PointAugmenting: Cross-Modal Augmentation for 3D Object Detection 中文翻译
**
PointAugmenting: Cross-Modal Augmentation for 3D Object Detection
**
Chunwei Wang, Chao Ma*, Ming Zhu, and Xiaokang Yang
MoE Key Lab of Artificial Intelligence, AI Institute, Shanghai Jiao Tong University
{weiwei0224, chaoma, droplet-to-ocean, xkyang} @sjtu.edu.cn
摘要
摄像头和激光雷达是两种互补的传感器摄像头和激光雷达是两种互补的传感器,用于自动驾驶领域中的三维物体检测。摄像头提供丰富的纹理和颜色线索,而激光雷达则专注于相对距离感应。LiDAR专门从事相对距离感应。三维物体检测的挑战在于难以有效地将二维相机图像和三维激光雷达点融合在一起。在本文中,我们提出了一种名为PointAugmenting的新的跨模式的三维物体检测算法。一方面,PointAugmenting使用由预训练的二维检测模型提取的相应的像素级卷积神经网络特征来装饰点云,然后在经过编码的点云上进行三维物体检测。与高度抽象的语义分割分数相比,来自2D目标检测检测网络的卷积神经网络特征能够自适应物体的出现位置的变化,检测性能实现了显著的提升。另一方面,PointAugmenting得益于一种新型的跨模式数据增强算法,该算法持续地在网络训练过程中将虚拟物体粘贴到图像和点云中。大规模的在nuScenes和Waymo上进行的广泛的实验,证明了我们的PointAugmentation的有效性和效率。值得注意的是PointAugmenting优于仅有LiDAR的基线检测器+6.5%mAP,并在nuScenes排行榜上达到了新的最先进水平。
1.介绍
三维物体检测在自动驾驶的三维场景理解中起着至关重要的作用。现有的三维物体检测算法主要是利用激光雷达和摄像头来感知环境。LiDAR以稀疏点云的形式掌握深度信息,而相机捕捉的图像则是具有丰富色彩和纹理的密集强度阵列形式。三维物体检测的挑战在于图像和点云之间的非对齐形式。在这项工作中。我们的目标是通过有效的跨模态数据融合,推进三维物体检测。
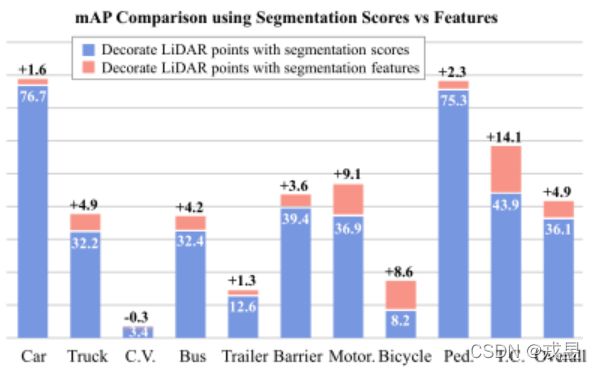
图一. 使用分割分数和CNN特征与LiDAR点融合的3D物体的性能比较。我们将PointPaint-ing[19]中的分割分数替换为从同一分割网络中提取的CNN特征[20]。我们使用仅有LiDAR的检测器CenterPoint[27]作为基线。在1/8的nuScenes数据集上改善了+4.9%mAP。1/8的nuScenes数据集的改进表明,来自图像的CNN特征在与点云融合方面更胜一筹。缩略语是指CON-V。缩略语代表交通车辆(C.V.)、摩托车(Motor.)、行人(Ped.)和交通锥体(T.C.)。
以前的论文已经探索了各种跨模型的传感器融合方案,这些方案可分为三类:决策级融合、建议级融合和像素级融合。决策级融合方法[13,21]采用现成的二维物体检测器,因此它们的性能受限于二维检测器的上限值。建议级融合方法,如MV3D[3]和AVOD[8],在区域建议层面进行融合,导致沉重的计算负荷。最近的方法[11,10,29,16,7,19]试图通过将点云投射到图像平面上来获取点状的图像特征。[11,10,29]在提取图像特征之前,构建了鸟瞰图(BEV)摄像机特征,然后与激光雷达鸟瞰图特征相融合,来解决视角不一致的问题。然而,跨视角的转换很容易导致特征模糊。相反,MVX-Net[16]、EPNet[7]和PointPainting[19]直接利用点与点之间的对应关系,用CNN特征来增强每个LiDAR点的CNN特征或图像分割分数。我们注意到PointPainting之前的融合策略具有有限的普遍性与性能,如同PointPainting总结的那样:“尽管近期有很多有关融合策略的研究,但在KITTI排行榜上排名靠前的顶级方法只是激光雷达"。

表1. GT-Paste数据增强方案的有效性。对LiDAR点应用GT-Paste数据增强,实现了+4.8%mAP的改善。
我们使用CenterPoint作为基线,在nuScenes数据集上使用1/8的训练数据。
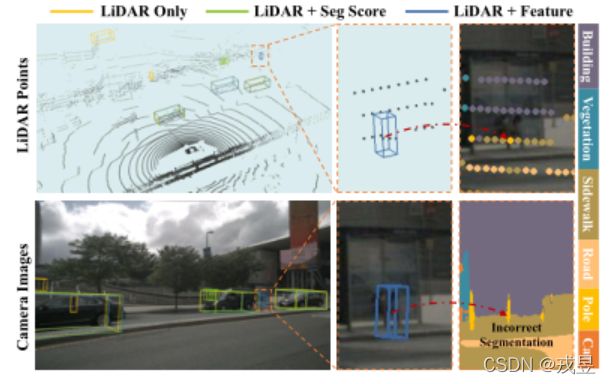
图2. 不同检测器的比较。场景中远处的行人被仅有LiDAR的基线检测器因为只有稀疏的点云所遗漏。PointPainting也失败了,因为对小物体的分割失败。
受益于图像特征提供的丰富语义,我们的方法成功地
成功地检测到了行人。
在分割分数的帮助下,PointPainting已经成为一种流行的融合基线。在大规模数据集上比单纯的LiDAR检测器有很大提升。
尽管有令人印象深刻的改进,但分割分数在覆盖图像中的颜色和纹理方面不是最优的。在直觉上,图像的高维CNN特征含有更丰富的外观线索和更大的感受野。因此,在与点云的融合方面,CNN的高维图像特征比分割分数更具有互补性。为了验证这一直觉,我们在点云的基础上进行了初步实验。具体来说,我们用由CNN提取的特征取代了分割分数。用同样的分割网络提取的CNN特征来代替分割分数[20]。图1显示,CNN特征帮助PointPainting在1/8 nuScenes [2]上取得了+4.9%mAP的显著收益。
这表明了CNN特征与点云融合在三维检测器中的有效性。
考虑到大多数三维检测任务缺乏地面真实分割标签,在大多数三维检测任务中,我们使用预先训练好的二维物体检测网络而不是图像分割网络作为特征提取器。我们的方法与之前的3D检测器MVX-Net[16]不同,后者利用VGG-16的Conv5层上的高层次语义信息。高层次语义信息经常导致邻近的点云图像特征模糊。因此,我们从CenterNet[33,32]的DLA34层中提取输出激活值作为图像特征。把重点放在图像的细微的细节上,以加强与点云信息的区分。
此外,考虑到LiDAR和相机之间的模态差距,我们采用了一个跨模态的后期融合机制。通过我们的融合方案,我们实现了显著的改进,分别比纯激光雷达和PointPainting方法在1/8的nuScenes数据集上,取得了+10.1%和+5.2%的显著改善。图2显示了我们方法的优越性。
在训练三维检测器时,瓶颈之一在于在于跨模型的数据增强。现有的仅有LiDAR的检测器广泛使用GT-Paste[22],这是一种数据增强方案。GT-Paste将以地面实况框和LiDAR的形式将其他场景的虚拟物体粘贴到训练场景中。表1
显示,GT-Paste将纯LiDAR的检测器提高了
+4.8%mAP。然而,直接将GT-Paste应用于跨
模式的检测器会破坏LiDAR点和摄像机图像之间的一致性。为了解决这个问题,我们提出了一个简单而有效的跨模态增强方法,使GT-Paste同时适用于点云和图像。具体来说,我们首先根据几何一致的规则,按照观察者的视角来过滤被遮挡的LiDAR点。然后,我们掌握遍历了当前场景中的所有目标,并将其对应的块
以从远到近的顺序粘贴到图像上。在跨模态数据增强的帮助下,我们提出的3D检测器取得了比最先进的方法更有竞争力的结果。
简而言之,我们的贡献被总结为以下几点。
·我们从二维物体检测网络中探索出有效的CNN特征,以作为图像的表示方法,并将其与二维物体检测网络相融合。
·我们提出了一个训练三维物体检测器的简单而有效的跨模式数据增强方法,同时考虑到了相机和激光雷达之间的模态一致性。
·我们在大规模的NuScenes和Waymo数据上广泛验证了跨模态融合和数据增强的有效性。所提出的三维检测器PointAugmenting在nuScenes上取得了迄今为止最先进的新成果。
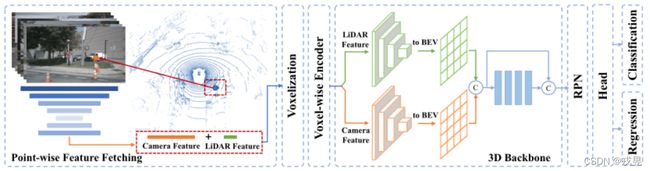
图3. PointAugmenting概述。该架构由两个阶段组成。(1) 逐点获取特征:LiDAR点被投射到图像平面上,然后被获取的逐点CNN特征所叠加。(2) 三维检测:我们将CenterPoint扩展到一个额外的三维稀疏卷积流来获取相机特征,并通过BEV地图中简单的跳过和串联方法来融合不同的模态。
2.相关工作
基于雷达的3D目标检测 现有的基于激光雷达的方法可以大致分为两类:即。基于网格和基于点。基于网格的方法将点状云转换成常规的三维体素[22,34,27,6]或BEV地图[9,24,23]。
在SECOND[22]中,提出了一个稀疏的卷积操作来解析紧密的点云数据。CenterPoint[27]用基于关键点的检测器取代了一般的基于锚点的检测器。对于基于点的方法,PointRCNN[15]和STD[26]应用PointNet[14]来分割前景并为每个点生成建议。3DSSD[25]是一个单阶段的检测器。为了提高计算效率,它将所有的上采样层和细化模块都处理掉了。与基于网格的方法相比,基于点的方法需要很高的计算负荷,从而
导致在大规模数据集上进行耗时的训练,如nuScenes[2]和Waymo[18]数据集。
基于融合的3D目标检测 最近,多传感器融合
已显示出巨大的优势。F-PointNet[13] 在二维检测结果的基础上生成三维边界框。AVOD[8]
和MV3D[3]通过ROI对物体建议进行融合。研究人员[11,10,29]试图将前视摄像机的特征转化为BEV图。ContFuse[11]引入了一个新的连续融合层,而3D-CVF[29]采用了自动校准的投影法来构建平滑的BEV特征图。尽管取得了很好的结果,但存在特征模糊的问题。相反,其他方法[7,16,19] 以点为单位探索融合机制。MVX-Net[16]和PointPainting[19]分别从摄像机图像中获取特征图和分割分数,并在这两个点上应用简单的串联。对这两个点进行简单的连接。EPNet[7]设计了一个LI-Fusion模块,用于建立一个更精细的点与点之间的对应关系。在我们的工作中。我们探索了一种更好的图像表示和融合机制,以促进跨模式的点对点数据融合。
数据增强 点云的数据增强在三维物体检测中至关重要。原始的GT-Paste增强将虚拟物体粘贴到当前训练场景中。这一操作不仅加速了网络收敛而且还缓解了恼人的类不平衡问题。然而,它对跨模态数据没有适应性。对于二维
数据增强,基于块的方法[17,31,28]可以在训练中选择丢弃或粘贴块,有利于一个更稳健的网络学习。Cutmix[31]使用一个从另一幅图像上剪下的补丁来重覆盖一个区域,[1]将其调整为二维检测任务,它适用于二维检测任务。受Cutmix的启发, 我们对跨模式的三维增强的策略是同时将物体点和图像补丁粘贴到场景中,同时保持传感器之间的一致性。
3.PointAugmenting
本节介绍了所提出的用于三维物体检测的PointAugmenting方法。我们采用CenterPoint作为我们的LiDAR基线,并通过一个跨模式的融合机制以及有效的数据增强来扩展它。图3展示了我们的跨模态网络结构。它包括两个阶段。(1)点对点的特征提取。LiDAR点被投射到图像平面上,然后被获取的逐点CN网络附加。
然后用取来的点状CNN特征进行附加。(2)
三维检测。我们将CenterPoint扩展到一个额外的摄像机特征的三维稀疏卷积流并融合
BEV地图中不同模式的特征。为了促进网络训练,我们进一步采用了一种新的数据增强方案。细节在下文中介绍。
3.1跨模型融合
为了提高执行效率,我们在CenterPoint[27]的基础上构建了我们的方法,它是一个单阶段和无锚的LiDAR-only 3D检测器。在Center-Point中的点云首先被送入一个三维编码器,该编码器经过级联后被称为三维编码器,通过体素化、体素特征编码器和三维主干网络,产生
平坦的紧凑的二维BEV特征图。最后,一个二维CNN将这些特征广播给多头,进行多头预测物体中心、三维尺寸和方向。
像素级特征提取 检测器PointPainting[19]的成功启发了我们使用相机图像的语义来装饰LiDAR点。图1中的初步结果表明,高维的
CNN特征比分割分数表现得更好。因此,我们选择图像的CNN特征来进行点的解码。为了提取点状的图像特征,我们使用了一个为二维网络训练的现成网络,用于二维物体检测而不是语义分割。其原因在于三个方面。首先,二维和三维物体检测是互补的任务,它们关注的是物体的不同粒度水平。它们彼此受益。第二,二维检测标签是随时可以从三维投影中获得的,而分割标签则是昂贵的,而且通常无法获得。
分割标签是昂贵的,而且通常无法获得。最后,正如[1]所建议的那样,检测网络比分割网络对数据的扩展更友好。具体来说,我们把CenterNet[33,32]的DLA34[30]的输出激活
作为图像特征,其中特征图的通道数为64,其比例系数为4。为了获取相应的点状图像特征,我们通过同构变换将LiDAR点投射到图像平面上来建立对应关系。然后,LiDAR点被附加到所获取的基于点的图像特征上,作为网络输入来执行。识别的图像特征作为网络输入来进行检测。
3D检测 每个LiDAR点在nuScenes和Waymo数据集上分别的定义是(x, y, z, r, t)和(x, y, z, r),其中x、y、z是位置坐标,r表示反射率,t表示相对时间。我们设定fi为64D图像特征。融合后的LiDAR点可以用(x, y, z, r, (t), fi)表示。考虑到LiDAR和相机之间的模态差距和不同的数据特征,与PointPainting使用的像素级的连接不同,我们采用了一种晚期融合机制。如图3所示,在体素特征编码器之后,我们使用两个独立的三维稀疏卷积分支来处理LiDAR和相机的图像。之后,我们将两个下采样的三维图像卷平铺为二维BEV图,每个通道的编号为256。然后,这两个BEV图被连接起来,再送入四个二维卷积块进行特征聚合。每个卷积块由两个3×3卷积层组成,然后是批量归一化层和一个ReLU激活函数。第一个块将通道数从512缩小到256。最后,我们在聚合的特征与先前的相机和之前的相机和LiDAR BEV特征之间添加一个跳过连接然后再转发到区域建议网络。
3.2跨模型数据增强
我们提出了一个有效的数据扩充方案,以使GT-Paste在训练我们的跨模态时适用。受最近的图像增强方案的启发,我们试图在粘贴LiDAR点到当前3D场景时,同时将图像补丁附加到图像上。主要挑战在于如何保持相机和激光雷达数据之间的一致性。如图4所示,从观察者的角度来看,被粘贴的自行车部分地被原始三维场景中的汽车遮挡住了,导致摄像机图像上出现重叠。如果我们直接将虚拟物体补丁粘贴到图像上,在重叠区域内投影的物体的点可能会获取不匹配的特征。此外, 投射到虚拟补丁中的地面点也会捕捉到不正确的信息。为了解决这个问题,我们确定前景物体之间的遮挡关系并
从观察者的角度过滤那些被遮挡的LiDAR点。
对于相机图像,我们将虚拟物体和原始物体都取出来,并将它们的补丁附在相机上,并通过远到近的轨道将它们的斑块连接起来。
点云增强 我们将LiDAR点(x, y, z)转换为LiDAR球面坐标系(r,θ,φ),用θ和φ的范围来表示物体的视角,其中θ和φ的最小和最大是由其地面实况框的八个角得到的。在选择虚拟对象时,原始的GT-Paste要求避免物体的碰撞。我们的方法还限制了物体之间的透视重叠,以避免过滤掉太多的前景点。然后,被选中的虚拟物体被粘贴到当前的的场景中,我们从观察者的角度过滤被遮挡的点。具体来说,给定当前场景中的原始和粘贴的虚拟物体,我们按照从近到远的顺序处理每个物体。如果一个原始物体被取走了,我们只丢弃那些被遮挡的物体。如果处理的是一个被粘贴的物体,所有比这个物体更远的遮挡点都将被此外。
我们在这个虚拟对象的视角下过滤背景点。
实物的角度过滤背景点。这是因为原始对象只遮蔽了远处的虚拟物体,而粘贴的虚拟物体则包括所有远处的物体和背景点。我们的遮挡感知的点过滤的详细过程在算法1中说明。
摄像机图像增强 为了匹配LiDAR和相机之间的一致性,对于每个粘贴到LiDAR场景中的虚拟物体,我们在一个二维边界框内将其对应的补丁附加到图像上。该二维边界框是由三维地面实景投影获得的。为了确定粘贴的位置,我们注意到,虽然虚拟点是在LiDAR场景中的原始位置上粘贴的,但虚拟块并不是在LiDAR场景中的原始位置上。由于相机外部参数的抖动,
我们需要通过当前的摄像机外部标定重新计算二维边界框的位置,然后通过平移和转换原始块,然后通过平移和缩放对原始补丁进行转换。此外,我们不是直接粘贴虚拟补丁,我们掌握了虚拟对象和原始对象的补丁,并按从远到近的顺序粘贴。通过这种方式,在图像中,背景物体被前景物体遮挡这与LiDAR场景中物
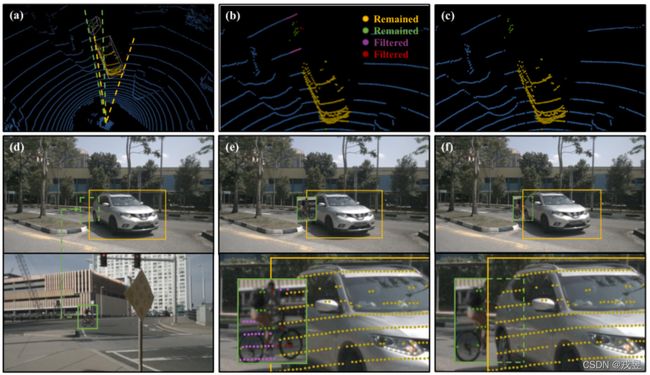
图4. 跨模态数据增强的例子。在(d)中,一辆粘贴的自行车(绿色)被原始场景中的汽车(黄色)部分遮挡住,其LiDAR点显示在(a)中。直接将虚拟补丁(绿色)粘贴到图像上会产生点与摄像机像素之间的不匹配(b和e)。(i) 两个物体的LiDAR点被部分投射到重叠区域,(ii) 一些背景点(紫色)获取了虚拟补丁中的特征。为了避免这种模糊性,我们过滤了被前面物体遮挡的前景点(红色)和被后面物体遮挡的背景点(紫色)。对于图像,我们对虚拟物体和原始物体的图像补丁进行裁剪,然后按照从远到近的顺序将它们粘贴到图像上。这可以观察到LiDAR点(c)和图像(f)之间的一致性。

体之间的遮挡关系一致。
退火策略 尽管有很大的性能提升,但数据
扩增违反了真实的数据分布,尤其是对于我们的数据来说,跨越LiDAR点和相机图像。为此
,我们在模型接近收敛时禁用了数据增强功能
,使我们的模型能够从真实的场景中学习。这一策略进一步产生了以下改进1/8的nuScenes数据集上+1.3%mAP(见表5)。
4.实验
我们在nuScenes和Waymo Open数据集上评估了我们提出的PointAugmenting 3D检测器,并进行了广泛的消融实验,以验证我们的设计选择。
4.1实验设置
通过实验,我们使用adamW[12]优化器与单周期策略[5],最大学习率为1e-3和3e-3用于nuScenes和Waymo,权重衰减为0.01,优化动量范围为0.85至0.95。在训练中,进行沿X轴和Y轴的全局缩放,全局旋转和随机
全局翻译的数据增强。我们还应用我们提出的跨模式数据增强,将虚拟物体粘贴到LiDAR场景和相机图像中。模型的训练是以批量在8V100的GPU上,以16个批次20个轮的规模进行模型训练。在推理中,我们保留每组中的前1000个预测,然后使用非最大抑制(NMS),IoU阈值0.2和得分阈值0.1。继CenterPoint之后,我们采用双重翻转测试。

表2. 对nuScenes测试集的性能比较。我们报告每个类别的NDS、mAP和mAP。

表3. 对Waymo验证集的性能比较。CenterPoint的结果是由我们自己复现的。
4.2 nuScenes 结果
nuScenes数据集[2]是一个用于3D检测的大规模数据集,它包括700个训练场景,150个场景用于验证,以及150个场景用于测试。该数据集使用六台摄像机和一个32光束的Li-DAR来收集。并为360度视野内的10个物体提供了3D注释。我们将检测范围设定在[-54m,54m]的X轴和Y轴,以及[-5m,3m]的Z轴。其体素大小为(0.075m,0.075m,0.2m)。我们使用10次扫描来增强LiDAR,并限制非空体素的最大数量
为90000。我们遵循官方评估协议[2]来报告结果。我们将我们的检测结果提交给nuScenes服务器进行评估。在表2中,我们的PointAugmenting比以前的最先进的方法在
在官方排行榜上表现出色。与与CenterPoint相比,我们的方法获得了显著的收益,即
+6.5%mAP和+3.7%NDS,并且在所有类别中都有持续的改进。我们的方法在所有类别中都有持续的改进。更详细地说,自行车获得增长幅度最大,达到+20.2%mAP。这是因为这是因为自行车通常有很少的LiDAR点和混乱的测距。因此,额外的语义线索可以作为三维检测器的一个有价值的指导。此外,在小类(交通锥)+5.2%mAP和尾类(建筑车辆)+8.0%mAP上都取得了显著的收益。这体现了利用相机来协助LiDAR处理困难数据的有效性。
4.3 Waymo 结果
Waymo开放数据集[18]是目前最大的自动驾驶数据集。共有798个场景用于训练,202个场景用于验证。由5个激光雷达传感器和5个针孔摄像机进行采集并标注了二维和三维标签。在训练期间。我们将X轴和Y轴的探测范围设定为[-76.8m,76.8m], Z轴为[-5m,3m],体素大小为(0.075m,0.075m,0.1m). 非空体素的最大数量被设定为120000。请注意,Waymo的摄像头只能覆盖250度左右的区域,这与Li-DAR点和3D标签不同。Li-DAR点和3D标签在整个360度范围内。因此。近1/3的LiDAR点无法获取其相应的的图像特征,这是因为在后方缺乏摄像头的缘故。因此,我们只选择了LiDAR点和相机视场内的地面实况,来训练我们的跨模式检测器。在推理阶段,为了检索整个场景中的三维检测,我们用CenterPoint的预测来完成左1/3场景的预测。
表3比较了我们与CenterPoint的检测结果。
尽管我们的跨模式检测器使用的训练数据比CenterPoint少,但它在所有物体类别和两个难度级别上的表现仍然非常出色。特别是,我们
在行人和骑自行车的人身上取得了显著的进步,分别为+1.91%和+4.41%的mAP, 这表明我们的方法对少于5个LiDAR点的物体有出色的表现。在mAPH方面,我们也取得了优异的成绩,表明对物体的航向预测更加准确。在Waymo数据集上的结果进一步验证了我们提出的PointAugmenting的有效性和通用性。
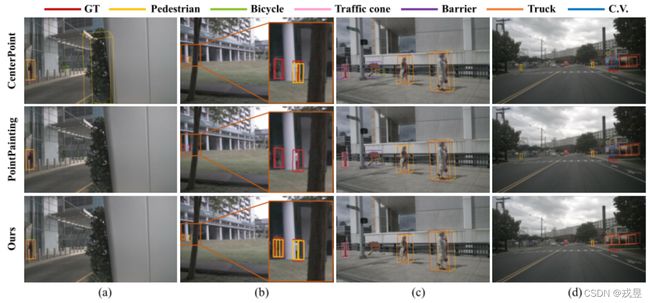
图5. 检测结果的定性比较。我们将我们的方法与CenterPoint[27]和PointPainting[19]进行比较。我们改进了
PointPainting与我们的融合机制进行公平比较。(a)表明了利用摄像机信息的必要性,其中Center-Point
Point由于失去了语义而错误地检测到一棵类似人类的树。在(b)中,PointAugmenting成功地检测到两个远处的行人而其他两个都失败了。在©中,由于混乱的几何形状,CenterPoint和PointPainting错误地将一个标志检测为一个障碍物或一辆自行车。在(d)中,CenterPoint和PointPainting将一辆卡车误认为是建筑车辆,而我们的PointAugmenting则成功了。
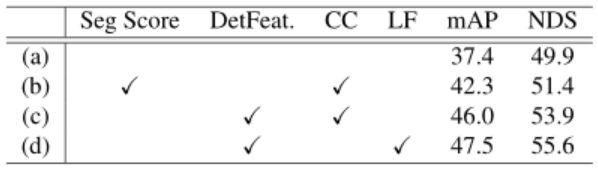
表4. 融合政策的比较。分割得分:装饰LiDAR点的分割分数,正如PointPainting所提出的那样。DetFeat:用图像特征来装饰LiDAR点。CC:通过点对点的连接,融合LiDAR和图像特征。LF:我们的后期融合机制。
4.4 消融实验
我们对nuScenes数据集进行了消融研究,以便
准确地指出改进之处。为了提高效率,我们使用1/8训练数据进行训练,并对整个验证数据集进行测试。我们对模型进行了20个轮次的训练,体素大小为(0.1m,0.1m,0.2m)的整个消融研究。
融合架构 在表4中我们比较了不同的融合政策。这里所有的研究都是在我们的跨模型的数据增强下训练的,但没有采用退火策略。对于图像分割,我们采用HRNet-W48[20]在Cityscapes[4]上进行预训练。我们将观察结果总结如下。
(1)跨模式融合的好处(a,d):我们的融合架构极大地提高了激光雷达的性能+10.1%mAP,这表明

表5. 跨模型数据增强的有效性。Naive:原始的GT-Paste应用于CenterPoint。CM:我们的跨模型的GT-Paste数据增强。Fade:训练策略在最后5个历时中停止我们的数据增强。Fusion:通过我们的后期融合机制增加相机流。
跨模型融合对三维物体检测的重要性。
(2)融合的相机输入(b,c):将PointPainting建议的分割分数替换为我们的分割特征。识别特征产生了+3.7%mAP的改进。尽管分割分数提供了一个紧凑的表示方法弥补LiDAR的不足,但CNN特征更擅长于提供丰富的外观线索和大的感受野。这些结果表明了为相机模式选择有效表示的重要性。
(3) 不同的融合机制(c,d): 后期融合机制与简单的串联法相比,我们通过使用我们的检测特征作为输入,实现了+1.5%的mAP增益。早期的逐点串联忽略了LiDAR之间数据特征的巨大差异。而我们的方法则是通过在BEV上融合特征来缩小模型的差距。

图6. 在我们的数据增强后,二维检测的定性结果。第一行:原始场景的二维检测结果。第二行:经过我们的GT-Paste数据增强后的结果。黄色和绿色方框分别表示原始物体和粘贴物体的检测结果。红框是假错误预测。
尽管晚期融合方案表现最好,但它带来了额外的计算成本,因为单独的3D稀疏卷积流。因此,一个有效的、高效的融合机制在未来是可取的。我们在图5中提出了定性的结果,以对比三种检测器,即CenterPoint、PointPainting和PointAugmenting。我们在nuScenes的全部训练数据上训练三个模型。图5显示了跨模式融合和我们的融合策略的优越性。通过利用丰富的相机信息,我们的PointAugmenting在减少错误预测方面明显优于其他两种方法。
跨模型数据增强 我们验证了我们的跨模态数据增强方案的有效性,见表5。主要观察结果总结如下。
(1) 纯LiDAR输入的GT-Paste(e,f,g): 对LiDAR点应用GT-Paste产生了+4.8%mAP的提升。这促使我们研究跨模式的数据增强。比较(g)和(f),用我们的GT-Paste取代原版的GT-Paste,产生了0.2%的mAP下降,这表明我们对LiDAR点的操作并不影响LiDAR的检测。
(2)跨模式输入的GT-Paste(h,i): 当我们利用相机的特征来帮助LiDAR检测时,移除我们的跨模型的数据增强。我们的跨模式数据增强的GT-Paste导致整体性能下降3.7%m。这一差异表明我们的策略是有效的。此外,我们的
方案也适用于其他跨模型检测器。
(3) 退火策略(i,j):我们在最后5个训练历时中应用退火策略,这进一步实现了+1.3%mAP的提升。虽然我们的数据增强方案对检测器有明显的好处,但它扰乱了真实的数据分布。因此,退火策略有助于从真实场景中学习。
可视化2D检测 为了验证以下因素的影响在二

表6. nuScenes数据集上每帧的运行时间。CC:像素级串联。LF:我们的后期融合机制。运行时间是在NVIDIA 1080Ti GPU上。
维图像主干上的GT-Paste,我们通过将摄像机图像转发到二维图像主干上,使二维检测结果可视化,即CenterNet与DLA34主干网络。图6显示了数据增强后的二维检测结果,其中大部分物体仍然可以被成功检测到。这意味着在我们对图像进行补丁粘贴操作时,点云增强的有效性。然而,在对图像进行增强后,出现了假阴性(红框)。在图6中,被粘贴的公交车由于被遮挡而丢失,而交通锥体则由于与背景颜色相似而被忽略。这种现象是促使我们采用退火的原因之一。
运行时间 我们在表6中报告了每一帧的运行时间。与单纯的激光雷达检测器CenterPoint相比,我们的PointAugmenting需要额外的运行时间,因为2D图像特征主干(383毫秒,图像大小为896×1600)和下面的三维分支(60毫秒)来生成BEV空间的特征。运行时间对自动驾驶来说是非常重要的。我们发现,减少输入图像的大小或用简单的点对点连接取代我们的后期融合,可以在很大程度上加速我们的方法。表6显示,我们的两个精简版在检测精度略有下降的情况下,实现了更快的速度,但检测精度略有下降。
5.总结
在本文中,我们提出了一个新的跨模态的三维物体检测器,名为PointAugmenting。利用跨模态数据融合和数据增强方案,
PointAugmenting在nuScenes检测排行榜上创造了新的最先进的结果。作为跨模态3D检测器的一个强有力的基准,我们的PointAugmenting可以在两个方面进行改进。首先,尽管我们的后期融合机制很有效,但更有效的跨模态融合方案是需要的。此外,考虑到LiDAR和相机的不同视场,一个能适应不同视场的简单模型是必不可少的,无论是LiDAR还是跨模式,在实际应用中都是需要的。
鸣谢:本工作得到了国家自然科学基金委(61906119,U19B2035)、上海市科技重大专项(2021SHZDZX0102)和上海浦江计划的大力支持。
参考文献
[1] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection.arXiv preprint arXiv:2004.10934, 2020.3,4
[2] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multi-modal dataset for autonomous driving. InProceedings of the
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020.2,3,6
[3] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia.Multi-view 3d object detection network for autonomous driving. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1907–1915, 2017.1,3
[4] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 3213–3223, 2016.7
[5] Sylvain Gugger. The 1cycle policy, 2018.5
[6] Chenhang He, Hui Zeng, Jianqiang Huang, Xian-Sheng Hua, and Lei Zhang. Structure aware single-stage 3d object detection from point cloud. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
pages 11873–11882, 2020.3
[7] Tengteng Huang, Zhe Liu, Xiwu Chen, and Xiang Bai. Epnet: Enhancing point features with image semantics for 3d object detection. InProceedings of the European Conference on Computer Vision (ECCV), pages 35–52, 2020.1,
3
[8] Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven L Waslander. Joint 3d proposal generation and object detection from view aggregation. In2018 IEEE/RSJ
International Conference on Intelligent Robots and Systems(IROS), pages 1–8, 2018.1,3
[9] Alex H Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Y ang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. InProceedings of the
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12697–12705, 2019.3,6
[10] Ming Liang, Bin Y ang, Y un Chen, Rui Hu, and Raquel Urtasun. Multi-task multi-sensor fusion for 3d object detection.
InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7345–7353, 2019.1,3
[11] Ming Liang, Bin Y ang, Shenlong Wang, and Raquel Urtasun.Deep continuous fusion for multi-sensor 3d object detection.
InProceedings of the European Conference on Computer Vision (ECCV), pages 641–656, 2018.1,3
[12] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017.5
[13] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgbd data. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 918–
927, 2018.1,3
[14] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages
652–660, 2017.3
[15] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3d object proposal generation and detection from point
cloud. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–779, 2019.3
[16] Vishwanath A Sindagi, Yin Zhou, and Oncel Tuzel. Mvxnet: Multimodal voxelnet for 3d object detection. InInternational Conference on Robotics and Automation (ICRA), pages 7276–7282, 2019.1,2,3
[17] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way
to prevent neural networks from overfitting.The Journal of Machine Learning Research, 15(1):1929–1958, 2014.3
[18] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou,
Y uning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2446–2454, 2020.3,6
[19] Sourabh V ora, Alex H Lang, Bassam Helou, and Oscar Beijbom. Pointpainting: Sequential fusion for 3d object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4604–4612,
2020.1,3,4,6,7
[20] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Y ang Zhao, Dong Liu, Y adong Mu, Mingkui Tan, Xinggang Wang, et al. Deep high-resolution representation learning for visual recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020.1,2,7
[21] Zhixin Wang and Kui Jia. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection.arXiv preprint arXiv:1903.01864, 2019.1
[22] Y an Y an, Y uxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection.Sensors, 18(10):3337, 2018.2,3
[23] Bin Y ang, Ming Liang, and Raquel Urtasun. Hdnet: Exploiting hd maps for 3d object detection. InConference on Robot Learning, pages 146–155, 2018.3
[24] Bin Y ang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3d object detection from point clouds. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), pages 7652–7660, 2018.3
[25] Zetong Y ang, Y anan Sun, Shu Liu, and Jiaya Jia. 3dssd: Point-based 3d single stage object detector. InProceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 11040–11048, 2020.3,6
[26] Zetong Y ang, Y anan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Std: Sparse-to-dense 3d object detector for pointcloud. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1951–1960, 2019.3
[27] Tianwei Yin, Xingyi Zhou, and Philipp Krähenbühl. Centerbased 3d object detection and tracking.arXiv preprint
arXiv:2006.11275, 2020.1,3,6,7
[28] Jaejun Y oo, Namhyuk Ahn, and Kyung-Ah Sohn. Rethinking data augmentation for image super-resolution: A comprehensive analysis and a new strategy. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8375–8384, 2020.3
[29] Jin Hyeok Y oo, Y eocheol Kim, Ji Song Kim, and Jun Won Choi. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection.
arXiv preprint arXiv:2007.08856, 2020.1,3
[30] Fisher Y u, Dequan Wang, Evan Shelhamer, and Trevor Darrell. Deep layer aggregation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition
(CVPR), pages 2403–2412, 2018.4
[31] Sangdoo Y un, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Y oungjoon Y oo. Cutmix: Regularization strategy to train strong classifiers with localizable
features. InProceedings of the IEEE International Conference on Computer Vision (CVPR), pages 6023–6032, 2019.3,4
[32] Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Tracking objects as points.In Proceedings of the European Conference on Computer Vision (ECCV), 2020.2,4
[33] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. InarXiv preprint arXiv:1904.07850, 2019.2,4
[34] Yin Zhou and Oncel Tuzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4490–4499, 2018.3
[35] Benjin Zhu, Zhengkai Jiang, Xiangxin Zhou, Zeming Li, and Gang Y u. Class-balanced grouping and sampling for point cloud 3d object detection.arXiv preprint arXiv:1908.09492,2019.6