MATLAB:模式分类chapter3上机练习1
考虑不同维数下的高斯概率密度模型。
(a)编写程序,对表格中的类中的3个特征然后分别求解最大似然估计。
(b)修改程序,处理二维数据的情形。然后处理对表格中的类中的任意两个特征的组合(共三种可能)。
(c)修改程序,处理三维数据的情形然后处理对表格中的类中3个特征的组合。
(d)假设这个三维高斯模型是可分离的,即,写一个程序估计类别中的均值和协方差矩阵中的3个参数。
(e)比较前4种方式计算出来的每一个特征的均值的异同。并加以解释。
(f)比较前4中方式计算出来的每一个特征的方差的异同。并加以解释。
分析高斯密度概型,在本题中,提供三个类分别3个特征10组样本数据。该情况属于高斯情况:![]() 。参数向量就由这两个成分组成。
。参数向量就由这两个成分组成。
(1)首先考虑单变量的情况,其中参数向量的组成成分是:![]()
通过对概率密度函数进行推论整理可以得出:

(2)当高斯函数为多元时,最大似然估计的过程类似。对于高斯分布的均值的最大似然估计结果为: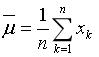

然而对上述分析中,方差的最大似然估计是有偏的估计。
而对协方差矩阵的无偏估计则如下式: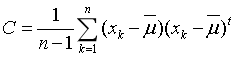
1,根据以上分析编写MATLAB程序:
首先在sample.m中录入数据保存为sample.mat文件,并在其中录入patterns和targets两个矩阵。
为了对表格中的类1(table=patterns(:,targets==1))的3个特征分别求解最大似然估计的两个参数。
该题中,对单个变量进行处理,则将列向量维数置为1;
循环计算u{i}=sum(table(i,:))/n;
sigma{i}=(sum((table(i,:)-u{i}).*(table(i,:)-u{i})))/n;
并输出到[u{i},sigma{i}]中
经过计算得到如下图所示结果:

2、对于类1中任意两个特征的组合(共3种可能)分别是 特征[x1,x2],[x2.x3],[x1,x3]
因此编写一个函数YPmean输入为一个列向量为d维的矩阵X,输出两个变量[u,sigma]
u为d维列向量的均值,sigma为d维的有偏估计的协方差矩阵。
将3种可行的方案用ways矩阵表示:ways=[1 2;2 3;1 3];
循环处理所有的组合方式得到如下结果:

由此可以看出,多元变量的均值列向量的每个值等于各单变量的均值,多元变量的协方差矩阵的正对角线上的值等于各单变量的方差。
3、当数据变为三维的时候,对类1 的三个特征同样代入YPmean函数进行计算输出均值向量为u,协方差矩阵为sigma。通过自定义的matrixOutput函数输出这两个矩阵得到的结果为;

由计算结果可以看出,多元变量的均值向量为单变量的均值按列向量组合,协方差矩阵的正对角线上的值为各单变量的方差。
通过分析中的公式,编写meanFun函数,输入为一个列向量为d维的矩阵,输出为两个变量[u,sigma]
u为d维列向量的均值,sigma为d维的无偏估计的协方差矩阵。
在(c)题中c.m脚本程序用matrixOutput函数输出该计算结果发现,
协方差矩阵与无偏估计的协方差矩阵之间数据不一致,因此对于类1 的三个特征之间的协方差矩阵以及单变量的方差的最大似然估计是有偏的估计。
4、假设这个三维高斯模型是可分离的,,写一个程序估计类型w2中的均值和协方差矩阵的3个参数。
在样本数据集sample中将类型2 的数据提取出来:table=patterns(:,targets==2);
同样代入YPmean函数进行计算:输入矩阵X=table(:,:);
则输出结果为:
通过求平均值计算类型2的均值与方差的结果如下:
由此可以推断,该估计同样是有偏估计,但是3个单变量的方差与该三维模型的协方差矩阵对角线数值相同。可以得出三个参数分别为0.053926,0.045970,0.007266。
源码地址:https://github.com/SiYuenYip/ML_lab2