超越YOLOv4-Tiny!CSL-YOLO:全新轻量化模型实现移动端实时检测!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童 CSL-YOLO: A New Lightweight Object Detection System for Edge Computing
CSL-YOLO: A New Lightweight Object Detection System for Edge Computing
论文:https://arxiv.org/abs/2107.04829
本文提出了一种新的轻量级卷积方法Cross-Stage Lightweight(CSL)模块,从简单的操作中生成冗余特征。在中间展开阶段用深度卷积代替逐点卷积来生成候选特征。所提出的CSL模块可以显著降低计算量。在MS-COCO上进行的实验表明,所提出的CSL-Module可以达到近似 卷积的拟合能力。
1简介
由于计算资源有限,开发轻量级目标检测器是必要的。为了降低计算成本,如何生成冗余特征起着至关重要的作用。
本文提出了一种新的轻量级卷积方法——Cross-Stage Lightweight(CSL)模块,从简单的操作中生成冗余特征。在中间展开阶段用深度卷积代替逐点卷积来生成候选特征。所提出的CSL模块可以显著降低计算量。在MS-COCO上进行的实验表明,所提出的CSL-Module可以达到近似 卷积的拟合能力。
最后,利用该模块构建了轻量级检测器CSL-YOLO,在仅43% FLOPs和52%参数的情况下,实现了比TinyYOLOv4更好的检测性能。
2本文方法
2.1 CSL-Module
以往的研究表明,使用更少的计算量来生成冗余特征图,可以大大减少FLOPs。CSPNet提出了一种跨阶段求解的方法,GhostNet系统地验证了cheap操作在该问题中的有效性。然而,问题是生成有价值的特征图的主要操作对于边缘计算来说仍然过于复杂。
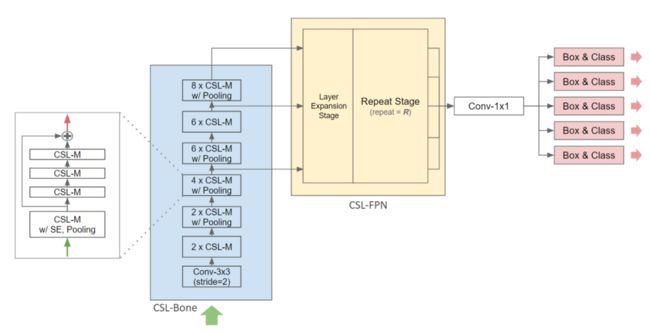
本文建议将输入特征映射划分为2个分支。第1个分支通过像GhostNet那样的cheap操作生成一半冗余的特征图;第2个分支通过轻量级主操作生成另外一半必要的特性映射,然后将2个输出cat在一起。总体架构如下图所示。
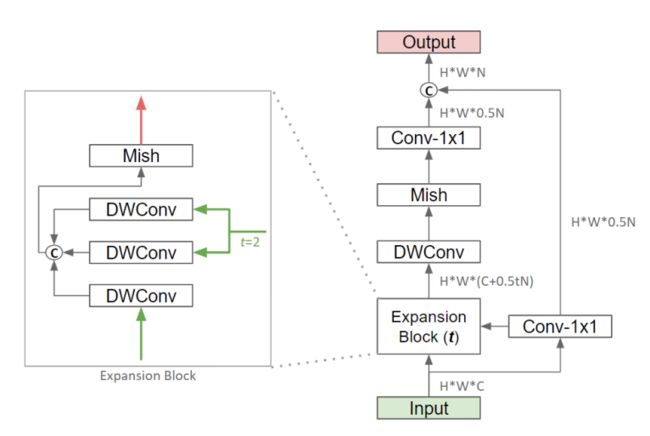
超参数 表示特征扩展的比例。在CSL-Bone中将 设为3,在else中将 设为2。当下采样或扩展块后需要注意力时,插入SE模块或自适应平均池化。此外,作者还使用了Mish作为激活函数,在实验中,Mish在CNN模型中的表现优于ReLU和Swish。
本文所提出的CSL-Module通过跳过分支的操作生成半冗余特征映射。在主分支上,它不同于CSP模块和Ghost模块。作者建议一个轻量级的主操作来生成另外一半必要的特性映射。在这个分支中设计了一个类似IRB的扩展块,利用跳跃分支的输入特征图和输出特征图,通过深度卷积生成中间候选特征图。
这个块的最大优点之一是无需pointwise CNN,大家都知道深度卷积比pointwise CNN的FLOPs要少得多。它不同于IRB。IRB使用逐点卷积来生成候选特征图。这个块的其他优点是它充分考虑了所有当前可用的特性,这可以最小化冗余计算。此外,因为已经有了跳跃分支,主分支只需要生成一半的特性图,显著减少了FLOPs。
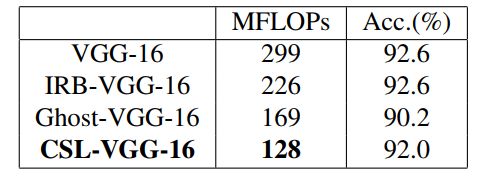
总的来说,所提出的CSL-Module通过cheap操作和跨阶段的思想减少了FLOPs。另一方面,特别对主分支进行了轻量级设计。替换了VGG-16中的卷积层来验证CSL-Module的有效性,分别将新的模型记为IRB-VGG-16、Ghost-VGG-16和CSLVGG-16。
在CIFAR-10上对它们进行了评估,训练设置和trick都是相同的(例如,flip、affine、mixup和steps learning rate)。从下表可以看出,CSL-Module比其他轻量级卷积方法更快。实验证明CSL-Module是一种非常有竞争力的轻量级卷积方法。
2.2 构建轻量化组件
本文提出了2种轻量级组件CSL-Bone和CSL-FPN。这2个组件是目标检测器所必需的。CSL-Bone比其他backbone模型提取输入图像的特征值更少;CSL-FPN能更有效地预测不同尺度上的边界框。
1、Lightweight Backbone
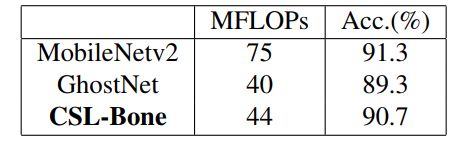
本文所提的CSL-Bone由几个CSL-Module组成。SE模块集成到第1个CSL-Module中,增强了整个组的特征提取能力。此外,还在适当的位置插入池化层进行降采样,以获得高级语义特征。

最后,CSL-Bone输出3种不同比例的特征图。总体架构如上图所示。作者在CIFAR-10上评估了CSL-Bone、MobileNetv2和GhostNet,并应用了相同的训练设置。由表2可以看出。尽管CSL-Bone的准确率低于MobileNetv2,但CSL-Bone的FLOPs仅比MobileNetv2低58.7%。另一方面,CSL-Bone的准确率比GhostNet高,但只略微增加了FLOPs。
2、Lightweight FPN
以往的研究表明,大尺度特征图具有更多的物体细节,如边缘、角落或纹理,而小尺度特征图具有全面的语义理解。Vanilla FPN将小特征图向上采样,然后将它们与大特征图融合。另一方面,Vanilla FPN输出3比例尺特征图。这有助于模型检测不同尺寸的物体。
本文提出的CSL-FPN首先将FPN中的所有 卷积替换为CSL-Module。其次,在扩展阶段,在2个尺度层之间形成一个中尺度层,这些中尺度层可以增强模型对不同尺度目标的检测能力;第3,在重复阶段,同时有(k)th层、(k-1)th层和(k+1)th层进行特征融合,但每次只使用奇层或偶层。
例如,在第1次融合中只有第2层和第4层,而在第2次融合中,有第1层,第3层和第5层。也就是说,所提出的CSL-FPN具有与Vanilla FPN相同的卷积数,但具有更多的特征融合。总体架构如图所示。
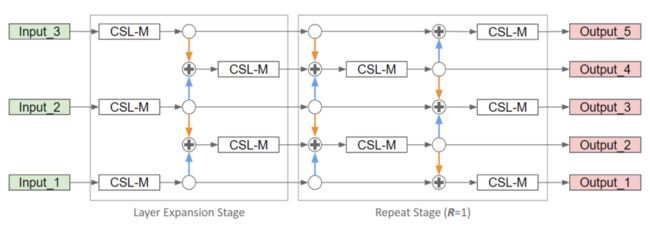
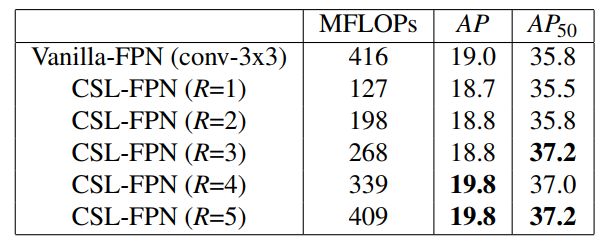
在本文提出的CSL-FPN的实现中,为了使元素的添加更容易,作者在层扩展阶段将5个输出层的通道设置为相同的。重复阶段使用一个超参数R来表示CSL-FPN总共堆叠了几个块。较大的R可以实现更高的AP,但FLOPs也会增加,因此在速度和性能之间存在权衡。作者在基于 CSL-YOLO的MS-COCO上测试了R的最佳值。表3显示了结果。随着R的增大,AP也从18.6%提高到19.8%,AP50从35.5%提高到37.2%,MFLOPs也从127下降到409。经过权衡决定将R设为3。
3Tricks of CSL-YOLO
 CSL-YOLO架构
CSL-YOLO架构
3.1 Anchors约束
YOLO系列使用K-means和IoU距离函数对ground truth的高度和宽度进行聚类,然后将中心点作为anchor box。这些锚点由k个聚类生成,并根据其规模分配到FPN的输出层。当将输出层从3层扩展到5层时,k也从9层增加到15层。

如果使用上述方法,那么由于MS-COCO中有许多小目标,这些anchor大多是小规模的。high-level的输出层将被迫使用小规模的anchor。然而,众所周知,high-level的特征图不利于小目标的检测。因此,作者在K-means前加入上式这样的尺度限制,使得生成的anchor分布更符合各个输出层的尺度。作者在下表中进行了实验,可以看到原来的3个输出层扩展到5个输出层后出现了恶化。在添加了约束方法后,它对AP有了相当大的改进。

3.2 Non-Exponential预测
YOLO级数实际上预测了x, y, w, h的偏移量,如下:

其中 和 为模型预测的目标高度和宽度的偏移量, 和 为anchor的高度和宽度。虽然对数函数可以限制模型的预测范围,但指数函数的敏感性使宽度和高度相当不稳定。因此去掉了log函数,让模型直接预测偏移量。则上式可以修改为:
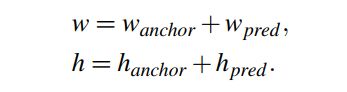
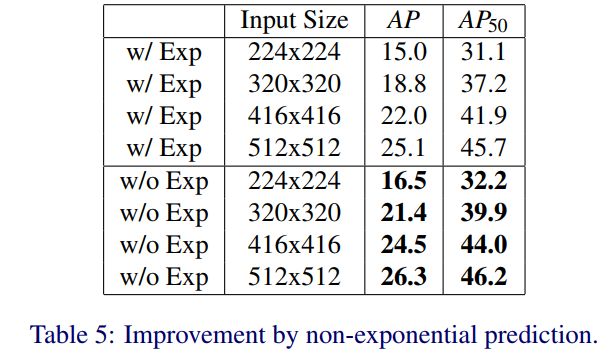
从下表可以明显看出,即使在不同的图像尺寸下,非指数预测也可以提高1~2%的AP。如图1所示,然后集成所有组件构建CSL-YOLO。在推理过程中,采用soft-nms技术对重叠框进行惩罚。
CSL-YOLO在416×416的输入尺度下,所提出的CSL-YOLO使用3.2M参数和1470 MFLOPs获得42.8%的AP50,而Tiny-YOLOv4使用6.1M参数和3450 MFLOPs获得40.2%的AP50。可以说,CSL-YOLO比先进的Tiny-YOLOv4占用更少的时间(FLOPs)和空间(参数),并能实现令人印象深刻的AP性能。此外,在224×224的输入尺度下,与最轻的YOLO-LITE相比,CSL-YOLO仍然在更低的FLOPs下获得更高的AP性能。

CSL-YOLO论文下载
后台回复:CSL,即可下载上述论文PDF
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-目标检测交流群成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看