PyTorch框架学习九——网络模型的构建
PyTorch框架学习九——网络模型的构建
- 一、概述
- 二、nn.Module
- 三、模型容器Container
-
- 1.nn.Sequential
- 2.nn.ModuleList
- 3.nn.ModuleDict()
- 4.总结
笔记二到八主要介绍与数据有关的内容,这次笔记将开始介绍网络模型有关的内容,首先我们不追求网络内部各层的具体内容,重点关注模型的构建,学会了如何构建模型,然后再开始一些具体网络层的学习。
一、概述
模型有关的内容主要如下图所示:
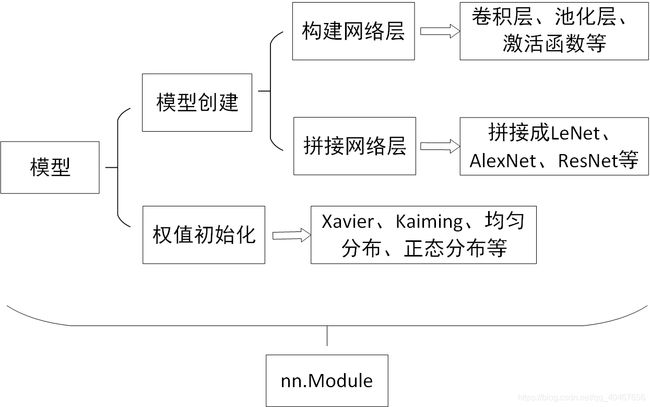
主要是模型的搭建和权值的初始化两个问题,而模型的搭建里,首先需要构建单独的网络层,然后将这些网络层按顺序拼接起来,就构成了一个模型,然后进行某种权值初始化,就可以用于训练数据。
今天介绍PyTorch中是如何实现模型创建的,具体内部的卷积、池化、激活函数等知识下次笔记介绍。上述的所有内容,在PyTorch中都有一个叫nn.Module的模块来实现。
看一个LeNet模型的例子:

从上图可以看出LeNet模型经过了这样一个网络层的流程:
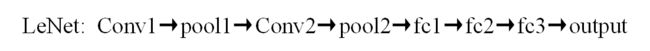
那我们要来搭建这个模型的话,就要先单独构建卷积层Conv,池化层pool,全连接层fc,然后按照上面的顺序进行拼接,拼接后的整体才是一个构建好的网络模型。
看一下LeNet的模型构建的代码:
class LeNet(nn.Module):
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
可以看出__init__()函数实现了对每一个单独的网络层的构建,forward()函数实现了子网络层的拼接。
二、nn.Module
介绍nn.Module之前先看一下torch.nn里四个重要的模块:
- torch.nn.Parameter:张量的子类,表示可学习的参数,如weight、bias。
- torch.nn.Module:所有网络层的基类,管理网络属性。
- torch.nn.functional:函数具体实现,如卷积、池化、激活函数等。
- torch.nn.init:参数初始化的方法。
这里重点介绍nn.Parameter和nn.Module。
nn.Module来构建网络层时会创建8个字典管理它的不同属性,分别如下所示:
- parameters:存储管理nn.Parameter类。
- modules:存储管理nn.Module类。
- buffers:存储管理缓冲属性,如BN层中的running_mean。
- ×××_hooks(5个):存储管理钩子函数(目前不了解)。
下面的代码是创建一个module时对8个字典的初始化:
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict()
self._buffers = OrderedDict()
self._backward_hooks = OrderedDict()
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict()
注意:
- 一个module可以包含多个子module,如LeNet是一个module,它包含了conv、fc等子module。
- 一个module相当于一个运算,必须实现forward函数。
- 每个module都有8个字典管理它的属性。
三、模型容器Container
模型容器有三种,如下图所示:

1.nn.Sequential
功能:是nn.Module的容器,用于按顺序包装一组网络层。
还是以LeNet为例,我们将LeNet分成features和classifier两部分,每个部分都是一个sequential:

代码如下:
class LeNetSequential(nn.Module):
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes),)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
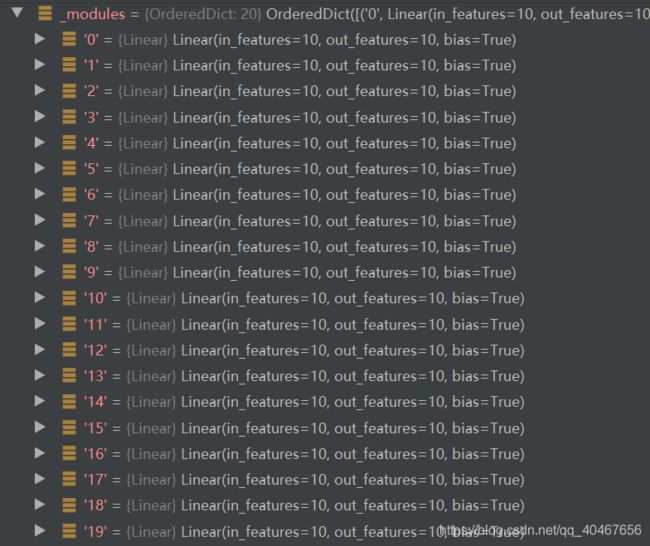
但是,这种构建网络的方式有一个小问题,每一层网络层都会自动按顺序编一个号作为name,如features这个Sequential里每层网络层在module属性内部是这样的:

这里只有六个网络层,所以还可以在短时间内找到你需要的那一个,但是当层数非常多的时候,这种数字命名的方式就很不友好,而Sequential也有相应的应对方法,即为每一层网络命名,具体代码如下所示:
class LeNetSequentialOrderDict(nn.Module):
def __init__(self, classes):
super(LeNetSequentialOrderDict, self).__init__()
self.features = nn.Sequential(OrderedDict({
'conv1': nn.Conv2d(3, 6, 5),
'relu1': nn.ReLU(inplace=True),
'pool1': nn.MaxPool2d(kernel_size=2, stride=2),
'conv2': nn.Conv2d(6, 16, 5),
'relu2': nn.ReLU(inplace=True),
'pool2': nn.MaxPool2d(kernel_size=2, stride=2),
}))
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(16*5*5, 120),
'relu3': nn.ReLU(),
'fc2': nn.Linear(120, 84),
'relu4': nn.ReLU(inplace=True),
'fc3': nn.Linear(84, classes),
}))
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
与原来不同的地方就是,构建了一个OrderedDict字典来存放键值对,key就是每一层网络的名字,value就是具体的网络层实现,看一下此时的module属性内部:

这样就很好寻找所需要的某一层网络。
综上,Sequential的特点:
- 顺序性:各网络层之间严格按照顺序构建。
- 自带forward():通过for循环依次执行前向传播运算。
2.nn.ModuleList
也是nn.module的容器,用于包装一组网络层,以迭代方式调用网络层。
主要方法:
- append():在ModuleList后面添加网络层
- extend():拼接两个ModuleList
- insert():指定在ModuleList中位置插入网络层
这种容器比较适合构建大量重复的网络层,因为利用了迭代的方法,下面就是构建20个线性层的例子
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
3.nn.ModuleDict()
也是nn.module的容器,用于包装一组网络层,以索引方式调用网络层。
主要方法:
- clear():清空ModuleDict
- items():返回可迭代的键值对
- keys():返回字典的键
- values():返回字典的值
- pop():返回一对键值,并从字典中删除
这种容器的特点是,因为键值对可以索引的特性,可用于选择网络层:
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU()
})
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
net = ModuleDict()
fake_img = torch.randn((4, 10, 32, 32))
output = net(fake_img, 'conv', 'relu')
print(output)
我们构建了conv、pool以及relu、prelu,然后我们选择使用conv和relu。
4.总结
对于上述提及的三种容器,它们各自的特点以及适用范围如下所示:
- nn.Sequential:顺序性,各层之间按顺序执行,常用于block的构建。
- nn.ModuleList:迭代性,常用于大量重复网络层的构建,通过for循环实现重复构建。
- nn.ModuleDict:索引性,常用于可选择的网络层的构建,通过字典的键值对实现选择。