虚幻AI蓝图基础笔记(万字整理)
AI原理
一、三大阶段
AI的处理过程可以分为三大阶段:感知、思考、行动
(1)感知
对AI当前状态作记录。
“基本过滤”也是一种感知行为。
基本过滤 - 如果其他感知的优先级更高,会忽略部分信息
(2)思考
AI利用感知阶段收集到的信息,对当前信息和目标进行评估,为之后的行动指明方向。
(3)行动
根据感知阶段的信息和思考阶段的决策,AI在行动阶段对信息做出相应的行为。
行动阶段结束后,AI会再次回到感知阶段。
行为有可见的,如跳跑;也有不可见的,如通信
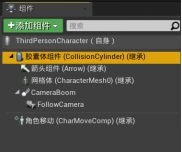
二、创造AI角色
一个角色蓝图,一个AI控制蓝图
- 胶囊体——控制碰撞
- 网格体——控制骨骼、动画、材质
- Camera Boom——控制摄像机视图
- 角色移动组件——控制角色移动、游泳、飞行等动作
流程
1.制作AI蓝图
a.拷贝第三人称角色蓝图——删掉事件图表中所有的节点(因为AI不需要输入数据)
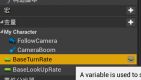
b.删除一些与输入有关的变量:“基础转动速率”、“基础俯仰速率”
![]()
c.删除摄像机组件:camera Boom(摄像机升降臂)、跟随相机

2.AI控制器
a.添加AI控制器 - 替换刚刚删除的玩家控制器的功能
b.建立AI控制器蓝图
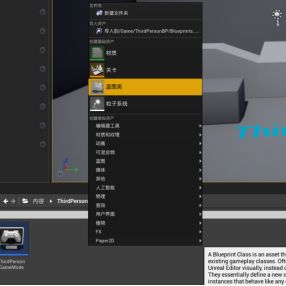
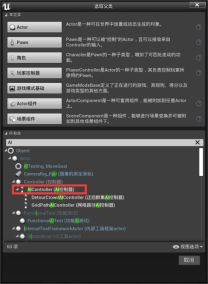
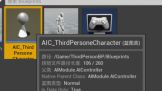
c.打开AI_ThirdPersonCharacter蓝图——PAWN——AI控制器类——绑定AI控制器蓝图
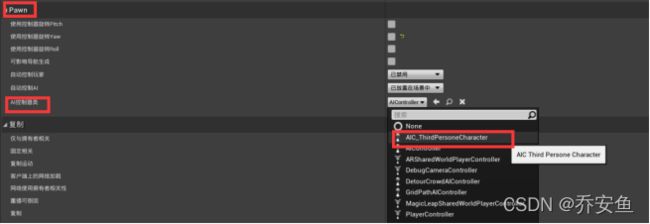
三、寻路
AI需要信息和数据才能在场景中移动并躲避障碍。
在场景中寻路是AI的基本功能,不仅仅是从A-B点。
(一)寻路原理
- 计算路径
- 躲避障碍
- 寻路网格体 - 用于帮助AI在场景中寻路。网格体由大量凸多边形组成,规定了哪些区域AI可以通过。

- 预计算数据
寻路网格体都是预先计算(“烘焙”)好的,这意味着在游戏开始前,以2D网格体形式表示的寻路网格体就已经包含了场景对象和AI自身生成的碰撞数据。这就使得寻路的开销更低。对于那些代理数量或类型不确定的实时体验来说,这点尤为明显。
添加寻路网格体Actor
为了让AI使用预计算数据。
流程
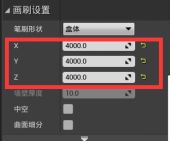
- 模式 - 寻路网格体(Nav Mesh Bounds Volume)拖入场景 - “细节”面板调整笔刷尺寸 -
让网格体覆盖AI需要行走的场景
寻路网格体开销低、速度快、高可靠,可以快速实现导航功能,但是场景无法动态修改寻路网格体。

(二)配置寻路网格体
1.寻路网格体调整
寻路网格体大小不需要特别准确。
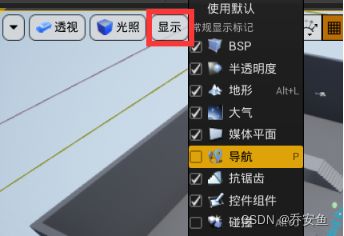
a.显示网格体 :视口选项 - 显示 - 导航(快捷键P)
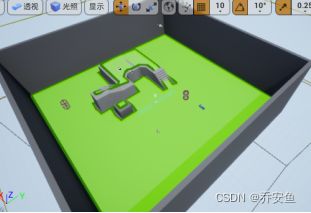
b.默认网格体自动更新 - 移动场景物件,寻路网格体会实时更新。若关卡较大,会很耗性能。
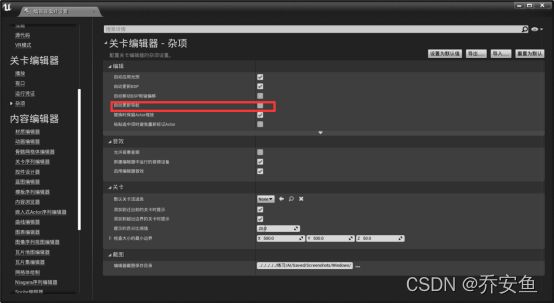
c.(仅对较大关卡)关闭自动更新 - 编辑器偏好设置 - 关卡编辑器 - 杂项 - 关闭自动更新导航
d. 手动更新 - 构建 - 导航 - 构建路径(无需在意日志里的错误消息)
2.使用RecastNavMesh调整寻路网格体部分属性
创建寻路网格体时,Recast寻路网格体自动创建。
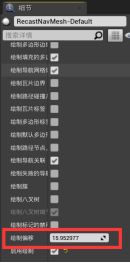
选中RecastNavMesh,在细节面板调整。
- 绘制偏移 - 抬升或降低寻路网格体。不会改变网格体实际位置,只是改变视觉效果。(对被遮挡的区域显示很有帮助)
默认为10。

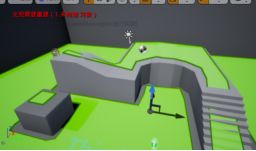
- 导航修改器体积(Nav Modifer Volume) - 不会生成任何几何体。
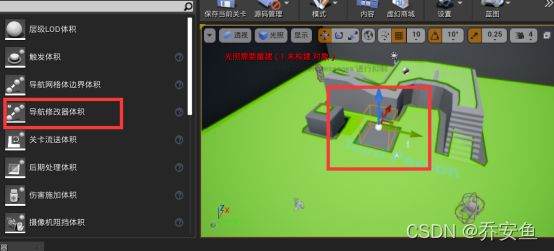
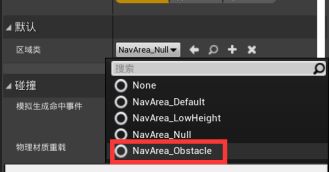
- 导航网格体障碍 - 表现某片区域难通过。AI不会优先选择这个路径。不会移除导航网格体。

- NavArea_Null - 移除导航网格体,无法通过
。

- NavArea_LowHeight - 在高度不足的地方使用。无法通过。
- NavArea_Default - 可以通过。
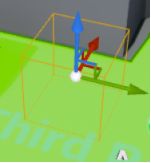
(三)导航网格体代理
如果想要尺寸更大、游泳、飞行的角色,只需要定义新的寻路网格体代理,并进行相应设置以适应新的尺寸和运动形式。
- 代理 - 场景中任何形式的自主实体。这里泛指AI角色。
- 在RecastNavMesh中调整代理参数,可打开AI蓝图的胶囊体参数对照调整。
- 代理高度 - 会出现高度不够,但是可以通行的状况。修改后,变为不可通过区域。


- 增加代理类型和数量:项目设置 - 引擎 - 导航系统 - 代理
四、使用控制器让AI漫游
(一)蓝图编写漫游逻辑
给角色蓝图新建一个自定义事件,包含随机漫游逻辑 - 增加一个函数,在游戏中反复调用自定义事件
流程
a.AI行动
打开AI角色蓝图 - 在“事件图表”窗口右键创建“自定义事件custom event”,命名为“random wander随机漫游”- “随机漫游”后跟“到Location的简单移动Simple Move To Location”函数
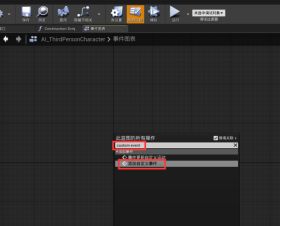

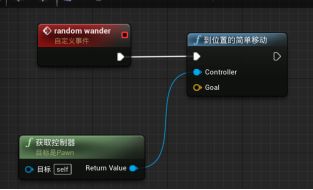
- “到Location 的简单移动”的两个参数:
- Controller - 角色的控制器。
- Goal - 用向量表示的目标位置。
- Get controller - 会获取所绑定的对象,并返回该对象的控制器。
b.“Get controller获取控制器”函数返回值与“到Location的简单移动”的controller参数连接。
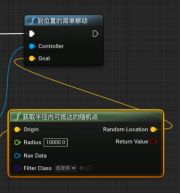
- “Get Random Reachable Point In Radius获取半径内能到达的随机点”参数:
- Origin起点
- Radius半径 - AI能到达的范围
- “Get Actor Location获取Actor位置” - 默认为自己。
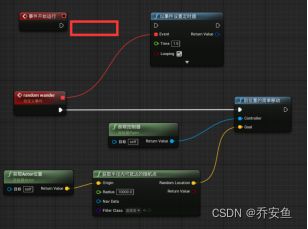
c.随机漫游
“获取半径内能到达的随机点”起点为当前AI的位置:“获取Actor位置”函数的返回值连接origin - 调整半径为1000 - 返回值与“到Actor的简单移动”的Goal参数连接。


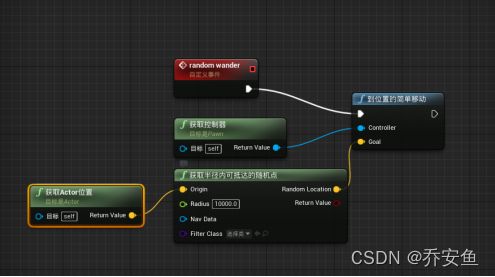
d.定时器循环
创建“begin play”事件 - 连到“set timer by event以事件设置定时器”函数 - random wander随机漫游事件连到“以事件设置定时器”函数的event引脚,设置开始时间time,勾选looping循环
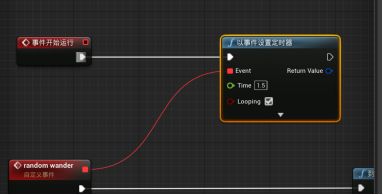

运行游戏,AI会在1.5s后随机漫游
(二)寻路网格体和GamePlay调试器
游戏运行后,按“’”打开控制台。
- 可在项目设置 - 引擎 - 输入 - 控制台,添加快捷键

Gameplay debug“调试器”:检验AI能否在游戏中正确使用寻路网格体。
运行游戏,按快捷键弹出Gamplay调试器,可以看到寻路网格体在不断更新
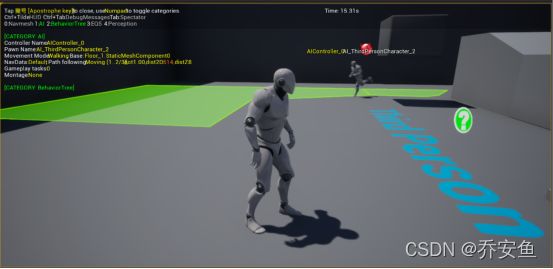
左上角 - 对应按键

AI信息,行为树
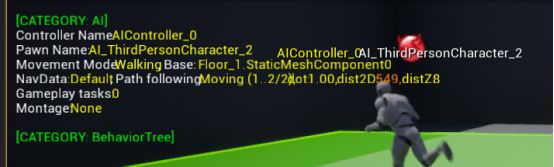
(三) 替换AI美术资源
1.替换AI人物
现在替换AI模型。类型最好是Character而不是Actor,这样才能调用pawn。
将蓝图直接拖入场景,boss就被导入了。
2.调整动画
编写好boss蓝图后,发现boss在移动时在平移,而不是播放跑步动画。
在其他的博主那里看到一个很方便的调试方法:
找到BOSS动画蓝图 - 找到Set is Accelerating一栏
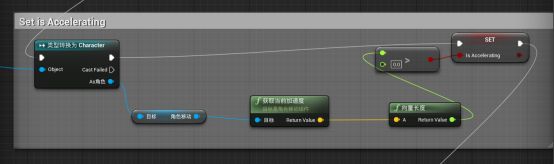
当前是获取的玩家的加速度,转换成向量,再转成长度。大于0则表示在加速。
但是我们的boss是个AI,并没有输入,所以需要获取当前AI的速度:
打断向量长度与0的判断 - 在左边变量找到speed,按住ctrl拖入 - speed与0的判断相连
![]()
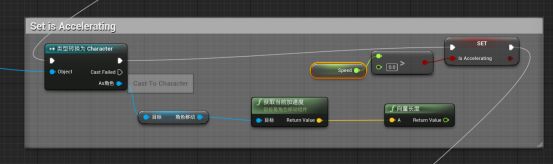
再次运行游戏,boss移动时就会播放跑步动画了。
五、AI感知
(一)视觉
A.创建感官
为AI增加AI感知组件:打开AI蓝图 - 在组件面板增加AI perception感知组件 - 细节 - AI感知,在感官配置栏添加数组 - 数组类型选AI sight Config(AI视力配置)
- 感官配置 - 多少数组代表AI拥有多少感官
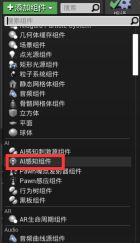

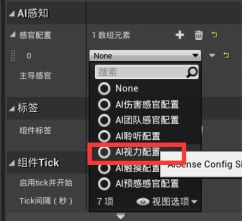
B.按归属检测 - 勾选“检测中立方”
- 系统默认为中立,所以给玩家选为中立方以便检测
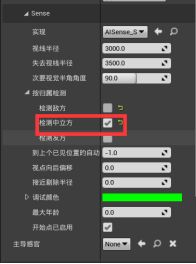
- 最大年龄 - 与多久前见到的最后一个目标有关
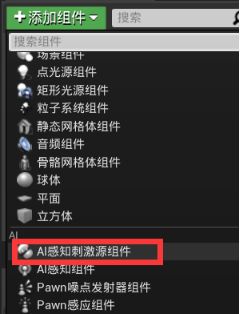
C.把玩家标记为刺激源,这样AI就能感知到。
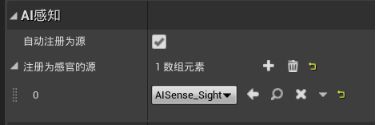
打开玩家蓝图 - 在组件面板添加AI感知刺激源组件 - 细节面板 - AI感知 - 勾选“自动注册为源”、添加数组、类型为AISense_Sight
(二)AI感知和Gameplay调试器
在使用Gameplay调试器之前,先禁用AI蓝图事件让AI停止移动,这样有助于处理感知系统。
A.打开AI蓝图 - 对“事件开始运行”的引脚按Alt断开,停止调用随机漫游事件
B.关闭TAA临时抗锯齿选项:编辑 - 项目设置 - 引擎 - 渲染 - 默认设置 - 抗锯齿方法,勾选“无”
- TAA临时抗锯齿 - 会把若干帧混合在一起,Gameplay的调试线条这类单像素线条很难观察到。

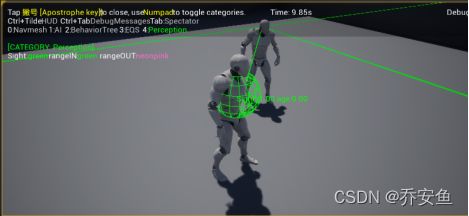
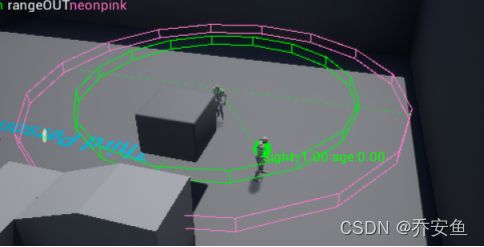
C.运行游戏 - “‘”调出控制台 - 4打开感知信息
- Sight:1 - 可被看见
- Age:多久前更新的信息
- 0 - 最新的信息。
离开后,年龄开始增加。球体表示最后的位置。
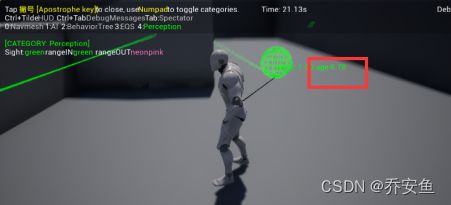
D.在AI蓝图中调整视线半径和失去视线半径数值。
- 视线半径 - 进入绿圈即可获得视野。
- 失去视线半径 - 走出粉圈则失去视野。
- 两者有间隔:过渡更自然。
- 两者重合:会在边界处反复失去和获得视野。
(三)使用AI感知事件
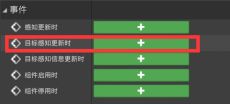
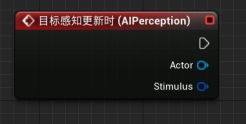
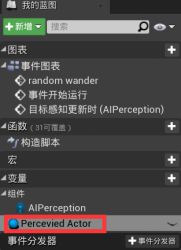
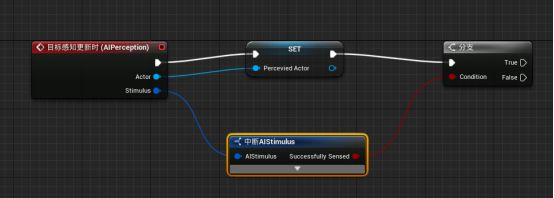
A.在AI蓝图中,选取AI Perception组件 - 在细节面板的事件选项中添加“On Target Perception Update目标感知更新时”事件 - 事件会在蓝图中生成。
- On Target Perception Update事件 - 捕获并存储AI感知的信息以及感知的方式。
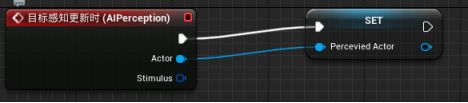
B.确定AI是否看到Actor
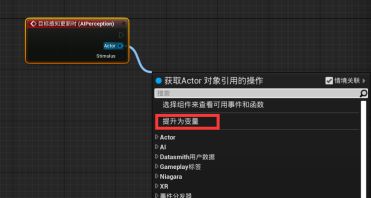
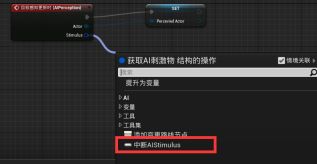
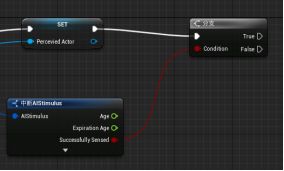
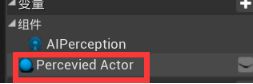
拖拽Actor引脚,提升为变量并给改名为“Perceived Actor可被感知的Actor” - 拖拽Simulates刺激源结构引脚,添加“中断AI Simulates”断点 - 左键点击并按住B生成Branch分支节点 - 中断AI Simulates的Successfully Sensed布尔值引脚与分支节点的“条件Condition”连接,SET的执行引脚与分支节点的执行相连接。
- Actor - 这个变量包含AI感知到的Actor的引用。这个引用会在蓝图中频繁地使用。
- 收起引脚 - 在中断AI Simulates的细节面板中点击“隐藏未连接的引脚”
C.丢失视野,则AI放弃追踪。
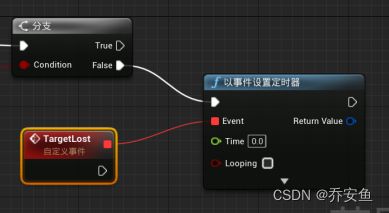
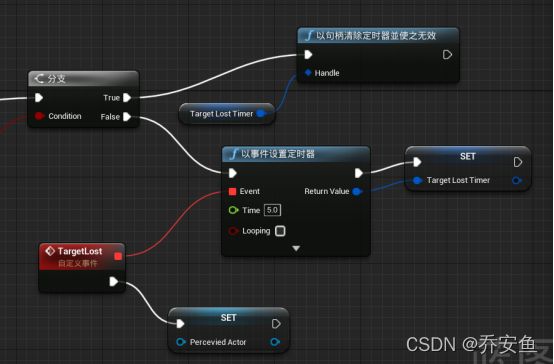
右键创建一个“自定义事件Custom Event”并改名为“Target Lost目标丢失” - 拖拽分支的False引脚并连接新建一个事件定时器“Set timer By Event” - Target Lost事件与定时器的Event相连接,作为触发器,time设为5s。不要勾选循环,因为只触发一次。 - 在“我的蓝图”面板按住Alt键,拖动Perceived Actor到蓝图中创建一个变量。 - Target Lost与Set执行引脚相连(由于没有为Perceived Actor赋值新的变量,AI感知的对象会被清空)
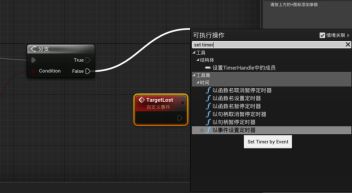

D.为真时,消除定时器
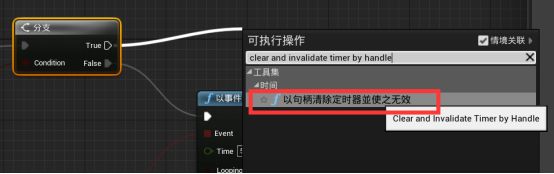
拖拽分支的True引脚并新建一个函数“Clear and invaliate timer by handle以句柄清除定时器并使之无效” - 在定时器的返回值拖拽并提升为变量,改名为Target Lost Timer。- 在我的蓝图面板按Ctrl拖拽并创建Target Lost Timer变量,与以句柄清除定时器并使之无效的handle句柄引脚相连接

六、行为树
AI最重要的环节 - 行为树。
借助行为树,可以轻松控制并显示AI的决策制定过程。
- 行为树:是一种将AI在场景中决策制定模型可视化的方法。
- 观察行为树的可视化结构,可以清晰地了解行为树的执行方式和执行顺序,而不必了解每个节点的具体工作方式。
- 执行顺序 - 由行为树中各个节点的位置决定。从上到下,从左到右。
1.任务节点
行为树的一种节点,下面无法添加其他节点。
是行为树分支的终点(但不是行为树的终点!)。
也被成为“叶节点”
- 任务状态 - 分为:成功、失败、执行。
- 无论失败与否,都会执行下一个节点。顺序从左到右。
2.合成
合成是AI执行分支的根。不会像叶节点那样执行,但能创建一个结构,并根据其子节点的成败控制顺序。
- 选择器合成 - 会执行它下面的子节点。
- 试图选择最合适的任务 -
子节点返回成功,选择器成功。所有子节点返回失败,选择器失败。(只要有一个任务成功,则成功。所有任务失败,则失败。) - 可以把优先级最高的任务放在左边。
- 试图选择最合适的任务 -
- Squencer合成 - 序列合成节点会按照序列顺序遍历子节点,当且仅当所有子节点返回成功,它才成功。如果某个步骤执行失败,它失败。
3.结合
任务和合成可以创建出各种方法来处理AI的行为。
不必纠结如何完成任务,只需制定决策完成任务即可。
(一)构建一个行为树
a.创建需要的资源
在内容栏里创建一个文件夹“BT_Assets” - 在文件夹中右键AI栏中创建一个行为树“BT_EnemyAI”,再创建一个黑板“BB_EnemyAI”

b.确保AI可以使用行为树
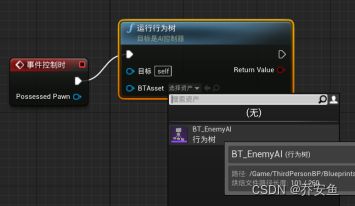
打开AI控制器蓝图 - 创建“Event On Posses事件控制时”事件 - 拖拽执行引脚创建“Run Behavior Tree运行行为树”函数,在BTAsset下拉栏中选择BT_EnemyAI行为树
c.确保黑板与行为树关联
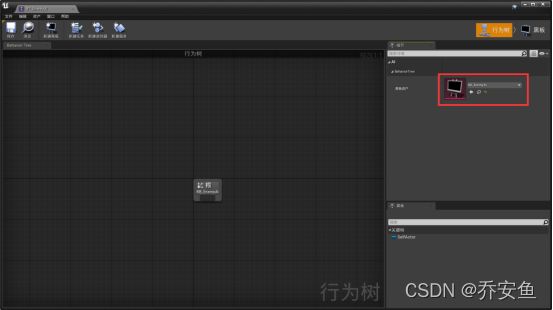
打开行为树,在细节面板确认资产是否选择黑板
d.在黑板创建一个变量来保存目标位置,作为新的漫游目的地
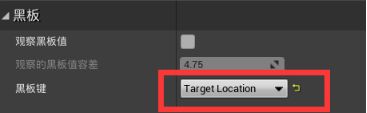
在行为树窗口切换为黑板 - 在黑板选项卡新建一个“向量Vector”条目,命名为Target Location

e.新建一个任务封装之前写的随机漫游逻辑
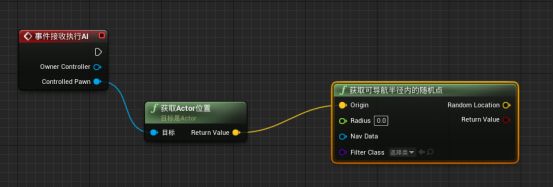
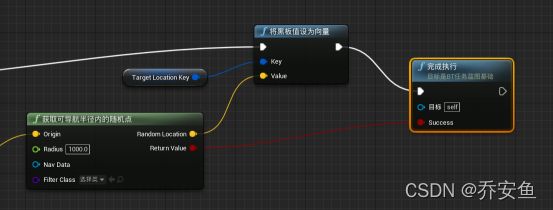
在行为树中新建任务BTTask_BluePrintBase,改名为“BTT_FindNavigatableLocation” - 新建文件夹来储存行为树任务,并打开蓝图 - 新建“Receive Execute AI事件接收执行AI” - 新建“获取可导航半径内的随机点Get random reachable point in radius”函数 ,半径改为1000 - “事件接受执行AI”事件的Controlled pawn引脚拖拽新建“获取actor位置”函数 - 获取actor位置的返回值与获取可导航半径内的随机点函数的Origin相连接。


f.处理随机参数的返回值
和之前的逻辑不同,一旦这个任务完成,它所包含的信息都会销毁。所以要把任务传给行为树,再传给黑板。
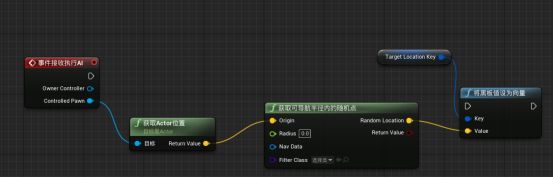
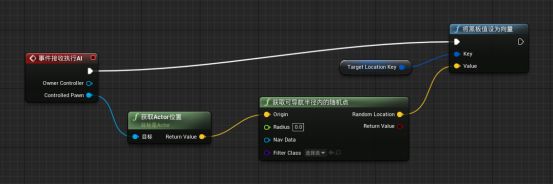
拖拽获取可导航半径内的随机点的random location新建“Set blackboard value as vector把黑板值设为向量”函数 - 拖拽Key引脚并“提升为变量”,改名为Target Location Key。并在我的面板中保证其为公开:因为要在行为树中操作。(名字要与黑板中的键相同,否则无法传递数值) - 事件接受执行AI事件的执行引脚与将黑板值设为向量的执行引脚相连。

g.告诉行为树任务已完成
如果不告诉,任务会一直卡在这里。
将黑板值设为向量的执行引脚与“finish execut完成执行”函数的执行引脚相连 - 获取可导航半径内的随机点的返回值与完成执行的success引脚相连。
只要AI找到随机点,就判断成功。
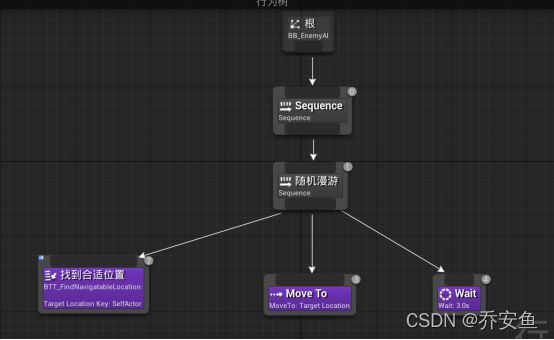
h. 创建行为树
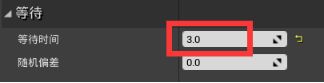
从根拖拽并添加一个sequence序列合成器 - 再添加一个sequnce合成,在细节面板改名为“random wander” - 在sequence下从左到右添加之前创建过的任务BTT_FindNavigatableLocation并改名为“Find suitable Location”,Target Location Key改为Target Location 、Move To并更改黑板键为Target Location、Wait并把等待时间改为3s

(二)追逐玩家
提供感知信息给AI,让AI制定决策。修改行为树以便控制执行流程。
A.创建新的黑板键来保存信息
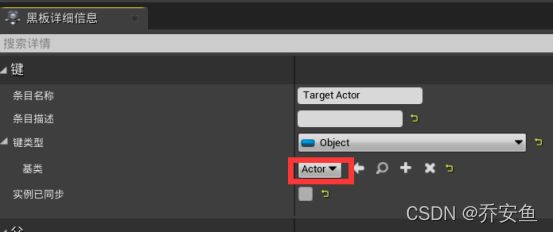
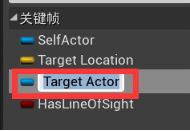
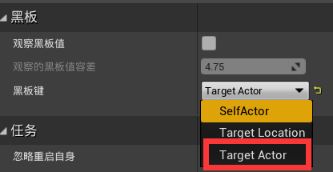
打开AI行为树 - 黑板 - 新建条目object类型,命名Target Actor - 细节面板,键类型>基类,改为Actor类型 - 新建布尔类型条目,命名Has Line Of Sight

![]()
B.调整AI控制器,可以根据感知系统变化来更新黑板键
打开AI控制器,创建一些辅助函数便于处理黑板键:
1.更新黑板数值函数
在我的蓝图面板中新增函数,命名为“Update Target Actor Key” - 在细节面板,输入分段添加一个条目。类型为Actor,命名为Target Actor - 蓝图中新建一个变量“获取黑板键Get Blackboard” - 拖拽引脚新建函数“Set Value As Object 将值设为对象”,拖拽Key name提升为变量“Target Actor Name”(与行为树相关联的黑板键相同)。细节面板>变量>类别,新建一个类别Key Names
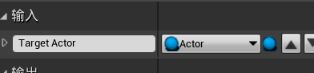
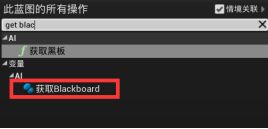
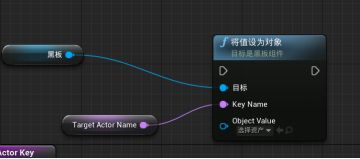

设置Target Actor Name的默认值:需要与黑板键名字一致,最保险的方法就是复制粘贴。
打开黑板,复制Target Actor名字,粘贴到Target Actor Name的默认值。

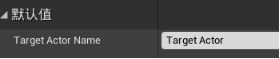
Update Target Actor Key的Target Actor 引脚与Set Value As Object的Object Value相连,执行引脚相连。
2.保存AI感知信息函数
在我的蓝图面板中新增函数,命名为Update Has Line Of Sight Key - 在细节面板,输入分段添加一个条目。类型为Boolean,命名为Has Line Of Sight - 蓝图中新建一个变量“获取黑板键Get Blackboard” - 拖拽引脚新建函数“Set Value As Bool 将值设为布尔”,拖拽Key name提升为变量“Has Line Of Sight Name”(与行为树相关联的黑板键相同)。移入Key Name类别。

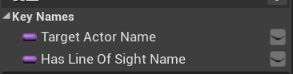
设置Has Line Of Sight Name的默认值:
打开黑板,复制Target Actor名字,粘贴到Target Actor Name的默认值。

Update Has Line Of Sight Key的Has Line Of Sight 引脚与Set Value As Bool的Bool Value相连,执行引脚相连。
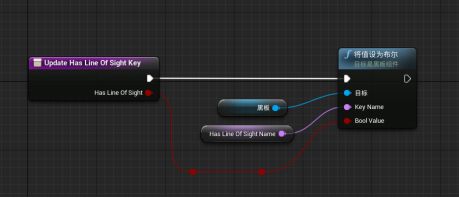
C.利用On Target Perception Update事件来更新新的黑板键
感知状态更新时,对应的黑板键也会更新。
为了访问新建的函数,要获取AI控制器的引用。
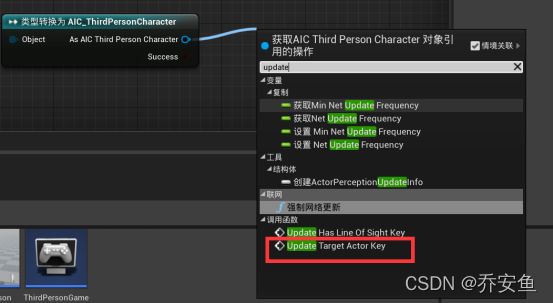
1.Update Target Actor Key来展示Target Lost事件
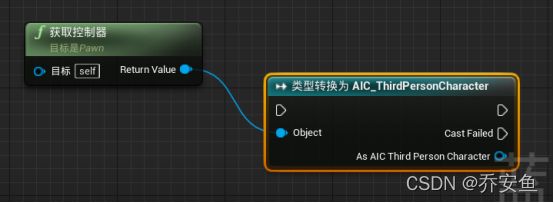
打开AI蓝图 - 新建get controller函数 - 把泛型引用改成AIC_ThirdPersonCharacter:拖拽get controller的返回值,新建cast to AIC_ThirdPersonCharacter“类型转换成AIC_ThirdPersonCharacter” - 为了清晰便于理解,“类型转换成AIC_ThirdPersonCharacter”右键“转换成纯类型转换” 。拖拽As AIC_ThirdPersonCharacter引脚调用Update Target Actor Key - Target Lost连接设置节点的执行引脚与Update Target Actor Key的执行引脚相连
(当没有目标Actor时,Update Target Actor Key不会提供任何参数)


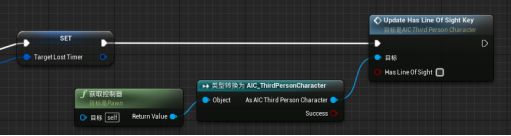
2.Has Line Of Sight Key表示为“假”时的情况
利用函数把Has Line Of Sight Key设为假:
复制get controller、类型转换成AIC_ThirdPersonCharacter两个函数 - 拽As AIC_ThirdPersonCharacter引脚调用Update Has Line Of Sight Key -连接设置节点的执行引脚与Update Has Line Of Sight Key的执行引脚相连(避免Update Has Line Of Sight Key勾选Has Line Of Sight)

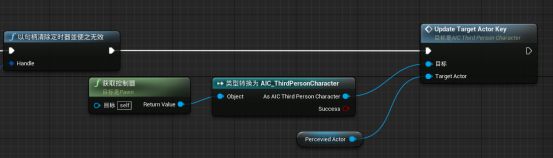
3.利用上面两个函数表示为“真”时的情况
此时AI可以看到玩家。
复制这两个函数
为真的执行引脚与Update Target Actor Key的执行引脚相连。在我的蓝图面板ctrl拖拽Percevied Actor 函数赋值给Update Target Actor Key的Target Actor - Update Target Actor Key的执行引脚与Update Has Line Of Sight Key 的执行引脚相连,勾选Has Line Of Sight
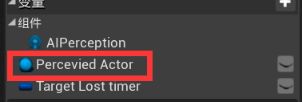
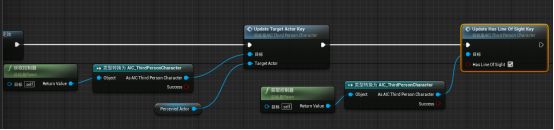
总结:黑板键是提供信息给行为,不做任何决定。行为树负责做决定。
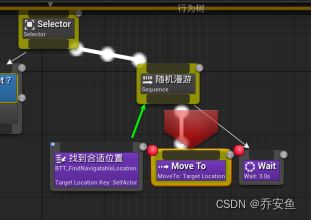
D.拼凑行为树
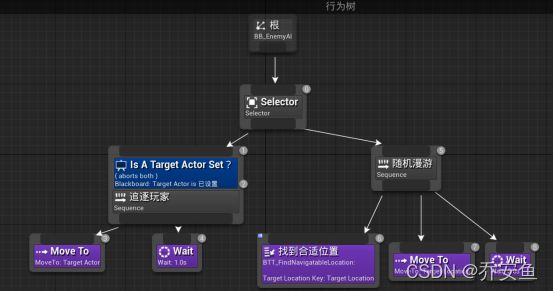
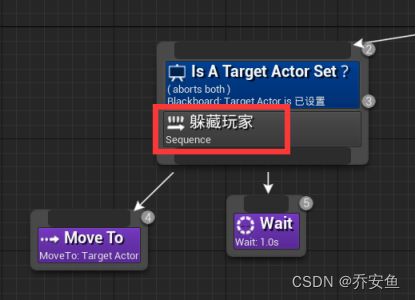
打开行为树 - 第一个合成器换成Slector ,随机漫游放置在右侧 - 在选择器下创造一个新序列Sequncer,并改名为“追逐玩家” - 追逐玩家序列下新建Move to任务,并在细节>黑板>黑板键,改为Target Actor - 新建Wait任务,并把时间改为1s。
- Wait任务 - 通常会在序列后加一个1s的wait任务,以此来避免AI在多个序列中快速浏览,这样会自然一些。

使用装饰器控制分支的执行方式(只有当前需要设置目标Actor时才应该执行):
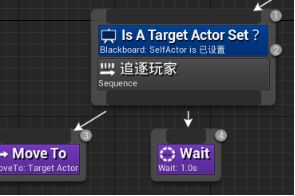
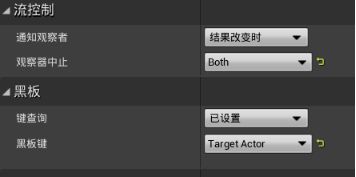
追逐玩家序列器>右键>添加装饰器>BlackBoard - 装饰器起名为Is A Target Actor Set?,把节点名称描述得清楚一些,有助于理解 - 配置装饰器,控制执行流程:黑板键选取Target Actor,通知观察者选取结果改变时、观察器中止选取Both
- 黑板分段 - 允许定义期望的结果
- 流控制分段 - 允许控制观察到期望结果时,执行流程会发生什么。
- 通知观察者
- 结果改变时 -(默认)键查询结果变化时,会按照观察器中止的内容执行。
- 值改变时 - 当目标Actor键变化时,执行流程改变。
- 观察器中止
- None(默认) - 不中止任何操作
- Self - 中止自己
- Low Priority - 中止低优先级序列
- Both - 两个序列都中止


- 通知观察者
(三)测试行为树
以最快最有效的方式跟踪行为树的执行流程。
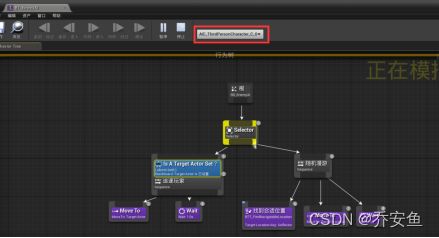
A.调试行为树信息
把玩家放在AI看不到的地方 - 运行游戏 - 打开行为树,选取AIC_ThirdPersonCharacter - 选取随机漫游的wait,F9打上断点。也可以用返回执行上一个节点。
随着行为树越复杂,这个功能越好用。
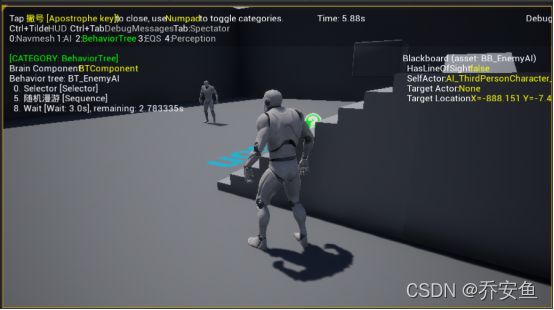
B.使用Gameplay观察行为树
如果出包,或者屏幕有限,可使用Gameplay调试器。
运行游戏 - 打开gameplay调试器 - 按1隐藏AI信息,只显示行为树信息 - 暂停游戏可观察具体流程信息、黑板信息
七、EQS环境查询系统
EQS(Environment Query System) - 让AI能将多种环境因素考虑在内。
(一)创建第一个EQS查询
创建一个AI感兴趣的食物Actor,放入关卡。然后建立EQS查询来帮助AI定位食物来源。
A. 创建食物
新建一个EQS文件夹 - 在文件夹内右键>蓝图类>创建一个Actor蓝图,改名为FoodSource - 打开蓝图,在组件面板新建一个CUBE立方体组件 - 在右侧细节面板>碰撞>碰撞预设,选为无碰撞 - 把Z轴坐标改为70,(有助于放入关卡地图) - 把食物拖入地图
- Nocollison - 避免和Actor碰撞影响寻路网格体,从而影响AI运动。


B.添加EQS查询食物来源
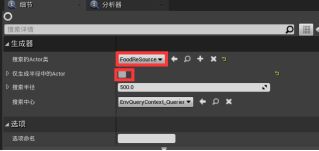
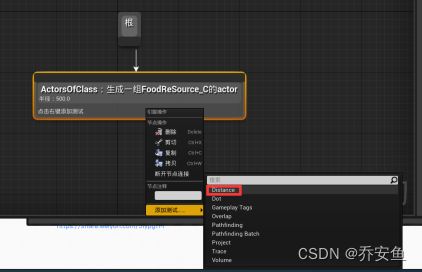
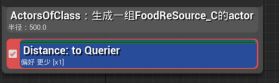
在EQS文件夹中右键>人工智能>创建环境查询资产,改名Find Closet Food Resource - 打开环境查询编辑器,拖动根节点创建Actors Of Class生成器 - 细节面板>生成器分段:搜索的Actor类选FoodResource,取消勾选“仅半径生成Actor” - Actors Of Class右键添加Distance测试,在细节面板:测试目的为仅得分,计分因子为-1
- 仅半径生成Actor - 如果是大型关卡,最好勾选。
- 偏好更少 - 各个食物来源会根据与AI的距离来计分,偏好更少的分数,也就是最近的。

C.在行为树中使用EQS
创建一个黑板键来存储最近的食物来源,然后用装饰器来决定AI是追逐玩家、随机漫游、搜寻食物。
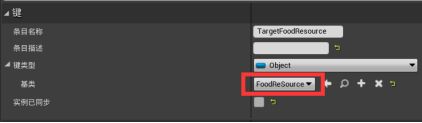
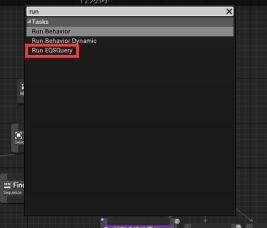
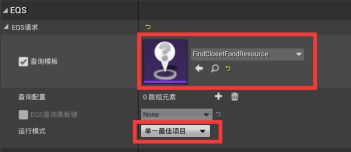
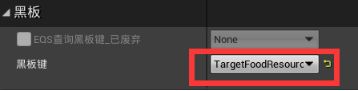
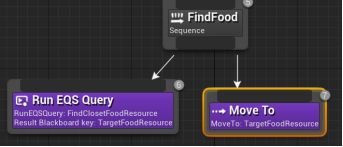
打开行为树 - 在黑板页面新建一个Object条目,改名为TargetFoodResource,基类选FoodResource - 在行为树页面,添加一个Sequence序列,改名为FindFood - 下拉序列器添加Run EQSQuery任务。细节>EQS>EQS请求:查询模板选择Find Closet Food Resource,运行模式选择单一最佳项目。(查询仅计分,会返回多个项目。所以要选择单一)黑板键设为TargetFoodResource。 - 下拉创造Move To Task任务,选取黑板键TargetFoodResource - 下拉添加Wait任务,等待时间改为1s。



(二)根据饥饿程度制定决策
赋予AI搜寻食物的理由,避免只搜寻食物,这样更自然。
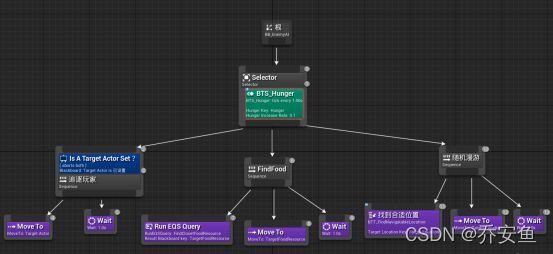
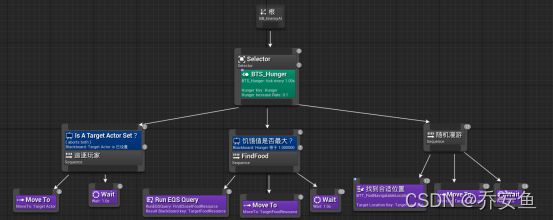
在行为树中创建一个服务,修改饥饿的黑板键>通过服务让饥饿程度上升>通过装饰器决定执行哪个序列。
A.创建饥饿黑板键
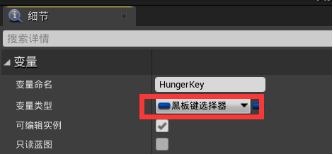
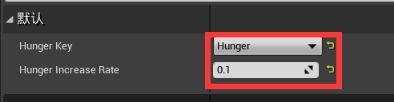
打开行为树,切换到黑板页面 - 创建一个浮点条目,起名Hunger - 在行为树页面新建服务 - 在内容管理器重命名服务为BTS_Hunger,新建文件夹Service,放入服务 - 在服务编辑器中新建一个变量HungerKey,改为公有(这样可以在其他的行为树中修改),变量类型改为BlackboardKey
![]()


B.编写饥饿服务蓝图
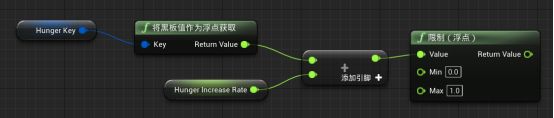
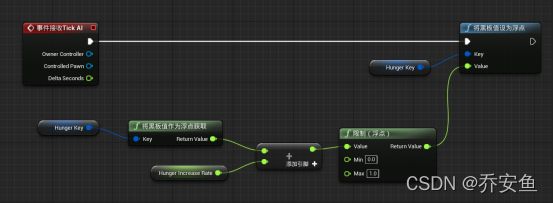
新建Event Receive Tick AI事件接收AI事件 - 按住Ctrl把HungerKey拖入事件图表 - 拖拽HungerKey引脚新建Get BlackBoard Value as Float将黑板值作为浮点数获取函数 - 拖拽Get BlackBoard Value as Float返回值新建Float+Float浮点数+浮点数,拖拽引脚提升为变量,改名为Hunger Increase Rate,改为公有 - 拖拽Float+Float新建Clamp Float限制浮点函数。
- Tick Event - 每当行为树的服务更新时,这个事件就会触发。
- 让饥饿值与递增率相加 - 表示这一帧饥饿发生了变化,限制范围0-1

把上面的值存入黑板中:
复制HungerKey - 拖拽新建Set BlackBoard Value as Float,限制浮点的返回值与其Value连接 - Event Receive Tick AI执行引脚与Set BlackBoard Value as Float执行引脚连接。
C.把服务添加到行为树
希望服务一直运行,所以要放在选择器中
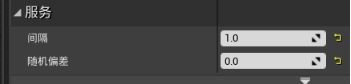
选择器>添加服务>BTS_Hunger - 细节面板中调整 - 默认分段:KEY选取Hunger,递增速率改为0.1; - 服务分段:去除随机偏差,间隔改为1。
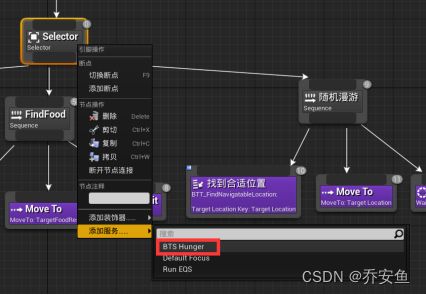
改变行为树执行顺序:
FindFood添加黑板装饰器 - Key选择Hunger,键值=1,名称改为饥饿值是否最大?
- 达到1时阻止FindFood序列
D.重置饥饿值:
当前一旦找到食物就会一直重复FindFood序列。
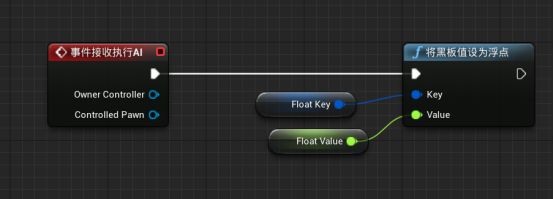
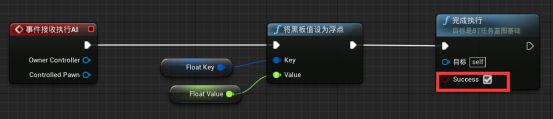
新建一个基类任务,改名为BTT_SetFloatKey,放入任务文件夹 - 在编辑器中新建变量FloatKey,设为公开。变量类型为黑板键。 - 再新建一个变量FloatValue,类型为浮点数,公开 - 新建Event Receive Execute AI事件接收执行AI事件 - 按住ctrl拖动FloatKey到蓝图中,拖拽引脚新建Set BlackBoard Value As Float - 按住ctrl拖动FloatValue到蓝图中,与Set BlackBoard Value As Float的Value连接 - Event Receive Execute AI执行引脚与Set BlackBoard Value As Float执行引脚连接 - 新建Finish Excute函数,勾选Success。Set BlackBoard Value As Float执行引脚与其相连

![]()
![]()
![]()
![]()
把新任务添加进行为树:
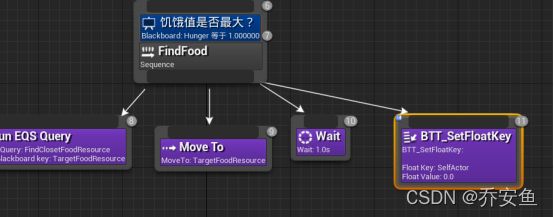
在FindFood下添加SetFloatKey任务,并把值设为0
![]()
(三)第二个EQS - 伏击
自定义情景。
a.新建一个情景用于EQS查询
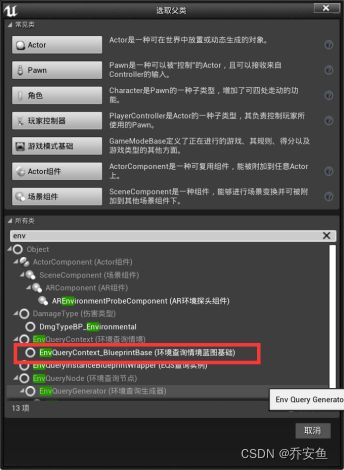
右键- 蓝图- 新建Env Query Context_BlueprintBase(环境查询情景蓝图基础),改名为EQSC_player - 在EQS文件夹中新建一个文件夹Contexts情景,把Env蓝图移入
b.创建蓝图
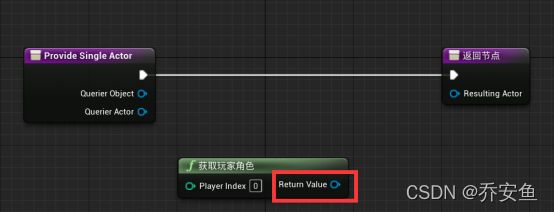
此情景的目的是找到玩家,并作为新的Actor,所以可以覆盖现有函数。
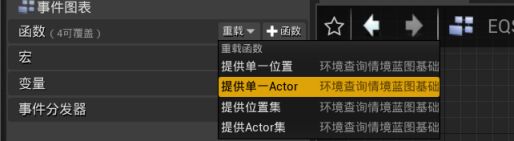
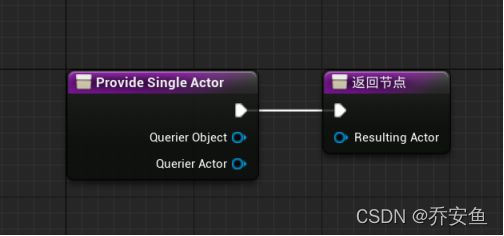
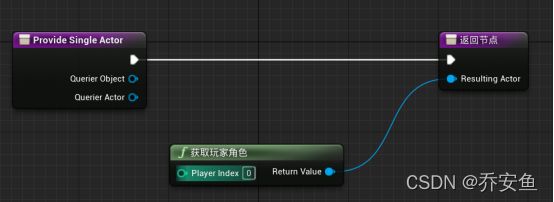
我的蓝图>函数>重载>提供单一Actor - 新建Get Player Character,返回值与Resulting Actor连接。
现在可以新建EQS查询了。
c.伏击EQS
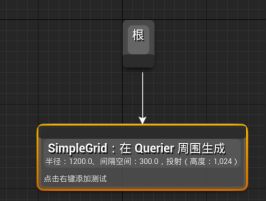
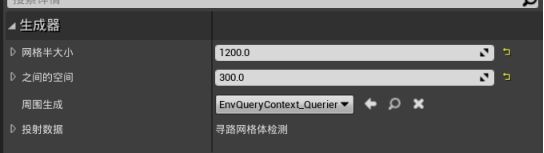
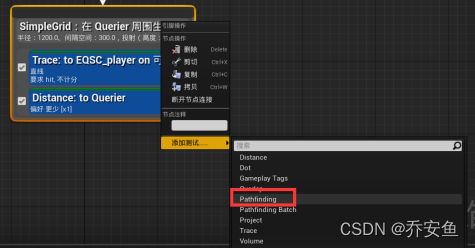
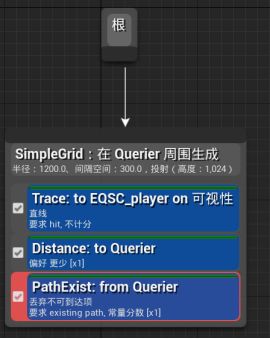
新建一个环境查询,起名EQS_HideNearPlayer - 在编辑器中拖动根节点,新建Point Grid生成器,网格大小1200,间隔300,EnvQueryContext_Querier在Querier周围生成。
- 网格点生成器原理:查询AI周边许多点作为起始点,逐渐缩小,直到一个点。更大更分散的更适合伏击行为。
移除AI会到达玩家能看到的点:
在生成器上添加测试Trace追踪 - 仅过滤(这个任务无法判断最佳点),情境选取EQSC_player
- 原理 - 会在玩家和网格点中添加一条射线,如果命中,这个点将会被移除。



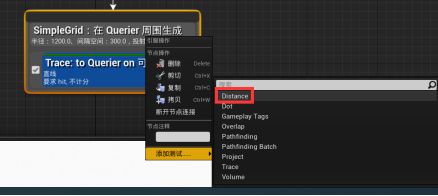
挑选离玩家最近的点:
添加Distance测试 - 仅得分,得分因子=-1


确保AI可到达位置:
得分高的点可能无法通过,筛选出能到达的点。玩家和网格体间可以生成一段导航路径。
添加PathFinding测试 - 过滤和计分 - 情境选取EnvQueryContext_Querier

![]()
d.加入行为树
追逐序列改为躲藏序列。
打开行为树 - 追逐玩家改为躲藏玩家 - 新建Run EQS Query任务并放置最左侧 - 黑板键Target Location,查询模板EQS_HideNearPlayer

![]()
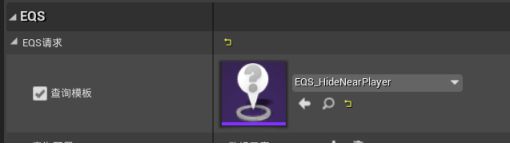
Move To任务黑板键改为Target Location
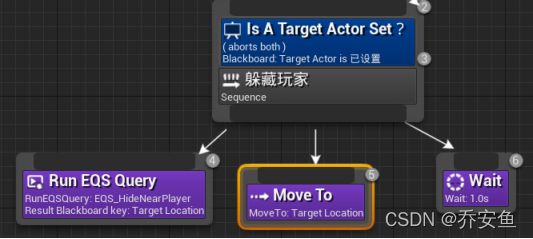
![]()
(四)EQS测试Pawn
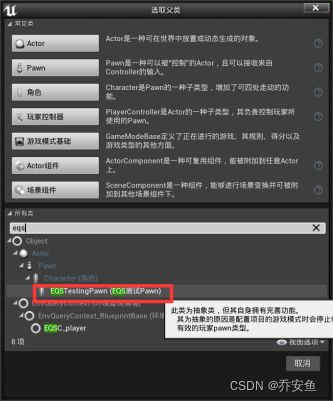
使用EQS测试Pawn可以在编辑器里快速迭代、测试查询,不需要一遍遍来运行游戏。
在EQS文件夹新建EQSTestingPawn蓝图,改名EQS_MyTestingPawn - 拖入关卡,放置在地面上 - 细节面板>EQS>查询模板,选择EQS_Find Closet Food Resource

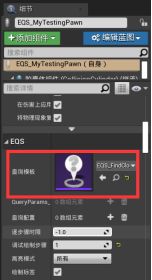
可以看到食物顶端有数字,那是EQSPawn打的分数,移动Pawn,分数会随之改变。
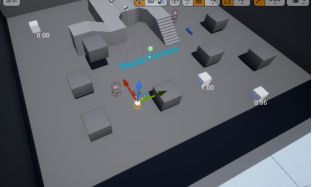
更换为EQS_HideNearPlayer,可以看到有效点太多,因为并没有开始运行游戏。修改情景为使用测试Pawn而不是玩家角色。
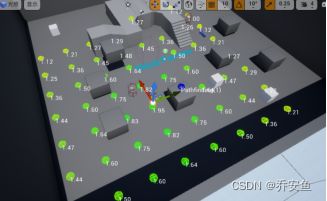
打开contexts文件夹的EQSC_playecontext蓝图 - 按住ALT点击获取玩家角色的返回值断开连接,而不删除节点。(演示结束后还要重新表示情景中的玩家角色) - 让情景表示EQS测试Pawn。因为Pawn将是查询的Actor,所以使用Provide Single Actor函数提供的引用 - 拖拽Querier Actor新建EQS_MyTestingPawn,右键纯类型转换,返回值与Resulting Actor连接。
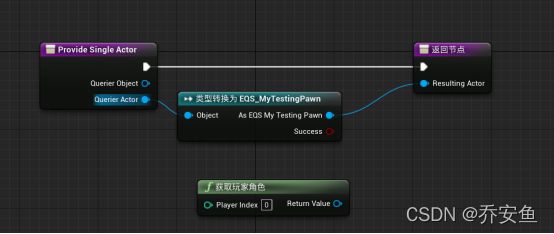
再次点击Pawn,发现网格点变化
- 蓝色 - 被追踪测试过滤掉
- 绿色 - 可伏击的点

正在查询模式换为单一最佳项目,显示最优点:
![]()

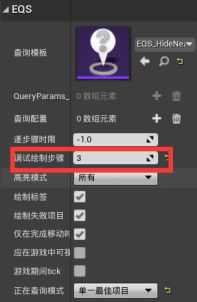
想要更多的细节,必须逐个检查每一项测试:
调试绘制步骤Step to Debug Draw - 步进数量与生成器中测试的执行顺序有关。
打开EQS_HideNearPlayer,比较每个测试和结果。

重置情景用于游戏测试:恢复EQS_PlayerContext

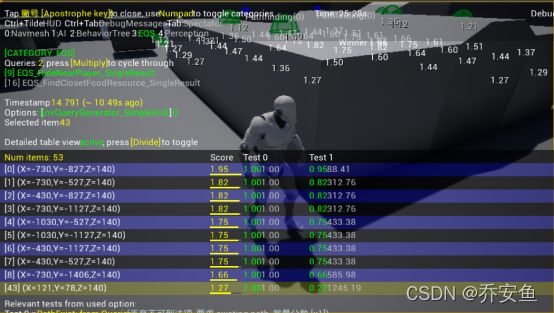
(五)EQS GamePlay调试器
如果游戏已经开始,使用Gameplay调试器,关闭AI、行为树信息,按3打开EQS信息。
按下小键盘“/”,可以看到各个得分点情况。
八、比较UE4的AI实现方式和AI理论
一 、 感知
- 导航系统 - 感知系统外的一种特殊感官。允许AI在前往位置时感知到静态障碍物。在未遇到障碍物之前还可以感知到其占据一片区域。
- 感官分类 - 任何能被AI感官系统覆盖的内容都归结于此:
- 通过感知系统添加的其他感官
二、思考
- 行为树
- 黑板
三、行动
- 行为树任务
- 移动
- 播放动画
- 发出声音
- 向其他AI发送消息
四、AI连接系统
- 行动再回到感官
- 当行为树任务完成时,会完成序列,然后重新评估装饰器。
- 注意:由于行为树和感知系统自身特性,这种基于事件的系统可以独立触发,而无需在循环中运行。
- 规划宏观任务流程时,这种方法可以把AI流程模块化
九、拓展
一、改善感官
- 为AI增加更多感官:
- 听觉
- 调整感官优先级
- 听觉
- 增强AI对环境的感知能力:
- 利用导航链接,让AI从坡道上跳下来
- 在EQS查询增加更多检测,使其更加精细:
- 为现有的隐藏点增加点积测试,让地上的点面向一个特定的方向,让AI只在玩家面前躲藏
二、改善思考
- 探索简单的视差
- 在AI向玩家移动时,是否在近战范围内
- 探索现有的装饰器类型
- 条件循环
- 冷却时间
三、改善行动
- 为AI增加一个搜索行为
- 看不到玩家时开始搜索
- 建立一个简单的巡逻系统
- 创建单独的巡逻对象,它们保存着各处场景的点的信息,让AI用它们查找下一个点