点云数据集
一、ModelNet40(点云分类)
普林斯顿ModelNet项目的目标是为计算机视觉、计算机图形学、机器人和认知科学领域的研究者们提供一个全面、干净的三维CAD模型集合, 该数据的主页地址https://modelnet.cs.princeton.edu, 数据最早发布在论文3D ShapeNets: A Deep Representation for Volumetric Shapes [CVPR 2015]上.
相关工作人员从数据中选择了常见的40类和10类构成数组子集, 分别表示为ModelNet40和ModelNet10, 且两个数据集都有orientation aligned的版本。实验中数据用到比较多的是ModelNet40, 有如下三种数据形式:
| 数据集 | modelnet40_normal_resampled.zip | modelnet40_ply_hdf5_2048.zip | ModelNet40.zip |
|---|---|---|---|
| 文件大小 | 1.71G | 435M | 2.04G |
| 内容 | point: x, y, z, normal_x, normal_y, normal_z; shape: 10k points |
point: x, y, z; normal_x, normal_y, normal_z; shape: 2048 points |
off格式, 具体参考这里 |
| 训练集 / 测试集 | 9843 / 2468 | 9840 / 2468 | 9844 / 2468 |
| 下载地址 | modelnet40_normal_resampled.zip | modelnet40_ply_hdf5_2048.zip | ModelNet40.zip |
二、ShapeNet Part(点云分割)
ShapeNet数据集是一个有丰富标注的、大规模的3D图像数据集, 发布于ShapeNet: An Information-Rich 3D Model Repository [arXiv 2015], 它是普林斯顿大学、斯坦福大学和TTIC研究人员共同努力的结果, 官方主页为shapenet.org.ShapeNet包括ShapeNetCore和ShapeNetSem子数据集.
ShapeNet Part是从ShapeNetCore数据集选择了16类并进行语义信息标注的数据集, 用于点云的语义分割任务, 其数据集发表于A Scalable Active Framework for Region Annotation in 3D Shape Collections [SIGGRAPH Asia 2016], 官方主页为 ShapeNet Part. 数据包含几个不同的版本, 其下载链接分别为shapenetcore_partanno_v0.zip (1.08G)和shapenetcore_partanno_segmentation_benchmark_v0.zip(635M). 下面就第2个数据集segmentation benchmark进行介绍:
从下面表格可以看出, ShapeNet Part总共有16类, 50个parts,总共包括16846个样本。该数据集中样本呈现出不均衡特性,比如Table包括5263个, 而Earphone只有69个。每个样本包含2000多个点, 属于小数据集。该数据集中训练集12137个, 验证集1870个, 测试集2874个, 总计16881个。[注意, 这里和下面表格统计的(16846)并不一样, 后来发现是训练集、验证集和测试集有35个重复的样本]
| 类别 | nparts/shape | nsamples | 平均npoints/shape |
|---|---|---|---|
| Airplane | 4 | 2690 | 2577 |
| Bag | 2 | 76 | 2749 |
| Cap | 2 | 55 | 2631 |
| Car | 4 | 898 | 2763 |
| Chair | 4 | 3746 | 2705 |
| Earphone | 3 | 69 | 2496 |
| Guitar | 3 | 787 | 2353 |
| Knife | 2 | 392 | 2156 |
| Lamp | 4 | 1546 | 2198 |
| Laptop | 2 | 445 | 2757 |
| Motorbike | 6 | 202 | 2735 |
| Mug | 2 | 184 | 2816 |
| Pistol | 3 | 275 | 2654 |
| Rocket | 3 | 66 | 2358 |
| Skateboard | 3 | 152 | 2529 |
| Table | 3 | 5263 | 2722 |
| Total | 50 | 16846 | 2616 |
三、S3DIS(语义分割)
S3DIS是3D室内场景的数据集, 主要用于点云的语义分割任务。主页http://buildingparser.stanford.edu/dataset.html. 关于S3DIS的论文是Joint 2D-3D-Semantic Data for Indoor Scene Understanding [arXiv 2017]和3D Semantic Parsing of Large-Scale Indoor Spaces [CVPR 2016]. S3DIS从3个building的6个Area采集得到, Area1, Area3, Area6属于buidling1, Area2和Area4属于building 2, Area5属于building 3. 常用的数据下载格式包括如下三种:
- Stanford3dDataset_v1.2_Aligned_Version.zip, 比如: RandLA-Net
- Stanford3dDataset_v1.2.zip, 比如: CloserLook3D
- indoor3d_sem_seg_hdf5_data.zip, 比如: PointNet
其中Stanford3dDataset_v1.2_Aligned_Version.zip和Stanford3dDataset_v1.2.zip都是完整场景的数据集, 每个点对应6个维度(x, y, z, r, g, b), 而indoor3d_sem_seg_hdf5_data.zip是对原始数据场景的切割,把大场景切割成1m x 1m的block: 完整数据集被切割成了23585个block, 每个block是4096个点, 每个点对应9个维度: 除了x, y, z, r, g, b信息外,剩余的3维是相对于所在大场景的位置(归一化坐标).
下面是由Stanford3dDataset_v1.2.zip数据统计得到的关于S3DIS的信息, 可能和论文中一些结果不太一致。S3DIS数据集由以上6个Area采集得到, 共包含272个场景, 可分为11种不同的场景(括号内为场景数量, 场景大小(点的数量)): office(156, 87w), conference room(11, 142w), hallway(61, 122w), auditorium(2, 817w), open space(1, 197w), lobby(3, 242w), lounge(3, 146w), pantry(3, 58w), copy room(2, 52w), storage(19, 35w) and WC(11, 70w). 根据语义信息, 上述场景被分成14个类别, 如下表所示. 可以看到不同的类别也是不均衡的, 比如wall有1547个, 但sofa只有55个.
| Total | column | clutter | chair | window | beam | floor | wall | ceiling | door | bookcase | board | table | sofa | stairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9833 | 254 | 3882 | 1363 | 168 | 159 | 284 | 1547 | 385 | 543 | 584 | 137 | 455 | 55 | 17 |
四、3DMatch数据集(关键点、特征描述子、点云配准等)
3DMatch数据集收集了来自于62个场景的数据,其中54个场景的数据用于训练,8个场景的数据用于评估,其具体名称查看train.txt和test.txt。3DMatch数据常用于3D点云的关键点,特征描述子,点云配准等任务。
官方主页 | 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions [CVPR 2017]
3DMatch原始数据集: 下载地址,共包括64个.zip文件。
以其中一个场景7-scenes-stairs为例,介绍其数据格式,如下截图所示,原始的3DMatch数据集包括两个.txt文件,多个seq文件夹,每个seq文件夹下包括多帧的.color.png, .depth.png, .pose.txt,可以看到, 其本身是不包括点云数据的,但是可以由这些数据生成点云数据(ply),一般是50帧-100帧生成一个点云数据,生成点云的代码可以参考fuse_fragments_3DMatch.py。

下面介绍3DMatch的训练集,包括FCGF和D3Feat处理的训练集。
1、3DMatch的训练集(FCGF)
3DMatch训练集来自54个场景,详细类别名称参见train.txt。每个场景均由1个seq或者多个seq的数据组成。这里以FCGF 网络使用的数据格式为例介绍3DMatch数据集。
首先,从这里下载训练集,下载解压后可以得到401个txt文件和2189个npz文件。2189个npz对应每个点云数据,包括(x, y, z)及对应的(r, g, b)信息,其中命名规则是场景@seqid-id,例如7-scenes-chess@seq-01_000.npz,表示此数据来自7-scenes-chess场景的seq-01,编号为000。401个txt表示这些npz的点云数据是如何关联的,其命名规则为场景@seqid-overlap,如[email protected]表示7-scenes-chess场景的seq-01下的overlap大于0.30的数据,打开此文件后,可以看到如下信息:
7-scenes-chess@seq-01_000.npz 7-scenes-chess@seq-01_001.npz 0.886878
7-scenes-chess@seq-01_000.npz 7-scenes-chess@seq-01_002.npz 0.636459
7-scenes-chess@seq-01_000.npz 7-scenes-chess@seq-01_003.npz 0.825012
7-scenes-chess@seq-01_000.npz 7-scenes-chess@seq-01_004.npz 0.783642
每一行表示点云之间的对应关系,如第一行表示点云7-scenes-chess@seq-01_000.npz和7-scenes-chess@seq-01_001.npz具有0.886878的overlap。可视化结果如下,第一个图中的红色的点云是7-scenes-chess@seq-01_000.npz,蓝色的点云是7-scenes-chess@seq-01_001.npz,可以看到两者是对齐的;第二个图是这两个点云的rgb信息的可视化。
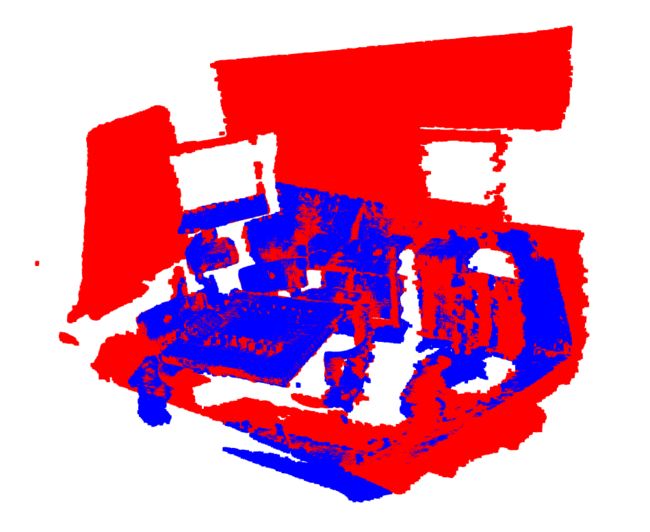

统计了一下,54个场景总共提供了7960对点云。
2、3DMatch训练集(D3Feat)
下载D3Feat训练使用的3DMatch数据集,解压后是6个.pkl文件,分别是 3DMatch_train_0.030_keypts.pkl, 3DMatch_train_0.030_overlap.pkl, 3DMatch_train_0.030_points.pkl, 3DMatch_val_0.030_keypts.pkl, 3DMatch_val_0.030_overlap.pkl和 3DMatch_val_0.030_points.pkl,可以通过这里查看这些.pkl文件是如何产生的。
-
3DMatch_train_0.030_keypts.pkl存储了什么信息 ?点云名(str, 如
sun3d-brown_bm_1-brown_bm_1/seq-01/cloud_bin_0) -> 点云(ndarray, n x 3)。总共有
3933个点云数据,点云点最少的是850个,点云点最多的是197343,平均点云点数量是27127。 -
3DMatch_train_0.030_overlap.pkl存储了什么信息 ?点云对(str, 如
7-scenes-pumpkin/seq-07/cloud_bin_11@7-scenes-pumpkin/seq-08/cloud_bin_2) -> overlap值(float)总共有
35297个点云对,overlap的最小值为0.30,最大值0.995,平均值为0.515。 -
3DMatch_train_0.030_points.pkl存储了什么信息 ?点云对(str, 如
analysis-by-synthesis-office2-5b/seq-01/cloud_bin_34@analysis-by-synthesis-office2-5b/seq-01/cloud_bin_35) -> 映射关系(ndarray, m x 2) -
可视化pairs中的点云和对应关键点

左图为两个具有overlap的点云的可视化,中间和右边的可视化是分别在红色和绿色点云上添加了对应点(蓝色区域)(来自于3DMatch_train_0.030_points.pkl)的可视化结果。
3、3DMatch的测试集
3DMatch的测试集包括以下8个场景,其中每个场景对应两个文件夹。以7-scenes-redkitchen为例,它包括7-scenes-redkitchen和7-scenes-redkitchen-evaluation两个文件夹,7-scenes-redkitchen文件夹下存放的是点云数据,命名格式均为cloud_bin_*.ply,共包括60个点云数据;7-scenes-redkitchen-evaluation/gt.log存放了correspondences点云对,组织格式为:
0 1 60
9.96926560e-01 6.68735757e-02 -4.06664421e-02 -1.15576939e-01
-6.61289946e-02 9.97617877e-01 1.94008687e-02 -3.87705398e-02
4.18675510e-02 -1.66517807e-02 9.98977765e-01 1.14874890e-01
0.00000000e+00 0.00000000e+00 0.00000000e+00 1.00000000e+00
0 2 60
9.54999224e-01 1.08859481e-01 -2.75869135e-01 -3.41060560e-01
-9.89491703e-02 9.93843326e-01 4.96360476e-02 -1.78254668e-01
2.79581388e-01 -2.01060700e-02 9.59896612e-01 3.54627338e-01
0.00000000e+00 0.00000000e+00 0.00000000e+00 1.00000000e+00
0 1 60中的0和1表示cloud_bin_0.ply和cloud_bin_1.ply点云是成对的,60表示总共包括有60个点云数据(前面也提到过),下面四列表示cloud_bin_1.ply -> cloud_bin_0.ply的变换矩阵。
可视化变换后的点云,红色的表示cloud_bin_0.ply点云,蓝色的表示对cloud_bin_1.ply变换后的点云,可视化结果显示两者基本重叠:
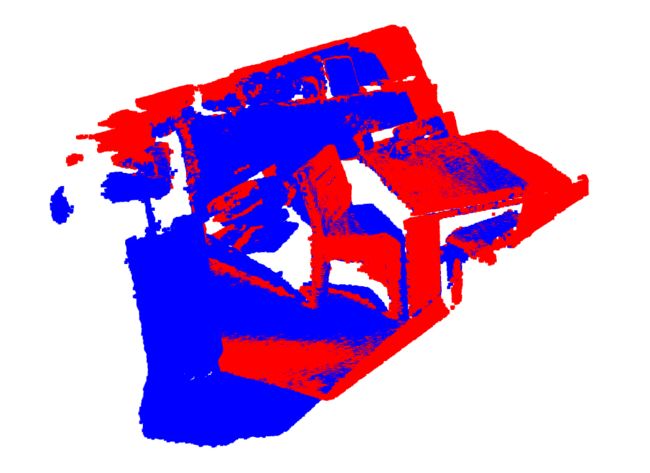
其它场景的统计数据如下,可视化和统计信息的代码均可通过test_set.py实现。
| 名称 | 点云数量 | Pairs数量 |
|---|---|---|
| 7-scenes-redkitchen | 60 | 506 |
| sun3d-home_at-home_at_scan1_2013_jan_1 | 60 | 156 |
| sun3d-home_md-home_md_scan9_2012_sep_30 | 60 | 208 |
| sun3d-hotel_uc-scan3 | 55 | 226 |
| sun3d-hotel_umd-maryland_hotel1 | 57 | 104 |
| sun3d-hotel_umd-maryland_hotel3 | 37 | 54 |
| sun3d-mit_76_studyroom-76-1studyroom2 | 66 | 292 |
| sun3d-mit_lab_hj-lab_hj_tea_nov_2_2012_scan1_erika | 38 | 77 |
| 总计 | 433 | 1623 |
五、3DMatch数据集的评估指标
评估指标主要基于FCGF [ICCV 2019],评估代码请参考https://github.com/chrischoy/FCGF/blob/master/scripts/benchmark_3dmatch.py。但Registration Recall的实现我感觉有问题,待日后再做补充吧。
- Feature-match Recall
M表示pairs点云对的数量,1 表示指示函数,![]() 是第s 个pair的correspondences,
是第s 个pair的correspondences,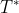 表当前pair点云的G.T.的R,t变换。
表当前pair点云的G.T.的R,t变换。![]() 是
是![]() 在
在 中选择的Feature Distance最小的点,即
中选择的Feature Distance最小的点,即![]() ,
,![]() 。
。![]() 和
和![]() 是两个超参数,常取值
是两个超参数,常取值![]() ,
, ![]() 。
。
简单的说,就是有M个点云对,对每一个点云对做一个是特征好/坏的判断: 在真实R,t的情况下,计算![]() 距离小于
距离小于![]() 的比例r,如果r大于
的比例r,如果r大于![]() ,则表示这个点云特征好,否则特征是坏的。
,则表示这个点云特征好,否则特征是坏的。
- Registration Recall
![]()
![]() 表示
表示 点云对中correspondences的数量,
点云对中correspondences的数量,![]() 表示G.T.的pair,
表示G.T.的pair,![]() 表示基于点云对预测的R,t变换。
表示基于点云对预测的R,t变换。
对于具有至少30% overlap的点云对,如果![]() ,则表示这是一个正确的点云对。
,则表示这是一个正确的点云对。