TensorFlow+FaceNet+训练模型
TensorFlow+FaceNet+训练模型
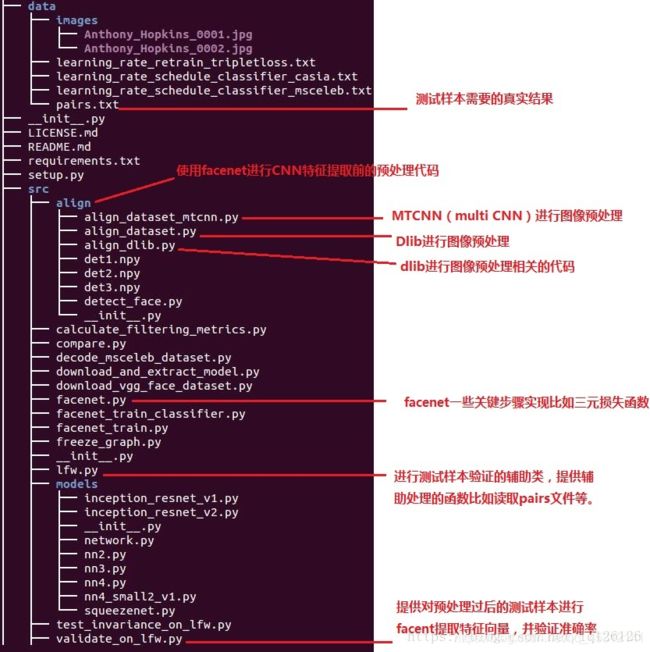
- 1、目录结构介绍
-
- 1.1、faceNet简介
- 2、模型准备
-
- 2.1、下载FaceNet源码
- 2.2、下载预训练模型
- 配置环境法1
-
- 2.3、数据预处理(align_dataset_mtcnn.py)
- 2.4、运行人脸比对程序(compare.py)
- 2.5、从新训练模型
1、目录结构介绍
1.1、faceNet简介
FaceNet是Google提出的用于人脸识别(recognition,k-NN),验证(verification, two persons),聚类(clustering, find common people among these faces)。与用于分类的神经网络(MobileNet、GoogleNet、VGG16/19、ResNet等)不同的是FaceNet选择了一种更直接的端到端的学习和分类方式,同时生成更少的参数量。

输入 Batch,有一个提取特征的深度神经网络(论文中用的是ZF-Net和Inceptio),然后对网络提取到的特征做 L2-normalization,之后通过embedding编码生成128d的向量,优化三元组损失函数得到最优模型。
![]()
总体流程:
- 一组图像通过分类模型(如论文中提到的ZFNet、Inception V1)提取特征。
- 将提取到的特征进行L2 normalize,得到embedding结果(即一张图片使用128维向量表示)
- 将得到的embedding结果作为输入,计算triplet loss。
- l2 normalize.参考tf.nn.l2_normalize方法的实现。
- output = x / sqrt(max(sum(x**2), epsilon))
漏了一个文件件介绍就是models,这个文件夹下面放的是facent采用的CNN卷积中不同网络结构的不同实现代码比如Inception-ResNet-v1.
2、模型准备
2.1、下载FaceNet源码
下载地址:facenet源码
-
Triplet loss training
目标:使用 Triplet loss 训练模型。
步骤: -
安装 TensorFlow。
-
下载 davidsandberg/facenet 并设置 Python Paths。
-
准备训练数据,包括下载数据、Face alignment(使用 align_dataset_mtcnn.py)。
-
使用 train_tripletloss.py 训练。
-
在 TensorBoard 上查看训练过程。
- MTCNN部分:用于人脸检测和人脸对齐,输出160×160大小的图像;
- CNN部分:可以直接将人脸图像(默认输入是160×160)映射到欧几里得空间,空间距离的长度代表了人脸图像的相似性。只要该映射空间生成、人脸识别,验证和聚类等任务就可以轻松完成;
2.2、下载预训练模型
facenet提供了两个预训练模型,分别是基于CASIA-WebFace和MS-Celeb-1M人脸库训练的,不过需要去谷歌网盘下载,这里给其中一个模型的百度网盘的链接:链接百度网盘地址密码: 12mh

- model.meta:模型文件,该文件保存了metagraph信息,即计算图的结构;
- model.ckpt.data:权重文件,该文件保存了graph中所有遍历的数据;
- model.ckpt.index:该文件保存了如何将meta和data匹配起来的信息;
- pb文件:将模型文件和权重文件整合合并为一个文件,主要用途是便于发布,详细内容可以参考博客https://blog.csdn.net/yjl9122/article/details/78341689
- 一般情况下还会有个checkpoint文件,用于保存文件的绝对路径,告诉TF最新的检查点文件(也就是上图中后三个文件)是哪个,保存在哪里,在使用tf.train.latest_checkpoint加载的时候要用到这个信息,但是如果改变或者删除了文件中保存的路径,那么加载的时候会出错,找不到文件;
配置环境法1
将facebet文件夹加到python引入库的默认搜索路径中,将facenet文件整个复制到anaconda3安装文件目录下lib\site-packages下:
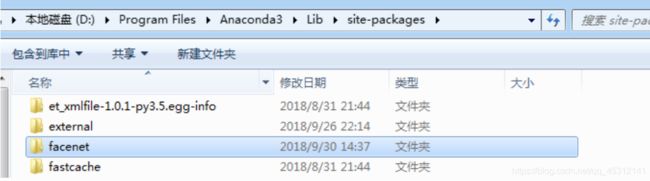
然后把剪切src目录下的文件,然后删除facenet下的所有文件,粘贴src目录下的文件到facenet下,这样做的目的是为了导入src目录下的包(这样import align.detect_face不会报错)。
在Anaconda Prompt中运行python,输入import facenet,不报错即可:

https://blog.csdn.net/xingwei_09/article/details/79161931
https://www.cnblogs.com/zyly/p/9703614.html
2.3、数据预处理(align_dataset_mtcnn.py)
MTCNN的实现主要在文件夹src/align中,文件夹的内容如下:
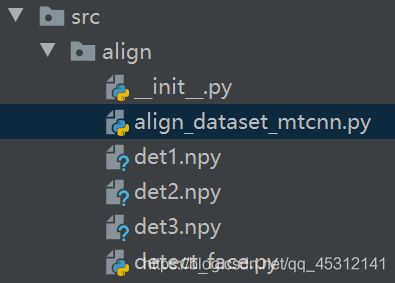
- detect_face.py:定义了MTCNN的模型结构,由P-Net、R-Net、O-Net组成,这三个网络已经提供了预训练的模型,模型数据分别对应文件det1.npy、det2.npy、det3.npy。
- align_dataset_matcnn.py:是使用MTCNN的模型进行人脸检测和对齐的入口代码
使用脚本align_dataset_mtcnn.py对LFW数据库进行人脸检测和对齐的方法通过在jupyter notebook中运行如下代码:
run src/align/align_dataset_mtcnn.py \
datasets/lfw/raw \
datasets/lfw/lfw_mtcnnpy_160 \
--image_size 160 --margin 32 \
--random_order
如果是在anaconda prompt中运行,将run改为python。
该命令会创建一个datasets/lfw/lfw_mtcnnpy_160的文件夹,并将所有对齐好的人脸图像存放到这个文件夹中,数据的结构和原先的datasets/lfw/raw一样。参数–image_size 160 --margin 32的含义是在MTCNN检测得到的人脸框的基础上缩小32像素(训练时使用的数据偏大),并缩放到160×160大小,因此最后得到的对齐后的图像都是160×160像素的,这样的话,就成功地从原始图像中检测并对齐了人脸。
"""Performs face alignment and stores face thumbnails in the output directory."""
# MIT License
#
# Copyright (c) 2016 David Sandberg
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from scipy import misc
import sys
import os
import argparse
import tensorflow as tf
import numpy as np
import facenet
import align.detect_face
import random
from time import sleep
#args:参数,关键字参数
def main(args):
sleep(random.random())
#设置对齐后的人脸图像存放的路径
output_dir = os.path.expanduser(args.output_dir)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Store some git revision info in a text file in the log directory保存一些配置参数等信息
src_path, _ = os.path.split(os.path.realpath(__file__))
facenet.store_revision_info(src_path, output_dir, ' '.join(sys.argv))
#获取lfw数据集 获取每个类别名称以及该类别下所有图片的绝对路径
dataset = facenet.get_dataset(args.input_dir)
print('Creating networks and loading parameters')
#建立MTCNN网络,并预训练(即使用训练好的网络初始化参数)
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=args.gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)
minsize = 20 # minimum size of face
threshold = [0.6, 0.7, 0.7] # three steps's threshold
factor = 0.709 # scale factor
# Add a random key to the filename to allow alignment using multiple processes
random_key = np.random.randint(0, high=99999)
bounding_boxes_filename = os.path.join(output_dir, 'bounding_boxes_%05d.txt' % random_key)
#每个图片中人脸所在的边界框写入记录文件中
with open(bounding_boxes_filename, "w") as text_file:
nrof_images_total = 0
nrof_successfully_aligned = 0
if args.random_order:
random.shuffle(dataset)
#获取每一个人,以及对应的所有图片的绝对路径
for cls in datase
#每一个人对应的输出文件夹
output_class_dir = os.path.join(output_dir, cls.name)
if not os.path.exists(output_class_dir):
os.makedirs(output_class_dir)
if args.random_order:
random.shuffle(cls.image_paths)
#遍历每一张图片
for image_path in cls.image_paths:
nrof_images_total += 1
filename = os.path.splitext(os.path.split(image_path)[1])[0]
output_filename = os.path.join(output_class_dir, filename + '.png')
print(image_path)
if not os.path.exists(output_filename):
try:
img = misc.imread(image_path)
except (IOError, ValueError, IndexError) as e:
errorMessage = '{}: {}'.format(image_path, e)
print(errorMessage)
else:
if img.ndim < 2:
print('Unable to align "%s"' % image_path)
text_file.write('%s\n' % (output_filename))
continue
if img.ndim == 2:
img = facenet.to_rgb(img)
img = img[:, :, 0:3]
#人脸检测,bounding_boxes表示边界框,形状为[n,5],5对应x1,y1,x2,y2,score
#人脸关键点坐标形状为[n,10],左右眼、鼻子、左右嘴角五个位置,每个位置对应一个x和y所以有10个参数
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
#边界框个数
nrof_faces = bounding_boxes.shape[0]
if nrof_faces > 0:
#【n,4】人脸框
det = bounding_boxes[:, 0:4]
img_size = np.asarray(img.shape)[0:2]
if nrof_faces > 1:
#一张图片中检测多个人脸
bounding_box_size = (det[:, 2] - det[:, 0]) * (det[:, 3] - det[:, 1])
img_center = img_size / 2
offsets = np.vstack([(det[:, 0] + det[:, 2]) / 2 - img_center[1], (det[:, 1] + det[:, 3]) / 2 - img_center[0]])
offset_dist_squared = np.sum(np.power(offsets, 2.0), 0)
index = np.argmax(bounding_box_size - offset_dist_squared * 2.0) # some extra weight on the centering
det = det[index, :]
det = np.squeeze(det)
bb = np.zeros(4, dtype=np.int32)
#边界框缩小margin区域,并进行裁切后缩放到统一尺寸
bb[0] = np.maximum(det[0] - args.margin / 2, 0)
bb[1] = np.maximum(det[1] - args.margin / 2, 0)
bb[2] = np.minimum(det[2] + args.margin / 2, img_size[1])
bb[3] = np.minimum(det[3] + args.margin / 2, img_size[0])
#print(bb)
cropped = img[bb[1]:bb[3], bb[0]:bb[2], :]
scaled = misc.imresize(cropped, (args.image_size, args.image_size), interp='bilinear')
nrof_successfully_aligned += 1
misc.imsave(output_filename, scaled)
text_file.write('%s %d %d %d %d\n' % (output_filename, bb[0], bb[1], bb[2], bb[3]))
else:
print('Unable to align "%s"' % image_path)
text_file.write('%s\n' % (output_filename))
print('Total number of images: %d' % nrof_images_total)
print('Number of successfully aligned images: %d' % nrof_successfully_aligned)
def parse_arguments(argv):
#解析命令行参数
parser = argparse.ArgumentParser()
#定义参数 input_dir、output_dir为外部参数名
parser.add_argument('input_dir', type=str, help='Directory with unaligned images.')
parser.add_argument('output_dir', type=str, help='Directory with aligned face thumbnails.')
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=182)
parser.add_argument('--margin', type=int,
help='Margin for the crop around the bounding box (height, width) in pixels.', default=44)
parser.add_argument('--random_order',
help='Shuffles the order of images to enable alignment using multiple processes.', action='store_true')
parser.add_argument('--gpu_memory_fraction', type=float,
help='Upper bound on the amount of GPU memory that will be used by the process.', default=1.0)
#解析
return parser.parse_args(argv)
if __name__ == '__main__':
main(parse_arguments(sys.argv[1:]))
调用align.detect_face.detect_face()函数进行人脸检测,返回校准后的人脸边界框的位置、score、以及关键点坐标;
对人脸框进行处理,从原图中裁切(先进行了边缘扩展32个像素)、以及缩放(缩放到160×160 )等,并保存相关信息到文件
def detect_face(img, minsize, pnet, rnet, onet, threshold, factor):
# im: input image
# minsize: minimum of faces' size
# pnet, rnet, onet: caffemodel
# threshold: threshold=[th1 th2 th3], th1-3 are three steps's threshold
# fastresize: resize img from last scale (using in high-resolution images) if fastresize==true
factor_count=0
total_boxes=np.empty((0,9))
points=[]
h=img.shape[0]
w=img.shape[1]
#最小值 假设是250x250
minl=np.amin([h, w])
#假设最小人脸 minsize=20,由于我们P-Net人脸检测窗口大小为12x12,
#因此必须缩放才能使得检测窗口检测到完整的人脸 m=0.6
m=12.0/minsize
minl=minl*m
# creat scale pyramid不同尺度金字塔,保存每个尺度缩放尺度系数0.6 0.6*0.7 ...
scales=[]
while minl>=12:
scales += [m*np.power(factor, factor_count)]
minl = minl*factor
factor_count += 1
# first stage
for j in range(len(scales)):
#缩放图像
scale=scales[j]
hs=int(np.ceil(h*scale))
ws=int(np.ceil(w*scale))
#归一化【-1,1】之间
im_data = imresample(img, (hs, ws))
im_data = (im_data-127.5)*0.0078125
img_x = np.expand_dims(im_data, 0)
img_y = np.transpose(img_x, (0,2,1,3))
out = pnet(img_y)
out0 = np.transpose(out[0], (0,2,1,3))
out1 = np.transpose(out[1], (0,2,1,3))
#输出为【n,9】前4位为人脸框在原图中的位置,第5位为判断为人脸的概率,后4位为框回归的值
boxes, _ = generateBoundingBox(out1[0,:,:,1].copy(), out0[0,:,:,:].copy(), scale, threshold[0])
# inter-scale nms非极大值抑制,然后保存剩下的bb
pick = nms(boxes.copy(), 0.5, 'Union')
if boxes.size>0 and pick.size>0:
boxes = boxes[pick,:]
total_boxes = np.append(total_boxes, boxes, axis=0)
#图片按照所有scale走完一遍,会得到在原图上基于不同scale的所有bb,然后对这些bb再进行一次NMS
#并且这次的NMS的threshold要提高
numbox = total_boxes.shape[0]
if numbox>0:
pick = nms(total_boxes.copy(), 0.7, 'Union')
total_boxes = total_boxes[pick,:]
#使用回归框校准bb,框回归:框左上角的横坐标的相对偏移、框左上角的纵坐标的相对偏移、框的宽度的误差、框的高度的误差
regw = total_boxes[:,2]-total_boxes[:,0]
regh = total_boxes[:,3]-total_boxes[:,1]
qq1 = total_boxes[:,0]+total_boxes[:,5]*regw
qq2 = total_boxes[:,1]+total_boxes[:,6]*regh
qq3 = total_boxes[:,2]+total_boxes[:,7]*regw
qq4 = total_boxes[:,3]+total_boxes[:,8]*regh
#【n,8】
total_boxes = np.transpose(np.vstack([qq1, qq2, qq3, qq4, total_boxes[:,4]]))
#把每一个bb转换为正方形
total_boxes = rerec(total_boxes.copy())
total_boxes[:,0:4] = np.fix(total_boxes[:,0:4]).astype(np.int32)
#把超过原图边界的坐标裁切以下,这时得到真正原图上bb(bounding box)的坐标
dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph = pad(total_boxes.copy(), w, h)
numbox = total_boxes.shape[0]
if numbox>0:
# second stage R-NET对于P-NET输出的bb,缩放到24x24
tempimg = np.zeros((24,24,3,numbox))
for k in range(0,numbox):
tmp = np.zeros((int(tmph[k]),int(tmpw[k]),3))
tmp[dy[k]-1:edy[k],dx[k]-1:edx[k],:] = img[y[k]-1:ey[k],x[k]-1:ex[k],:]
if tmp.shape[0]>0 and tmp.shape[1]>0 or tmp.shape[0]==0 and tmp.shape[1]==0:
tempimg[:,:,:,k] = imresample(tmp, (24, 24))
else:
return np.empty()
#标准化【-1,1】
tempimg = (tempimg-127.5)*0.0078125
#转置【n,24,24,3】
tempimg1 = np.transpose(tempimg, (3,1,0,2))
out = rnet(tempimg1)
out0 = np.transpose(out[0])
out1 = np.transpose(out[1])
score = out1[1,:]
ipass = np.where(score>threshold[1])
total_boxes = np.hstack([total_boxes[ipass[0],0:4].copy(), np.expand_dims(score[ipass].copy(),1)])
mv = out0[:,ipass[0]]
if total_boxes.shape[0]>0:
pick = nms(total_boxes, 0.7, 'Union')
total_boxes = total_boxes[pick,:]
total_boxes = bbreg(total_boxes.copy(), np.transpose(mv[:,pick]))
total_boxes = rerec(total_boxes.copy())
numbox = total_boxes.shape[0]
if numbox>0:
# third stage
total_boxes = np.fix(total_boxes).astype(np.int32)
dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph = pad(total_boxes.copy(), w, h)
tempimg = np.zeros((48,48,3,numbox))
for k in range(0,numbox):
tmp = np.zeros((int(tmph[k]),int(tmpw[k]),3))
tmp[dy[k]-1:edy[k],dx[k]-1:edx[k],:] = img[y[k]-1:ey[k],x[k]-1:ex[k],:]
if tmp.shape[0]>0 and tmp.shape[1]>0 or tmp.shape[0]==0 and tmp.shape[1]==0:
tempimg[:,:,:,k] = imresample(tmp, (48, 48))
else:
return np.empty()
tempimg = (tempimg-127.5)*0.0078125
tempimg1 = np.transpose(tempimg, (3,1,0,2))
out = onet(tempimg1)
#关键点
out0 = np.transpose(out[0])
#框回归
out1 = np.transpose(out[1])
#人脸概率
out2 = np.transpose(out[2])
score = out2[1,:]
points = out1
ipass = np.where(score>threshold[2])
points = points[:,ipass[0]]
#[n,5]
total_boxes = np.hstack([total_boxes[ipass[0],0:4].copy(), np.expand_dims(score[ipass].copy(),1)])
mv = out0[:,ipass[0]]
w = total_boxes[:,2]-total_boxes[:,0]+1
h = total_boxes[:,3]-total_boxes[:,1]+1
#人脸关键点
points[0:5,:] = np.tile(w,(5, 1))*points[0:5,:] + np.tile(total_boxes[:,0],(5, 1))-1
points[5:10,:] = np.tile(h,(5, 1))*points[5:10,:] + np.tile(total_boxes[:,1],(5, 1))-1
if total_boxes.shape[0]>0:
total_boxes = bbreg(total_boxes.copy(), np.transpose(mv))
pick = nms(total_boxes.copy(), 0.7, 'Min')
total_boxes = total_boxes[pick,:]
points = points[:,pick]
#返回bb:[n,5]x1,y1,x2,y2,score,和关键点[n,10]
return total_boxes, points
到这里、我们的准备工作已经基本完成,测试数据集LFW,模型、程序都有了,我们接下来开始评估模型的准确率。
run src/validate_on_lfw.py \
datasets/lfw/lfw_mtcnnpy_160 \
models/facenet/model-20170512-110547/
2.4、运行人脸比对程序(compare.py)
在自己的数据上使用已有的模型
run src/compare.py \
models/facenet/model-20170512-110547/ \
test_imgs/1.jpg test_imgs/2.jpg test_imgs/3.jpg
facenet可以直接比对两个人脸经过它的网络映射之后的欧氏距离
compare.py源码如下:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from scipy import misc
import tensorflow as tf
import numpy as np
import sys
import os
import argparse
import facenet
import align.detect_face
def main(args):
images = load_and_align_data(args.image_files, args.image_size, args.margin, args.gpu_memory_fraction)
with tf.Graph().as_default():
with tf.Session() as sess:
# 载入模型
facenet.load_model(args.model)
# images_placeholder是输入图像的占位符,后面把image传给它
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
#embeddings是卷积网络最后输出的特征
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
#phase_train_placeholder占位符决定了现在是不是训练阶段
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
# 计算特征
feed_dict = {images_placeholder: images, phase_train_placeholder: False}
emb = sess.run(embeddings, feed_dict=feed_dict)
#print(emb)#可将计算的特征打印出来,facenet提取出的特征是128维的
#nrof_images是图片总数目
nrof_images = len(args.image_files)
#简单地打印图片名称
print('Images:')
for i in range(nrof_images):
print('%1d: %s' % (i, args.image_files[i]))
print('')
# 打印距离矩阵
print('Distance matrix')
print(' ', end='')
for i in range(nrof_images):
print(' %1d ' % i, end='')
print('')
for i in range(nrof_images):
print('%1d ' % i, end='')
for j in range(nrof_images):
dist = np.sqrt(np.sum(np.square(np.subtract(emb[i, :], emb[j, :]))))
print(' %1.4f ' % dist, end='')
print('')
def load_and_align_data(image_paths, image_size, margin, gpu_memory_fraction):
minsize = 20 # minimum size of face
threshold = [0.6, 0.7, 0.7] # three steps's threshold
factor = 0.709 # scale factor
print('Creating networks and loading parameters')
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)
#nrof_samples是图片总数目,image_paths存储了这些图片的路径
nrof_samples = len(image_paths)
#img_list中存储了对齐后的图像
img_list = [None] * nrof_samples
for i in range(nrof_samples):
#读入图像
img = misc.imread(os.path.expanduser(image_paths[i]))
img_size = np.asarray(img.shape)[0:2]
#使用P-NET,R-NET,O-NET,即MTCNN检测并对齐图像,检测的结果存入bounding_boxes
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
#对于检测出的bounding_boxes,减去margin(在MTCNN检测得到的人脸框的基础上缩小32像素(训练时使用的数据偏大))
det = np.squeeze(bounding_boxes[0, 0:4])
bb = np.zeros(4, dtype=np.int32)
bb[0] = np.maximum(det[0] - margin / 2, 0)
bb[1] = np.maximum(det[1] - margin / 2, 0)
bb[2] = np.minimum(det[2] + margin / 2, img_size[1])
bb[3] = np.minimum(det[3] + margin / 2, img_size[0])
#裁剪出人脸区域,并缩放到卷积神经网络输入的大小
cropped = img[bb[1]:bb[3], bb[0]:bb[2], :]
aligned = misc.imresize(cropped, (image_size, image_size), interp='bilinear')
prewhitened = facenet.prewhiten(aligned)
img_list[i] = prewhitened
images = np.stack(img_list)
return images
def parse_arguments(argv):
parser = argparse.ArgumentParser()
parser.add_argument('model', type=str,
help='Could be either a directory containing the meta_file and ckpt_file or a model protobuf (.pb) file')
parser.add_argument('image_files', type=str, nargs='+', help='Images to compare')
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=160)
parser.add_argument('--margin', type=int,
help='Margin for the crop around the bounding box (height, width) in pixels.', default=44)
parser.add_argument('--gpu_memory_fraction', type=float,
help='Upper bound on the amount of GPU memory that will be used by the process.', default=1.0)
return parser.parse_args(argv)
if __name__ == '__main__':
main(parse_arguments(sys.argv[1:]))
- 首先使用MTCNN网络对原始测试图片进行检测和对齐,即得到[n,160,160,3]的输出;
- 从模型文件(meta,ckpt文件)中加载facenet网络;
- 把处理后的测试图片输入网络,得到每个图像的特征,对特征计算两两之间的距离以得到人脸之间的相似度;
2.5、从新训练模型
从头训练一个新模型需要非常多的数据集,这里我们以CASIA-WebFace为例,这个 dataset 在原始地址已经下载不到了,而且这个 dataset 据说有很多无效的图片,所以这里我们使用的是清理过的数据库。该数据库可以在百度网盘有下载:下载地址,提取密码为 3zbb
这个数据库有 10575 个类别494414张图像,每个类别都有各自的文件夹,里面有同一个人的几张或者几十张不等的脸部图片。我们先利用MTCNN 从这些照片中把人物的脸框出来,然后交给下面的 Facenet 去训练。
下载好之后,解压到datasets/casia/raw目录下
其中每个文件夹代表一个人,文件夹保存这个人的所有人脸图片。与LFW数据集类似,我们先利用MTCNN对原始图像进行人脸检测和对齐
run src/align/align_dataset_mtcnn.py \
datasets/casia/raw \
datasets/casia/casia_maxpy_mtcnnpy_182 \
--image_size 182 --margin 44 \
对齐后的图像保存在路径datasets/casia/casia_maxpy_mtcnnpy_182下,每张图像的大小都是182×182。而最终网络的输入是160×160,之所以先生成182×182的图像,是为了留出一定的空间给数据增强的裁切环节。我们会在182×182的图像上随机裁切出160×160的区域,再送入神经网络进行训练。
运行如下命令进行训练
train_softmax.py 或train_tripletloss.py
run src/train_softmax.py \
--logs_base_dir logs/facenet/ \
--models_base_dir models/facenet/ \
--data_dir datasets/casia/casia_maxpy_mtcnnpy_182 \
--image_size 160 \
--model_def models.inception_resnet_v1 \
--lfw_dir datasets/lfw/lfw_mtcnnpy_160 \
--optimizer RMSPROP \
--learning_rate -1 \
--max_nrof_epochs 80 \
--keep_probability 0.8 \
--random_crop --random_flip \
--learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt \
--weight_decay 5e-5 \
--center_loss_factor 1e-2 \
--center_loss_alfa 0.9
上面命令中有很多参数,我们来一一介绍。首先是文件src/train_softmax.py文件,它采用中心损失和softmax损失结合来训练模型,其中参数如下:
也就是说一开始一直使用0.1作为
- logs_base_dir./logs:将会把训练日志保存到./logs中,在运行时,会在./logs文件夹下新建一个以当前时间命名的文讲夹。最终的日志会保存在这个文件夹中,所谓的日志文件,实际上指的是tf中的events文件,它主要包含当前损失、当前训练步数、当前学习率等信息。后面我们会使用TensorBoard查看这些信息;
- –models_base_dir ./models:最终训练好的模型保存在./models文件夹下,在运行时,会在./models文件夹下新建一个以当前时间命名的文讲夹,并用来保存训练好的模型;
- data_dir …/datasets/casis/casia_maxpy_mtcnnpy_182:指定训练所使用的数据集的路径,这里使用的就是刚才对齐好的CASIA-WebFace人脸数据;
- image_size 160:输入网络的图片尺寸是160×160大小;
- mode_def models.inception_resnet_v1:指定了训练所使用的卷积网络是inception_resnet_v1网络。项目所支持的网络在src/models目录下,包含inception_resnet_v1,inception_resnet_v2和squeezenet三个模型,前两个模型较大,最后一个模型较小。如果在训练时出现内存或者显存不足的情况可以尝试使用sequeezenet网络,也可以修改batch_size 大小为32或者64(默认是90);
- lfw_dir …/datasets/lfw/lfw_mtcnnpy_160:指定了LFW数据集的路径。如果指定了这个参数,那么每训练完一个epoch,就会在LFW数据集上执行一次测试,并将测试的准确率写入到日志文件中;
- optimizer RMSPROP :指定训练使用的优化方法;
- learning_rate -1:指定学习率,指定了负数表示忽略这个参数,而使用后面的–learning_rate_schedule_file参数规划学习率;
- max_nrof_epochs 80:指定训练轮数epoch;
- keep_probability 0.8:在全连接层,加入dropout,这个参数表示dropout中连接被保持的概率。
- random_crop:表明在数据增强时使用随机裁切;
- random_flip :表明在数据增强时使用随机翻转;
- learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt:在之前指定了–learning_rate -1,因此最终的学习率将由参数–learning_rate_schedule_file决定。这个参数指定一个文件data/learning_rate_schedule_classifier_casia.txt,该文件内容如下:
# Learning rate schedule
# Maps an epoch number to a learning rate
0: 0.05
60: 0.005
80: 0.0005
91: -1
- weight_decay 5e-5:正则化系数;
- center_loss_factor 1e-2 :中心损失和Softmax损失的平衡系数;
- center_loss_alfa 0.9:中心损失的内部参数;
除了上面我们使用到的参数,还有许多参数,下面介绍一些比较重要的:
- pretrained_model :models/20180408-102900 预训练模型,使用预训练模型可以加快训练速度(微调时经常使用到);
- batch_size:batch大小,越大,需要的内存也会越大;
- random_rotate:表明在数据增强时使用随机旋转;
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
import os.path
import time
import sys
import tensorflow as tf
import numpy as np
import importlib
import itertools
import argparse
import facenet
import lfw
from tensorflow.python.ops import data_flow_ops
from six.moves import xrange # @UnresolvedImport
def main(args):
# 载入网络结构
network = importlib.import_module(args.model_def)
# 为本次运行新建日志目录与模型目录
subdir = datetime.strftime(datetime.now(), '%Y%m%d-%H%M%S')
log_dir = os.path.join(os.path.expanduser(args.logs_base_dir), subdir)
if not os.path.isdir(log_dir): # Create the log directory if it doesn't exist
os.makedirs(log_dir)
#新建保存模型的文件夹
model_dir = os.path.join(os.path.expanduser(args.models_base_dir), subdir)
if not os.path.isdir(model_dir): # Create the model directory if it doesn't exist
os.makedirs(model_dir)
# Write arguments to a text file
# 保存输入参数信息
facenet.write_arguments_to_file(args, os.path.join(log_dir, 'arguments.txt'))
# Store some git revision info in a text file in the log directory
# 保存git相关信息
src_path,_ = os.path.split(os.path.realpath(__file__))
facenet.store_revision_info(src_path, log_dir, ' '.join(sys.argv))
# 获取数据集
# PS:要求数据集按照给定规则存放
np.random.seed(seed=args.seed)
# 获取数据集,通过get_dataset获取的train_set是包含文件路径与标签的集合
train_set = facenet.get_dataset(args.data_dir)
# pre-trained model 路径
print('Model directory: %s' % model_dir)
print('Log directory: %s' % log_dir)
if args.pretrained_model:
print('Pre-trained model: %s' % os.path.expanduser(args.pretrained_model))
# lfw 测试集
if args.lfw_dir:
print('LFW directory: %s' % args.lfw_dir)
# Read the file containing the pairs used for testing
pairs = lfw.read_pairs(os.path.expanduser(args.lfw_pairs))
# Get the paths for the corresponding images
lfw_paths, actual_issame = lfw.get_paths(os.path.expanduser(args.lfw_dir), pairs)
# 建立图运行上下文
with tf.Graph().as_default():
tf.set_random_seed(args.seed)
global_step = tf.Variable(0, trainable=False)
# Placeholder for the learning rate
# 创建各种 placeholder
learning_rate_placeholder = tf.placeholder(tf.float32, name='learning_rate')
batch_size_placeholder = tf.placeholder(tf.int32, name='batch_size')
phase_train_placeholder = tf.placeholder(tf.bool, name='phase_train')
# 为什么 shape 是 (None, 3) ?因为使用了 triplet loss,输入需要3张图片
image_paths_placeholder = tf.placeholder(tf.string, shape=(None,3), name='image_paths')
labels_placeholder = tf.placeholder(tf.int64, shape=(None,3), name='labels')
# 数据集准备
#新建一个队列,数据流操作,fifo,先入先出
input_queue = data_flow_ops.FIFOQueue(capacity=100000,
dtypes=[tf.string, tf.int64],
shapes=[(3,), (3,)],
shared_name=None, name=None)
# 文件名入队操作
# enqueue_many返回的是一个操作
enqueue_op = input_queue.enqueue_many([image_paths_placeholder, labels_placeholder])
# 读取队列中数据,经过一系列转换(读取图片、切片、水平镜像、reshape)
# 得到的结果是[images, label],其中images的shape为(3, image_size, image_size, 3), label的shape为(3,)
nrof_preprocess_threads = 4
images_and_labels = []
for _ in range(nrof_preprocess_threads):
filenames, label = input_queue.dequeue()
images = []
for filename in tf.unstack(filenames):
file_contents = tf.read_file(filename)
image = tf.image.decode_image(file_contents, channels=3)
if args.random_crop:
image = tf.random_crop(image, [args.image_size, args.image_size, 3])
else:
image = tf.image.resize_image_with_crop_or_pad(image, args.image_size, args.image_size)
if args.random_flip:
image = tf.image.random_flip_left_right(image)
#pylint: disable=no-member
image.set_shape((args.image_size, args.image_size, 3))
images.append(tf.image.per_image_standardization(image))
images_and_labels.append([images, label])
# 由于 enqueue_many=True
# 因此输入队列 images_and_labels 中的每个元素,即[images, label]也会根据axis=0的切分为多条数据
# image_batch 的 shape 为 (batch_size, image_size, image_size, 3)
# labels_batch 的 shape 为 (batch_size)
image_batch, labels_batch = tf.train.batch_join(
images_and_labels, batch_size=batch_size_placeholder,
shapes=[(args.image_size, args.image_size, 3), ()], enqueue_many=True,
capacity=4 * nrof_preprocess_threads * args.batch_size,
allow_smaller_final_batch=True)
image_batch = tf.identity(image_batch, 'image_batch')
image_batch = tf.identity(image_batch, 'input')
labels_batch = tf.identity(labels_batch, 'label_batch')
# Build the inference graph
# 将图片转换为长度为128的向量,并进行l2 normalize操作
# 创建网络图:除了全连接层和损失层
prelogits, _ = network.inference(image_batch, args.keep_probability,
phase_train=phase_train_placeholder, bottleneck_layer_size=args.embedding_size,
weight_decay=args.weight_decay)
embeddings = tf.nn.l2_normalize(prelogits, 1, 1e-10, name='embeddings')
# Split embeddings into anchor, positive and negative and calculate triplet loss
# 获取triplet输入数据,并计算损失函数
anchor, positive, negative = tf.unstack(tf.reshape(embeddings, [-1,3,args.embedding_size]), 3, 1)
triplet_loss = facenet.triplet_loss(anchor, positive, negative, args.alpha)
# 获取学习率
# 将指数衰减应用到学习率上
learning_rate = tf.train.exponential_decay(learning_rate_placeholder, global_step,
args.learning_rate_decay_epochs*args.epoch_size, args.learning_rate_decay_factor, staircase=True)
# saver summary相关
tf.summary.scalar('learning_rate', learning_rate)
# Calculate the total losses
# 根据REGULARIZATION_LOSSES返回一个收集器中所收集的值的列表
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# 我们选择L2-正则化来实现这一点,L2正则化将网络中所有权重的平方和加到损失函数。如果模型使用大权重,则对应重罚分,并且如果模型使用小权重,则小罚分。
# 这就是为什么我们在定义权重时使用了regularizer参数,并为它分配了一个l2_regularizer。这告诉了TensorFlow要跟踪
# l2_regularizer这个变量的L2正则化项(并通过参数reg_constant对它们进行加权)。
# 所有正则化项被添加到一个损失函数可以访问的集合——tf.GraphKeys.REGULARIZATION_LOSSES。
# 将所有正则化损失的总和与先前计算的triplet_loss相加,以得到我们的模型的总损失。
total_loss = tf.add_n([triplet_loss] + regularization_losses, name='total_loss')
# Build a Graph that trains the model with one batch of examples and updates the model parameters
train_op = facenet.train(total_loss, global_step, args.optimizer,
learning_rate, args.moving_average_decay, tf.global_variables())
# Create a saver
# saver summary相关
saver = tf.train.Saver(tf.trainable_variables(), max_to_keep=3)
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
# Start running operations on the Graph.
# 创建Session并进行变量初始化
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=args.gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
# Initialize variables
sess.run(tf.global_variables_initializer(), feed_dict={phase_train_placeholder:True})
sess.run(tf.local_variables_initializer(), feed_dict={phase_train_placeholder:True})
# 运行输入数据队列,并获取FileWriter
summary_writer = tf.summary.FileWriter(log_dir, sess.graph)
coord = tf.train.Coordinator()
tf.train.start_queue_runners(coord=coord, sess=sess)
with sess.as_default():
# 导入 pre-trained model
if args.pretrained_model:
print('Restoring pretrained model: %s' % args.pretrained_model)
saver.restore(sess, os.path.expanduser(args.pretrained_model))
# Training and validation loop
epoch = 0
# 将所有数据过一遍的次数
while epoch < args.max_nrof_epochs:
# 这里是返回当前的global_step值吗,step可以看做是全局的批处理个数
step = sess.run(global_step, feed_dict=None)
# epoch_size是一个epoch中批的个数
# 这个epoch是全局的批处理个数除以一个epoch中批的个数得到epoch,这个epoch将用于求学习率
epoch = step // args.epoch_size
# Train for one epoch
train(args, sess, train_set, epoch, image_paths_placeholder, labels_placeholder, labels_batch,
batch_size_placeholder, learning_rate_placeholder, phase_train_placeholder, enqueue_op, input_queue, global_step,
embeddings, total_loss, train_op, summary_op, summary_writer, args.learning_rate_schedule_file,
args.embedding_size, anchor, positive, negative, triplet_loss)
# Save variables and the metagraph if it doesn't exist already
save_variables_and_metagraph(sess, saver, summary_writer, model_dir, subdir, step)
# Evaluate on LFW
if args.lfw_dir:
evaluate(sess, lfw_paths, embeddings, labels_batch, image_paths_placeholder, labels_placeholder,
batch_size_placeholder, learning_rate_placeholder, phase_train_placeholder, enqueue_op, actual_issame, args.batch_size,
args.lfw_nrof_folds, log_dir, step, summary_writer, args.embedding_size)
return model_dir
def train(args, sess, dataset, epoch, image_paths_placeholder, labels_placeholder, labels_batch,
batch_size_placeholder, learning_rate_placeholder, phase_train_placeholder, enqueue_op, input_queue, global_step,
embeddings, loss, train_op, summary_op, summary_writer, learning_rate_schedule_file,
embedding_size, anchor, positive, negative, triplet_loss):
batch_number = 0
# 获取学习率
if args.learning_rate>0.0:
lr = args.learning_rate
else:
lr = facenet.get_learning_rate_from_file(learning_rate_schedule_file, epoch)
# 每个 epoch 要训练 epoch_size 个 batch
while batch_number < args.epoch_size:
# Sample people randomly from the dataset
# 从数据集中获取数据
# 确保数据总量为 args.people_per_batch * args.images_per_person
# 输出为两个列表 image_paths, num_per_class
# 其中 len(image_paths) == len(num_per_class),代表数据集中类别数量
# 分类的数量不一定是 args.people_per_batch
# 从dataset中随机抽取样本数据
image_paths, num_per_class = sample_people(dataset, args.people_per_batch, args.images_per_person)
print('Running forward pass on sampled images: ', end='')
start_time = time.time()
# 样本个数nrof_examples=batch中的人数people_per_batch×每个人对应的照片数量images_per_person
nrof_examples = args.people_per_batch * args.images_per_person
# 这里将shape转换为(-1, 3)主要是计算图中的定义,而非实际需要
labels_array = np.reshape(np.arange(nrof_examples),(-1,3))
image_paths_array = np.reshape(np.expand_dims(np.array(image_paths),1), (-1,3))
# 进行enqueue操作
sess.run(enqueue_op, {image_paths_placeholder: image_paths_array, labels_placeholder: labels_array})
# 读取数据集中数据并进行操作,得到embedding向量
# 结果保存在 emb_array 中
emb_array = np.zeros((nrof_examples, embedding_size))
nrof_batches = int(np.ceil(nrof_examples / args.batch_size))
# nrof_batches代表需要运行的batch数=nrof_triplets×3(图片数量)/batch_size
for i in range(nrof_batches):
batch_size = min(nrof_examples-i*args.batch_size, args.batch_size)
emb, lab = sess.run([embeddings, labels_batch], feed_dict={batch_size_placeholder: batch_size,
learning_rate_placeholder: lr, phase_train_placeholder: True})
emb_array[lab,:] = emb
print('%.3f' % (time.time()-start_time))
# Select triplets based on the embeddings
# 进行 select triblets 操作image
# 其中 len(triplets) == nrof_triplets
# triplets 是个队列,每个元素是个三元组,分别代表 anchor positive negative 的 image_path
print('Selecting suitable triplets for training')
triplets, nrof_random_negs, nrof_triplets = select_triplets(emb_array, num_per_class,
image_paths, args.people_per_batch, args.alpha)
selection_time = time.time() - start_time
print('(nrof_random_negs, nrof_triplets) = (%d, %d): time=%.3f seconds' %
(nrof_random_negs, nrof_triplets, selection_time))
# Perform training on the selected triplets
# 基于刚刚获取的 triplets 进行训练
nrof_batches = int(np.ceil(nrof_triplets*3/args.batch_size))
triplet_paths = list(itertools.chain(*triplets))
labels_array = np.reshape(np.arange(len(triplet_paths)),(-1,3))
triplet_paths_array = np.reshape(np.expand_dims(np.array(triplet_paths),1), (-1,3))
sess.run(enqueue_op, {image_paths_placeholder: triplet_paths_array, labels_placeholder: labels_array})
nrof_examples = len(triplet_paths)
train_time = 0
i = 0
emb_array = np.zeros((nrof_examples, embedding_size))
loss_array = np.zeros((nrof_triplets,))
summary = tf.Summary()
step = 0
while i < nrof_batches:
start_time = time.time()
batch_size = min(nrof_examples-i*args.batch_size, args.batch_size)
feed_dict = {batch_size_placeholder: batch_size, learning_rate_placeholder: lr, phase_train_placeholder: True}
err, _, step, emb, lab = sess.run([loss, train_op, global_step, embeddings, labels_batch], feed_dict=feed_dict)
emb_array[lab,:] = emb
loss_array[i] = err
duration = time.time() - start_time
print('Epoch: [%d][%d/%d]\tTime %.3f\tLoss %2.3f' %
(epoch, batch_number+1, args.epoch_size, duration, err))
batch_number += 1
i += 1
train_time += duration
summary.value.add(tag='loss', simple_value=err)
# Add validation loss and accuracy to summary
#pylint: disable=maybe-no-member
summary.value.add(tag='time/selection', simple_value=selection_time)
summary_writer.add_summary(summary, step)
return step
def select_triplets(embeddings, nrof_images_per_class, image_paths, people_per_batch, alpha):
""" Select the triplets for training
"""
trip_idx = 0
# 某个人的图片的embedding在emb_arr中的开始索引
emb_start_idx = 0
num_trips = 0
triplets = []
# VGG Face: Choosing good triplets is crucial and should strike a balance between
# selecting informative (i.e. challenging) examples and swamping training with examples that
# are too hard. This is achieve by extending each pair (a, p) to a triplet (a, p, n) by sampling
# the image n at random, but only between the ones that violate the triplet loss margin. The
# latter is a form of hard-negative mining, but it is not as aggressive (and much cheaper) than
# choosing the maximally violating example, as often done in structured output learning.
# 遍历每一个人
for i in xrange(people_per_batch):
# 这个人有多少张图片
nrof_images = int(nrof_images_per_class[i])
# 遍历第i个人所有照片对应的embedding特征
for j in xrange(1,nrof_images):
# a_idx表示第j张图片在emb_arr中的位置
a_idx = emb_start_idx + j - 1
# neg_dists_sqr表示这张图片跟其他所有图片的欧式距离
neg_dists_sqr = np.sum(np.square(embeddings[a_idx] - embeddings), 1)
for pair in xrange(j, nrof_images): # For every possible positive pair.
# 在同一个人下我们找postive图片
p_idx = emb_start_idx + pair
# (a,p)之间的欧式距离
pos_dist_sqr = np.sum(np.square(embeddings[a_idx]-embeddings[p_idx]))
# 同一个人的图片不作为negative ,所以将其另为nan
neg_dists_sqr[emb_start_idx:emb_start_idx+nrof_images] = np.NaN
#all_neg = np.where(np.logical_and(neg_dists_sqr-pos_dist_sqr
# 找到其他人的图片满足条件:(a,n)距离-(a,p)距离
all_neg = np.where(neg_dists_sqr-pos_dist_sqr<alpha)[0] # VGG Face selecction
# nrof_random_negs表示满足上述条件的emb_arr索引
nrof_random_negs = all_neg.shape[0]
# 如果有满足条件的negative
if nrof_random_negs>0:
# 从中随机选取一个作为negative
rnd_idx = np.random.randint(nrof_random_negs)
n_idx = all_neg[rnd_idx]
# 将anchor的图片路径,postive的图片路径,negative的图片路径放入三元组triplets中
triplets.append((image_paths[a_idx], image_paths[p_idx], image_paths[n_idx]))
#print('Triplet %d: (%d, %d, %d), pos_dist=%2.6f, neg_dist=%2.6f (%d, %d, %d, %d, %d)' %
# (trip_idx, a_idx, p_idx, n_idx, pos_dist_sqr, neg_dists_sqr[n_idx], nrof_random_negs, rnd_idx, i, j, emb_start_idx))
trip_idx += 1
num_trips += 1
emb_start_idx += nrof_images
np.random.shuffle(triplets)
return triplets, num_trips, len(triplets)
def sample_people(dataset, people_per_batch, images_per_person):
# nrof_images为总共抽取图片数量
# people_per_batch为每一个batch抽样多少人
# images_per_person为没人抽取多少张
nrof_images = people_per_batch * images_per_person
# Sample classes from the dataset
# nrof_classes表示dataset共有多少人的图片
nrof_classes = len(dataset)
# class_indices为每个人的索引
class_indices = np.arange(nrof_classes)
# 随机打乱索引,为下一步抽样做准备
np.random.shuffle(class_indices)
i = 0
# 保存抽样出来的图片途径
image_paths = []
# 每个人抽取的图片个数
num_per_class = []
# 抽样的图片是属于哪一个人的,作为label
sampled_class_indices = []
# Sample images from these classes until we have enough
# 不断进行抽样达到指定的数量为止
while len(image_paths)<nrof_images:
# class_index为第i个人的标签
class_index = class_indices[i]
# nrof_images_in_class为第i个人的图片总数
nrof_images_in_class = len(dataset[class_index])
# image_indices为图片索引
image_indices = np.arange(nrof_images_in_class)
# 随机打乱第i人的图片索引数组
np.random.shuffle(image_indices)
# nrof_images_from_class表示应该从该人物中抽取的图片数量
nrof_images_from_class = min(nrof_images_in_class, images_per_person, nrof_images-len(image_paths))
idx = image_indices[0:nrof_images_from_class]
# 从该人中抽取人物对应图片的路径
image_paths_for_class = [dataset[class_index].image_paths[j] for j in idx]
# 将抽样出来的图像所对应的label加到sampled_class_indices中
sampled_class_indices += [class_index]*nrof_images_from_class
# 将抽样出来的图片路径加到image_paths中
image_paths += image_paths_for_class
# 每个人物抽取啊图片的数量信息加到num_per_class中
num_per_class.append(nrof_images_from_class)
i+=1
# 返回抽取的图片路径和每个人所对应的照片数量
return image_paths, num_per_class
def evaluate(sess, image_paths, embeddings, labels_batch, image_paths_placeholder, labels_placeholder,
batch_size_placeholder, learning_rate_placeholder, phase_train_placeholder, enqueue_op, actual_issame, batch_size,
nrof_folds, log_dir, step, summary_writer, embedding_size):
start_time = time.time()
# Run forward pass to calculate embeddings
print('Running forward pass on LFW images: ', end='')
nrof_images = len(actual_issame)*2
assert(len(image_paths)==nrof_images)
labels_array = np.reshape(np.arange(nrof_images),(-1,3))
image_paths_array = np.reshape(np.expand_dims(np.array(image_paths),1), (-1,3))
sess.run(enqueue_op, {image_paths_placeholder: image_paths_array, labels_placeholder: labels_array})
emb_array = np.zeros((nrof_images, embedding_size))
nrof_batches = int(np.ceil(nrof_images / batch_size))
label_check_array = np.zeros((nrof_images,))
for i in xrange(nrof_batches):
batch_size = min(nrof_images-i*batch_size, batch_size)
emb, lab = sess.run([embeddings, labels_batch], feed_dict={batch_size_placeholder: batch_size,
learning_rate_placeholder: 0.0, phase_train_placeholder: False})
emb_array[lab,:] = emb
label_check_array[lab] = 1
print('%.3f' % (time.time()-start_time))
assert(np.all(label_check_array==1))
_, _, accuracy, val, val_std, far = lfw.evaluate(emb_array, actual_issame, nrof_folds=nrof_folds)
print('Accuracy: %1.3f+-%1.3f' % (np.mean(accuracy), np.std(accuracy)))
print('Validation rate: %2.5f+-%2.5f @ FAR=%2.5f' % (val, val_std, far))
lfw_time = time.time() - start_time
# Add validation loss and accuracy to summary
summary = tf.Summary()
#pylint: disable=maybe-no-member
summary.value.add(tag='lfw/accuracy', simple_value=np.mean(accuracy))
summary.value.add(tag='lfw/val_rate', simple_value=val)
summary.value.add(tag='time/lfw', simple_value=lfw_time)
summary_writer.add_summary(summary, step)
with open(os.path.join(log_dir,'lfw_result.txt'),'at') as f:
f.write('%d\t%.5f\t%.5f\n' % (step, np.mean(accuracy), val))
def save_variables_and_metagraph(sess, saver, summary_writer, model_dir, model_name, step):
# Save the model checkpoint
print('Saving variables')
start_time = time.time()
checkpoint_path = os.path.join(model_dir, 'model-%s.ckpt' % model_name)
saver.save(sess, checkpoint_path, global_step=step, write_meta_graph=False)
save_time_variables = time.time() - start_time
print('Variables saved in %.2f seconds' % save_time_variables)
metagraph_filename = os.path.join(model_dir, 'model-%s.meta' % model_name)
save_time_metagraph = 0
if not os.path.exists(metagraph_filename):
print('Saving metagraph')
start_time = time.time()
saver.export_meta_graph(metagraph_filename)
save_time_metagraph = time.time() - start_time
print('Metagraph saved in %.2f seconds' % save_time_metagraph)
summary = tf.Summary()
#pylint: disable=maybe-no-member
summary.value.add(tag='time/save_variables', simple_value=save_time_variables)
summary.value.add(tag='time/save_metagraph', simple_value=save_time_metagraph)
summary_writer.add_summary(summary, step)
def get_learning_rate_from_file(filename, epoch):
with open(filename, 'r') as f:
for line in f.readlines():
line = line.split('#', 1)[0]
if line:
par = line.strip().split(':')
e = int(par[0])
lr = float(par[1])
if e <= epoch:
learning_rate = lr
else:
return learning_rate
def parse_arguments(argv):
parser = argparse.ArgumentParser()
parser.add_argument('--logs_base_dir', type=str,
help='Directory where to write event logs.', default='~/logs/facenet')
parser.add_argument('--models_base_dir', type=str,
help='Directory where to write trained models and checkpoints.', default='~/models/facenet')
parser.add_argument('--gpu_memory_fraction', type=float,
help='Upper bound on the amount of GPU memory that will be used by the process.', default=1.0)
parser.add_argument('--pretrained_model', type=str,
help='Load a pretrained model before training starts.')
parser.add_argument('--data_dir', type=str,
help='Path to the data directory containing aligned face patches.',
default='~/datasets/casia/casia_maxpy_mtcnnalign_182_160')
parser.add_argument('--model_def', type=str,
help='Model definition. Points to a module containing the definition of the inference graph.', default='models.inception_resnet_v1')
parser.add_argument('--max_nrof_epochs', type=int,
help='Number of epochs to run.', default=500)
parser.add_argument('--batch_size', type=int,
help='Number of images to process in a batch.', default=90)
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=160)
parser.add_argument('--people_per_batch', type=int,
help='Number of people per batch.', default=45)
parser.add_argument('--images_per_person', type=int,
help='Number of images per person.', default=40)
parser.add_argument('--epoch_size', type=int,
help='Number of batches per epoch.', default=1000)
parser.add_argument('--alpha', type=float,
help='Positive to negative triplet distance margin.', default=0.2)
parser.add_argument('--embedding_size', type=int,
help='Dimensionality of the embedding.', default=128)
parser.add_argument('--random_crop',
help='Performs random cropping of training images. If false, the center image_size pixels from the training images are used. ' +
'If the size of the images in the data directory is equal to image_size no cropping is performed', action='store_true')
parser.add_argument('--random_flip',
help='Performs random horizontal flipping of training images.', action='store_true')
parser.add_argument('--keep_probability', type=float,
help='Keep probability of dropout for the fully connected layer(s).', default=1.0)
parser.add_argument('--weight_decay', type=float,
help='L2 weight regularization.', default=0.0)
parser.add_argument('--optimizer', type=str, choices=['ADAGRAD', 'ADADELTA', 'ADAM', 'RMSPROP', 'MOM'],
help='The optimization algorithm to use', default='ADAGRAD')
parser.add_argument('--learning_rate', type=float,
help='Initial learning rate. If set to a negative value a learning rate ' +
'schedule can be specified in the file "learning_rate_schedule.txt"', default=0.1)
parser.add_argument('--learning_rate_decay_epochs', type=int,
help='Number of epochs between learning rate decay.', default=100)
parser.add_argument('--learning_rate_decay_factor', type=float,
help='Learning rate decay factor.', default=1.0)
parser.add_argument('--moving_average_decay', type=float,
help='Exponential decay for tracking of training parameters.', default=0.9999)
parser.add_argument('--seed', type=int,
help='Random seed.', default=666)
parser.add_argument('--learning_rate_schedule_file', type=str,
help='File containing the learning rate schedule that is used when learning_rate is set to to -1.', default='data/learning_rate_schedule.txt')
# Parameters for validation on LFW
parser.add_argument('--lfw_pairs', type=str,
help='The file containing the pairs to use for validation.', default='data/pairs.txt')
parser.add_argument('--lfw_dir', type=str,
help='Path to the data directory containing aligned face patches.', default='')
parser.add_argument('--lfw_nrof_folds', type=int,
help='Number of folds to use for cross validation. Mainly used for testing.', default=10)
return parser.parse_args(argv)
if __name__ == '__main__':
main(parse_arguments(sys.argv[1:]))
参考文章:
1、MTCNN人脸检测与对齐和FaceNet人脸识别
2、[人脸检测MTCNN和人脸识别Facenet(附源码)]
(https://www.cnblogs.com/zyly/p/9703614.html)
3、官方Wiki:大概介绍了提供的集中功能以及对应的步骤