实验——参数估计与非参数估计
目录
- 1 最大似然估计
-
- 1.1 实验要求
- 1.2 实验思路
- 1.3 代码实现
- 1.4 实验结果
- 2 Parzen窗
-
- 2.1 实验要求
- 2.2 实验思路
- 2.3 代码实现
- 2.4 实验结果
- 3 K近邻
-
- 3.1 实验要求
- 3.2 实验思路
- 3.3 代码实现及结果
-
- 3.3.1 一维情况
- 3.3.2 二维情况
- 3.3.3 三维情况
- 4 KNN实战
-
- 4.1 实验要求
- 4.2 实验思路
- 4.3 实验结果与思考
1 最大似然估计
1.1 实验要求
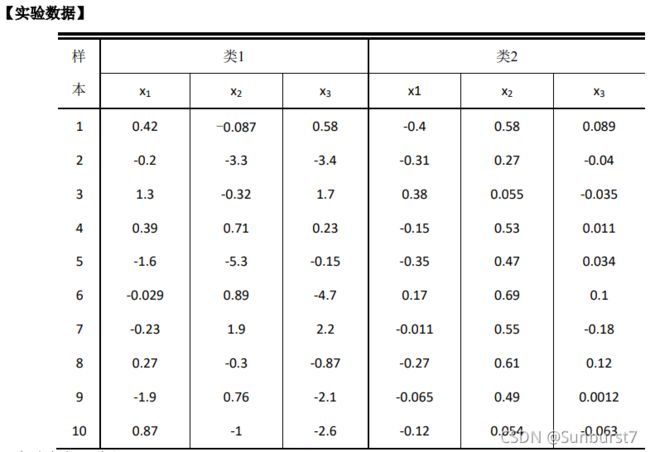
使用上面给出的三维数据:
-
编写程序,对类1和类2中的三个特征分别求解最大似然估计的均值̂和方差 σ 2 \sigma^2 σ2。
-
编写程序,处理二维数据的情形()~(µ, Σ)。对类1和类2中任意两个特征的组合分别求解最大似然估计的均值̂和方差 Σ \Sigma Σ(每个类有3种可能)。
-
编写程序,处理三维数据的情形()~(µ, Σ)。对类1和类2中三个特征求解最大似然估计的均值̂和 方差。
-
假设该三维高斯模型是可分离的,即 Σ = d i a g ( σ 1 , σ 2 , σ 3 ) \Sigma=diag(\sigma^1,\sigma^2,\sigma^3) Σ=diag(σ1,σ2,σ3),编写程序估计类1和类2中的均值和协方差矩阵中的参数。
-
比较前 4 种方法计算出来的每一个特征的均值 μ \mu μ的异同,并加以解释。
-
比较前 4 种方法计算出来的每一个特征的方差 σ \sigma σ的异同,并加以解释。
1.2 实验思路
根据最大似然估计的原理,可以推导出:**均值的最大似然估计就是样本的均值,而协方差的最大似然估计是n个 ( x k − μ ^ ) ( x k − μ ^ ) t (\textbf{x}_k-\hat{\mu})(\textbf{x}_k-\hat{\mu})^t (xk−μ^)(xk−μ^)t的算术平均。**实际上对方差的最大似然估计是有偏的估计,样本的协方差矩阵 C = 1 n − 1 ( x k − μ ^ ) ( x k − μ ^ ) t C=\frac{1}{n-1}(\textbf{x}_k-\hat{\mu})(\textbf{x}_k-\hat{\mu})^t C=n−11(xk−μ^)(xk−μ^)t,而我们估计的方差是 σ ^ = n − 1 n C \hat{\sigma}=\frac{n-1}{n}C σ^=nn−1C,具体原理可以看:参数估计—最大似然估计与贝叶斯估计

对于任意一个多元的高斯分布,这里的多元就对应着数据的多特征(例如本次实验中的x1,x2,x3),此高斯分布的采样是以列向量的形式,每行的值为一个随机变量,因此计算统计属性:
- 均值:分别计算每个特征的均值,以向量的形式输出,即均值向量
- 方差:数据集中所有向量(列向量)计算 ( x − μ ) ( x − μ ) T (\textbf{x}-\mu)(\textbf{x}-\mu)^T (x−μ)(x−μ)T,在求和取平均
当高斯模型是可分离的时,说明每个特征(随机变量)相互独立,则任意两个特征的协方差为0(Cov(x1,x2)=0),因此协方差矩阵的形式如下:
[ σ 1 2 0 . . . 0 0 σ 2 2 0 . . . . . . 0 0 σ n 2 ] \begin{bmatrix} \sigma_{1}^2 & 0 & ... & 0\\ 0 & \sigma_{2}^2 & & 0\\ ... & & ... & \\ 0 & 0 & & \sigma_{n}^2 \end{bmatrix} ⎣⎢⎢⎡σ120...00σ220......00σn2⎦⎥⎥⎤
1.3 代码实现
数据以DataFrame的形式存储,计算均值向量的函数:
# 通用的计算一个数据集的平均向量
def calculateAvg(vectors:pd.DataFrame):
# 创建一个空Series存储平均数
avg = pd.Series(index=vectors.columns,dtype=float)
for column in vectors.columns:
# 分别计算每个特诊的平均值
avg[column] = vectors[column].mean()
return np.array(avg)
计算协方差矩阵的函数:
# 通用的计算一个数据集的估计协方差矩阵:对每个向量求其协方差矩阵再求和取平均
# 返回一个协方差矩阵,训练集内是一维向量的话返回的矩阵只有一个元素
def calculateCov(vectors:pd.DataFrame):
# 计算数据集的均值列向量
mu = np.matrix(calculateAvg(vectors)).T
# 获取训练集中每个随机变量的维度
dimension = vectors.shape[1]
Cov = np.zeros((dimension,dimension))
for index,row in vectors.iterrows():
# 取出训练集中的每一个数据,形式为列向量
xi = np.matrix(row).T
diff = xi - mu
Cov+=diff*diff.T
# 取平均
return Cov/vectors.shape[0]
利用DataFrame[[特征1,特征2,..]]来提取训练集中的某几个特征,分别实现计算。
-
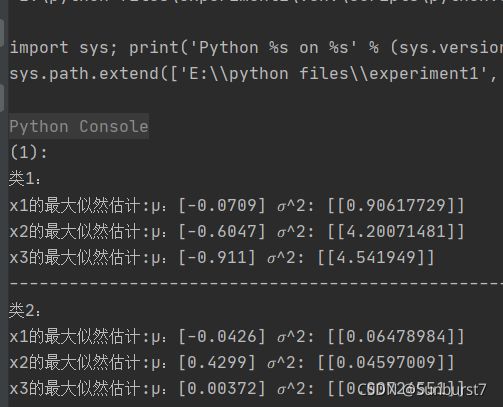
问(1)编写程序,对类1和类2中的三个特征分别求解最大似然估计的均值̂和方差 σ 2 \sigma^2 σ2。
# 创建数据帧 trainSet_1 = pd.read_csv('w1.csv') trainSet_2 = pd.read_csv('w2.csv') # (1)对类 1 和类 2 中的三个特征分别求解最大似然估计的均值̂和方差2。 print("(1): ") print("类1:") trainSet_1_x1 = trainSet_1['x1'].to_frame() print("x1的最大似然估计:μ:"+str(calculateAvg(trainSet_1_x1))+" ^2: "+str(calculateCov(trainSet_1_x1))) trainSet_1_x2 = trainSet_1['x2'].to_frame() print("x2的最大似然估计:μ:"+str(calculateAvg(trainSet_1_x2))+" ^2: "+str(calculateCov(trainSet_1_x2))) trainSet_1_x3 = trainSet_1['x3'].to_frame() print("x3的最大似然估计:μ:"+str(calculateAvg(trainSet_1_x3))+" ^2: "+str(calculateCov(trainSet_1_x3))) print("------------------------------------------------------------------------------") print("类2:") trainSet_2_x1 = trainSet_2['x1'].to_frame() print("x1的最大似然估计:μ:"+str(calculateAvg(trainSet_2_x1))+" ^2: "+str(calculateCov(trainSet_2_x1))) trainSet_2_x2 = trainSet_2['x2'].to_frame() print("x2的最大似然估计:μ:"+str(calculateAvg(trainSet_2_x2))+" ^2: "+str(calculateCov(trainSet_2_x2))) trainSet_2_x3 = trainSet_2['x3'].to_frame() print("x3的最大似然估计:μ:"+str(calculateAvg(trainSet_2_x3))+" ^2: "+str(calculateCov(trainSet_2_x3))) -
问(2)编写程序,处理二维数据的情形()~(µ, Σ)。对类1和类2中任意两个特征的组合分别求解最大似然估计的均值̂和方差 Σ \Sigma Σ(每个类有3种可能)。
# 创建数据帧 trainSet_1 = pd.read_csv('w1.csv') trainSet_2 = pd.read_csv('w2.csv') # (2)处理二维数据的情形()~(µ, Σ)。对类 1 和类 2 中任意两个特征的组合分别求解最大似然估计的均值̂和方差(每个类有3种可能)。 print("(2): ") print("类1:") trainSet_1_x1x2 = trainSet_1[['x1','x2']] print("(x1,x2)的最大似然估计:") print("μ:"+str(calculateAvg(trainSet_1_x1x2))) print("^2: ") print(calculateCov(trainSet_1_x1x2)) trainSet_1_x1x3 = trainSet_1[['x1','x3']] print("(x1,x3)的最大似然估计:") print("μ:"+str(calculateAvg(trainSet_1_x1x3))) print("^2:") print(calculateCov(trainSet_1_x1x3)) trainSet_1_x2x3 = trainSet_1[['x2','x3']] print("(x2,x3)的最大似然估计:") print("μ:"+str(calculateAvg(trainSet_1_x2x3))) print("^2: ") print(calculateCov(trainSet_1_x2x3)) print("------------------------------------------------------------------------------") print("类2:") trainSet_2_x1x2 = trainSet_2[['x1','x2']] print("(x1,x2)的最大似然估计:") print("μ:"+str(calculateAvg(trainSet_2_x1x2))) print("^2: ") print(calculateCov(trainSet_2_x1x2)) trainSet_2_x1x3 = trainSet_2[['x1','x3']] print("(x1,x3)的最大似然估计:") print("μ:"+str(calculateAvg(trainSet_2_x1x3))) print("^2: ") print(calculateCov(trainSet_2_x1x3)) trainSet_2_x2x3 = trainSet_2[['x2','x3']] print("(x2,x3)的最大似然估计:") print("μ:"+str(calculateAvg(trainSet_2_x2x3))) print("^2: ") print(calculateCov(trainSet_2_x2x3)) -
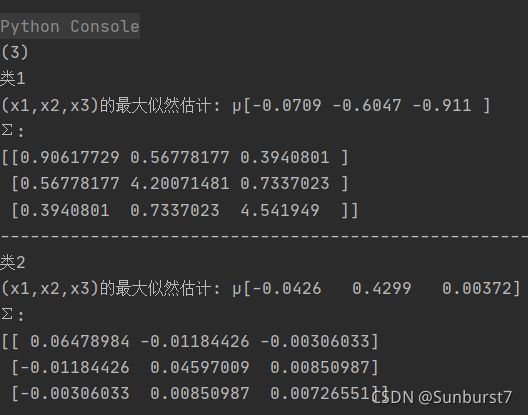
(3)编写程序,处理三维数据的情形()~(µ, Σ)。对类1和类2中三个特征求解最大似然估计的均值̂和 方差。
# 创建数据帧 trainSet_1 = pd.read_csv('w1.csv') trainSet_2 = pd.read_csv('w2.csv') # (3)编写程序,处理三维数据的情形()~(µ, Σ)。对类 1 和类 2 中三个特征求解最大似然估计的均值̂和方差 print("(3)") print("类1") print("(x1,x2,x3)的最大似然估计: µ"+str(calculateAvg(trainSet_1))) print("Σ:") print(calculateCov(trainSet_1)) print("------------------------------------------------------------------------------") print("类2") print("(x1,x2,x3)的最大似然估计: µ"+str(calculateAvg(trainSet_2))) print("Σ:") print(calculateCov(trainSet_2)) -
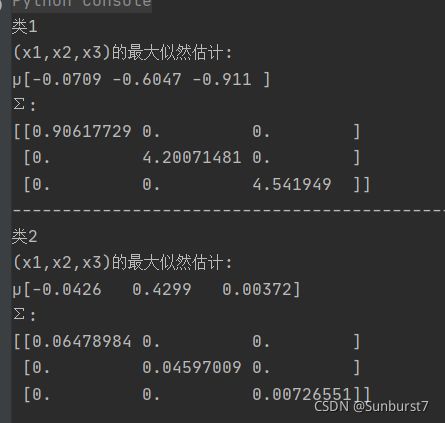
(4)假设该三维高斯模型是可分离的,即 Σ = d i a g ( σ 1 , σ 2 , σ 3 ) \Sigma=diag(\sigma^1,\sigma^2,\sigma^3) Σ=diag(σ1,σ2,σ3),编写程序估计类1和类2中的均值和协方差矩阵中的参数。
# 创建数据帧 trainSet_1 = pd.read_csv('w1.csv') trainSet_2 = pd.read_csv('w2.csv') # 取出每一个特征 trainSet_1_x1 = trainSet_1['x1'].to_frame() trainSet_1_x2 = trainSet_1['x2'].to_frame() trainSet_1_x3 = trainSet_1['x3'].to_frame() trainSet_2_x1 = trainSet_2['x1'].to_frame() trainSet_2_x2 = trainSet_2['x2'].to_frame() trainSet_2_x3 = trainSet_2['x3'].to_frame() # (4) # 因为该模型是可分离的,所以各个特征之间相互独立,每个训练样本向量(x1,x2,x3)的Cov(xi,xj)=0 所以协方差是一个对角矩阵,对角线即为一维数据的方差。 print("类1") print("(x1,x2,x3)的最大似然估计:") print("µ"+str(calculateAvg(trainSet_1))) Cov_1 = np.zeros((3,3)) Cov_1[0, 0] = calculateCov(trainSet_1_x1) Cov_1[1, 1] = calculateCov(trainSet_1_x2) Cov_1[2, 2] = calculateCov(trainSet_1_x3) print("Σ:") print(Cov_1) print("----------------------------------------------------------") print("类2") print("(x1,x2,x3)的最大似然估计:") print("µ"+str(calculateAvg(trainSet_2))) Cov_2 = np.zeros((3,3)) Cov_2[0, 0] = calculateCov(trainSet_2_x1) Cov_2[1, 1] = calculateCov(trainSet_2_x2) Cov_2[2, 2] = calculateCov(trainSet_2_x3) print("Σ:") print(Cov_2) -
(5)(6)比较前 4 种方法计算出来的每一个特征的均值 μ \mu μ与方差 Σ \Sigma Σ的异同,并加以解释。
均值的计算与向量维度无关,都是每一维数据求和再除以n。
因为该模型是可分离的,所以各个特征之间相互独立,每个训练样本向量(x1,x2,x3)的Cov(xi,xj)=0 所以协方差是一个对角矩阵,除对角线外其他处的值为0,对角线即为一维数据的方差。
1.4 实验结果
-
问题1
-
问题2
(2): 类1: (x1,x2)的最大似然估计: μ:[-0.0709 -0.6047] ^2: [[0.90617729 0.56778177] [0.56778177 4.20071481]] (x1,x3)的最大似然估计: μ:[-0.0709 -0.911 ] ^2: [[0.90617729 0.3940801 ] [0.3940801 4.541949 ]] (x2,x3)的最大似然估计: μ:[-0.6047 -0.911 ] ^2: [[4.20071481 0.7337023 ] [0.7337023 4.541949 ]] ------------------------------------------------------------------------------ 类2: (x1,x2)的最大似然估计: μ:[-0.0426 0.4299] ^2: [[ 0.06478984 -0.01184426] [-0.01184426 0.04597009]] (x1,x3)的最大似然估计: μ:[-0.0426 0.00372] ^2: [[ 0.06478984 -0.00306033] [-0.00306033 0.00726551]] (x2,x3)的最大似然估计: μ:[0.4299 0.00372] ^2: [[0.04597009 0.00850987] [0.00850987 0.00726551]] -
问题3
-
问题4
2 Parzen窗
2.1 实验要求
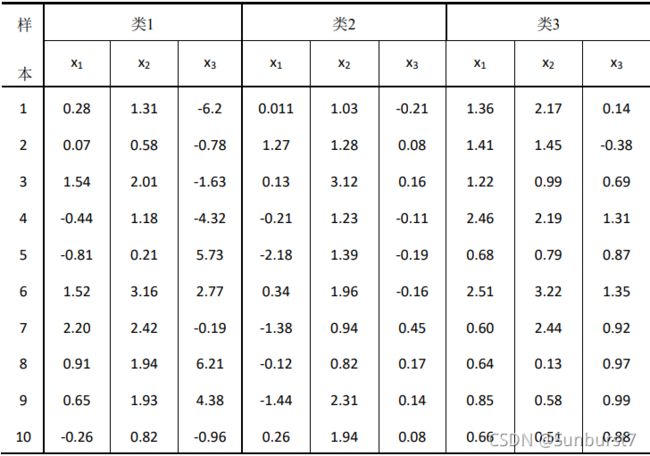
Parzen 窗估计: 使用上面表格中的数据进行 Parzen 窗估计和设计分类器。窗函数为一个球形的高斯函数如下所示:
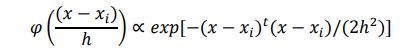
编写程序,使用 Parzen 窗估计方法对任意一个的测试样本点进行分类。对分类器的训练则使用表格中的三维数据。令h = 1,分类样本点为 ( 0.5 , 1.0 , 0.0 ) t , ( 0.31 , 1.51 , − 0.50 ) t , ( − 0.3 , 0.44 , − 0.1 ) t (0.5,1.0,0.0)^t,(0.31,1.51,-0.50)^t,(-0.3,0.44,-0.1)^t (0.5,1.0,0.0)t,(0.31,1.51,−0.50)t,(−0.3,0.44,−0.1)t 。
2.2 实验思路
实验给出的训练集数据分类三个类别,记为w1,w2,w3,我们分别对这三类数据计算每个训练集样本的关于样本测试点的窗函数值,在求和取平均,计算出估计的后验概率。
由于先验知识我的得到,这三类的先验概率应相等,所以由最大后验概率决策变为最大似然决策,根据以下公式计算出每个类的估计类条件概率密度,比大小判断即可。

值得注意的是,Parzen窗是将测试样本点放在窗的中心,让训练集中的每个数据去与窗中心比对,也就是 x \textbf{x} x代表测试集数据, x i \textbf{x}_i xi代表训练集数据
2.3 代码实现
- 11行定义了一个窗函数计算函数,输入一个测试样本点、一个训练集样本点以及窗宽,输出窗函数的值。
- 21行定义了一个求和取平均的函数,用于计算每个类的类条件概率密度
- 31行定义了一个分类器,传入测试点,通过已经输入好的训练集对该测试数据进行分类
import pandas as pd
import numpy as np
import math
# 导入训练集数据
trainSet_1 = pd.read_csv('w1.csv')
trainSet_2 = pd.read_csv('w2.csv')
trainSet_3 = pd.read_csv('w3.csv')
# 计算sample测试数据在训练数据trainSample下的窗函数
def window(sample:pd.Series,trainSample:pd.Series,h):
# 将Series转化为列向量
vector_s = np.matrix(sample).T
vector_ts = np.matrix(trainSample).T
# 计算 x-xi
diff = vector_s - vector_ts
# 返回窗函数值
return math.exp(-diff.T*diff/(2*h**2))
# Parzen窗方法估计该类的条件概率密度
def Parzen(sample:pd.Series,trainSet:pd.DataFrame):
# 初始化似然
likelihood = 0.0
for index, row in trainSet.iterrows():
# 对样本的每个点计算窗函数(h=1),累加
likelihood+=window(sample,row,1)
likelihood = likelihood/10
# 返回估计的后验概率
return likelihood
# 该实验的Parzen窗分类器,训练集中每个类的先验概率相等,因此后验概率就等于类条件概率密度
def ParzenClassifier(sample:pd.Series):
posterior_1 = Parzen(sample, trainSet_1)
posterior_2 = Parzen(sample, trainSet_2)
posterior_3 = Parzen(sample, trainSet_3)
print(sample)
print("p(w1): "+ str(posterior_1))
print("p(w2): " + str(posterior_2))
print("p(w3): " + str(posterior_3))
if posterior_1>posterior_2:
if posterior_1>posterior_3:
print("Sample belong 类1")
else:
print("Sample belong 类3")
else:
if posterior_2>posterior_3:
print("Sample belong 类2")
else:
print("Sample belong 类3")
print("-------------------------------------")
ParzenClassifier(pd.Series([0.5,1.0,0.0]))
ParzenClassifier(pd.Series([0.31,1.51,-0.50]))
ParzenClassifier(pd.Series([-0.3,0.44, -0.1]))
2.4 实验结果
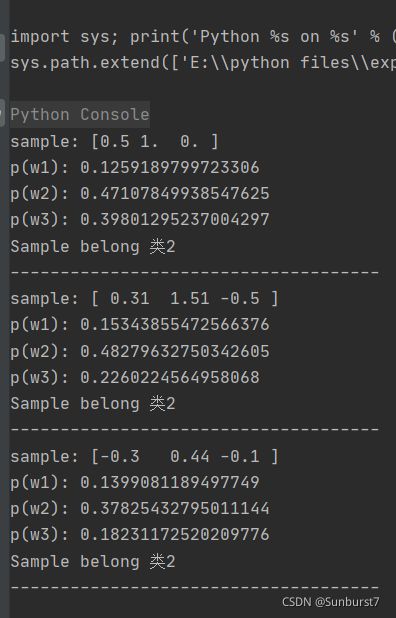
可以看到这三个测试数据都属于类2
3 K近邻
3.1 实验要求
k-近邻概率密度估计: 对上面表格中的数据使用k-近邻方法进行概率密度估计:
- 编写程序,对于一维的情况,当有 n 个数据样本点时,进行k-近邻概率密度估计。 对表格中的类3的特征1,用程序画出当 k=1,3,5 时的概率密度估计结果。
- 编写程序,对于二维的情况,当有 n 个数据样本点时,进行k-近邻概率密度估计。 对表格中的类2的特征(1, 2),用程序画出当 k=1,3,5 时的概率密度估计结果。
- 编写程序,对表格中的3个类别的三维特征,使用k-近邻概率密度估计方法。并且 对下列点处的概率密度进行估计: (-0.41,0.82,0.88),(0.14,0.72, 4.1),(-0.81,0.61, -0.38)
3.2 实验思路
p ( x ) ≈ k R / n V R p(\textbf{x})\approx \frac{k_R/n}{V_R} p(x)≈VRkR/n
实验的核心公式就是(3)式,给定一个测试数据点,以测试数据点为中心,我们分别计算从该点到训练集中样本点的数据的距离作为度量的标准,排序。然后选出距离测试数据点第k近的样本点距离 h k h_k hk,计算出包括k个训练集数据点的超立方体体积 V R V_R VR,带入公式计算。具体的针对不同维度:
- 一维: V R = 2 h k V_R=2h_k VR=2hk,超立方体的体积就是以测试点为中心, 2 h k 2h_k 2hk的线段长度。
- 二维: V R = π h k 2 V_R=\pi h_k^2 VR=πhk2,超立方体体积是以测试点为中心, h k h_k hk为半径的圆
- 三维: V R = 4 3 π h k 3 V_R=\frac{4}{3}\pi h_k^3 VR=34πhk3
指的注意的是,在画图的过程中,可能出现测试点与样本点重合的情况,这时最好在分母加上一个极小项防止/0。
当我们估计出类条件概率密度后,因为由表中数据得到,每个类别的训练数据数量相等先验概率相同,因此对于每个测试数据只需要计算三种情况下的类条件概率密度,再用最大类条件概率密度估计进行决策即可。
3.3 代码实现及结果
3.3.1 一维情况
编写了一个1维KNN方法计算一个测试数据集的概率密度,输入测试数据(一维)、训练集、K值。输出概率密度
# 对于一维的情况,当有 n 个数据样本点时,进行k-近邻概率密度估计,
# 对于类3_x3特征,估计任意一个点关于类3的类条件概率密度
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 定义1维KNN方法计算一个测试数据集的概率密度,输入测试数据、训练集、K值 输出概率密度
def one_dimension_KNN(testData:float,trainSet:pd.Series,k:int):
distance = []
for i in range(trainSet.shape[0]):
# 计算测试数据点 与 训练集中每个样本点的距离
d = np.abs(testData-trainSet[i])
distance.append(d)
# 距离数组进行排序 提取出第k个数据
distance.sort()
posterior = (k/trainSet.shape[0])/(2*distance[k-1])
return posterior
# 导入实验1数据,w3类的x3特征
trainSet1 = pd.read_csv('w3.csv')['x3']
# 随机产生n=500个-2~2的1维随机数
dimension1_randoms = np.random.uniform(-2, 2, 500)
# 进行升序排序
dimension1_randoms = np.sort(dimension1_randoms)
# 声明三个一维数组用于存储K值不同情况下的后验概率
dimension1_posterior_1 = []
dimension1_posterior_3 = []
dimension1_posterior_5 = []
# 对随机数计算后验概率
for i in range(500):
dimension1_posterior_1.append(one_dimension_KNN(dimension1_randoms[i], trainSet1, 1))
dimension1_posterior_3.append(one_dimension_KNN(dimension1_randoms[i], trainSet1, 3))
dimension1_posterior_5.append(one_dimension_KNN(dimension1_randoms[i], trainSet1, 5))
# 画出三张一维的图像
plt.subplot(131)
plt.plot(dimension1_randoms,dimension1_posterior_1)
plt.title('k=1 pdf')
plt.subplot(132)
plt.plot(dimension1_randoms,dimension1_posterior_3)
plt.title('k=3 pdf')
plt.subplot(133)
plt.plot(dimension1_randoms,dimension1_posterior_5)
plt.title('k=5 pdf')
plt.show()
实验结果如图,可以看到在k=1时,在训练集样本点周围有着明显的尖峰,表示图中充满噪音(可能测试样本只是和某个训练样本接近而不是该类,但类条件概率密度却很大)当k增大时曲线变得平滑最后收敛为一个极值,表示类条件概率密度的估计慢慢变得准确。
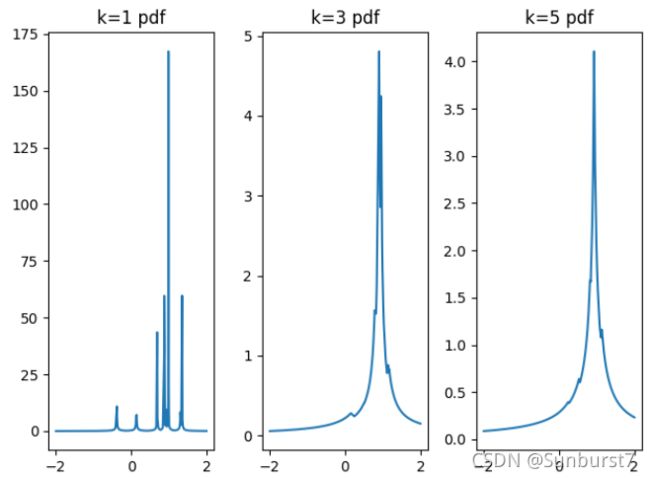
3.3.2 二维情况
定义2维KNN方法
- 输入n个测试数据的x1特征取值矩阵与x2特征取值矩阵、训练数据集、k值。
- 输出后验概率估计数组
生成x1、x2特征的测试数据是在一定范围内每隔0.05采样。
# 对于2维的情况,当有 n 个数据样本点时,进行k-近邻概率密度估计,
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 定义2维knn方法(x1,x2) 输入x1特征取值矩阵与x2特征取值矩阵、训练数据集、k
# x1矩阵代表二维坐标轴的所有点的x1特征值 x2矩阵代表二维坐标轴的所有点的x2特征值
def two_dimension_KNN(x1:np.matrix,x2:np.matrix,trainSet:pd.DataFrame,k:int):
# 声明一个后验概率矩阵存储计算出的后验概率 行(x轴)代表x2的取值,列(y轴)代表x1取值
posteriorMatrix = np.zeros((x1.shape[0],x1.shape[1]))
# 每一个x2特征
for i in range(x1.shape[0]):
# 每一个x1特征
for j in range(x1.shape[1]):
# 存储二维的欧氏距离
distance = []
for index,row in trainSet.iterrows():
# 计算测试数据点 与 训练集中每个样本点的欧式距离
d = np.sqrt((x1[i,j]-row[0])**2+(x2[i,j]-row[1])**2)
distance.append(d)
# 距离数组进行排序 提取出第k个数据
distance.sort()
# 分母加上一个极小的数防止测试点与样本点重合导致分布为0的情况
posterior = (k / trainSet.shape[0]) / (np.pi * (distance[k - 1]**2)+np.spacing(1))
posteriorMatrix[i,j] = posterior
return posteriorMatrix
# 导入实验2数据 w2类的x1,x2特征
trainSet2 = pd.read_csv('w2.csv')[['x1','x2']]
# 生成x1 100个 x2 80个测试数据
test_x1 = np.arange(-3, 2, 0.05)
test_x2 = np.arange(0, 4, 0.05)
# 将x1与x2网格化
matrix_x1,matrix_x2 = np.meshgrid(test_x1, test_x2)
# 计算不同k值情况下网格中每个点的后验概率
posterior1 = two_dimension_KNN(matrix_x1,matrix_x2,trainSet2,1)
posterior3 = two_dimension_KNN(matrix_x1,matrix_x2,trainSet2,3)
posterior5 = two_dimension_KNN(matrix_x1,matrix_x2,trainSet2,5)
# 画图配置
fig = plt.figure(figsize=(12, 6), facecolor='w')
ax1 = fig.add_subplot(131, projection='3d')
ax1.plot_surface(matrix_x1,matrix_x2,posterior1,
rstride=1, # rstride(row)指定行的跨度
cstride=1, # cstride(column)指定列的跨度
cmap=plt.get_cmap('rainbow')) # 设置颜色映射
ax1.set_xlabel('x2')
ax1.set_ylabel('x1')
ax1.set_zlabel('likelihood')
plt.title('k=1 pdf')
ax2 = fig.add_subplot(132, projection='3d')
ax2.plot_surface(matrix_x1,matrix_x2,posterior3,
rstride=1,
cstride=1,
cmap=plt.get_cmap('rainbow'))
ax1.set_xlabel('x2')
ax1.set_ylabel('x1')
ax1.set_zlabel('likelihood')
plt.title('k=3 pdf')
ax3 = fig.add_subplot(133, projection='3d')
ax3.plot_surface(matrix_x1,matrix_x2,posterior5,
rstride=1,
cstride=1,
cmap=plt.get_cmap('rainbow'))
ax1.set_xlabel('x2')
ax1.set_ylabel('x1')
ax1.set_zlabel('likelihood')
plt.title('k=5 pdf')
plt.show()
实验结果如图所示:同一维的情况,在k=1时,在训练集样本点周围有着明显的尖峰,表示图中充满噪音(可能测试样本只是和某个训练样本接近而不是该类,但类条件概率密度却很大)当k增大时曲线变得平滑最后收敛为一个极值,表示类条件概率密度的估计慢慢变得准确。
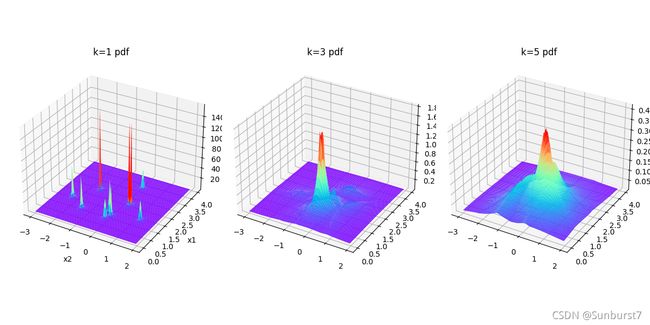
3.3.3 三维情况
该情况与前面的有所不同,实验要求导入三个类别全部特征,判断具体的三个测试数据属于哪个类别,因此对于每个测试数据需要计算三种情况下的类条件概率密度,再用最大类条件概率密度估计进行决策。
import numpy as np
import pandas as pd
# 导入实验3数据 三个类别的全部特征
trainSet3_1 = pd.read_csv('w1.csv')
trainSet3_2 = pd.read_csv('w2.csv')
trainSet3_3 = pd.read_csv('w3.csv')
trainSet = [trainSet3_1, trainSet3_2, trainSet3_3]
# 三维的KNN方法,该方法输入一个三维列向量,k值;输出该向量的类别
def three_dimension_KNN(testData:np.matrix,k:int):
# 声明距离数组用于保存距离
distance = [[],[],[]]
posterior = []
for i in range(3):
# 对每类的数据集计算测试数据点与训练集中每个样本点的距离
for j in range(10):
d = np.sqrt((testData[0,0]-trainSet[i].iloc[j]['x1'])**2 +
(testData[1,0]-trainSet[i].iloc[j]['x2'])**2 +
(testData[2,0]-trainSet[i].iloc[j]['x3'])**2)
distance[i].append(d)
# 距离数组进行排序 提取出第k个数据
distance[i].sort()
V = 4 * np.pi * (distance[i][k - 1] ** 3) / 3
posterior.append(k/10/V)
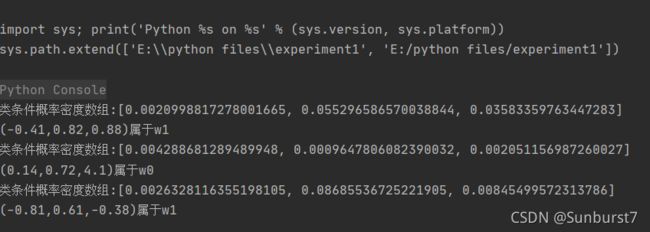
print("类条件概率密度数组:"+str(posterior))
return posterior.index(max(posterior))
# [0.14],[0.72],[4.1] [-0.81],[0.61],[-0.38]]
print("(-0.41,0.82,0.88)属于w"+str(three_dimension_KNN(np.matrix([[-0.41],[0.82],[0.88]]),3)))
print("(0.14,0.72,4.1)属于w"+str(three_dimension_KNN(np.matrix([[0.14],[0.72],[4.1]]),3)))
print("(-0.81,0.61,-0.38)属于w"+str(three_dimension_KNN(np.matrix([[-0.81],[0.61],[-0.38]]),3)))
分类的结果如图:
4 KNN实战
现有一数据集存放在 e2.txt 中,共有 1000 条数据。e2.txt 中数据格式如下图所示:

三个特征: 1.每年的出行里程 2.玩游戏所占用的时间百分比 3.每三天喝的牛奶总升数。三个标签: 1.不喜欢 2.一般 3.喜欢
用学过的 KNN 方法 来构建一个分类器,判断一个样本所属的类别
4.1 实验要求
-
数据预处理
- 将 e2.txt 中的数据处理成可以输入给模型的格式
- 是否还需要对特征值进行归一化处理?目的是什么?
-
数据可视化分析:将预处理好的数据以散点图的形式进行可视化,通过直观感觉总结规律,感受KNN模型思想与人类经验的相似之处。
-
构建 KNN 模型并测试
-
输出测试集各样本的预测标签和真实标签,并计算模型准确率。
-
选择哪种距离更好?欧氏还是马氏?
-
改变数据集的划分以及 k 的值,观察模型准确率随之的变化情况。 注意:选择训练集与测试集的随机性
-
-
使用模型构建可用系统 利用构建好的 KNN 模型实现系统,输入为新的数据的三个特征,输出为预测的类别。
4.2 实验思路
KNN模型的核心方法还是之前构造的三维KNN方法,简单的修改了一点输出:我们这里拿欧式距离度量
# 三维的KNN方法,该方法输入一个三维列向量,k值;输出该向量的类别
def three_dimension_KNN(testData:np.matrix,k:int):
# 声明距离数组用于保存距离
distance = [[],[],[]]
posterior = []
# 对三种预测标签分别计算后验概率
for i in range(3):
# 对每类的数据集计算测试数据点与训练集中每个样本点的距离
for j in range(trainSet[i].shape[0]):
# 计算欧氏距离
d = np.sqrt((testData[0,0]-trainSet[i].iloc[j]['mileage'])**2 +
(testData[1,0]-trainSet[i].iloc[j]['game'])**2 +
(testData[2,0]-trainSet[i].iloc[j]['milk'])**2)
distance[i].append(d)
# 距离数组进行排序 提取出第k个数据
distance[i].sort()
V = 4 * np.pi * (distance[i][k - 1] ** 3) / 3
posterior.append(k/10/V)
print("概率密度数组:"+str(posterior))
if posterior.index(max(posterior)) == 0:
return 'largeDoses'
elif posterior.index(max(posterior)) == 1:
return 'smallDoses'
else:
return 'didntLike'
先导入实验数据:
data = pd.DataFrame(columns=['mileage','game','milk','isLike'])
# 读取文件
with open('e2.txt','r') as f:
# 按行读取
content = f.readlines()
for line in content:
# 按照'\t'分割
newLine = pd.Series(line.split('\t'),index=['mileage','game','milk','isLike'])
# 去除预测标签末尾的'\n'
newLine['isLike'] = newLine['isLike'].strip('\n')
data = data.append(newLine,ignore_index=True)
由于每个特征的度量值不同,有的特征取值很大,有的特征取值很小,如果直接进行计算欧式具体不合理,我们需要进行归一化的处理:使用最小归一化的方法,将所有的特征值映射到[0,1]区间上。计算公式如下:
x ′ = x − m i n m a x − m i n x'=\frac{x-min}{max-min} x′=max−minx−min
实际过程我们使用一个库:
# 归一化
features = data.iloc[:,0:3]
features = MinMaxScaler().fit_transform(features)
data.iloc[:,0:3] = features # 覆盖原来数据
然后是对训练集与测试集的划分,因为有选择训练集与测试集的随机性,我们采用留出法:直接将原数据集划分为两个互斥的数据集,即训练集与测试集。具体的就是每隔10行选取一行作为测试集,余下的数据作为训练集,同时按照预测标签进行分组。
# 每隔10行选取一行作为测试集,余下的数据作为训练集,按照预测标签进行分组
testSet = data.iloc[::10,:]
for index,row in testSet.iterrows():
data.drop(index=index,inplace=True)
group = data.groupby('isLike')
trainSet = [group.get_group('largeDoses'),group.get_group('smallDoses'),group.get_group('didntLike')]
最后进行预测,画图即可。
4.3 实验结果与思考
完整代码如下:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 三维的KNN方法,该方法输入一个三维列向量,k值;输出该向量的类别
def three_dimension_KNN(testData:np.matrix,k:int):
# 声明距离数组用于保存距离
distance = [[],[],[]]
posterior = []
# 对三种预测标签分别计算后验概率
for i in range(3):
# 对每类的数据集计算测试数据点与训练集中每个样本点的距离
for j in range(trainSet[i].shape[0]):
# 计算欧氏距离
d = np.sqrt((testData[0,0]-trainSet[i].iloc[j]['mileage'])**2 +
(testData[1,0]-trainSet[i].iloc[j]['game'])**2 +
(testData[2,0]-trainSet[i].iloc[j]['milk'])**2)
distance[i].append(d)
# 距离数组进行排序 提取出第k个数据
distance[i].sort()
V = 4 * np.pi * (distance[i][k - 1] ** 3) / 3
posterior.append(k/10/V)
print("概率密度数组:"+str(posterior))
if posterior.index(max(posterior)) == 0:
return 'largeDoses'
elif posterior.index(max(posterior)) == 1:
return 'smallDoses'
else:
return 'didntLike'
data = pd.DataFrame(columns=['mileage','game','milk','isLike'])
# 读取文件
with open('e2.txt','r') as f:
# 按行读取
content = f.readlines()
for line in content:
# 按照'\t'分割
newLine = pd.Series(line.split('\t'),index=['mileage','game','milk','isLike'])
# 去除预测标签末尾的'\n'
newLine['isLike'] = newLine['isLike'].strip('\n')
data = data.append(newLine,ignore_index=True)
# 归一化
features = data.iloc[:,0:3]
features = MinMaxScaler().fit_transform(features)
data.iloc[:,0:3] = features # 覆盖原来数据
# 每隔10行选取一行作为测试集,余下的数据作为训练集,按照预测标签进行分组
testSet = data.iloc[::10,:]
for index,row in testSet.iterrows():
data.drop(index=index,inplace=True)
group = data.groupby('isLike')
trainSet = [group.get_group('largeDoses'),group.get_group('smallDoses'),group.get_group('didntLike')]
# 进行预测
T = 0 # 预测正确的个数
F = 0 # 预测错误的个数
forecast = []
for index,row in testSet.iterrows():
columnVector = np.matrix([
[row[0]],
[row[1]],
[row[2]]
])
forecast.append(three_dimension_KNN(columnVector,3))
if forecast[int(index/10)] == row[3]:
T+=1
else:
F+=1
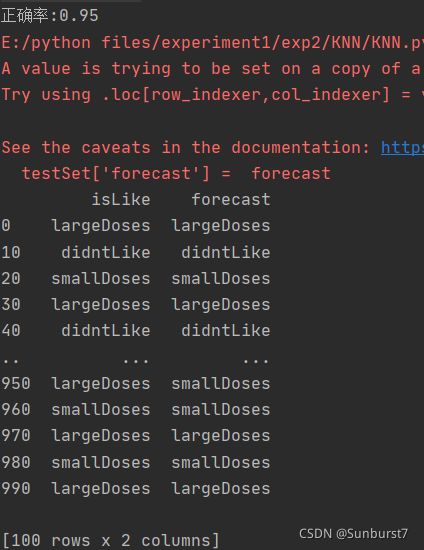
print("正确率:"+str(T/(T+F)))
# 给测试集添加预测标签列
testSet['forecast'] = forecast
# 画图
fig = plt.figure(figsize=(12, 6), facecolor='w')
ax1 = plt.axes(projection='3d')
ax1.legend(loc='best') # 添加图例
ax1.scatter3D(trainSet[0]['mileage'],trainSet[0]['game'],trainSet[0]['milk'],c='r',label='largeDoses')
ax1.scatter3D(trainSet[1]['mileage'],trainSet[1]['game'],trainSet[1]['milk'],c='y',label='smallDoses')
ax1.scatter3D(trainSet[2]['mileage'],trainSet[2]['game'],trainSet[2]['milk'],c='b',label='didntLike')
for index,row in testSet.iterrows():
if row[3] == row[4]:
ax1.scatter3D(row[0], row[1], row[2], c='g')
else:
ax1.scatter3D(row[0], row[1], row[2], c='k')
ax1.set_xlabel('mileage')
ax1.set_ylabel('game')
ax1.set_zlabel('milk')
plt.legend(loc='best')
plt.show()
-
当k=3时
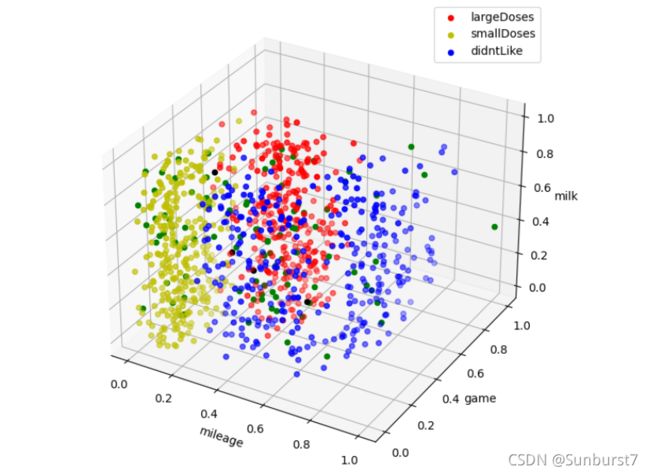
图中绿色的点是预测正确的点,黑色的点是预测错误的点,其他颜色的点是训练集,可以看到在三种类别交汇的地方(决策边界处)有误判的出现。而在每种类别密集的地方基本没有误判的情况。