神经网络与深度学习实验day12-基于ResNet18完成cifar-10图像分类任务
神经网络与深度学习实验day12-基于ResNet18完成cifar-10图像分类任务
- 5.5 实践:基于ResNet18网络完成图像分类任务
-
- 5.5.1 数据处理
-
- 5.5.1.1数据集导入
- 5.5.1.2 划分训练集、验证集、测试集
- 5.5.2 模型构建
- 5.5.3 模型训练
- 5.5.4 模型评价
- 5.5.5 模型预测
- 思考题
-
- 1. 什么是“预训练模型”?什么是“迁移学习”?(必做)
- 2. 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
- 3. 阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
- 4. 用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
- 总结
- References:
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification)
计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。
很多任务可以转换为图像分类任务。
比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。

- 数据集:CIFAR-10数据集
- 网络:ResNet18模型
- 损失函数:交叉熵损失
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据处理
5.5.1.1数据集导入
数据集导入函数:
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_' + str(batch_id))
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding='latin1')
imgs = batch['data'].reshape((len(batch['data']), 3, 32, 32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
加载数据集:
imgs_batch, labels_batch = load_cifar10_batch(folder_path='C:/Users/大楠爱吃屁/Desktop/cifar-10-python.tar/cifar-10-python/cifar-10-batches-py',
batch_id=1, mode='train')
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
观察一下数据集中的一张图片:
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('cnn-car.pdf')
5.5.1.2 划分训练集、验证集、测试集
导入包:
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import PIL.Image as Image
划分训练集、验证集、测试集的函数:
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path='C:/Users/大楠爱吃屁/Desktop/cifar-10-python.tar/cifar-10-python/cifar-10-batches-py', mode='train'):
if mode == 'train':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate(
[self.labels, labels_batch])
elif mode == 'dev':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = img.transpose(1, 2, 0)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
执行划分:
train_dataset = CIFAR10Dataset(folder_path='C:/Users/大楠爱吃屁/Desktop/cifar-10-python.tar/cifar-10-python/cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='C:/Users/大楠爱吃屁/Desktop/cifar-10-python.tar/cifar-10-python/cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='C:/Users/大楠爱吃屁/Desktop/cifar-10-python.tar/cifar-10-python/cifar-10-batches-py', mode='test')
5.5.2 模型构建
导入nndl中的函数:
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
self.dev_scores = []
self.train_epoch_losses = []
self.train_step_losses = []
self.dev_losses = []
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
self.model.train()
num_epochs = kwargs.get("num_epochs", 0)
log_steps = kwargs.get("log_steps", 100)
eval_steps = kwargs.get("eval_steps", 0)
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
global_step = 0
for epoch in range(num_epochs):
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
logits = self.model(X).cuda()
y = y.to(dtype=torch.int64)
y = y.cuda()
loss = self.loss_fn(logits, y)
total_loss += loss
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
loss.backward()
if custom_print_log:
custom_print_log(self)
self.optimizer.step()
optimizer.zero_grad()
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
self.model.train()
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
trn_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
self.model.eval()
global_step = kwargs.get("global_step", -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
X, y = data
y = y.to(torch.int64)
X = X.cuda()
y = y.cuda()
logits = self.model(X).cuda()
loss = self.loss_fn(logits, y).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
@torch.no_grad()
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
import torch
def accuracy(preds, labels):
print(preds)
if preds.shape[1] == 1:
preds = torch.can_cast((preds >= 0.5).dtype, to=torch.float32)
else:
preds = torch.argmax(preds, dim=1)
torch.can_cast(preds.dtype, torch.int32)
return torch.mean(torch.tensor((preds == labels), dtype=torch.float32))
class Accuracy():
def __init__(self):
self.num_correct = 0
self.num_count = 0
self.is_logist = True
def update(self, outputs, labels):
if outputs.shape[1] == 1:
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
preds = torch.can_cast((outputs >= 0), dtype=torch.float32)
else:
preds = torch.can_cast((outputs >= 0.5), dtype=torch.float32)
else:
preds = torch.argmax(outputs, dim=1).int()
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
构建torchvision.models中的resnet18模型:
from torchvision.models import resnet18
resnet18_model = resnet18()
5.5.3 模型训练
建议使用cuda进行训练,如果没有cuda选择cpu:
import torch.nn.functional as F
import torch.optim as opt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
lr = 0.001
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = resnet18_model
model.to(device)
optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9)
loss_fn = F.cross_entropy
metric = Accuracy()
runner = RunnerV3(model, optimizer, loss_fn, metric)
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
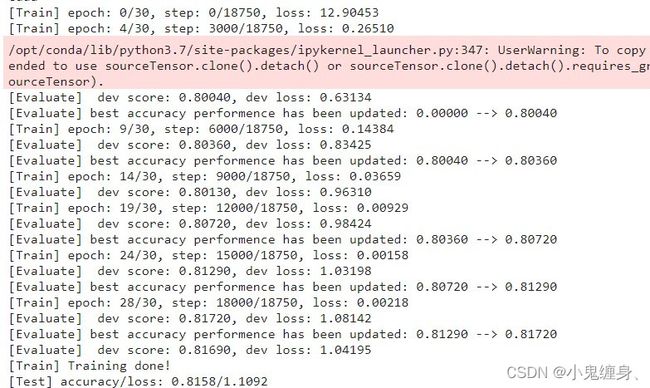
训练结果示意:

5.5.4 模型评价
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(iter(test_loader))
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
评价结果:
![]()
5.5.5 模型预测
输入一张图片进行测试:
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
X = X.cpu()
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
print(label[2].numpy())
label = label[2].numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='C:/Users/大楠爱吃屁/Desktop/cifar-10-python.tar/cifar-10-python/cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')
测试结果:

思考题
1. 什么是“预训练模型”?什么是“迁移学习”?(必做)
预训练模型:
预训练模型是深度学习架构,已经过训练以执行大量数据上的特定任务。这种训练不容易执行,并且通常需要大量资源,超出许多可用于深度学习模型的人可用的资。在谈论预训练模型时,通常指的是在Imagenet上训练的CNN。
言简意赅的意思就是(用自己的话说):预训练模型通过大量数据使用高配置GPU和多次GPU进行训练从而得到的模型参数,再保存模型得到预训练模型。
迁移学习:
迁移学习是机器学习中的一个名词,是指一种学习对另一种学习的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范的学习中。
迁移学习专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。计算机领域的迁移学习和心理学常常提到的学习迁移在概念上有一定关系,但是两个领域在学术上的关系非常有限。
简要来说,就是将一种模型的学习思想用到另一种方法中区,从而产生影响,在机器学习中,有一种图像处理办法叫做图片的风格迁移,也是一种迁移学习。
2. 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
对于使用预训练模型,由于自身电脑的局限性,用Kaggle平台提供GPU进行训练。
resnet = models.resnet18(pretrained=True)
resnet = models.resnet18(pretrained=False)
对比分析:
通过对比可以看出,使用预训练的结果比不适用预训练的结果表现的要好,说明参数的初始值对于网络的最终结果也会产生影响,预训练是必要的。
3. 阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
首先看一下五种深度的ResNet
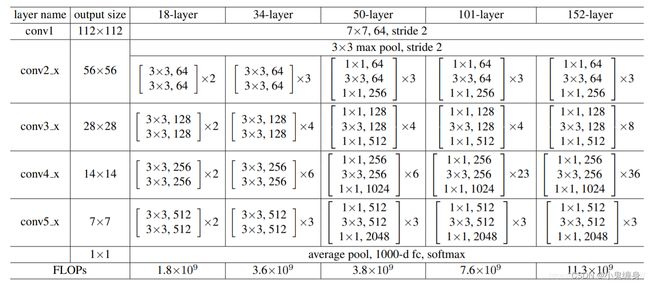
resnet18:
layer1:

layer2:

layer3-4:
layer3和layer4结构和layer2相同,无非就是通道数变多,输出尺寸变小,就不再赘述。
ResNet18和ResNet34的区别:
ResNet18和34都是基于Basicblock,结构非常相似,差别只在于每个layer的block数。
下面看一下ResNet50的结构:
layer1:
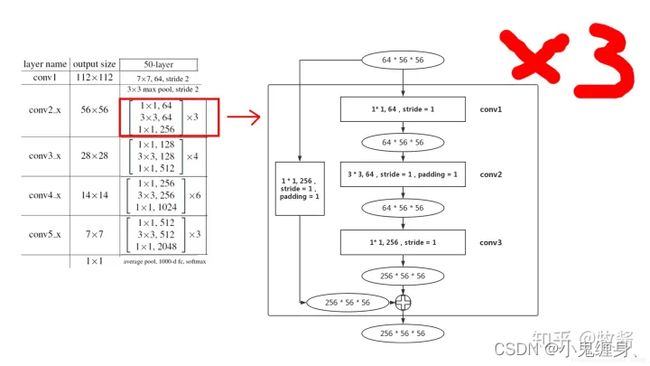
layer2:
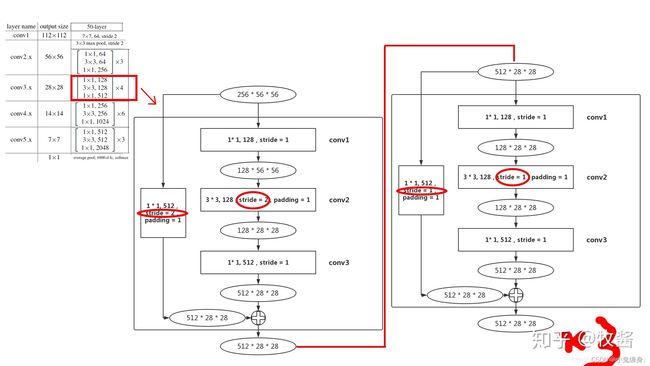
layer3-4
layer3和layer4结构和layer2相同,无非就是通道数变多,输出尺寸变小,就不再赘述。
ResNet50和ResNet101和ResNet152的区别:
ResNet50、101和152都是基于Basicblock,结构非常相似,差别只在于每个layer的block数。
简单谈一谈自己的看法:
先说一下ResNet最大的创新点,正是标题中的《Deep Residual Learning for Image Recognition》体现,深度残差网络使得ResNet横空出世,ResNet的结构,它使用了一种连接方式叫做“shortcut connection”,shortcut翻译过来就是“抄近道”的意思。

为什么会出现“残差网络”呢?因为随着网络的逐渐深入,神经网络的弊端幅效益开始增大,诸如什么梯度爆炸、梯度消失、搞不好还过拟合,残差网络的提出允许ResNet的网络层数进一步加深,从而有利于更好的提取特征,获得更高的准确率。
那么对于这五种ResNet深度网络,我自己的理解是,对于不是很大的数据集,使用ResNet18\34\50已经可以满足要求,对于大型数据可以使用高层网络提取更复杂的特征,因为随着网络层数的逐步加深,越容易出现梯度消失的问题,也容易造成模型的训练难度变大,此次ResNet18实现cifar10如果没有cuda,只用cpu跑的话,可能得跑几个小时才能看一次结果,那么这个模型的效益就不在了,另外,随着层数的加深,也容易出现退化的现象,即:当模型的深度增加时,输出的错误率反而提高,对于我们想要达到的目标来说是“适得其反”的。
4. 用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
2.1 首先说一下LeNet:
1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,从而完成数字识别。
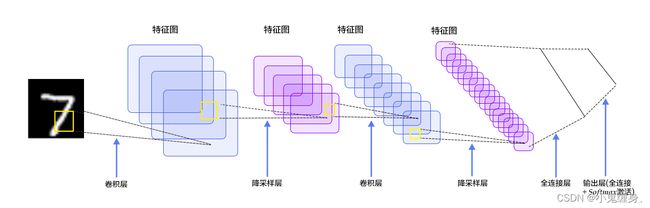
对于LeNet的评价:
LeNet作为卷积神经网络的鼻祖,无论是开创性还是影响力都是巨大的,一直供后人学习着,作为深度学习的“Hello World”,因为是LeNet是CNN的创始者,所以在很多方面LeNet存在着很多缺点,比如不能解决图片输入尺寸过大的问题,当输入的图片过大时,他表现得效果不尽人意。
2.2浅谈一下AlexNet
在2012年,Alex Krizhevsky等人提出的AlexNet以很大优势获得了ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
- 数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
- 使用Dropout抑制过拟合
- 使用ReLU激活函数减少梯度消失现象

对AlexNet的简要评价:
AlexNet的成功归结于几个方面:①扩充了数据集的大小,使用数据增强;② 激活函数 ReLU 对抗梯度消失;③ Dropout 避免过拟合;④LRN 的使用;⑤ 双GPU并行计算提升计算速度。AlexNet提出的relu激活函数目前仍在使用,drop-out已经用的比较少了而且不太好用。不过AlexNet网络的深度还不是特别的深入,但相对于LeNet已经有了很多的创新点。
2.3谈VGGNet
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zis。serman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和pooling层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
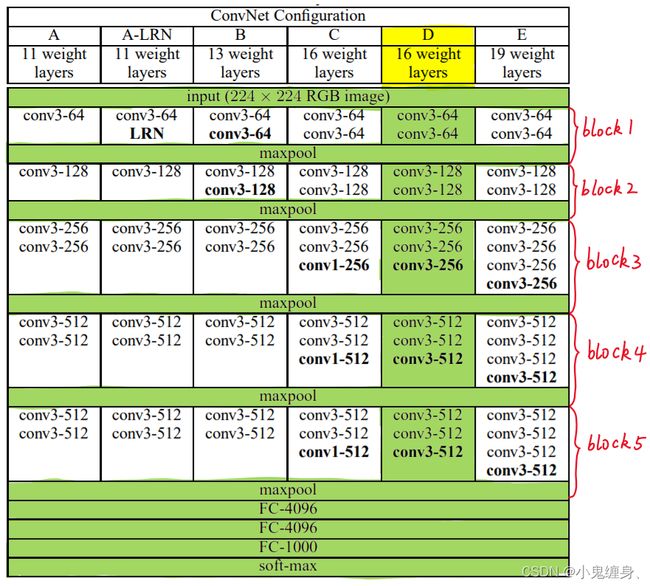
对于VGG的简要评价:
vgg模型的输入是固定的224×224的彩色RGB通道图像。输入做的唯一一个数据预处理就是各自减去 RGB 3个通道的均值,使用的是非常小的3×3的卷积核。创新性的将其中一个结构采用了一些1×1的卷积核。VGG虽然没有取得ImageNet的冠军,但是其结构相对于当年的冠军GoogleNet简单,并且准确率也不差多少,我对于VGG的评价就是,简单且好用。
2.4谈GoogleNet
GoogleNet参数为500万个 ,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍。
GoogLeNet在2014的ImageNet分类任务上击败了VGG-Nets夺得冠军。
GoogleNet模型图片
对于GoogleNet的简要评价:
作为2014年ImageNet分类任务上的冠军,肯定是有很多地方值得我们学习的。创新性的将卷积层和激活层的传统办法替代为了Inception结构,将卷积神经网络推向了一个新的高度,GoogLeNet的核心思想是:将全连接,甚至卷积中的局部连接,全部替换为稀疏连接,从而产生了既能保持网络结构的稀疏性,又能利用密集计算的高效性的方法,创新性的将将原来线性卷积层改为多层感知卷积层,并且将全连接层改为全局平均池化
2.5谈ResNet
2015年何恺明推出的ResNet在ISLVRC和COCO上横扫所有选手,获得冠军。ResNet在网络结构上做了大创新,而不再是简单的堆积层数,ResNet在卷积神经网络的新思路,绝对是深度学习发展历程上里程碑式的事件。
对于ResNet的简要评价:
ResNet主要解决的问题,就是在深度网络中的退化的问题。在深度学习的领域中,常规网络的堆叠并不会是越深效果则越好,在超过一定深度以后,准确度开始下降,并且由于训练集的准确度也在降低,证明了不是由于过拟合的原因。并且创新性的给出了残差网络的实现,能够很好的起到优化训练的结果。ResNet是当前的主流网络,在VGG基础上提升了长度,加入了res-block结构。整个ResNet不使用dropout,全部使用BN,但是吧,对于现在已经有的transformer来说,ResNet好像又不厉害了(但是确实牛),感觉是长江后浪推前浪。
总结
CNN思维导图
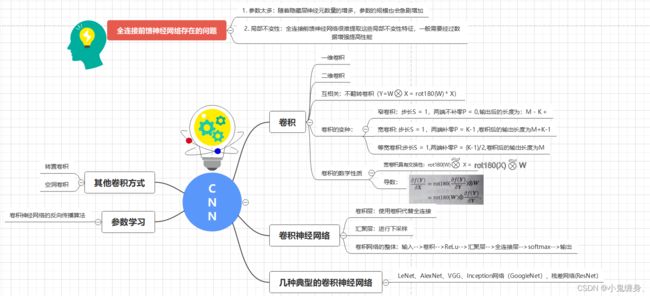
实验总结:
此次实验基于torch对CIFAR10进行图像分类,最终得到了73.6%的正确率,感觉还是有点不甘心,前几天天天调参数,感觉ResNet的设计不应该训练经典的CIFAR10才有73.6%的准确率,好像大家的准确率都稳定在了75左右,可能是参数的问题?不像。任何能改参数的地方我都改了一遍,然后大大小小的参数都试过了,每次都跑20多分钟,这还是用了CUDA的,要是没用CUDA,用的CPU,我估计现在跑一个结果都得一两个小时,超级慢!。配了好几天的参数,最终还是觉得这个模型就只有75左右的准确率了,我甚至都把resnet18改成resnet50了,我也试了resnet34,感觉准确率没变多少,真的不知道哪里有问题,如果有人能知道上边的代码问题在哪儿,不知道为啥准确率在73%,损失稳定在1.0左右,我期望的准确率在95%,误差降在0.01左右,如果有知道解决办法的,请告知我,谢谢。
References:
关于深度残差网络(Deep residual network, ResNet)
ResNet网络结构分析
GoogleNet、AleXNet、VGGNet、ResNet等总结
一文读懂LeNet、AlexNet、VGG、GoogleNet、ResNet到底是什么?
vgg和alexnet,lenet resnet等网络简要评价和使用体会
GoogLeNet原理和实现
卷积神经网络VGG 论文细读 + Tensorflow实现
深度学习:经典网络模型lenet,alexnet,vggnet,googlenet,Resnet,densenet可解释性
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
老师博客:NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类