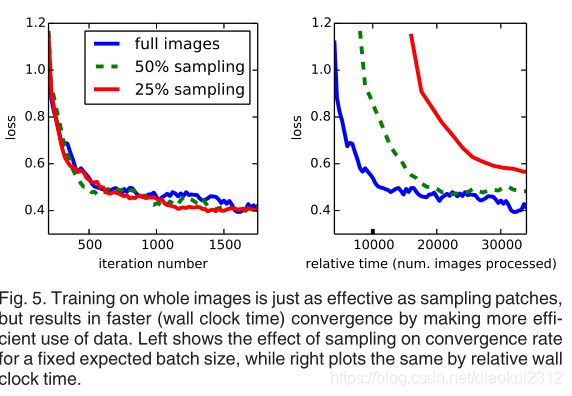
Patch Sampling As explained in Section 3.4, our full image training effectively batches each image into a regular grid of large, overlapping patches. By contrast, prior work randomly samples patches over a full dataset [27, 2, 7, 28, 9], potentially resulting in higher variance batches that may accelerate convergence [22]. We study this tradeoff by spatially sampling the loss in the manner described earlier, making an independent choice to ignore each final layer cell with some probability 1 − p. To avoid changing the effective batch size, we simultaneously increase the number of images per batch by a factor 1/p. Note that due to the efficiency of convolution, this form of rejection sampling is still faster than patchwise training for large enough values of p (e.g., at least for p > 0.2 according to the num-bers in Section 3.1). Figure 5 shows the effect of this form of sampling on convergence. We find that sampling does not have a significant effect on convergence rate compared to whole image training, but takes significantly more time due to the larger number of images that need to be consi-dered per batch. We therefore choose unsampled, whole image training in our other experiments.
Class Balancing Fully convolutional training can balance classes by weighting or sampling the loss. Although our labels are mildly unbalanced (about 3/4 are background), we find class balancing unnecessary.
Dense Prediction The scores are upsampled to the input dimensions by deconvolution layers within the net. Final layer deconvolutional filters are fixed to bilinear interpolation, while intermediate upsampling layers are initialized to bilinear upsampling, and then learned.
Augmentation We tried augmenting the training data by randomly mirroring and “jittering” the images by translating them up to 32 pixels (the coarsest scale of prediction) in each direction. This yielded no noticeable improvement.
Implementation All models are trained and tested with Caffe [18] on a single NVIDIA Tesla K40c. Our models and code are publicly available at
http://fcn.berkeleyvision.org.
4.3实验框架
优化 我们用带有动量的随机梯度下降算法(SGD)进行训练。我们使用的mini-batch大小为20张图片,和对于FCN-AlexNet, FCN-VGG16和FCN-GoogleNet使用由线性搜索得到的固定的学习率,分别为 1 0 − 3 10^{-3} 10−3, 1 0 − 4 10^{-4} 10−4, 和 5 − 5 5^{-5} 5−5。我们使用动量为0.9,权重衰减为 5 − 4 5^{-4} 5−4或 2 − 4 2^{-4} 2−4,并且将对偏差的学习率增加了一倍,虽然我们发现训练仅对学习速率敏感。我们对类评分层进行零初始化,因为随机初始化既不能产生更好的性能,也不能更快的收敛。Droupout被包含在原始分类器网络中使用。
微调 我们通过整个网络的反向传播来微调所有层。如表2所示,单独微调输出分类器仅是完全微调性能的70%。考虑到学习基础分类网所需的时间,从头开始训练是不可行的。 (请注意,VGG网络是分阶段训练的,而我们是从完整的16层版本初始化的。)对于粗FCN-32s版本,单个GPU上的微调需要三天时间,而每个版本大约需要一天时间才能升级到FCN-16s和FCN-8s版本。
更多的训练数据 PASCAL VOC 2011分割训练集标签1112张图像。Hariharan等人[14]收集了一组更大的8498 PASCAL训练图像的标签,用于训练之前的先进系统SDS[15]。这一训练数据提高了FCNVGG16验证集的分数3.4分,达到平均59.4 IU。
Patch采样 如第3.4节所述,我们的整个图像训练有效地将每个图像分批成一个规则的大重叠网格块。相比之下,先前的工作在整个数据集上随机采样patches,可能导致更高的方差批次,从而可能加速收敛。我们通过以前面描述的方式对损失进行空间采样来研究这种权衡,并做出独立选择,以1-p的概率忽略每个最终层单元。 为了避免更改有效的批次大小,我们同时将每批次的图像数量增加了1/p。请注意,由于卷积效率高,对于足够大的p值(例如,至少根据第3.1节中的p> 0.2而言),这种形式的拒绝采样仍比逐块训练更快。图5显示了这种采样形式对收敛的影响。我们发现,与整个图像训练相比,采样对收敛速度没有显着影响,但是由于每批需要考虑的图像数量更多,因此采样花费的时间明显更多。因此,我们在其他实验中选择未采样的整体图像训练。
解释了为什么全图像训练,而没有选择采样的原因
类别平衡 完全卷积训练可以通过加权或采样损失来平衡类别。虽然我们的标签略有不平衡(大约3 / 4为背景),但我们发现类平衡是不必要的。
密集预测。 分数通过网络中的反卷积层上采样到输入维度。最终层的反卷积滤波器固定为双线性插值,而中间的上采样层则初始化为双线性插值,然后学习。
增强 我们尝试通过随机镜像和“抖动”图像来增强训练数据,方法是将图像在每个方向上最多转换为32个像素(最粗的预测比例)。这没有产生明显的改善。
实现 所有模型都在单个NVIDIA Titan X上使用Caffe [54]进行了训练和测试。我们的模型和代码可在http://fcn.berkeleyvision.org上公开获得。
5 Results
We test our FCN on semantic segmentation and scene parsing, exploring PASCAL VOC, NYUDv2, and SIFT Flow. Although these tasks have historically distinguished between objects and regions, we treat both uniformly as pixel prediction. We evaluate our FCN skip architecture on each of these datasets, and then extend it to multi-modal input for NYUDv2 and multi-task prediction for the semantic and geometric labels of SIFT Flow.
Metrics We report four metrics from common semantic segmentation and scene parsing evaluations that are variations on pixel accuracy and region intersection over union (IU). Let n i j n_{ij} nijbe the number of pixels of class i i i predicted to belong to class j j j, where there are n c l n_{cl} ncl different classes, and let t i = ∑ j n i j t_i=\sum _{j}n^{_{ij}} ti=∑jnij be the total number of pixels of class i i i. We compute:
- pixel accuracy: ∑ i n i i / ∑ i t i \sum _{i}n^{_{ii}}/\sum _{i}t_{i} ∑inii/∑iti
- mean accuraccy: ( 1 / n c l ) ∑ i n i i / t i \left ( 1/n_{cl} \right )\sum_{i}n^{_{ii}}/t{_{i}} (1/ncl)∑inii/ti
- mean IU: ( 1 / n c l ) ∑ i n i i / ( t i + ∑ j n j i − n i i ) \left ( 1/n_{cl} \right )\sum_{i}n^{_{ii}}/\left ( t{_{i}}+\sum _{j}n_{ji}-n_{ii} \right ) (1/ncl)∑inii/(ti+∑jnji−nii)
- frequency weighted IU: ( ∑ k t k ) − 1 ∑ i t i n i i / ( t i + ∑ j n j i − n i i ) \left ( \sum _{k}t_{k} \right )^{-1}\sum _{i}t_{i}n_{ii}/\left ( t_{i}+\sum _{j}n_{ji}-n_{ii} \right ) (∑ktk)−1∑itinii/(ti+∑jnji−nii)
PASCAL VOC. Table 4 gives the performance of our FCN-8s on the test sets of PASCAL VOC 2011 and 2012, and compares it to the previous best, SDS [14], and the well-known R-CNN [5]. We achieve the best results on mean IU by 30 percent relative. Inference time is reduced 114 × 114\times 114×(convnet only, ignoring proposals and refinement) or 286 × 286\times 286× (overall). Fig. 6 compares the outputs of FCN-8s and SDS.

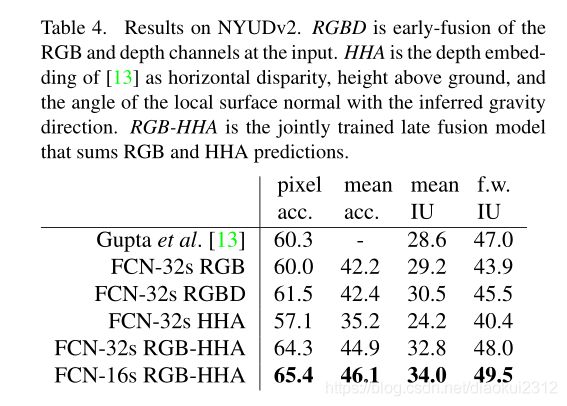
NYUDv2. is an RGB-D dataset collected using the Microsoft Kinect. It has 1,449 RGB-D images, with pixelwise labels that have been coalesced into a 40 class semantic segmentation task by Gupta et al. We report results on the standard split of 795 training images and 654 testing images.(Note: all model selection is performed on PASCAL 2011 val.)Table 4 gives the performance of several net variations. First we train our unmodified coarse model (FCN-32s) on RGB images. To add depth information, we train on a model upgraded to take four-channel RGB-D input (early fusion). This provides little benefit, perhaps due to similar number of parameters or the difficulty of propagating meaningful gradients all the way through the model. Following the success of Gupta et al[13], we try the three-dimensional HHA encoding of depth , training nets on just this information,as well as a “late fusion” of RGB and HHA where the predictions from both nets are summed at the final layer, and the resulting two-stream net is learned end-to-end. Finally we upgrade this late fusion net to a 16-stride version.
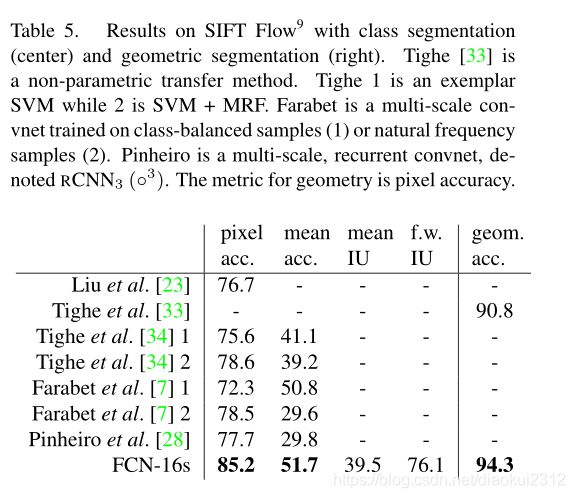
SIFT Flow is a dataset of 2,688 images with pixel labels for 33 semantic classes (“bridge”, “mountain”, “sun”), as well as three geometric classes (“horizontal”, “vertical”, and “sky”). An FCN can naturally learn a joint representation that simultaneously predicts both types of labels. We learn a two-headed version of FCN-16s with semantic and geometric prediction layers and losses.The learned model performs as well on both tasks as two independently trained models, while learning and inference are essentially as fast as each independent model by itself. The results in Table 5, computed on the standard split into 2,488 training and 200 test images,9show state-of-the-art performance on both tasks.
5 结果
我们测试了我们的FCN在语义分割和场景解析,探索PASCAL VOC,NYUDv2,和SIFT Flow。 虽然这些任务历来在对象和区域之间有所区别,但我们将两者均视为像素预测。 我们在每个数据集上评估FCN跳跃体系结构,然后将其扩展到NYUDv2的多模式输入,以及SIFT Flow的语义和几何标签的多任务预测。
指标。 我们从常见的语义分割和场景解析评估报告了四个指标,这些指标是像素精度和联合区域交叉(IU)的变化。设 n i j n_{ij} nij为类 i i i预测属于类 j j j的像素个数,其中有 n c l n_{cl} ncl不同的类,设 t i = ∑ j n i j t_i=\sum _{j}n^{_{ij}} ti=∑jnij为类i的总像素个数,我们计算:
- 像素精度: ∑ i n i i / ∑ i t i \sum _{i}n^{_{ii}}/\sum _{i}t_{i} ∑inii/∑iti
- 平均准确度: ( 1 / n c l ) ∑ i n i i / t i \left ( 1/n_{cl} \right )\sum_{i}n^{_{ii}}/t{_{i}} (1/ncl)∑inii/ti
- 平均IU: ( 1 / n c l ) ∑ i n i i / ( t i + ∑ j n j i − n i i ) \left ( 1/n_{cl} \right )\sum_{i}n^{_{ii}}/\left ( t{_{i}}+\sum _{j}n_{ji}-n_{ii} \right ) (1/ncl)∑inii/(ti+∑jnji−nii)
- 频率加权IU: ( ∑ k t k ) − 1 ∑ i t i n i i / ( t i + ∑ j n j i − n i i ) \left ( \sum _{k}t_{k} \right )^{-1}\sum _{i}t_{i}n_{ii}/\left ( t_{i}+\sum _{j}n_{ji}-n_{ii} \right ) (∑ktk)−1∑itinii/(ti+∑jnji−nii)
PASCAL VOC. 表3给出了FCN-8在PASCAL VOC 2011和2012测试集上的性能,并将其与之前的最先进的SDS [15]和著名的R-CNN[10] 进行了比较。我们在平均IU上取得了20%的相对优势。推理时间减少了114倍(仅限于convnet,忽略提案和完善内容)或286倍(总体)。
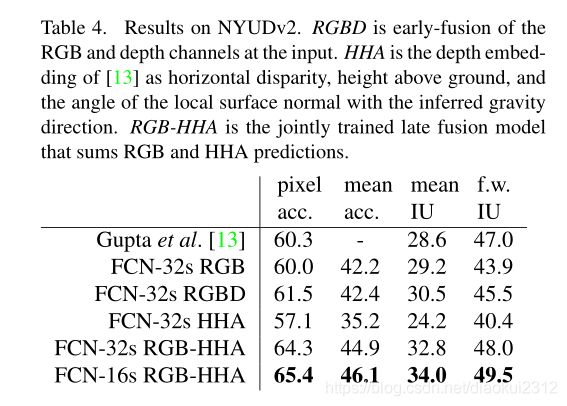
NYUDv2. 是使用Microsoft Kinect收集的RGB-D数据集。它具有1449个RGB-D图像,带有按像素划分的标签,由Gupta等人合并为40类语义分割任务。我们报告了795张训练图像和654张测试图像的标准分割结果。表4给出了几种净变化的性能。首先,我们在RGB图像上训练未修改的粗糙模型(FCN-32s)。为了增加深度信息,我们训练了一个升级后的模型以采用四通道RGB-D输入(早期融合)。这可能带来的好处很小,这可能是由于参数数量相似或难以通过网络传播有意义的梯度所致。继成功Gupta等。我们尝试对深度进行三维HHA编码,以及后期融合的RGB和HHA都是预测在最终层相加,,并得出结果两流网络是端到端学习的。最后,我们将这个后期的融合网络升级为16步版本。
SIFT流. 是2688个图像的数据集,带有33个语义类别(“桥”,“山”,“太阳”)以及三个几何类别(“水平”,“垂直”和“天空”)的像素标签。 FCN可以自然地学习可以同时预测两种标签类型的联合表示。我们学习了带有语义和几何预测层以及损失的FCN-16s的两头版本。该网络在两个任务上的表现都好于两个独立训练的网络,而学习和推理基本上与每个独立的网络一样快。表5中的结果按标准划分为2488个训练图像和200张测试图像,在两个任务上均显示出更好的性能。
6 Conclusion
Fully convolutional networks are a rich class of models, of which modern classification convnets are a special case. Recognizing this, extending these classification nets to segmentation, and improving the architecture with multi-resolution layer combinations dramatically improves the state-of-the-art, while simultaneously simplifying and speeding up learning and inference.
Acknowledgements This work was supported in part by DARPA ’s MSEE and SMISC programs, NSF awards IIS1427425, IIS-1212798, IIS-1116411, and the NSF GRFP , Toyota, and the Berkeley Vision and Learning Center. We gratefully acknowledge NVIDIA for GPU donation. We thank Bharath Hariharan and Saurabh Gupta for their advice and dataset tools. We thank Sergio Guadarrama for reproducing GoogLeNet in Caffe. We thank Jitendra Malik for his helpful comments. Thanks to Wei Liu for pointing out an issue wth our SIFT Flow mean IU computation and an error in our frequency weighted mean IU formula.
6 分析
完全卷积网络是一类丰富的模型,现代分类卷积网络是其中的特例。认识到这一点,扩展了这些分类网络进行分割,并通过多分辨率图层组合改进体系结构可极大地改善最新技术,同时简化并加快学习和推理速度。
致谢 这项工作得到了DARPA的MSEE和SMISC计划的部分支持,NSF授予IIS1427425,IIS-1212798,IIS-1116411和NSF GRFP,Toyota以及Berkeley视觉和学习中心。我们非常感谢NVIDIA为GPU的捐赠。我们感谢Bharath Hariharan和Saurabh Gupta的建议和数据集工具。感谢Sergio Guadarrama在Caffe中复制GoogLeNet。我们感谢Jitendra Malik的有益评论。感谢Liu Wei指出了我们的SIFT Flow平均IU计算中的一个问题以及我们的频率加权平均IU公式中的一个错误。
7.参考文献
References
在这里我们要注意的是FCN的缺点:
是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性.