PODNet: Pooled Outputs Distillation for Small-Tasks Incremental Learning论文详解ECCV2020
ECCV2020
论文地址:https://doi.org/10.1007/978-3-030-58565_6
代码地址:https://github.com/arthurdouillard/incremental learning.pytorch
目录
1.贡献点
2.方法
2.1 pool类型
2.2 POD(Pooled Outputs Distillation)方法
2.3 LSC(Local Similarity Classifier)
三、实验结果
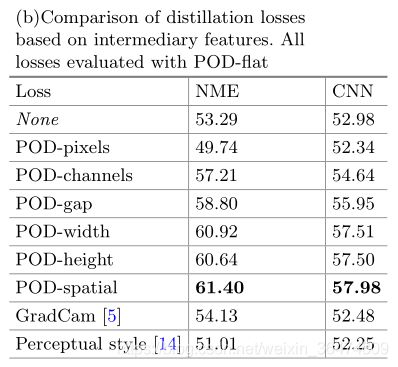
3.1 消融实验
3.2 同类对比
四、评价
基于样本回放的方法,同时基于知识蒸馏,本文改进了蒸馏的形式,定义了Pooled Output Distillation(POD)
1.贡献点
PODNet受到representation learning的启发。贡献点有两个
- spatial-based distillation-loss, 基于空间的蒸馏loss,改进了feature的蒸馏方法
- representation comprising multiple proxy vectors, 代理向量,改进了模型的分类器。
2.方法
2.1 pool类型

不同的Pool方法,看图很好理解。GAP即global average pooling,相当于除了channel外的所有通道进行pooling.
2.2 POD(Pooled Outputs Distillation)方法

假定分类过程定义为:
![]()
h=f(x)定义为特征提取过程,g()可以被定义为分类器。这也是增量学习中常被采用的结构,即双阶段,一个分类器阶段,一个特征提取阶段。
本文提出POD(Pooled Outputs Distillation)算法,不仅将蒸馏用于特征提取阶段h=f()的最终输出,也应用于f()的中间过程(intermediate layer)。
![]()
即特征提取中的每一层都作为中间结果,用于kd,上标t表示task t,下标L表示模型第L层。
假定中间层的输出:
![]()
约束最强的就是pixel级别的蒸馏:

其他的蒸馏方式有channel级别,GAP级别,width级别,height级别
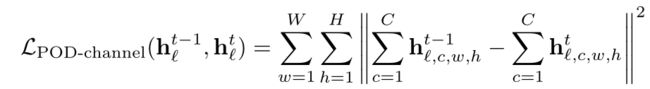


pixel级别的蒸馏对于模型限制比较严格,其他级别的对于模型限制相对较松,需要一个权衡,作者最终选用的是Spatial级别的蒸馏,相当于width和height层面蒸馏loss之和。
![]()
后文的实验中也证实了此种方法的蒸馏性能最佳。
对于特征提取模型最终的特征,可以运用pixel级别的蒸馏

最终的蒸馏loss即最终模型的蒸馏和正常蒸馏的结合:
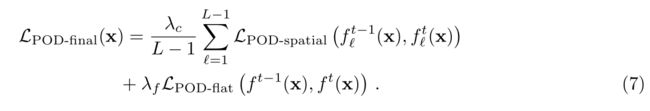
模型的loss可见图:
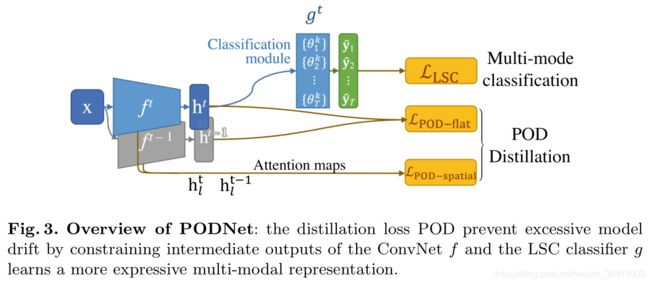
根据图中所示,特征提取阶段每层的特征进行spatial层面的蒸馏,最终的特征进行完整的蒸馏,最终分类器运用分类loss即可。
2.3 LSC(Local Similarity Classifier)
旧的分类任务,相当于fc分类器,用权重与feature进行点乘操作,但是根据UCIR(Learning a Unified Classifier Incrementally via Rebalancing, CVPR2019)的研究结果,fc层的分类器在增量训练后会倾向于训练更近的类别,即倾向于增量类,所以UCIR对分类器进行了改进。

分类器将fc层的点乘操作替换为了cosine相似度。
本文发现,如果只利用一个cos相似度的分类器,则不能很好的适应同一类别内多样性的需求,因此作者将之前的一个cos分类器分为了K个,相当于K个代理,以最终的k个cos分类器的分类结果来作为分类结果。

将分类器改进为此形式之后,搭配交叉熵loss即可取得不错的结果,作者又参考了NCA loss(Neighbourhood Components Analysis. NIPS2005),类似于交叉熵loss的改进,这个loss可以取得更快的收敛速度。写为下面这种形式:
NCA loss照作者说的具有更快的收敛速度,但是可能并没有交叉熵实用,因为NCA loss早在2005年就被提出,但是目前依然没有被广泛采用,可能涉及到样本之间的关系,耗费运算或者存储。后文NCA 和交叉熵之间loss的消融实验提升并不明显,也没有谈及运算消耗,因此NCA loss可能是作者在凑贡献点,也有可能与LSC分类器结合可以取得较好的效果。
三、实验结果
3.1 消融实验

a是关于分类器的消融实验,LSC比直接的cosine分类器具有更好的效果,POD的加入能够取得更好的效果。
3.2 同类对比
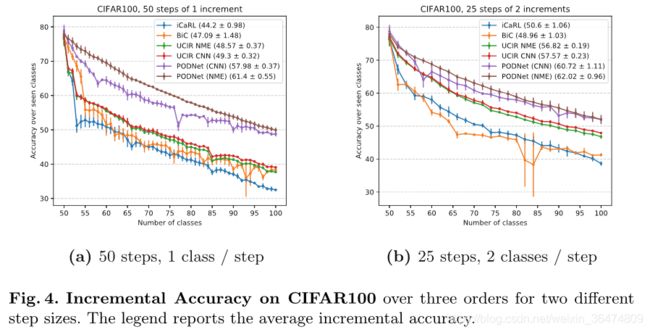
均可以取得较好的效果。
四、评价
本文改进了蒸馏的形式,让蒸馏的对于模型的限定刚好不松不紧,适用于增量任务。
改进了分类器的loss形式,将cosine分类器与代理向量相结合,取得了不错的效果。