Python神经网络学习(五)--机器学习--简单的神经网络
前言
抱歉时隔这么久再讲神经网络的内容,希望大家还没忘记第二期的内容:分类器是什么东西?https://blog.csdn.net/qq_38431572/article/details/117199679 https://blog.csdn.net/qq_38431572/article/details/117199679
https://blog.csdn.net/qq_38431572/article/details/117199679
第二期讲的是分类器,而上一期(第四期)的线性回归讲的是预测器,如果大家把概念搞混了,可以去第一期再回顾一下,上面的文章都是3-5分钟的阅读量。
前面回顾
在第一期中已经讲过,代码中神经元就相当于一个小的功能函数,那么当很多个神经元组合起来,就能完成很多的事情了。
多层次的神经网络就是利用每个层次多个神经网络,多层链接,然后就完成了复杂的任务。
本期速看
这次就从三层的神经网络起步,最后完成一个验证码识别的任务(会提供源码和验证码图片,等审核通过后上传到下载里面,评论区提供链接)
本期的公式中,注意我使用的 * 和 · 符号,前面 * 是普通乘法,后面 · 是矩阵点乘。
三层神经网络
一层,一个神经元
先从最简单的开始,这个想必大家已经很熟悉了,一个神经元,接受一个输入,然后通过激活函数计算,计算完成之后的结果和目标值进行比较,然后得到误差,之后把参数+这个误差的一部分(乘以学习率),完成误差更新,重复很多次之后就完成了训练。
三层,每层三个神经元
三层神经元的结构和原理
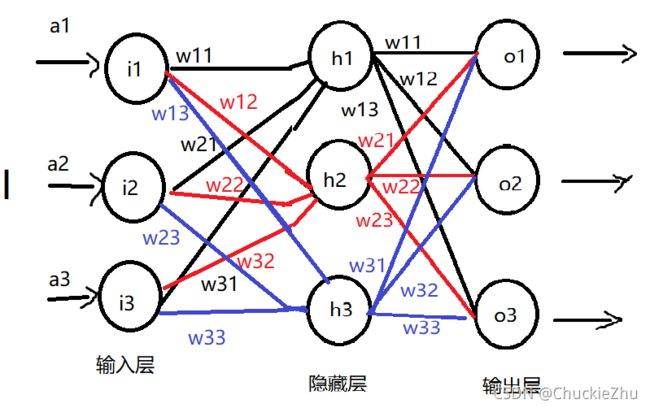
这个时候比较麻烦,三层的结构是这样的:
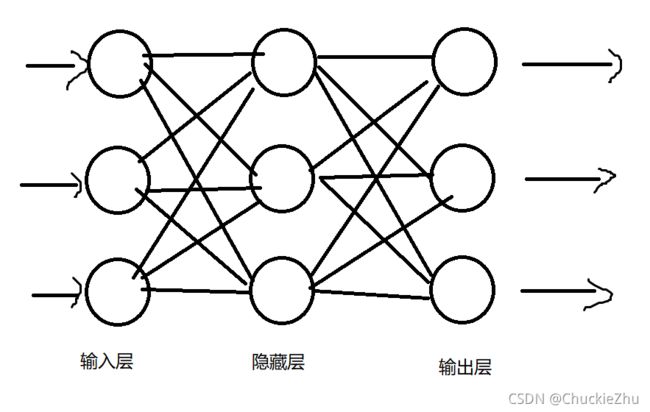
看起来乱七八糟的,但是原理还是一样的:
刚开始在输入层接收三个输入的值,通过计算,向右一直传递(向前传递),然后经过隐藏层的计算,经过输出层的计算,得到最终的输出结果,把这个结果和真实的结果比较,得到误差,然后反向计算每一层的误差,根据误差更新参数,重复多次后就得到了最终的结果。
输入层
顾名思义,这个层级仅仅用来输入数据,不会做任何的处理,直接把输入向隐藏层传递,这也符合我们的认知,输入层就是用来输入的,输入什么就应该是什么。
隐藏层
无论隐藏层有多少层,统称为隐藏层,这里隐藏层只有1层,是特殊情况。除了输入层和输出层都是隐藏层。
输出层
对于分类器来讲,一般输出层的数量和分类的数量有关,比如0-9共10个数字,就需要10个输出神经元。具体使用时需要实际调整。
输入在三个层级的流动
输入层-隐藏层
上面的图片有点乱,也令人害怕,不如先看一部分,先看四个节点:

那么,单论这一个隐藏层的节点来看,就非常明了了,这个节点的输入就是:
![]()
其中w就是权重,w11代表前一层的第1个->后一层的第1个。w21表示前一层的第2个->后一层的第1个,以此类推,a就是代表网络的输入。
同理,隐藏层其他两个节点的输入也就能算了:
![]()
![]()
问题在于,如果节点很多,不能写很多这样的式子,这是可以引入矩阵乘法,重写h1的输入:
W就是权重矩阵,I就是输入的矩阵,同理:
整个隐藏层的输入就是: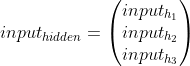
那上面三个式子又可以再次合并了:
其中,![]() 代表隐藏层的输入,
代表隐藏层的输入, ![]() 代表输入层和隐藏层之间的权重矩阵,I 就代表了整个神经网络的输入。这次我们把符号标入图片,再来看这两层:
代表输入层和隐藏层之间的权重矩阵,I 就代表了整个神经网络的输入。这次我们把符号标入图片,再来看这两层:
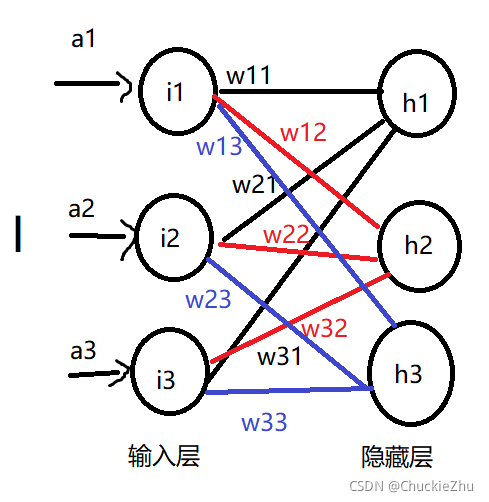
这时是不是就清晰了很多,下面的操作就是使用激活函数给每个隐藏层的输入计算一下,这就是隐藏层的输出(这里选择sigmoid作为激活函数):
隐藏层-输出层
先把隐藏层和输出层的连接图画出来:
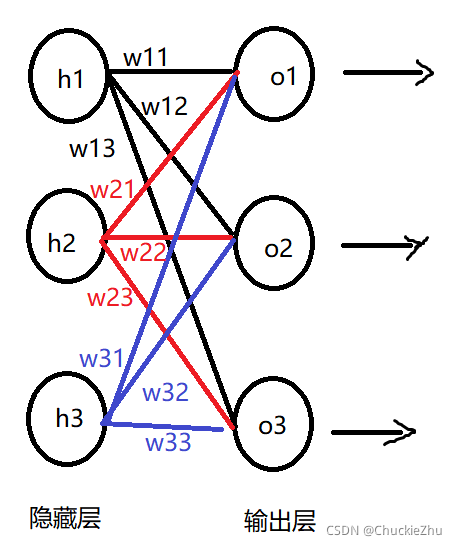
同理,根据图可以写出最终的输出公式:
![]()
其中,![]() 是输出层的输入,
是输出层的输入,![]() 是隐藏层->输出层的权重矩阵,
是隐藏层->输出层的权重矩阵,![]() 是隐藏层的输出。
是隐藏层的输出。
输入层-隐藏层-输出层
现在再来回顾整张图片,相信大家不会再害怕了吧:
计算误差
方法
和之前一样,我们使用实际值-计算值作为误差,在这个网络中,假设实际应该得到的输出是:![]() , 上面计算我们得到的输出是:
, 上面计算我们得到的输出是:![]() ,那么整个网络的误差就是:
,那么整个网络的误差就是:
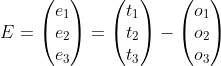 。
。
和之前一样,我们可以获得误差的平方项:
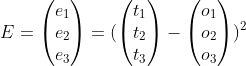
现在回顾一下,我们需要通过误差矫正所有的权重,根据梯度下降的算法(第四期讲的),权重的更新公式应该如同这样:
![]()
这时,我们发现E里面只有 t 和 o ,没有w啊,可以不难发现,o 是由 w 计算出来的,应用链式法则:
![]() 。
。
只拿出来两个节点说明,单独看e1:
误差:![]()
误差对权重的导数:
(删除常数2是因为常数可以通过学习率修正,所以无论常数是多少,都可以删除掉,也可以不删除)
对于计算误差来说,t1和o1都已经知道了,下一步就是计算后面的偏导数,再来看:
![]() ,更精确的写,应该是:
,更精确的写,应该是:![]() ,即输出层的输出对隐层-输出层的权重的偏导数,那这个式子又可以写成这样:
,即输出层的输出对隐层-输出层的权重的偏导数,那这个式子又可以写成这样:
![]()
其中,Sigmoid()求导是Sigmoid(1-Sigmoid()),在这里不计算了,大家有兴趣算一下。
Sigmoid()内部的部分对w求导,得到一个常数C乘以![]() ,如上所述,常数省略掉。整个大式子化简成:
,如上所述,常数省略掉。整个大式子化简成:
![]()

虽然很长,但是推导下来,也不觉得恐怖,只需要按照这个步骤敲代码就好了。
假定现在我们计算出了这个e,现在要怎么传递呢?
输出层-隐藏层
先把前面的图拿来一下:
假定这个![]() (o1处的误差)已知,误差向前传递,很容易想明白:谁给的东西多,就谁的误差大。
(o1处的误差)已知,误差向前传递,很容易想明白:谁给的东西多,就谁的误差大。
比如,o1这个节点,h1提供了w11的权重,h2提供了w21的权重,h3提供了w31的权重,那么误差从o1传递回去就应该给h1传递
![]() ,
,
同理:
o1给h2传递:![]()
o1给h3传递:![]()
可以发现,这三个误差的分母是相同的,那干脆都不要了,权直接删掉权重。
同理可计算o2、o3向前传递的误差。使用矩阵形式表示:
这个就是误差传播的矩阵,这个权重矩阵正好是前向传播矩阵的转置矩阵。
那么整个训练就可以根据这些东西来。
代码实现
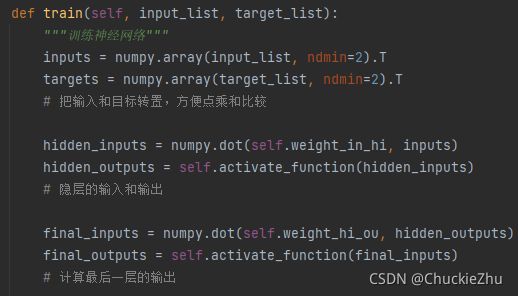
训练
前向计算输出
反向计算误差
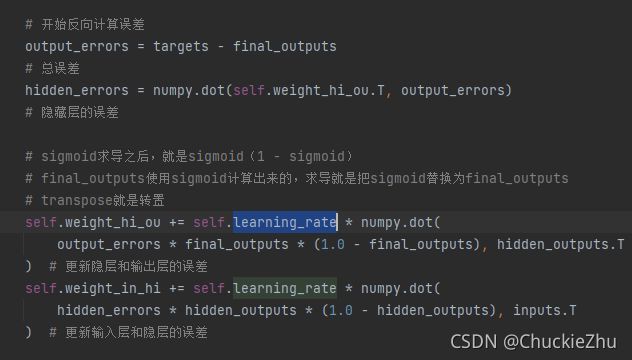
预测
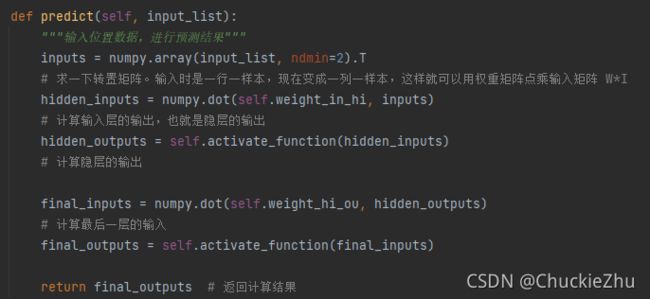
其实代码的每一个步骤都是和上面的推导一一对应,代码中注释页很齐全,希望大家比着代码多多理解。
验证码识别
图片来源
我自己使用windows的画图软件,调整图片大小,自己手写的图片。
识别策略
首先把图片切割为四个部分,然后分别识别,最后汇总结果:
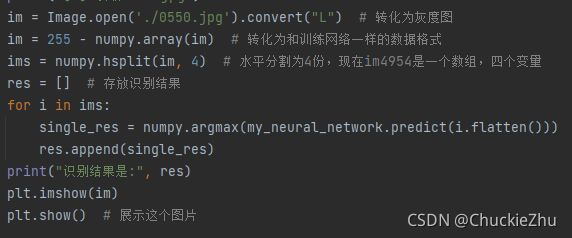
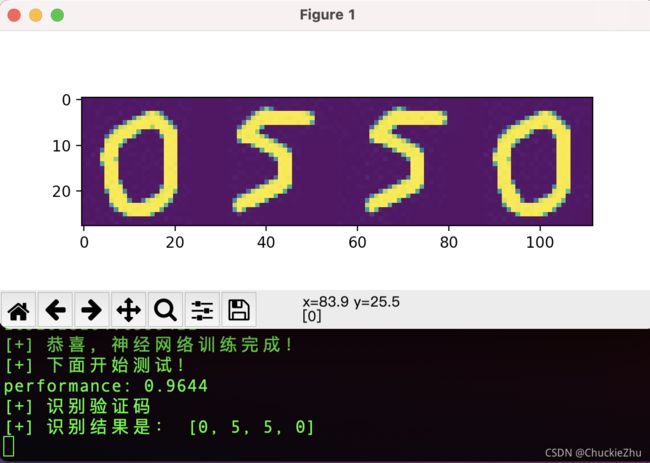
识别效果
(windows太慢了,最后用mac跑的代码,M1芯片,大概只用了一分钟。windows10 10代i5好像需要200+秒的样子):
结束语
本期有点晦涩,如果不懂欢迎评论区留言讨论,希望大家都能理解明白。
感谢观看!