机器学习笔记之卡尔曼滤波(二)滤波思想的推导过程
机器学习笔记之卡尔曼滤波——滤波思想的推导过程(Filtering)
- 引言
-
- 回顾:隐马尔可夫模型 VS 卡尔曼滤波
-
- 离散状态动态模型(Discrete State Dynamic Model)
- 线性高斯动态模型(Linear Gaussian Dynamic Model)
- 滤波问题思想推导
-
- 公式推导过程
- 滤波问题求解步骤
- 迭代过程总结
引言
上一节介绍了动态模型,本节将介绍卡尔曼滤波模型中的滤波问题。
回顾:隐马尔可夫模型 VS 卡尔曼滤波
动态模型(Dynamic Model)的局部概率图模型表示如下:
这里并非单独比较隐马尔可夫模型和卡尔曼滤波两种模型,而是对描述隐马尔可夫模型和卡尔曼滤波的相关性质 进行比较:
(这里从模型参数的角度进行比较)
'非线性、非高斯动态模型'的代表(Non-Linear,Non-Gaussian Dynamic Model)——粒子滤波(Particle Filter)在后续介绍时再进行归纳,这里仅归纳2种模型。
离散状态动态模型(Discrete State Dynamic Model)
具有代表性的模型——隐马尔可夫模型。
- 状态转移概率 P ( i t ∣ i t − 1 ) \mathcal P(i_t \mid i_{t-1}) P(it∣it−1)
由于离散状态动态模型中的隐变量是离散型随机变量,因此 P ( i t ∣ i t − 1 ) \mathcal P(i_t \mid i_{t-1}) P(it∣it−1)通过查找状态转移矩阵 A \mathcal A A得到对应结果:
A = [ a i j ] K × K = [ a 11 , a 12 , ⋯ , a 1 K a 21 , a 22 , ⋯ , a 2 K ⋮ a K 1 , a K 2 , ⋯ , a K K ] K × K a i j = P ( i t = q j ∣ i t − 1 = q i ) \begin{aligned} \mathcal A & = [a_{ij}]_{\mathcal K \times \mathcal K} = \begin{bmatrix} a_{11},a_{12},\cdots,a_{1\mathcal K} \\ a_{21},a_{22},\cdots,a_{2\mathcal K} \\ \vdots \\ a_{\mathcal K1},a_{\mathcal K2},\cdots,a_{\mathcal K\mathcal K} \\ \end{bmatrix}_{\mathcal K \times \mathcal K} \\ a_{ij} & = \mathcal P(i_t = q_j \mid i_{t-1} = q_i) \end{aligned} Aaij=[aij]K×K=⎣⎢⎢⎢⎡a11,a12,⋯,a1Ka21,a22,⋯,a2K⋮aK1,aK2,⋯,aKK⎦⎥⎥⎥⎤K×K=P(it=qj∣it−1=qi)
其中 q i , q j q_i,q_j qi,qj均是 隐变量取值的离散集合 Q \mathcal Q Q中的元素:
q i , q j ∈ Q = { q 1 , q 2 , ⋯ , q K } \begin{aligned} q_i,q_j \in \mathcal Q = \{q_1,q_2,\cdots,q_{\mathcal K}\} \end{aligned} qi,qj∈Q={q1,q2,⋯,qK} - 发射概率 P ( o t ∣ i t ) \mathcal P(o_t \mid i_t) P(ot∣it)
离散状态动态模型中对观测变量 O = { o 1 , o 2 , ⋯ , o T } \mathcal O =\{o_1,o_2,\cdots,o_T\} O={o1,o2,⋯,oT}没有具体要求,它可以是离散型随机变量,也可以是连续型随机变量。这里为容易表达起见,设定 O \mathcal O O是离散型随机变量。因此 P ( o t ∣ i t ) \mathcal P(o_t \mid i_t) P(ot∣it)通过查找发射矩阵 B \mathcal B B得到相应结果:
B = [ b j ( k ) ] K × M = [ b 1 ( 1 ) , b 1 ( 2 ) , ⋯ , b 1 ( M ) b 2 ( 1 ) , b 2 ( 2 ) , ⋯ , b 2 ( M ) ⋮ b K ( 1 ) , b K ( 2 ) , ⋯ , b K ( M ) ] K × M b j ( k ) = P ( o t = v k ∣ i t = q j ) \begin{aligned} \mathcal B & = [b_j(k)]_{\mathcal K \times \mathcal M} = \begin{bmatrix} b_1(1),b_1(2),\cdots,b_1(\mathcal M) \\ b_2(1),b_2(2),\cdots,b_2(\mathcal M) \\ \vdots \\ b_{\mathcal K}(1),b_{\mathcal K}(2),\cdots,b_{\mathcal K}(\mathcal M) \\ \end{bmatrix}_{\mathcal K \times \mathcal M} \\ b_j(k) & = \mathcal P(o_t = v_k \mid i_t = q_j) \end{aligned} Bbj(k)=[bj(k)]K×M=⎣⎢⎢⎢⎡b1(1),b1(2),⋯,b1(M)b2(1),b2(2),⋯,b2(M)⋮bK(1),bK(2),⋯,bK(M)⎦⎥⎥⎥⎤K×M=P(ot=vk∣it=qj)
而 v k v_k vk表示 观测变量取值的离散集合 V \mathcal V V中的元素:
v k ∈ V = { v 1 , v 2 , ⋯ , v M } v_k \in \mathcal V = \{v_1,v_2,\cdots,v_{\mathcal M}\} vk∈V={v1,v2,⋯,vM} - 初始概率 P ( i 1 ) \mathcal P(i_1) P(i1)
在隐马尔可夫模型中介绍过,初始概率分布使用 π \pi π进行表示:
P ( i 1 ) = π \mathcal P(i_1) = \pi P(i1)=π
综上,离散状态动态模型需要求解的模型参数具体表示如下:
λ = ( π , A , B ) \lambda = (\pi,\mathcal A,\mathcal B) λ=(π,A,B)
线性高斯动态模型(Linear Gaussian Dynamic Model)
具有代表性的模型——卡尔曼滤波。
相比于离散状态动态模型,该模型更突出的是线性:隐变量与观测变量均是连续型随机变量。
- 状态转移概率 P ( i t ∣ i t − 1 ) \mathcal P(i_t \mid i_{t-1}) P(it∣it−1)
线性高斯动态模型中隐变量之间服从线性关系,且对应噪声服从高斯分布:
i t = A ⋅ i t − 1 + B + ϵ ϵ ∼ N ( 0 , Q ) P ( i t ∣ i t − 1 ) ∼ N ( A ⋅ i t − 1 + B , Q ) \begin{aligned} i_t = \mathcal A \cdot i_{t-1} + \mathcal B + \epsilon \quad \epsilon \sim \mathcal N(0,\mathcal Q)\\ \mathcal P(i_t \mid i_{t-1}) \sim \mathcal N(\mathcal A \cdot i_{t-1} + \mathcal B,\mathcal Q) \end{aligned} it=A⋅it−1+B+ϵϵ∼N(0,Q)P(it∣it−1)∼N(A⋅it−1+B,Q)
其中 A , B \mathcal A,\mathcal B A,B表示线性关系的模型参数; Q \mathcal Q Q表示转移过程高斯分布噪声的协方差信息。 - 发射概率 P ( o t ∣ i t ) \mathcal P(o_t \mid i_t) P(ot∣it)
同理,隐变量与观测变量之间同样服从线性关系,对应噪声服从高斯分布:
o t = C ⋅ i t + D + δ δ ∼ N ( 0 , R ) P ( o t ∣ i t ) ∼ N ( C ⋅ i t + D , R ) \begin{aligned} o_t = \mathcal C \cdot i_t + \mathcal D + \delta \quad \delta \sim \mathcal N(0,\mathcal R)\\ \mathcal P(o_t \mid i_t) \sim \mathcal N(\mathcal C \cdot i_t +\mathcal D,\mathcal R) \end{aligned} ot=C⋅it+D+δδ∼N(0,R)P(ot∣it)∼N(C⋅it+D,R)
这里的 C , D \mathcal C,\mathcal D C,D表示线性关系的模型参数; R \mathcal R R表示发射过程噪声高斯分布的协方差信息。 - 初始概率 P ( i 1 ) \mathcal P(i_1) P(i1)
不同于 π \pi π这种具体的概率值结果,线性高斯动态模型的初始概率同样是高斯分布:
P ( i 1 ) ∼ N ( μ 1 , Σ 1 ) \mathcal P(i_1) \sim \mathcal N(\mu_1,\Sigma_1) P(i1)∼N(μ1,Σ1)
综上,线性高斯动态模型需要求解的模型参数表示如下:
λ = ( A , B , C , D , Q , R , μ 1 , Σ 1 ) \lambda = (\mathcal A,\mathcal B,\mathcal C,\mathcal D,\mathcal Q,\mathcal R,\mu_1,\Sigma_1) λ=(A,B,C,D,Q,R,μ1,Σ1)
滤波问题思想推导
公式推导过程
我们需要解决的滤波问题具体表示如下:
P ( i t ∣ o t , o t − 1 , ⋯ , o 1 ) \mathcal P(i_t \mid o_t,o_{t-1},\cdots,o_1) P(it∣ot,ot−1,⋯,o1)
类似于求值问题 P ( O ∣ λ ) \mathcal P(\mathcal O \mid \lambda) P(O∣λ),我们希望通过迭代方式表示 t t t时刻滤波结果与其他时刻滤波结果之间的关联关系:
- 首先,滤波问题本身是一个条件概率。根据条件概率的定义,改写为如下形式:
P ( i t ∣ o 1 , ⋯ , o t ) = P ( i t , o 1 , ⋯ , o t ) P ( o 1 , ⋯ , o t ) \mathcal P(i_t \mid o_1, \cdots,o_t) = \frac{\mathcal P(i_t,o_1,\cdots,o_t)}{\mathcal P(o_1,\cdots,o_t)} P(it∣o1,⋯,ot)=P(o1,⋯,ot)P(it,o1,⋯,ot)
由于 P ( o 1 , ⋯ , o t ) \mathcal P(o_1,\cdots,o_t) P(o1,⋯,ot)是初始时刻到 t t t时刻观测变量的联合概率分布,而观测变量是给定的数据集合,因此 P ( o 1 , ⋯ , o t ) \mathcal P(o_1,\cdots,o_t) P(o1,⋯,ot)是可求的。令 C 1 = P ( o 1 , ⋯ , o t ) \mathcal C_1 = \mathcal P(o_1,\cdots,o_t) C1=P(o1,⋯,ot),则有:
P ( i t ∣ o 1 , ⋯ , o t ) = 1 C 1 P ( i t , o 1 , ⋯ , o t ) \mathcal P(i_t \mid o_1,\cdots,o_t) = \frac{1}{\mathcal C_1}\mathcal P(i_t,o_1,\cdots,o_t) P(it∣o1,⋯,ot)=C11P(it,o1,⋯,ot) - 将联合概率分布使用条件概率公式展开,展开为 o t o_t ot作为后验的条件概率的乘积形式:
P ( i t ∣ o 1 , ⋯ , o t ) = 1 C 1 [ P ( o t ∣ o 1 , ⋯ , o t − 1 , i t ) ⋅ P ( o 1 , ⋯ , o t − 1 , i t ) ] \mathcal P(i_t \mid o_1,\cdots,o_t) = \frac{1}{\mathcal C_1}\left[\mathcal P(o_t \mid o_1,\cdots,o_{t-1},i_t) \cdot \mathcal P(o_1,\cdots,o_{t-1},i_t)\right] P(it∣o1,⋯,ot)=C11[P(ot∣o1,⋯,ot−1,it)⋅P(o1,⋯,ot−1,it)]
观察中括号中的第一项,可以使用观测独立性假设改写成如下形式:
观测独立性假设是‘隐马尔可夫模型’中介绍的,需要的去复习一下~隐马尔可夫模型介绍-传送门
P ( o t ∣ o 1 , ⋯ , o t − 1 , i t ) = P ( o t ∣ i t ) \mathcal P(o_t \mid o_1,\cdots,o_{t-1},i_t) = \mathcal P(o_t \mid i_t) P(ot∣o1,⋯,ot−1,it)=P(ot∣it)
从而最终改写成如下形式:
P ( i t ∣ o 1 , ⋯ , o t ) = 1 C 1 [ P ( o t ∣ i t ) ⋅ P ( o 1 , ⋯ , o t − 1 , i t ) ] \mathcal P(i_t \mid o_1,\cdots,o_t) = \frac{1}{\mathcal C_1}\left[\mathcal P(o_t \mid i_t) \cdot \mathcal P(o_1,\cdots,o_{t-1},i_t)\right] P(it∣o1,⋯,ot)=C11[P(ot∣it)⋅P(o1,⋯,ot−1,it)] - 将括号中的 P ( o 1 , ⋯ , o t − 1 , i t ) \mathcal P(o_1,\cdots,o_{t-1},i_t) P(o1,⋯,ot−1,it)通过条件概率公式,展开成以 i t i_t it为后验的条件概率乘积形式:
P ( o 1 , ⋯ , o t − 1 , i t ) = P ( i t ∣ o 1 , ⋯ , o t − 1 ) ⋅ P ( o 1 , ⋯ , o t − 1 ) \mathcal P(o_1,\cdots,o_{t-1},i_t) = \mathcal P(i_t \mid o_1,\cdots,o_{t-1}) \cdot \mathcal P(o_1,\cdots,o_{t-1}) P(o1,⋯,ot−1,it)=P(it∣o1,⋯,ot−1)⋅P(o1,⋯,ot−1)
其中 P ( o 1 , ⋯ , o t − 1 ) \mathcal P(o_1,\cdots,o_{t-1}) P(o1,⋯,ot−1)同样也是观测变量的联合概率分布,是可求的。因此定义 C 2 = P ( o 1 , ⋯ , o t − 1 ) \mathcal C_2 = \mathcal P(o_1,\cdots,o_{t-1}) C2=P(o1,⋯,ot−1),从而有:
P ( i t ∣ o 1 , ⋯ , o t ) = C 2 C 1 [ P ( o t ∣ i t ) ⋅ P ( i t ∣ o 1 , ⋯ , o t − 1 ) ] \mathcal P(i_t \mid o_1,\cdots,o_t) = \frac{\mathcal C_2}{\mathcal C_1} \left[\mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid o_1,\cdots,o_{t-1})\right] P(it∣o1,⋯,ot)=C1C2[P(ot∣it)⋅P(it∣o1,⋯,ot−1)] - 继续观察中括号中的第二项:这明显是一个预测问题,通常采用方法是 通过积分,引入隐变量 i t − 1 i_{t-1} it−1:
其中红色框表示‘条件项’与‘后验项’;需要引入中间变量(蓝色框)将它们关联起来。
不要忘记,隐变量i t i_t it是连续型随机变量,其对应的积分是∫ i t \int_{i_t} ∫it。
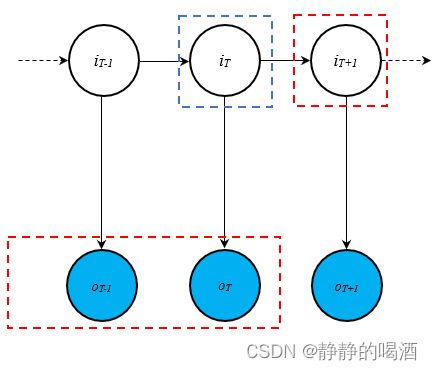
P ( i t ∣ o 1 , ⋯ , o t − 1 ) = ∫ i t − 1 P ( i t , i t − 1 ∣ o 1 , ⋯ , o t − 1 ) d i t − 1 \mathcal P(i_{t} \mid o_1,\cdots,o_{t-1}) = \int_{i_{t-1}}\mathcal P(i_t,i_{t-1} \mid o_1,\cdots,o_{t-1}) di_{t-1} P(it∣o1,⋯,ot−1)=∫it−1P(it,it−1∣o1,⋯,ot−1)dit−1
再根据条件概率的推导式,转化为如下格式:
∫ i t − 1 P ( i t ∣ i t − 1 , o 1 , ⋯ , o t − 1 ) ⋅ P ( i t − 1 ∣ o 1 , ⋯ , o t − 1 ) d i t − 1 \int_{i_{t-1}} \mathcal P(i_t \mid i_{t-1},o_1,\cdots,o_{t-1}) \cdot \mathcal P(i_{t-1} \mid o_1, \cdots,o_{t-1})di_{t-1} ∫it−1P(it∣it−1,o1,⋯,ot−1)⋅P(it−1∣o1,⋯,ot−1)dit−1
其中第一项使用齐次马尔可夫假设将其简化为 P ( i t ∣ i t − 1 ) \mathcal P(i_t \mid i_{t-1}) P(it∣it−1);第二项正是 t − 1 t-1 t−1时刻的滤波问题。
至此, t t t时刻与 t − 1 t-1 t−1时刻滤波结果的关联关系。最终结果整理如下:
P ( i t ∣ o 1 , ⋯ , o t ) = C 2 C 1 [ P ( o t ∣ i t ) ∫ i t − 1 P ( i t ∣ i t − 1 ) ⋅ P ( i t − 1 ∣ o 1 , ⋯ , o t − 1 ) d i t 1 ] = P ( o 1 , ⋯ , o t − 1 ) P ( o 1 , ⋯ , o t ) ⋅ [ P ( o t ∣ i t ) ∫ i t − 1 P ( i t ∣ i t − 1 ) ⋅ P ( i t − 1 ∣ o 1 , ⋯ , o t − 1 ) d i t − 1 ] \begin{aligned} \mathcal P(i_t \mid o_1,\cdots,o_t) & = \frac{\mathcal C_2}{\mathcal C_1}\left[\mathcal P(o_t \mid i_t) \int_{i_{t-1}} \mathcal P(i_t \mid i_{t-1}) \cdot \mathcal P(i_{t-1} \mid o_1,\cdots,o_{t-1}) di_{t_1}\right] \\ & = \frac{\mathcal P(o_1,\cdots,o_{t-1})}{\mathcal P(o_1,\cdots,o_t)} \cdot \left[\mathcal P(o_t \mid i_t) \int_{i_{t-1}} \mathcal P(i_t \mid i_{t-1}) \cdot \mathcal P(i_{t-1} \mid o_1,\cdots,o_{t-1}) di_{t-1}\right] \end{aligned} P(it∣o1,⋯,ot)=C1C2[P(ot∣it)∫it−1P(it∣it−1)⋅P(it−1∣o1,⋯,ot−1)dit1]=P(o1,⋯,ot)P(o1,⋯,ot−1)⋅[P(ot∣it)∫it−1P(it∣it−1)⋅P(it−1∣o1,⋯,ot−1)dit−1]
滤波问题求解步骤
卡尔曼滤波在处理滤波问题时,是使用在线算法(On-line Algorithm)。即 执行到某时刻时,才能够计算出该时刻关于隐变量的后验信息。
它的求解步骤是一个迭代过程。每一次迭代均包含2个步骤:
- 更新步骤(Update):根据给定的观测变量结果(从初始时刻 t o to to 当前时刻),求出当前时刻隐变量的后验概率分布:
P ( i t ∣ o 1 , ⋯ , o t ) \mathcal P(i_t \mid o_1,\cdots,o_t) P(it∣o1,⋯,ot) - 预测步骤(Prediction):根据给定的观测变量结果(从初始时刻 t o to to 当前时刻),求出下一时刻隐变量的后验概率分布:
P ( i t + 1 ∣ o 1 , ⋯ , o t ) \mathcal P(i_{t+1} \mid o_1,\cdots,o_t) P(it+1∣o1,⋯,ot)
具体过程表示如下:
已知条件:
- 隐变量初始时刻的概率分布 P ( i 1 ) \mathcal P(i_1) P(i1):
P ( i 1 ) ∼ N ( μ 1 , Σ 1 ) \mathcal P(i_1) \sim \mathcal N(\mu_1,\Sigma_1) P(i1)∼N(μ1,Σ1) - 基于观测独立性假设,观测变量 o t o_t ot在给定对应时刻隐变量 i t i_t it的条件概率 P ( o t ∣ i t ) \mathcal P(o_t \mid i_t) P(ot∣it):
P ( o t ∣ i t ) ∼ N ( C ⋅ i t + D , R ) \mathcal P(o_t \mid i_t) \sim \mathcal N(\mathcal C \cdot i_t +\mathcal D,\mathcal R) P(ot∣it)∼N(C⋅it+D,R) - 基于齐次马尔可夫假设,隐变量 i t i_t it在给定上一时刻隐变量 i t − 1 i_{t-1} it−1的条件概率 P ( i t ∣ i t − 1 ) \mathcal P(i_t \mid i_{t-1}) P(it∣it−1):
P ( i t ∣ i t − 1 ) ∼ N ( A ⋅ i t − 1 + B , Q ) \mathcal P(i_t \mid i_{t-1}) \sim \mathcal N(\mathcal A \cdot i_{t-1} + \mathcal B,\mathcal Q) P(it∣it−1)∼N(A⋅it−1+B,Q)
相关公式介绍:
本质上,卡尔曼滤波待求解的模型参数有很多:
λ = ( A , B , C , D , Q , R , μ 1 , Σ 1 ) \lambda = (\mathcal A,\mathcal B,\mathcal C,\mathcal D,\mathcal Q,\mathcal R,\mu_1,\Sigma_1) λ=(A,B,C,D,Q,R,μ1,Σ1)
但实际上,这些参数都是用来描述正态分布 的参数。因此这里给出出现条件概率、积分情况下 概率分布的变化:
这属于高斯分布的常用计算公式范畴,给大家推荐一篇相关推导文章。PRML笔记-高斯分布-传送门
给定 变量 X \mathcal X X的边缘概率分布 P ( X ) \mathcal P(\mathcal X) P(X) 与 给定 X \mathcal X X条件下,变量 Y \mathcal Y Y的条件概率分布 P ( Y ∣ X ) \mathcal P(\mathcal Y \mid \mathcal X) P(Y∣X) 如下:
这里假设'协方差矩阵'Λ , L \Lambda,\mathcal L Λ,L是‘正定矩阵’,它们均可以求逆。
{ P ( X ) : x ∈ P ( X ) , x ∼ N ( μ , Λ − 1 ) P ( Y ∣ X ) : y ∈ P ( Y ∣ X ) , y ∼ N ( A ⋅ x + B , L − 1 ) \begin{cases} \mathcal P(\mathcal X):x \in \mathcal P(\mathcal X),x\sim \mathcal N(\mu,\Lambda^{-1}) \\ \mathcal P(\mathcal Y \mid \mathcal X): y\in \mathcal P(\mathcal Y \mid \mathcal X),y \sim \mathcal N(\mathcal A \cdot x + \mathcal B,\mathcal L^{-1}) \end{cases} {P(X):x∈P(X),x∼N(μ,Λ−1)P(Y∣X):y∈P(Y∣X),y∼N(A⋅x+B,L−1)
则变量 Y \mathcal Y Y的边缘概率分布 P ( Y ) \mathcal P(\mathcal Y) P(Y)可表示为:
P ( Y ) = ∫ X P ( X , Y ) d X = ∫ X P ( X ) ⋅ P ( Y ∣ X ) d X → P ( Y ) : y ∈ P ( Y ) , y ∼ N ( A ⋅ μ + B , L − 1 + A Λ − 1 A T ) \begin{aligned} \mathcal P(\mathcal Y) & = \int_{\mathcal X} \mathcal P(\mathcal X,\mathcal Y)d\mathcal X = \int_{\mathcal X} \mathcal P(\mathcal X) \cdot \mathcal P(\mathcal Y \mid \mathcal X) d\mathcal X\\ & \to \mathcal P(\mathcal Y):y \in \mathcal P(\mathcal Y),y \sim \mathcal N(\mathcal A \cdot \mu + \mathcal B,\mathcal L^{-1} + \mathcal A \Lambda^{-1}\mathcal A^T) \end{aligned} P(Y)=∫XP(X,Y)dX=∫XP(X)⋅P(Y∣X)dX→P(Y):y∈P(Y),y∼N(A⋅μ+B,L−1+AΛ−1AT)
给定 Y \mathcal Y Y条件下,变量 X \mathcal X X的条件概率分布 P ( X ∣ Y ) \mathcal P(\mathcal X \mid \mathcal Y) P(X∣Y)可表示为:
P ( X ∣ Y ) = P ( Y ∣ X ) ⋅ P ( X ) P ( Y ) → P ( X ∣ Y ) : x ∈ P ( X ∣ Y ) , x ∼ N ( Σ { A T L ( y − B ) + A μ } , Σ ) Σ = Λ + A T L A − 1 \begin{aligned} \mathcal P(\mathcal X \mid \mathcal Y) & = \frac{\mathcal P(\mathcal Y \mid \mathcal X) \cdot \mathcal P(\mathcal X)}{\mathcal P(\mathcal Y)} \\ & \to \mathcal P(\mathcal X \mid \mathcal Y): x\in \mathcal P(\mathcal X \mid \mathcal Y),x \sim \mathcal N(\Sigma \{\mathcal A^T \mathcal L(y-\mathcal B) + \mathcal A \mu\},\Sigma) \quad \Sigma = \Lambda + \mathcal A^T \mathcal L\mathcal A^{-1} \end{aligned} P(X∣Y)=P(Y)P(Y∣X)⋅P(X)→P(X∣Y):x∈P(X∣Y),x∼N(Σ{ATL(y−B)+Aμ},Σ)Σ=Λ+ATLA−1
具体过程:
- 初始步骤 ( t = 1 ) (t=1) (t=1):
- 隐变量 i 1 i_1 i1的初始化作为 i 1 i_1 i1的 更新步骤(Update):
P ( i 1 ∣ o 1 ) = P ( i 1 ) ∼ N ( μ 1 , Σ 1 ) \mathcal P(i_1 \mid o_1) = \mathcal P(i_1) \sim \mathcal N(\mu_1,\Sigma_1) P(i1∣o1)=P(i1)∼N(μ1,Σ1) - 预测步骤:基于 P ( i 1 ∣ o 1 ) \mathcal P(i_1\mid o_1) P(i1∣o1),求解下一时刻隐变量 i 2 i_2 i2基于 o 1 o_1 o1的条件概率 P ( i 2 ∣ o 1 ) \mathcal P(i_2 \mid o_1) P(i2∣o1):
P ( i 2 ∣ o 1 ) = ∫ i 1 P ( i 2 ∣ i 1 ) ⋅ P ( i 1 ∣ o 1 ) \begin{aligned} \mathcal P(i_2 \mid o_1) = \int_{i_1} \mathcal P(i_2 \mid i_1) \cdot \mathcal P(i_1 \mid o_1) \end{aligned} P(i2∣o1)=∫i1P(i2∣i1)⋅P(i1∣o1)
根据已知条件, P ( i 2 ∣ i 1 ) ∼ N ( A ⋅ i 1 + B , Q ) \mathcal P(i_2 \mid i_1) \sim \mathcal N(\mathcal A \cdot i_1 + \mathcal B,\mathcal Q) P(i2∣i1)∼N(A⋅i1+B,Q),结合初始概率分布, P ( i 2 ∣ o 1 ) \mathcal P(i_2 \mid o_1) P(i2∣o1)的概率分布表示如下:
P ( i 2 ∣ o 1 ) ∼ N ( A ⋅ μ 1 + B , Q + A Σ 1 A T ) \mathcal P(i_2\mid o_1) \sim \mathcal N(\mathcal A \cdot \mu_1 +\mathcal B,\mathcal Q + \mathcal A \Sigma_1 \mathcal A^T) P(i2∣o1)∼N(A⋅μ1+B,Q+AΣ1AT)
至此,我们通过预测步骤求解出 P ( i 2 ∣ o 1 ) \mathcal P(i_2 \mid o_1) P(i2∣o1)的概率分布:
注意,这仅是一个‘预测结果’。
{ μ 2 = A ⋅ μ 1 + B Σ 2 = Q + A Σ 1 A T \begin{cases} \mu_2 = \mathcal A \cdot \mu_1 +\mathcal B \\ \Sigma_2 = \mathcal Q + \mathcal A \Sigma_1 \mathcal A^T \end{cases} {μ2=A⋅μ1+BΣ2=Q+AΣ1AT
- 隐变量 i 1 i_1 i1的初始化作为 i 1 i_1 i1的 更新步骤(Update):
- t = 2 t=2 t=2时刻:
通过 预测步骤 得到了 P ( i 2 ∣ o 1 ) \mathcal P(i_2 \mid o_1) P(i2∣o1)的概率分布结果,结合观测独立性概率 P ( o 2 ∣ i 2 ) \mathcal P(o_2 \mid i_2) P(o2∣i2),求解 P ( i 2 ∣ o 1 , o 2 ) \mathcal P(i_2 \mid o_1,o_2) P(i2∣o1,o2)。- 更新步骤:
已知:
P ( o 2 ∣ i 2 ) ∼ N ( C ⋅ i 2 + D , R ) P ( i 2 ∣ o 1 ) ∼ N ( μ 2 , Σ 2 ) \begin{aligned} \mathcal P(o_2 \mid i_2) & \sim \mathcal N(\mathcal C \cdot i_2 + \mathcal D,\mathcal R) \\ \mathcal P(i_2 \mid o_1) & \sim \mathcal N(\mu_2,\Sigma_2) \end{aligned} P(o2∣i2)P(i2∣o1)∼N(C⋅i2+D,R)∼N(μ2,Σ2)
则有:
P ( i 2 ∣ o 1 , o 2 ) = P ( o 1 ) P ( o 1 , o 2 ) [ P ( o 2 ∣ i 2 ) ⋅ P ( i 2 ∣ o 1 ) ] ∝ P ( o 2 ∣ i 2 ) ⋅ P ( i 2 ∣ o 1 ) \begin{aligned} \mathcal P(i_2 \mid o_1,o_2) & = \frac{\mathcal P(o_1)}{\mathcal P(o_1,o_2)} \left[\mathcal P(o_2\mid i_2) \cdot \mathcal P(i_2 \mid o_1)\right] \\ & \propto \mathcal P(o_2\mid i_2) \cdot \mathcal P(i_2 \mid o_1) \end{aligned} P(i2∣o1,o2)=P(o1,o2)P(o1)[P(o2∣i2)⋅P(i2∣o1)]∝P(o2∣i2)⋅P(i2∣o1)
将结果代入上述公式中:
P ( i 2 ∣ o 1 , o 2 ) ∼ N ( Σ { C T R − 1 ( o 2 − D ) + C ⋅ μ 2 } , Σ ) Σ = Σ 2 − 1 + C R − 1 C − 1 { μ 2 ∗ = ( Σ 2 − 1 + C R − 1 C − 1 ) { C T R − 1 ( o 2 − D ) + C ⋅ μ 2 } Σ 2 ∗ = Σ 2 − 1 + C R − 1 C − 1 \begin{aligned} \mathcal P(i_2 \mid o_1,o_2) & \sim \mathcal N(\Sigma \{\mathcal C^T\mathcal R^{-1}(o_2 - \mathcal D) + \mathcal C \cdot \mu_2\},\Sigma) \quad \Sigma = \Sigma_2^{-1} + \mathcal C \mathcal R^{-1}\mathcal C^{-1} \\ & \begin{cases} \mu_2^* = (\Sigma_2^{-1} + \mathcal C \mathcal R^{-1}\mathcal C^{-1}) \{\mathcal C^T\mathcal R^{-1}(o_2 - \mathcal D) + \mathcal C \cdot \mu_2\}\\ \Sigma_2^* = \Sigma_2^{-1} + \mathcal C \mathcal R^{-1}\mathcal C^{-1} \end{cases} \end{aligned} P(i2∣o1,o2)∼N(Σ{CTR−1(o2−D)+C⋅μ2},Σ)Σ=Σ2−1+CR−1C−1{μ2∗=(Σ2−1+CR−1C−1){CTR−1(o2−D)+C⋅μ2}Σ2∗=Σ2−1+CR−1C−1
- 更新步骤:
- 后续时刻以此类推。
迭代过程总结
观察上面的求解步骤,它明显包含两个步骤:
- 预测步骤(Prediction):对下一时刻的隐变量进行一个预测:
P ( i 2 ∣ o 1 ) ∼ N ( μ 2 , Σ 2 ) { μ 2 = A ⋅ μ 1 + B Σ 2 = Q + A Σ 1 A T \mathcal P(i_2 \mid o_1) \sim \mathcal N(\mu_2,\Sigma_2) \\ \begin{cases} \mu_2 = \mathcal A \cdot \mu_1 +\mathcal B \\ \Sigma_2 = \mathcal Q + \mathcal A \Sigma_1 \mathcal A^T \end{cases} P(i2∣o1)∼N(μ2,Σ2){μ2=A⋅μ1+BΣ2=Q+AΣ1AT - 更新步骤(Update):在上一时刻预测的基础上,对当前时刻隐变量进行更新。同时对下一时刻隐变量进行预测。
P ( i 2 ∣ o 1 , o 2 ) ∼ N ( Σ { C T R − 1 ( o 2 − D ) + C ⋅ μ 2 } , Σ ) Σ = Σ 2 − 1 + C R − 1 C − 1 { μ 2 ∗ = ( Σ 2 − 1 + C R − 1 C − 1 ) { C T R − 1 ( o 2 − D ) + C ⋅ μ 2 } Σ 2 ∗ = Σ 2 − 1 + C R − 1 C − 1 \begin{aligned} \mathcal P(i_2 \mid o_1,o_2) & \sim \mathcal N(\Sigma \{\mathcal C^T\mathcal R^{-1}(o_2 - \mathcal D) + \mathcal C \cdot \mu_2\},\Sigma) \quad \Sigma = \Sigma_2^{-1} + \mathcal C \mathcal R^{-1}\mathcal C^{-1} \\ & \begin{cases} \mu_2^* = (\Sigma_2^{-1} + \mathcal C \mathcal R^{-1}\mathcal C^{-1}) \{\mathcal C^T\mathcal R^{-1}(o_2 - \mathcal D) + \mathcal C \cdot \mu_2\}\\ \Sigma_2^* = \Sigma_2^{-1} + \mathcal C \mathcal R^{-1}\mathcal C^{-1} \end{cases} \end{aligned} P(i2∣o1,o2)∼N(Σ{CTR−1(o2−D)+C⋅μ2},Σ)Σ=Σ2−1+CR−1C−1{μ2∗=(Σ2−1+CR−1C−1){CTR−1(o2−D)+C⋅μ2}Σ2∗=Σ2−1+CR−1C−1 - 重复执行上述两个步骤。
( μ 2 , Σ 2 ) → ( μ 2 ∗ , Σ 2 ∗ ) (\mu_2,\Sigma_2) \to (\mu_2^*,\Sigma_2^*) (μ2,Σ2)→(μ2∗,Σ2∗),是一个明显的“先预测,再对预测修正”的过程。
至此,卡尔曼滤波部分介绍结束,下一节将介绍粒子滤波(Particle Filter)。
相关参考:
【PRML】高斯分布
机器学习-白板推导系列(十五)-线性动态系统-卡曼滤波(Kalman Filter)笔记
机器学习-线性动态系统2-Filtering问题
机器学习-线性动态系统3-Filtering问题求解