83FPS,史上最快 | IA-SSD: 基于点云的高效3D目标检测网络(CVPR2022)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【IASSD】获取论文和代码!
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
后台回复【数据集下载】获取计算机视觉近30种数据集!
1论文主要贡献
论文针对三维激光雷达点云的有效目标检测问题开展了研究,为了减少内存和计算成本,现有的基于point的pipeline通常采用任务无关随机采样或最远点采样来逐步向下采样输入pointset,然而并非所有点对目标检测任务都同等重要。对于detector来说,前景点本质上比背景点更重要。基于此,论文提出了一种高效的单级基于point的3D目标检测器,称为IA-SSD。
IA-SSD利用两种可学习的,面向任务、实例感知的下采样策略来分层选择属于感兴趣对象的前景点。此外,还引入了上下文质心感知模块,以进一步估计精确的实例中心。最后,为了提高效率,论文按照纯编码器架构构建了IA-SSD。在多个大规模检测benckmark上进行的实验证明了IA-SSD的优势。由于低内存占用和高度并行性,在KITTI数据集上单个RTX2080Ti GPU实现了每秒80多帧的速度。

2面临的一些问题
由于复杂的几何结构和不均匀的密度,激光雷达点云中的三维物体检测任务(即预测7自由度的三维box框,包括三维位置、三维尺寸、方向和类别标签)仍然极具挑战性。由于三维点云的非结构化和无序性质,早期的工作通常首先将原始点云转换为中间规则表示,包括将三维点云投影到鸟瞰视图或正面视图的二维图像,或转换为密集的三维体素。然后,可以2D检测范式网络部署到3D目标检测任务中,尽管最近取得了显著进展,但由于3D-2D投影或体素化引入了量化误差,不可避免地限制了现有方法的性能。另一种技术流遵循基于点的pipeline,直接对原始点云进行操作,通常直接学习逐点特征,然后通过特定的对称函数进行聚合,如max-pooling。
虽然这些方法很不错,并且没有任何显式信息丢失,但仍然存在昂贵的计算/内存成本和有限的检测性能。本文首先深入研究了现有的基于point的框架,并在实验中发现,所使用的启发式采样策略远远不能令人满意,因为许多重要的前景点在最终的边界框回归步骤之前被丢弃。因此,检测性能,特别是对行人等小目标的检测性能从根本上受到限制。论文认为并非所有点对目标检测任务都同等重要,使用角度出发,只有前景点,才是真正需要关心的。
基于上述出发点,论文提出一个面向任务、实例感知的下采样框架,以显式保留前景点,同时降低内存/计算成本。具体而言,提出了两种变体,即类感知和质心感知采样策略。此外还提出了上下文实例质心感知,以充分利用边界框周围有意义的上下文信息进行实例中心回归。最后构建了基于自底向上单级框架的IA-SSD,如下图所示,所提出的IA-SSD被证明是高效的(一次通过可并行推断100帧,在单个RTX 2080Ti GPU上的速度为83 FPS),并且在KITTI基准上是准确的。
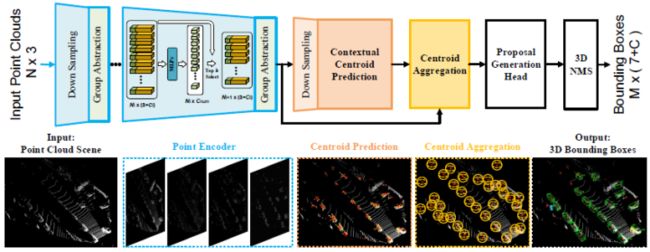
3领域方法介绍
论文简要概述了现有的基于体素的检测器、基于点的检测器和点-体素检测器。
1.基于Voxel方法
为了处理非结构化三维点云,基于体素的检测器通常首先将不规则点云转换为规则体素网格,这允许利用成熟的卷积网络架构。早期的工作,对输入点云进行密集体素化,然后利用卷积神经网络学习特定的几何模式。然而,效率是这些方法的主要限制之一,因为计算和内存成本随着输入分辨率呈立方体增长。为此,Yan等人[49]通过利用3D子流形稀疏卷积[9],提出了一种称为SECOND的高效架构。通过减少对空体素的计算,计算和存储效率显著提高。此外,提出了PointPillars,以进一步将体素简化为pillars (即仅在平面中进行体素化)。
现有的方法大致可分为单级检测器[7,11,54,55,57,58]和两级检测器[4,36–39,53]。尽管简单有效,但由于空间分辨率降低和结构信息不足,尤其是对于具有稀疏点的小对象,它们通常无法实现令人满意的检测性能。为此,SA-SSD通过引入辅助网络来利用结构信息。Ye等人[54]介绍了一种混合体素网络(HVNet),用于集中和投影多尺度特征图,以获得更好的性能。郑等人[58]提出了置信IoU感知(CIA-SSD)网络来提取空间语义特征,用于目标检测。相比之下,两级检测器可以获得更好的性能,但计算/存储成本较高。Shi等人[39]提出了一种两级检测器,即Part-A2,它由Part-aware和聚合模块组成。Deng等人[5]通过引入完全卷积网络来扩展PV-RCNN[36],以进一步利用原始点云的体积表示并同时进行细化。
总的来说,基于体素的方法可以实现良好的检测性能和良好的效率。然而,体素化不可避免地引入量化损耗。为了补偿预处理阶段的结构失真,需要在[20,25,27,28,35]中引入复杂的模块设计,这反过来会大大降低最终检测效率。此外,考虑到复杂的几何结构和各种不同的对象,在实践中确定最佳分辨率并不容易。
2.基于Point方法
与基于体素的方法不同,基于点的方法[30,38,52]直接从非结构化点云学习几何,进一步为感兴趣的对象生成特定proposal。考虑到3D点云的无序性,这些方法通常采用PointNet[31]及其变体[22、32、33、45、47],使用对称函数聚合独立的逐点特征。Shi等人[38]提出了PointRCNN,一种用于3D对象检测的两阶段3D区域proposal框架。该方法首先从分割的前景点生成对象建议,然后利用语义特征和局部空间线索回归高质量的三维边界框。Qi等人[30]介绍了VoteNet,这是一种基于深度Hough投票的单级point 3D检测器,用于预测实例质心。受2D图像中单级检测器[21]的启发,Yang等人[52]提出了一种3D单级检测(3DSSD)框架,而关键是融合采样策略,包括特征和欧几里德空间上的最远点采样。PointGNN[40]是一个将图形神经网络推广到3D对象检测的框架。
基于点的方法直接在原始点云上操作,无需任何额外的预处理步骤(如体素化),因此通常直观直观。然而,基于点的方法的主要瓶颈是学习能力不足和效率有限。
3.基于Point-Voxel方法
为了克服基于点的方法(即不规则和稀疏的数据访问、较差的内存局部性[23])和基于体素方法(如量化损失)的缺点,已经开始使用几种方法[3、16、36、37、53]从3D点云学习点-体素联合表示。PV-RCNN[36]及其后续工作[37]从体素抽象网络中提取逐点特征,以细化从三维体素主干生成的proposal。
HVPR[29]是一种单级3D探测器,通过引入高效内存模块以增强基于点的功能,从而在准确性和效率之间提供更好的折衷。Qian等人[34]提出了一种轻量级区域聚合细化网络(BANet)通过局部邻域图构造,产生更精确的box边界预测。
4IA-SSD
与密集预测任务(如需要逐点预测的3D语义分割)不同,3D对象检测自然关注小而重要的前景对象(即,感兴趣的实例,包括汽车、行人等)。然而,现有的基于点的检测器通常在其框架中采用任务无关的下采样方法,如随机采样[14]或最远点采样[32,52]。
尽管有效降低了内存/计算成本,但在渐进下采样中,最重要的前景点也会减少。此外,由于不同物体的大小和几何形状差异很大,现有detector通常为不同类型的物体训练具有各种仔细调整的超参数的单独模型。然而,这不可避免地影响了这些模型在实践中的部署。因此论文的目标是:能否训练一个基于单点的模型,该模型能够在一次通过中有效地检测多类对象?
基于此,论文通过引入实例感知下采样和上下文质心感知模块,提出了一种高效的单级检测器。如下图所示,为了提高效率,IA-SSD采用了[52]中使用的轻型纯编码器架构。首先将输入的激光雷达点云送入网络以提取逐点特征,然后进行拟议的实例感知下采样,以逐步降低计算成本,同时保留信息丰富的前景点。学习的潜在特征进一步输入到上下文质心感知模块,以生成实例建议并回归最终边界框。

1.实例感知下采样策略
为了实现高效的三维目标检测,必须通过渐进下采样来减少内存和计算成本,特别是对于大型三维点云。然而,主动下采样可能会丢失前景对象的大部分信息。总的来说,目前尚不清楚如何在计算效率和前景点的保留之间实现理想的权衡。为此,论文首先进行了一项实证研究,以定量评估不同的抽样方法,并遵循常用的编码体系结构(即具有4个编码层的PointNet++[32]),评估了随机点采样[14]、基于欧几里德距离的FPS(D-FPS)[32]和特征距离(Feat FPS)[52]等方法。
实验显示,在多次随机下采样操作后,实例召回率显著下降,表明大量前景点已被删除。D-FPS和Feat FPS在早期阶段都实现了相对较好的实例召回率,但在最后一个编码层也无法保留足够的前景点。因此,精确检测感兴趣的目标仍然是一项挑战,特别是对于行人和骑自行车的人等小目标,在这些小目标中只剩下极有限的前景点。
为了尽可能多地保留前景点,论文利用每个点的潜在语义,因为随着分层聚合在每个层中运行,学习的点特征可能包含更丰富的语义信息。根据这一思想,论文通过将前景语义先验合并到网络训练管道中,提出了以下两种面向任务的采样方法:
Class-aware Sampling
该采样策略旨在学习每个点的语义,从而实现选择性下采样。为了实现这一点,论文引入了额外的分支来利用潜在特征中丰富的语义。通过将两个MLP层附加到编码层,以进一步估计每个点的语义类别:
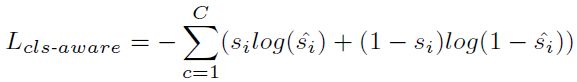
其中C表示类别数,si表示one-hot标签,si^表示预测Logit。在推理过程中,具有前k个前景分数的点被保留,并被视为馈送到下一编码层的代表点,如下表所示,该策略倾向于保留更多的前景点,因此实现了较高的实例召回率。
Centroid-aware Sampling
考虑到实例中心估计是最终目标检测的关键,进一步提出了一种质心感知下采样策略,为更接近实例质心的点赋予更高的权重。将实例i的soft point mask定义如下:
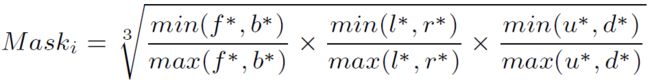
其中f∗, b∗, l∗, r∗, u∗, d∗ 分别表示点到边界框的6个surface(前、后、左、右、上和下)的距离。在这种情况下,靠近长方体质心的点可能具有更高的mask score(最大值为1),而位于surface上的点的mask分数为0。在训练期间,soft point mask将用于根据空间位置为边界框内的点指定不同的权重,因此将几何先验隐含地纳入网络训练。
将soft point mask与前景点的损失项相乘,以便为中心附近的点分配更高的概率。注意,在推理过程中不再需要box,如果模型训练充分,只需在下采样后保留得分最高的前k个点。

2.上下文实例质心感知
上下文质心预测
受2D图像中上下文预测成功的启发[6,51],论文试图利用边界框周围的上下文线索(质心预测)。遵循[30]明确预测偏移量∆ c到实例中心,并添加了正则化项以最小化质心预测的不确定性,质心预测损失公式如下:

基于质心的实例聚合
对于移位代表(质心)点,进一步利用PointNet++模块学习每个实例的潜在表示。将相邻点转换为局部规范坐标系,然后通过共享MLP和对称函数聚合点特征。
Proposal Generation Head
将聚集的质心点特征输入到提案生成头中,预测具有带有类别的bounding box。论文将proposal编码为具有位置、规模和方向的多维表示。最后,所有proposal都通过具有特定IoU阈值的3D-NMS后处理进行过滤。
5实验细节
为了提高效率,论文基于单级编码器体系结构构建了IA-SSD。SA层[32]用于提取逐点特征,并使用具有递增半径组的多尺度分组([0.2,0.8]、[0.8,1.6]、[1.6,4.8])来稳定地提取局部几何特征。考虑到早期层中包含的有限语义,在前两个编码层中采用D-FPS,然后是所提出的实例感知下采样。256个代表点特征被馈送到上下文质心预测模块中,然后是三个MLP层(256→256→3) 以预测实例质心。最后,添加分类和回归层(三个MLP层)以输出语义标签和相应的边界框。
KITTI数据集上IA-SSD和其它SOTA方法性能速度对比:

1.与现有SOTA方法比较
在KITTI基准中,根据难度等级,汽车、行人和骑自行车的目标分为三个子集(“容易”、“中等”和“hard”),“中等”结果通常被用作最终排名的主要指标。如下表所示,提出的IA-SSD实现了SOTA的自行车检测性能,甚至优于几个strong点-体素和体素检测器[36,39]。这主要是因为提出的实例感知采样可以有效地保留前景点,从而能够准确检测小对象。
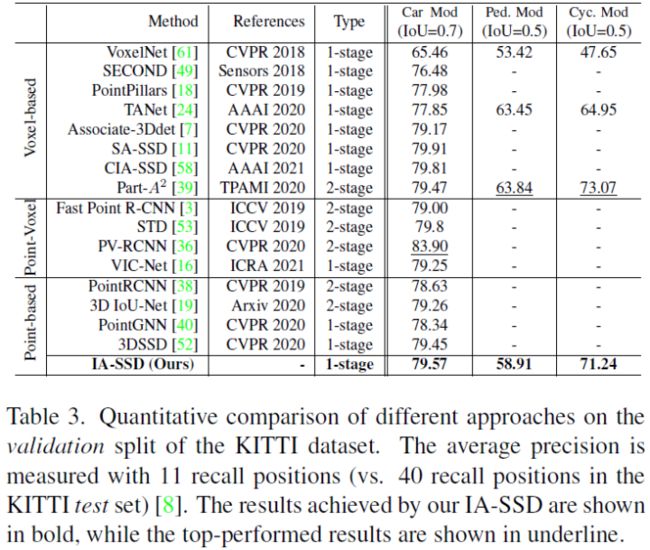
与其他基于point的检测器相比,IA-SSD还实现了最佳的车辆检测性能,比PointRCNN[38]提升(1.91%,4.68%,4.4%),比SOTA方法3DSSD[52]强(0.51%,0.75%,0.55%)。尽管具有不错的检测性能,所提出的IA-SSD也同样显示出优异的效率。它可以在单个NVIDIA RTX 2080Ti上以85 FPS的速度检测Intel [email protected])由于实例感知采样策略和上下文质心感知模块,可以与多类一起训练(即,训练单个模型以检测多类对象),而不是训练不同目标的单模型[52]。
为了公平比较,论文在Waymo数据集上调整了框架,将输入点的数量从16384个更改为65536个,并将每个采样层的采样比例增加到四倍,同时保持其余不变。此外,所有基线都基于OpenPCDet代码库实现,以进行严格比较,性能对比如下所示,行人非机动车车指标保持优势,机动车略差:

为了进一步验证IA-SSD在更复杂和现实情况下的通用性,还评估了IA-SSD对最新ONCE数据集的性能[26]。将60k点输入IA-SSD,类似于Waymo数据集上的设置,并训练80个epoch进行公正比较。如下表所示,论文的方法在所有基线中都具有竞争力。这再次验证了所提出的组件的优越性,以及方法应用于大规模复杂激光雷达场景的效率

速度评估,IA-SSD速度上占有绝对优势:

可视化结果如下:
6参考
[1] Not All Points Are Equal: Learning Highly Efficient Point-based Detectors for 3D LiDAR Point Clouds
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
