元学习Meta-Learning
目录
1. 背景
2. 元学习meta-learning
3. 应用
3.1 事件抽取(Zero-shot Transfer Learning for Event Extraction)
1. 背景
Artificial Intelligence --> Machine Learning --> Deep Learning --> Deep Reinforcement Learning --> Deep Meta Learning
在Machine Learning时代,复杂一点的分类问题效果就不好了,Deep Learning深度学习的出现基本上解决了一对一映射的问题,比如说图像分类,一个输入对一个输出,因此出现了AlexNet这样的里程碑式的成果。但如果输出对下一个输入还有影响呢?也就是sequential decision making的问题,单一的深度学习就解决不了了,这个时候Reinforcement Learning增强学习就出来了,Deep Learning + Reinforcement Learning = Deep Reinforcement Learning深度增强学习。有了深度增强学习,序列决策初步取得成效,因此,出现了AlphaGo这样的里程碑式的成果。但是,
- 深度增强学习太依赖于巨量的训练,并且需要精确的Reward,对于现实世界的很多问题,比如机器人学习,没有好的reward,也没办法无限量训练,怎么办?
- 或者把棋盘变大一点AlphaGo还能行吗?目前的方法显然不行,AlphaGo会立马变成傻瓜。而我们人类就厉害多了,分分钟可以适应新的棋盘。
再举个例子人脸识别,我们人往往可以只看一面就能记住并识别,而现在的深度学习却需要成千上万的图片才能做到。
我们人类拥有的快速学习能力是目前人工智能所不具备的,而人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分的利用以往的知识经验来指导新任务的学习。因此,如何让人工智能能够具备快速学习的能力成为现在的前沿研究问题,namely Meta Learning.
problem: deep learning依赖大量优质的标柱训练数据集 and 计算资源;移植能力差poor portability/ˌpɔː.təˈbɪl.ə.ti/ n.;task-specific独立应用于特定任务,but new concept or things come out continuously。
Reference:
[1] 学会学习Learning to Learn:让AI拥有核心价值观从而实现快速学习 - 知乎 ===>作者将人的感性通过weight价值观网络体现出来,很有想法,很有意思的一个点!
[2] 元学习Meta Learning/Learning to learn_langb2014的博客-CSDN博客
2. 元学习meta-learning
solution:快速学习;利用以往的知识经验来知道新任务学习;learning to learn;inference,思考
概念:元学习, meta-learning, known as learning to learn(Schmidhuber, 1987; Bengio et al., 1991; Thrun and Pratt, 1998)), is an alternative paradigm that draws on past experience in order to learn and adapt to new tasks quickly: the model is trained on a number of related tasks such that it can solve unseen tasks using only a small number of training examples.
3. 应用
3.1 事件抽取(Zero-shot Transfer Learning for Event Extraction)
- Problem: Most previous event extraction studies have relied heavily on features derived from annotated event mentions, thus can not be applied to new event types without annotation /tyˌæn.əˈteɪ.ʃən/ n. 标注 effort.
- Solution: We designed a transferable neural architecture, mapping event mentions and types jointly into a shared semantic space using structural and compositional neural networks, where the type of each evnet mention can be determined by the closest of all candidate types.
- Scheme: By leveraging (1) available manual annotation for a small set of existing event types and (2) existing event ontologies /ɒnˈtɒl.ə.dʒi/ n. 本体, our framework applies to new event types without requiring additional annotation.
(1) goal of event extraction: event triggers; event arguments from unstructural data.
--->poor portability /ˌpɔː.təˈbɪl.ə.ti/ n. 可移植性of traditional supervised methods and the limited coverage of available event annotations.
--->problem: handling new event types means to start from scratch without being able to re-use annotations for old event types.
reasons: thest approaches modeled event extraction as a classification problem, encoding features only by measuring the similarity between rich features encoded for test event mentions and annotated event mentions.
--->We observed that both event mentions and types can be represented with structures.
event mention structure <--- constructed from trigger and candidate arguments
event type structure <--- consists of event type and predefined roles
---> Figure 2.
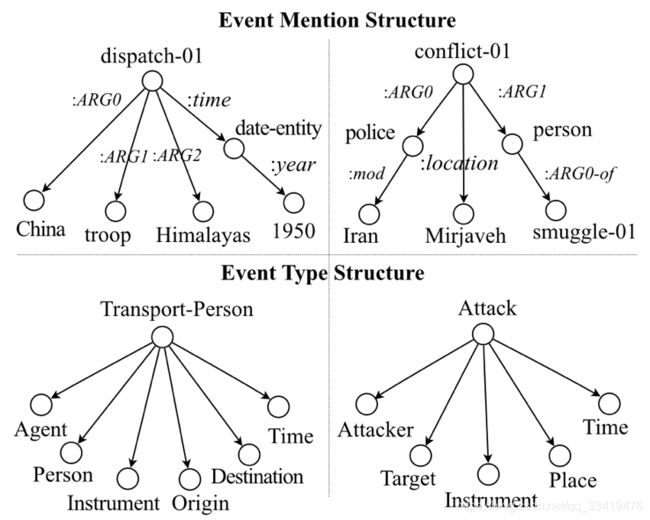
Figure 2: Examples of Event Mention and Type Structures from ERE.
AMR --> abstract meaning representation, to identify candidate arguments and construct event mention structures.
ERE --> entity relation event, event types can also be represented with structures form ERE.
besides the lexical semantics that relates a trigger to its type, their structures also tend to ben similar.
this observation is similar to the theory that the semantics of an event structure can be generalized and mapped to event mention structures in semantic and predictable way.
event extraction task --> by mapping each mention to its semantically closest event type in the ontology.
---> one possible implementation: Zero-Shot Learning(ZSL), which had been successfully exploited in visual object classification.
main idea of ZSL for vision tasks: is to represent both images and type labels in a multi-dimensional vector space separately, and then learn a regression model to map from image semantic space to type label semantic space based on annotated images for seen labels. This regression model can be further used to predict the unseen labels of any given image.
---> one goal is to effectively transfer the knowledge of events from seen types to unseen types, so we can extract event mentions of any types defined in the ontology.
We design a transferable neural architecture, which jointly learns and maps the structural representation of both event mentions and types into a shared semantic space by minimizing the distance between each event mention and its corresponding type.
unseen types' event mentions, their structures will be projected into the same semantic space using the same framework and assigned types with top-ranked similarity values.
(2) Approach
Event Extraction: triggers; arguments
Figure 3: Architecture Overview
1) a sentence S, start by identifying candidate triggers and arguments based on AMR parsing.
e.g. dispatching is the trigger of a Transport_Person event with four arguments(0, China; 1, troops; 2, Himalayas; 3, time)
we build a structure St using AMR as shown in Figure 3. e.g. dispatch-01
2) each structure is composed of a set of tuples, e.g.
we use a matrix to represent each AMR relation, composing its semantics with two concepts for each tuple, and feed all tuple representations into CNN to generate event mention structure representation Vst(namely candidate trigger).
----> pooling & concatenation. --> Vst
Shared CNN----> Convolution Layer
----> Structure Composition Layer <--St
3) Given a target event ontology, for each type y, e.g. Transport_Person, we construct a type structure Sy by incorporating its predefined roles, and use a tensor to denote the implicit relation between any types and arguments.
compose the semantics of type and argument role with the tensor for each tuple, e.g.
we generate the event type structure representation Vsy using the same CNN.
4) By minimizing the semantic distance between dispatch-01 and Transport_Person Vst and Vsy.
we jointly map the representations of event mention and event types into a shared semantic space, where each mention is closest to its annotated type.
5) After training, the compositional functions and CNNs can be further used to project any new event mention(e.g. donate-01) into the semantic space and find its closest event type()
(3) Joint Event Mention and Type Label Embedding
CNN is good at capture sentence level information in various NLP tasks.
--> we use it to generate structure-label representations.
For each event mention structure St=(u1,u2,..., un) and each event type structure Sy=(u1', u2', ...., up') which contains h and p tuples respectively.
--> we apply a weight-sharing CNN to each input structure to jointly learn event mention and type structural representations, which will be later used to learn the ranking function for zero-shot event extraction.
--> Input layer is a sequence of tuples, where the order of tuples is represented by a d * 2 dimensional vector, thus each mention structure and each type stucture are represented as a feature map of dimensionality d x 2h* and d x 2p* respectively.
--> Convolution Layer
--> Max-Pooling
--> Learning
(4) Joint Event Argument and Role Embedding
(5) Zero-Shot Classification