论文阅读:Text-based Question Answering from Information Retrieval and Deep Neural Network Perspectives
从信息检索和深度神经网络视角的基于文本的问答:调研
文章目录
- 从信息检索和深度神经网络视角的基于文本的问答:调研
- 0. 摘要
- 1. 介绍
- 2. 基于文本的问答的主要框架
- 3. 来自信息检索的问答相似性
- 4. 深度学习视角下的问答相似性
-
- 4.1 表示模型
- 4.2 交互模型
- 4.3 混合模型
- 5. QA 的数据集
- 6. 评估
- 7. 文献中的结果
- 8. 讨论
- 9. 结论
- 10. 图摘
0. 摘要
基于文本的问题回答(QA)是一项具有挑战性的任务,旨在为用户的问题找到简短而具体的答案。这一领域的研究已使用信息检索技术进行广泛研究 ,并在近年来考虑的深度神经网络方法中已得到越来越多的关注 。深度学习方法是本文的重点,它提供了一种强大的技术来学习问题和文本之间的多层表示和交互。在本文中,我们为QA中的各种模型做一个全面的概述 ,包括传统的信息检索的视角,以及最近的深度神经网络的角度。我们还为这项任务介绍了著名的数据集,并从文献中引用了可用的结果,以便在不同的技术之间进行比较。
关键词:基于文本的问答、信息检索、深度学习
1. 介绍
问答(QA)是计算机科学中一个快速发展的研究问题,其目的是寻找简短而具体的答案。QA系统主要有两种方法:基于文本的QA 和 基于知识的QA。基于知识的QAs 依靠知识库(KBs)来找到用户问题的答案。Freebase 是其中一个受欢迎的KBs (Bollacker et al., 2008),在最近许多基于知识的QA工作中,它被广泛用作基线。KBs 包括 实体、关系和事实。知识库中的事实以(主语、谓语、宾语[subject, predicate, object])格式存储,其中主语和宾语是实体,谓语是关系,表示宾语和主语之间的关系。例如:问题 “In which city was Albert Einstein born?” 的答案 可以被存在于一个事实三元组 ’(Albert Einstein, place-of-birth, Ulm)’中。在这个任务中,有两种类型的问题:单关系问题和多关系问题。一个简单的问题由 KB 中的一个事实来回答,而 多关系问题的答案则通过对 KB 中的多个事实进行推理来找到 (Yu et al., 2017)。SimpleQuestions 和 WebQSP 分别是 单关系问题和多关系问题 的主要数据库。
在基于文本的问答中,候选答案是通过在候选答案文本中寻找最相似的答案文本来获得的。给定问题 Q Q Q 和答案集合 { A 1 , A 2 , . . . , A n } \{A_1,A_2,...,A_n\} {A1,A2,...,An},
这个系统的目标是在这些答案中找到最好的答案。最近的研究在基于文本的QA中提出了不同的深度神经模型,该模型比较两段文本并产生相似度评分。在本文中,我们重点研究了基于文本的QA,并对现有的基于文本的QA方法进行了综述。
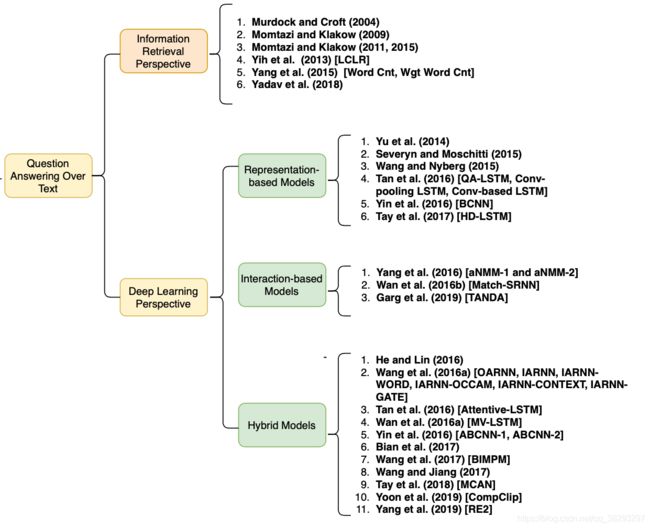
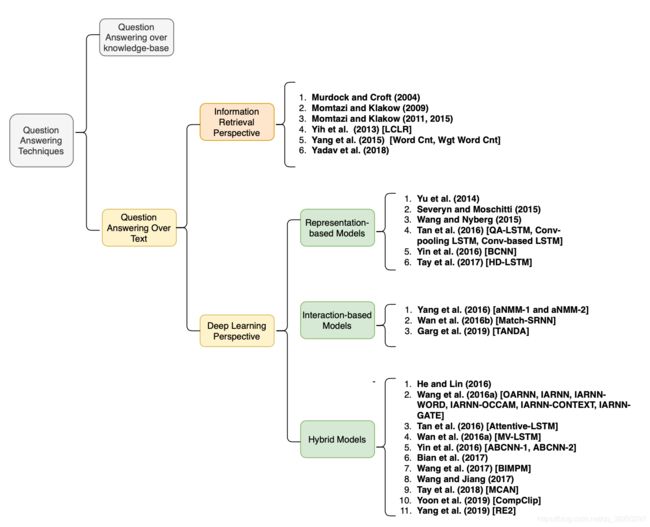
图1展示了QA系统的总体分类,包括每个类别的主要代表模型。Diefenbach et al. (2018) 提供了一个综述,仅涵盖基于知识库的QA,并包含了到2017年的提出的模型。Soares and Parreiras (2018) 是另一篇综述,没有讨论提出的模型,也包括2018年之前的工作; Kodra (2017) 命名了各种各样的QA系统,在每种QA类型中只讨论了少量提出的模型,而重点关注神经模型。(Wu et al., 2019 是最近的另一项调研,只涵盖知识库上的QA。** Dimitrakis et al. (2019) ** 提供了QA系统的不同组件的概述,但是没有讨论所提议模型的体系结构。(Lai et al., 2018) 发表了一份综述报告,为深度学习方法的分类提供了不同的视角,但没有涵盖提出的模型的架构。
图1:本文提出的QA技术的分类
我们的论文从不同的角度,包括这一领域中最先进的模型,对文本QA中的代表性模型的体系结构提供了明了和完整的概述。此外,本文还讨论了所提出模型的注意特征( noted features)。此外,近年来,预训练的上下文化语言模型(如ELMO、BERT、RoBERTa 和 ALBERT)在包括QA在内的自然语言处理(NLP)下游任务方面取得了巨大进展,但上述文章都没有讨论这些模型。
本文组织如下:
- 第2节中,我们介绍了QA系统的体系结构。
- 第3节,讨论了用于问题答案相似度的基于信息检索的模型
- 第4节,讨论了深度学习模型
- 第5节,介绍了QA中最流行的QA数据集
- 第6节中,介绍了评估指标
- 第7节,报告和比较回顾模型的结果
- 第8节,讨论论文
- 第9节,结论
2. 基于文本的问答的主要框架
如图2所示,基于文本的QA体系结构包括三个主要阶段:问题处理、文档和文章检索以及答案抽取。每一个阶段都在文章 (Jurafsky and Martin, 2009) 中描述。
图2:基于文本的QA体系结构 (Jurafsky and Martin, 2009)

- 问题处理:这个阶段包括两个主要步骤,即查询公式化和答案类型检测。
在查询公式化步骤中,使用信息检索(IR)引擎生成的查询用来检索相关文档。 由查询重述规则生成的查询看起来像是预期答案的一个子集。
在答案类型检测步骤中,使用分类器根据期望答案的类型对问题进行分类。在这一步中可以使用不同的基于神经或基于特征的分类器。 - 文档和文章检索:在查询公式化步骤中生成的查询,送入IR引擎,并返回前 n n n 个检索到的文档。由于答案抽取模型主要针对的是文档的短段,篇章检索模型应用于检索到的文档,以接收文本的短段。这是QA的核心部分,可以找到与输入问题相似的段落/句子。
- 答案抽取:在QA的最后阶段,从给定的文章中检索最相关的答案。在这一步中,我们需要度量输入问题和提取答案的相似性。
如前所述,估计问题和答案句的相似度是基于文本的QA系统的重要组成部分。由于检索到的句子足够短,足以满足用户的需求,因此这一步的输出也可以表示给用户,而无需进一步提取答案。问题和回答句子的相似度可以通过信息检索或深度学习方法来衡量。在第3节和第4节中,我们分别从信息检索的角度和深度学习的方法来回顾相关作品。
3. 来自信息检索的问答相似性
(ad hoc:类似于图书馆里的书籍检索,即书籍库(数据库)相对稳定不变,不同用户的查询要求是千变万化的。这种检索就称为ad hoc。基于Web的搜索引擎也属于这一类。
ad-hoc retrieval:即席检索)
尽管基于词汇的信息检索模型在即席检索中得到了广泛的应用,但在问答任务中应用较少,因为问答句子的长度比一般的web文档要短,而且问答中问题与回答句子之间的词汇差距比即席检索更具有 代词(pronoun) 的意义。它推动了在QA中使用先进的信息检索方法的研究。本节将介绍其中一些方法。在本节的最后,信息检索方法的简要概述如表1所示。

Yang et al. (2015) 提供了用于开放域QA的 WikiQA 数据集。他们使用基于信息检索的模型评估了 WikiQA 和 QASent 数据集,这些模型 如单词计数(Word Cnt)、加权单词计数(Wgt Word Cnt)、学习受限潜在表示(LCLR) (Yih et al., 2013),和段落向量(PV) * (Le and Mikolov, 2014)*。
Word Cnt 模型: 计算在问题和回答句子中出现的非停用词
Wgt Word Cnt 模型:和Word Cnt 一样,但它也通过问题中词语的逆文档频率(IDF)权重来重新加权计数
Yih et al. (2013) 提出的模型背后的思想是:采用概率分类器、使用问题和答案的语义模型来预测它们之间是否相关。他们利用问答句中每对词的同义词/反义词、上位词/下位词和语义词相似性来创建语义模型。他们采用学习受限潜在表示(LCLR) (Chang et al., 2010)对问题和答案进行分类。分类器的细节如下所示:
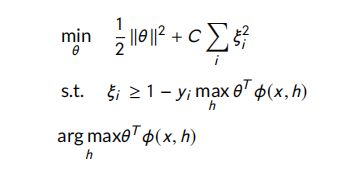
Murdock and Croft (2004) 提出了一种QA翻译模型。在他们的模型中,给定答案 ( A ) (A) (A) 的问题 Q Q Q 的概率表示为 P ( Q ∣ A ) P(Q|A) P(Q∣A),它由以下公式计算:

其中, λ \lambda λ 为平滑参数, D A D_A DA 为包含答案 A A A 的文档, C C C 为集合。该思路基于 Berger and Lafferty (1999) 提出的模型,然而采用不同的相似度模型计算 P ( q i ∣ a j ) P(q_i|a_j) P(qi∣aj)。
Momtazi and Klakow (2009) 提出了基于类的句子检索语言模型。他们的基于类的语言模型旨在通过寻找单词之间的关系来缓解单词不匹配问题。采用Brown词聚类算法对模型中的词进行聚类,通过以下等式计算出具有答案句 S S S 的问题 Q Q Q 的概率:
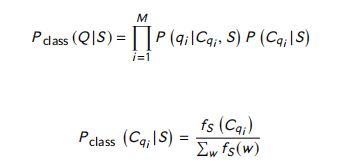
其中, P ( q i ∣ C q i , S ) P(q_i|C_{q_i},S) P(qi∣Cqi,S) 是有类簇 ( C q i ) (C_{q_i}) (Cqi)和答案句模型 ( C ) (C) (C)下的术语 q i q_i qi 的概率; P ( C q i ∣ S ) P(C_{q_i}|S) P(Cqi∣S) 是 给定句子模型 S S S 的条件下 ( C q i ) (C_{q_i}) (Cqi) 的概率。 f s ( C q i ) f_s(C_{q_i} ) fs(Cqi) 是 S S S 句中术语 q i q_i qi 类簇中所有词的出现次数, w w w 代表词汇。
Momtazi and Klakow (2011, 2015) 提出了一种经过训练的触发语言模型。在他们的模型中,通过使用单词之间的上下文信息,可以缓解单词不匹配的问题。该模型的思想是寻找触发词和目标词对,而答案句中出现的目标词和问题句中出现的触发词意味着相关词之间的联系。他们训练了一个从语料库中提取触发-目标对的模型,并将该模型用于计算问题词 q i q_i qi 的概率,其答案为 S S S,记为 P ( q i ∣ S ) P (q_i |S) P(qi∣S):

其中, s j s_j sj 和 q i q_i qi 分别代表答案句的第 j j j 个术语,问题句中的第 i i i 个术语。 f c ( q i , s j ) f_c (q_i ,s_j ) fc(qi,sj) 是 在 C C C 语料库创建的模型中,属于 q i q_i qi 触发 术语 s j s_j sj 的次数。 P ( q i ∣ S ) P (q_i |S) P(qi∣S) 给定句子 S S S 时, q i q_i qi 的概率, N N N 是句子长度。
有了上述概率,问题 ( Q ) (Q) (Q)具有答案 ( S ) (S) (S) 的 概率计算如下:
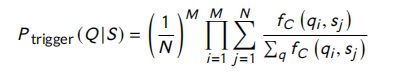
其中, M M M 是问题长度。
Yadav et al. (2018) 提出了一个模型,该模型分三个步骤计算每个问题-答案对的匹配分数。第一步,每个单词的IDF权重计算公式如下:

其中 N N N 是问题的个数, d o c f r e q ( q i ) docfreq(q_i ) docfreq(qi) 是 单词 q i q_i qi 出现的问题的个数。
在第二步中,在question和answer中的术语之间执行一对多的对齐。每个问题词 q i q_i qi 和每个回答词 a i a_i ai 的 Glove 词嵌入(Pennington et al., 2014) 之间的余弦相似度被认为是它们的相似度。然后 前 K + K^+ K+ 个最相似的单词 { a q i , 1 + , a q i , 2 + , a q i , 3 + , . . . , a q i , K + + } \{a_{q^i,1}^+,a_{q^i,2}^+,a_{q^i,3}^+,...,a_{q^i,K^+}^+\} {aqi,1+,aqi,2+,aqi,3+,...,aqi,K++} 和 K − K^- K− 个最不相似的单词 { a q i , 1 − , a q i , 2 − , a q i , 3 − , . . . , a q i , K + − } \{a_{q^i,1}^-,a_{q^i,2}^-,a_{q^i,3}^-,...,a_{q^i,K^+}^-\} {aqi,1−,aqi,2−,aqi,3−,...,aqi,K+−} 被找到。
最后,在第三步中,通过以下公式计算每个问答句之间的相似度评分 S ( Q , A ) S(Q, A) S(Q,A):

其中, a l i g n ( q i , A ) align(q_i , A) align(qi,A) 是 q i q_i qi 与答案 A A A 之间的对齐分数; λ \lambda λ 是负面信息的权重; p o s ( q i , A ) pos(q_i , A) pos(qi,A) 和 n e g ( q i , A ) neg (q_i , A) neg(qi,A) 分别表示 K + K^+ K+ 个最相似词和 K − K^- K− 个最不相似词的一对多对齐得分。他们还提出了另外两个基线,单对齐(一对一)和一对所有。在一对一方法中,只使用最相似的单词 K + = 1 K^+ = 1 K+=1 这个单一对齐得分。在一对多的方法中,在计算 a l i g n ( q i , A ) align(q_i , A) align(qi,A) 时,以相同的权重考虑问题项 q i q_i qi 与所有答案项的相似性,使 a l i g n ( q i , A ) align(q_i , A) align(qi,A) 变为:

其中 M M M 是答案句子的字数。
4. 深度学习视角下的问答相似性
深度学习模型可以分为三类:基于表示、基于交互和混合(Guo et al., 2016)模型 。
- 基于表示的模型分别构造问题和候选答案的固定 d d d 维向量表示,然后在潜在空间内进行匹配。
- 基于交互的模型计算问题和候选答案句子的每个术语之间的交互,其中交互可以是身份或句法/语义相似。
- 混合模型结合了交互模型和表示模型。它们由一个表示组件(将一系列单词组合成固定 d d d 维的表示)和一个交互组件组成。这些组件可以并行或串行出现。
本节中,我们将会回顾所提出的深度神经模型的结构,并根据上述类别列举模型的类型。与上一节类似,我们将在本节的最后简要概述基于深度学习的模型。
4.1 表示模型
Yu et al. (2014) 提出了一种基于生成神经网络的问题/答案对是否相关的二分类模型。该模型捕捉了问题和答案句的语义特征。每个样本都用一个三元组 ( q i , a i j , y i j ) (q_i,a_{ij},y_{ij}) (qi,aij,yij) 表示,其中 q i ∈ Q q_i \in Q qi∈Q 是一个问题, a i j a_{ij} aij 是 q i q_i qi的一个候选答案,标签 y i j y_{ij} yij 表示 a i j a_{ij} aij 是否为 q i q_i qi 的正确答案。对每个答案,一个相关的问题被生成,然后使用点积来获取所生成问题与给定问题的语义相似性。这种相似性用于预测候选答案对于给定问题是否正确。答案正确的概率可以表述为:

其中 q ′ = M a q'=Ma q′=Ma 是生成问题。通过最小化 所有标记数据QA对 的交叉熵来训练模型,如下:

其中 ∣ ∣ θ ∣ ∣ F 2 ||\theta||_F^2 ∣∣θ∣∣F2 是 θ \theta θ 的 Frobenius 范数。
每个句子都是由 词袋 和 bi-gram 建模的。在词袋模型中,一个句子是通过平均所有单词(停用词除外)的嵌入来表示的。Bi-gram 模型能够独立于 bigrams 在句子中的位置来捕捉它们的特征。由于bigram模型的架构如图3所示,因此在bigram模型中使用了一个卷积层和一个池化层对句子进行建模。每个 bigram 被映射到一个特征值 c i c_i ci,计算如下:
![]()
其中, s s s 是句子的向量表示。在平均池化层中组合所有 bigram 特征,最终得到与初始词嵌入具有相同维数的全句表示,计算如下:

下图是图3:Yu et al. (2014) 提出的模型架构

下图是图4:Severyn and Moschitti (2015) 提出的模型架构

Severyn and Moschitti (2015) 提出了一个选择答案的框架。他们将任务分为两个主要子任务:(1) 将单词的原始空间映射到特征空间编码,(2) 学习对象对之间的相似性函数。他们使用卷积神经网络(CNN)架构来学习将输入文本(查询或文档)映射到向量空间模型。在第二部分中,他们使用了噪声信道方法来寻找一个文档的转换,使其尽可能接近查询: S i m ( x q , x d ) = x q T M x d Sim(x_q , x_d ) = x_q^T Mx_d Sim(xq,xd)=xqTMxd;为此,他们使用神经网络架构来训练相似度矩阵 M M M。根据图4,来自第一个CNN模型的查询和文档的向量表示 拼接送给第二个CNN,训练并构建相似度矩阵。
以下是图5:Wang and Nyberg (2015) 提出的模型架构

Wang and Nyberg (2015) 采用多层堆叠双向长短时( Long Short-term)记忆网络(BiLSTM)完成了答案句子选择任务。如图5所示,问题和答案项的word2vec表示序列被喂入该模型 。为了区分问题和答案,将符号 < S > <S> 被放在问题 q q q 和答案 a a a 之间。在不同的递归神经网络(RNN)架构中,选择堆叠的BiLSTM为第一层双向RNN,从双向提取问题和答案的上下文信息;换句话说,它使用未来的信息;第二层堆叠的BiLSTM提供了更好的结果,这是由于其在提取更高级别的抽象能力;第三层 LSTM是一个更复杂的RNN块,这缓解了标准RNNs梯度消失的问题。每个时间步长的最终输出表明给出的答案是否为问题的正确答案。
该模型采用梯度增强回归树(GBDT)方法将堆叠的BiLSTM关联模型组合起来,精确匹配问答句中的专有名词和基数。
Tan et al. (2016) 提出了一种用于句子匹配的基本模型,称为QA-LSTM,如图6所示。
以下是图6 : (Tan et al., 2016) QA-LSTM基础模型的架构
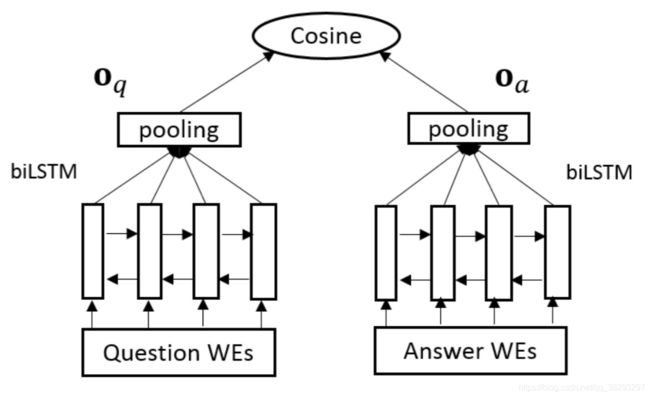
从图中可以看出,在基本模型中,问答句的单词嵌入被输入到一个BiLSTM网络中。每个句子可用三种不同的方式得到一个固定大小的表示:
(1)拼接两个方向的最终输出
(2)对BiLSTM的所有输出进行平均池和最大池
(3)利用余弦相似度对问答句的语义匹配进行评分
LSTM在捕获长期依赖关系方面是一个强大的架构,但它的缺点是没有注意到局部 n-gram,然而卷积结构与之相反;因此,每个CNN和RNN块都有各自的优缺点。本文提出了基本QA-LSTM的三种变体,其中一种属于混合模型,在4.3节中进行了描述。下面将描述属于基于表示模型的另外两个QA-LSTM变体。
- Convolutional pooling LSTM:如图7所示,池化层被替换为卷积层,以捕获更丰富的局部信息,并在该层之上放置输出层,用于生成输入句子的表示。输入句子的表示由以下方程式生成:
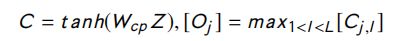
其中, Z ∈ R k ∣ h ∣ × L Z ∈ R^{k |h|×L} Z∈Rk∣h∣×L , m m m 列 是由 以序列中第 m m m个token为中心, BiLSTM 的第 k k k个隐藏层向量串联而成。 L L L为序列长度, W c p W_{cp} Wcp 为网络参数。
以下是图7:(Tan et al., 2016) 提出的Conv-pooling LSTM 的模型架构
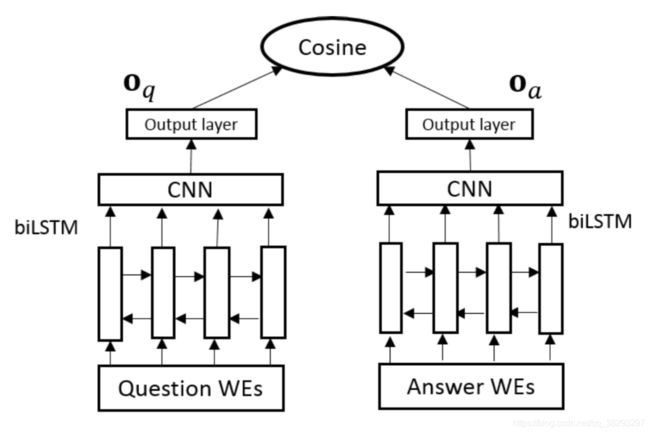
- 基于卷积的LSTM:该模型的架构如图8所示。
以下是图8: (Tan et al., 2016) 提出的基于卷积的LSTM的模型架构

在这个模型中,单词嵌入首先被喂给一个CNN,用于检索底层的局部n-gram交互。卷积的输出被输入到BiLSTM网络中以捕获长时依赖关系。然后使用最大池产生句子表示。卷积层 X X X 的输出由下式得到:
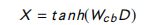
其中, D ∈ R k E × L D ∈ R^{k E×L} D∈RkE×L 是这个模型的输入; D D D 的列 l l l 是以第 l l l 个单词为中心,大小为 E E E 的 k k k 个单词向量的拼接。
Yin et al. (2016) 提出了一种Basic CNN (BCNN)模型和三种基于注意力的CNN (ABCNN)文本匹配模型。ABCNN模型属于混合类别,在4.3节中进行了描述。下面介绍BCNN的架构。
**Basic CNN (BCNN):**该模型的架构如图9所示。
以下是图9:(Yin et al., 2016) 提出的BCNN 的模型架构
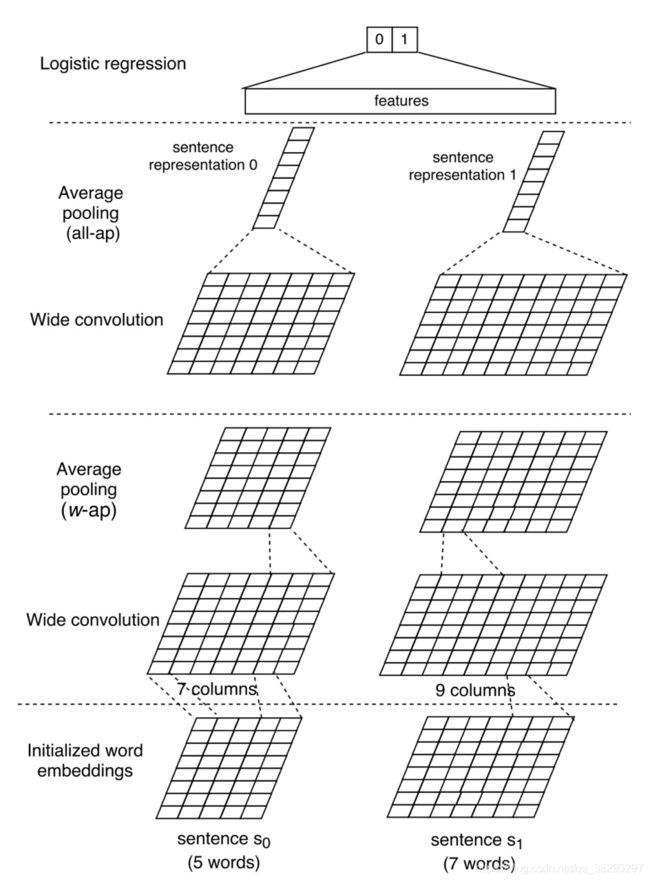
这个模型基于Siamese架构(Bromley et al., 1993)。 该模型使用卷积以及 w-ap 池化和 all-ap 池化层 表示每个句子;然后使用逻辑回归比较这两个表示。BCNN的各层描述如下:
-
输入层:每个句子以 d 0 × s d_0 \times s d0×s的矩阵给模型,其中 d 0 d_0 d0 是每个单词的word2vec (Mikolov et al., 2013)嵌入的维数, s s s 是两个句子的最大长度(较短的句子被填充为较大的句子长度)。
-
卷积层:窗口大小为 w w w 的句子中的单词嵌入 拼接起来,表示为: c i ∈ R w ⋅ d 0 c_i \in R^{w \cdot d_0} ci∈Rw⋅d0,其中 0 < i < s + w 0 < i < s + w 0<i<s+w( s s s 是句子长度)。然后 c i c_i ci 通过以下公式转化为 p i p_i pi:
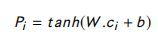
令 W ∈ R d 1 × w ⋅ d 0 W \in R^{d_1 \times w \cdot d_0} W∈Rd1×w⋅d0 是卷积权重, b ∈ R d 1 b \in R^{d_1} b∈Rd1 是偏置。 -
平均池化层:该模型利用两种平均池化算法,叫 all-ap 和 w-ap去从卷积中提取鲁棒特征。 all-ap 池化是使用在最后的卷积层和计算每列的平均。 w-ap 池化 用于中间的卷积层,计算每连续的 w w w列的平均值。
-
输出层:输出层运用逻辑回归对最终表示进行分类,以确定问题和回答句子是否相关。
Tay et al. (2017) 提出 Holographic-dual LSTM (HD-LSTM),QA任务的一个二分类模型。如图10所示,HD-LSTM由四个主要部分组成。
以下是图10 : (Tay et al., 2017) 提出的 HD-LSTM 的模型架构

在表示层中,使用Q-LSTM和A-LSTM两个多层lstm来学习问题和答案的表示。用全息合成法(holographic composition) 去度量 Q-LSTM和A- lstm输出的相似度。 最后,利用全连接隐藏层对QA对进行正确或不正确的二值分类。HD-LSTM的各部分描述如下:
-
学习QA表示:这一层不学习单词嵌入,而是使用预训练的SkipGram embeddings (Mikolov et al., 2013)的权重 W W W。问题和答案序列的嵌入被输入Q-LSTM和A-LSTM。在Q-LSTM和A-LSTM的最后一个隐藏输出中生成问题和答案的表示。
-
QA对全息匹配:将在前一层学习到的问题和答案嵌入送到全息层中,向量的循环相关性用于建模它们的相似性。问题与回答的相似性由以下等式建模:
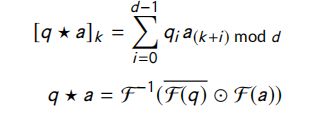
其中, F F F 是快速傅里叶变换, q q q 是问题, a a a 是答案, d d d 是embeddings 的维度。在上式中,问题和答案的嵌入必须具有相同的维度。 -
全息隐藏层:这是一个全连接dense层。这层的输入输出分别是:$ [[q*a], Sim(q, a), X_{feat} ]$ 和 h o u t h_{out} hout。 ( X f e a t ) (X_{feat}) (Xfeat) 是单词重叠特征, S i m ( q , a ) Sim(q, a) Sim(q,a) 是 q q q 和 a a a 之间的双线性相似函数,定义为:

其中, M ∈ R n × n M \in R^{n \times n} M∈Rn×n 是 q ∈ R n q \in R^n q∈Rn 和 a ∈ R n a \in R^n a∈Rn 的相似度矩阵。 S i m ( q , a ) Sim(q, a) Sim(q,a) 和 $ [q * a]$ 的拼接使性能更差。因此,为了缓解这一弱点, ( X f e a t ) (X_{feat}) (Xfeat) 被拼接起来,使模型工作得更好。 -
Softmax 层:最后使用了:
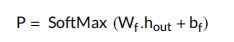
其中, W f W_f Wf 和 b f b_f bf 是网络参数。
4.2 交互模型
Yang et al. (2016) 提出了aNMM-1和aNMM-2神经匹配模型。ANMM-1主要工作步骤如下:
-
构建QA匹配矩阵:矩阵中的每个单元格表示对应的问答词的相似度。相似度是通过标准化单词嵌入的点积来计算的。
-
学习语义匹配:不同的答案句子长度导致了QA矩阵的大小的变化。为了解决这个问题,使用权值共享方法。在value shared weights method中,每个节点的权重都是基于其自身的值,其中一个节点的值表示两个单词之间的相似性。每个问题项的隐含层输入定义如下:
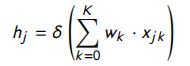
其中, j j j 是问题项的索引, w k w_k wk 是模型参数, x j k x_{jk} xjk 是在范围 k k k 内所有匹配信号的和(将可能匹配信号的范围划分为 k k k 个相等的bins,每个匹配分数分配给一个bin) -
问题注意力网络:在隐状态 h j h_j hj 中应用带有问题词嵌入权值的注意层。最后,匹配分数计算公式如下
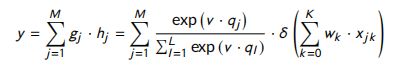
其中, v v v 是模型的参数,问题字嵌入的点积 和 v v v 被喂入 softmax 函数。
以下是图11: (Yang et al., 2016) 提出的 ANMM-2 模型的架构
在aNNM-2中,每个问题答案匹配向量使用多个共享权值,那么在第一隐层中存在多个中间节点。由于 aNMM-2 的架构如图11所示,模型 y y y 的最终输出定义为:
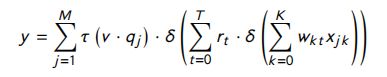
其中, T T T 是隐藏层1的节点数, r t r_t rt 是从隐藏层1到2的模型参数。 τ ( v , q j ) \tau (v,q_j) τ(v,qj) 计算如下:
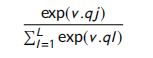
Wan et al. (2016b) 提出了一种递归语义匹配模型——Match-SRNN。图12显示了Match-SRNN的架构;
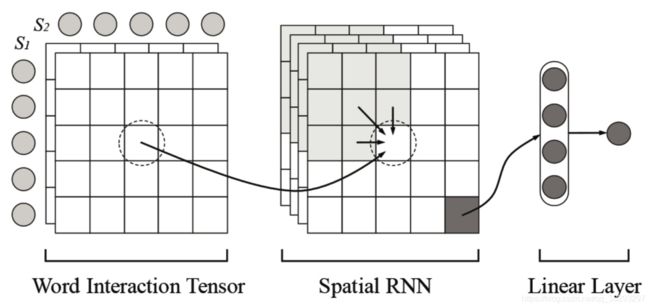
根据图12,Match-SRNN分为三个主要步骤:在第一步中,对词级交互进行建模。第二步是两个不同句子 ( S 1 [ 1 : i ] a n d S 2 [ 1 : j ] ) (S1[1 : i] and S2[1 : j]) (S1[1:i]andS2[1:j]) 的两个前缀之间的交互的特殊情况进行建模,作为 S 1 [ 1 : i − 1 ] S1[1 : i -1] S1[1:i−1] 和 S 2 [ 1 : j ] S2[1 : j] S2[1:j]、 S 1 [ 1 : i ] S1[1 : i ] S1[1:i] 和 S 2 [ 1 : j − 1 ] S2[1 : j-1] S2[1:j−1]、 S 1 [ 1 : i − 1 ] S1[1 : i -1] S1[1:i−1] 和 S 2 [ 1 : j − 1 ] S2[1 : j-1] S2[1:j−1] 之间的交互函数,and 词 w i w_i wi 和 v j v_j vj 之间的交互。这种特殊交互的方程是:
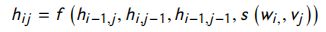
其中, h i j h_{ij} hij 是 S 1 [ 1 : i ] S1[1 : i] S1[1:i] 和 S 2 [ 1 : j ] S2[1 :j] S2[1:j] 之间的交互。这种建模交互的递归方式有助于捕获两个句子之间的长期依赖关系。
在第三步中,使用一个线性函数来测量两个给定句子的匹配分数。下面是关于这些步骤的更多细节。
-
Neural tensor network: w i w_i wi 和 v j v_j vj 两个词之间的相互作用由神经张量网络根据下式捕捉:
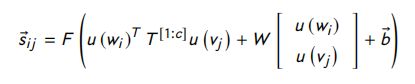
其中, s i j s_{ij} sij 是 w i w_i wi 和 v j v_j vj 词相似度的向量表示; T i T_i Ti 是张量参数的一个切片, W W W 和 b b b 是参数, F ( Z ) = m a x ( 0 , Z ) F (Z ) = max(0, Z ) F(Z)=max(0,Z)。 -
Spatial RNN:在这一层中,GRU被用作RNN,因为它很容易实现 建模 h i j h_{ij} hij 的Spatial-GRU。图13显示了本工作中使用的1D-GRU和Spatial-GRU的架构。
以下是图13:Spatial-GRU (right) and GRU (left) 的架构
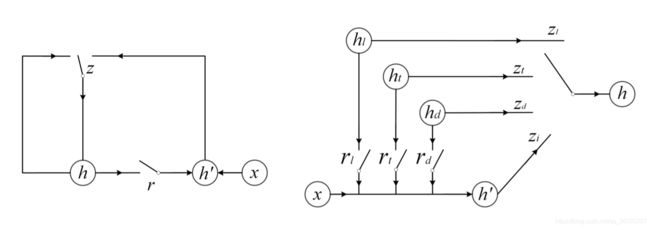
根据图13右图,Spatial-GRU有四个更新门,三个重置门。Spatial-GRU中的函数 f f f 计算如下
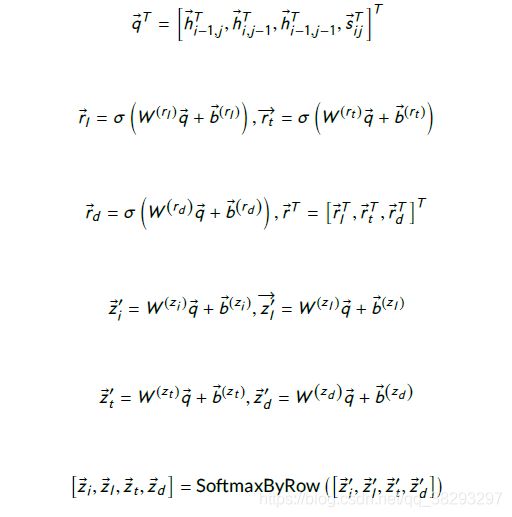
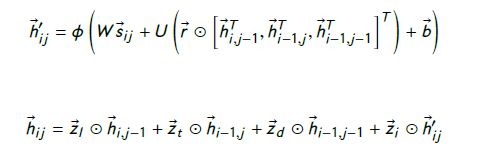
-
Linear Scoring Function:两个给定句子的最终匹配分数由公式计算: M ( S 1 , S 2 ) = W ( s ) h m n + b ( s ) M(S_1,S_2) = W^{(s)}h_{mn}+b^{(s)} M(S1,S2)=W(s)hmn+b(s),其中 h m n h_{mn} hmn 是两个句子间的全局交互, W ( s ) W^{(s)} W(s) 和 b ( s ) b^{(s)} b(s) 是网络参数。
Devlin et al. (2019) 提出了 Bidirectional Encoder Representations from Transformers (BERT) 模型,是一个语言模型神经网络。
以下是图14:(Devlin et al., 2019) 提出的预训练 和 微调 的BERT 架构

以下是 图15 : 构建BERT的输入表示
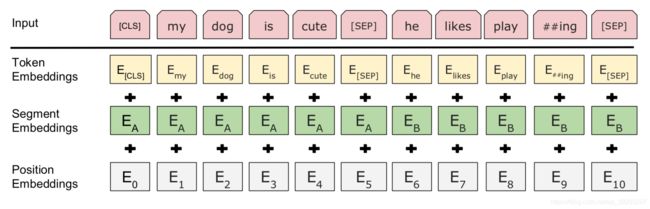
BERT采用多层双向架构,每一层是一个transformer 【Vaswani et al. (2017)】编码器。BERT采用了与transformer模型相同的解码段。BERT广泛应用于各种NLP下游任务,包括QA、自然语言推理和文本分类,其用于捕获给定序列之间的文本依赖关系。BERT在大型语料库上通过masked语言模型和下一句预测 两种不同的方法进行预训练,然后根据应用 对每个具体的下游任务进行微调。BERT的架构包括预处理和微调步骤,如图14所示。BERT的输入是单词的输入表示序列。将单词嵌入、分段嵌入和位置嵌入相加,构建每个单词的输入表示,如图15所示。在QA领域中,在序列的第一个位置使用一个 ( C L S ) (CLS) (CLS),然后将问题和候选答案分别跟一个 ( S E P ) (SEP) (SEP) 放在序列中。BERT的输出是每个token的编码表示。BERT也被用于问答任务中,由于BERT在问答句子中使用了交叉匹配的注意力,因此它被认为是一种基于交互的模型。
Garg et al. 提出 TANDA模型。它利用BERT和RoBERTa预训练的语言模型来建模两个句子序列之间的依赖关系,用于答案句子选择(AS2)。对BERT进行微调的数据量太小,可能会导致模型不稳定、有噪声。为了缓解这个问题,他们为AS2使用了两个不同的微调步骤。在为AS2任务在大型语料库上执行的第一个微调步骤中,BERT被转换成AS2模型 ,而不仅仅是语言模型。然后通过对目标数据集上的模型进行微调,使模型适用于特定的问题类型领域。TANDA模型的架构如图16所示。
以下是图16:(Garg et al.) 提出的TANDA 的模型架构

问题和答案对附加一个 [ S E P ] [SEP] [SEP] 并传递给BERT模型。token [ ] C L S []CLS []CLS 的编码表示被传到一个全连接层,然后是一个sigmoid函数,用于预测给定问题和答案对的匹配分数。
4.3 混合模型
He and Lin (2016) 提出了一个QA任务模型,该模型由四个主要部分组成。模型的架构如图17所示。该模型的不同组成部分如下:
以下是图17:He and Lin (2016) 的模型架构
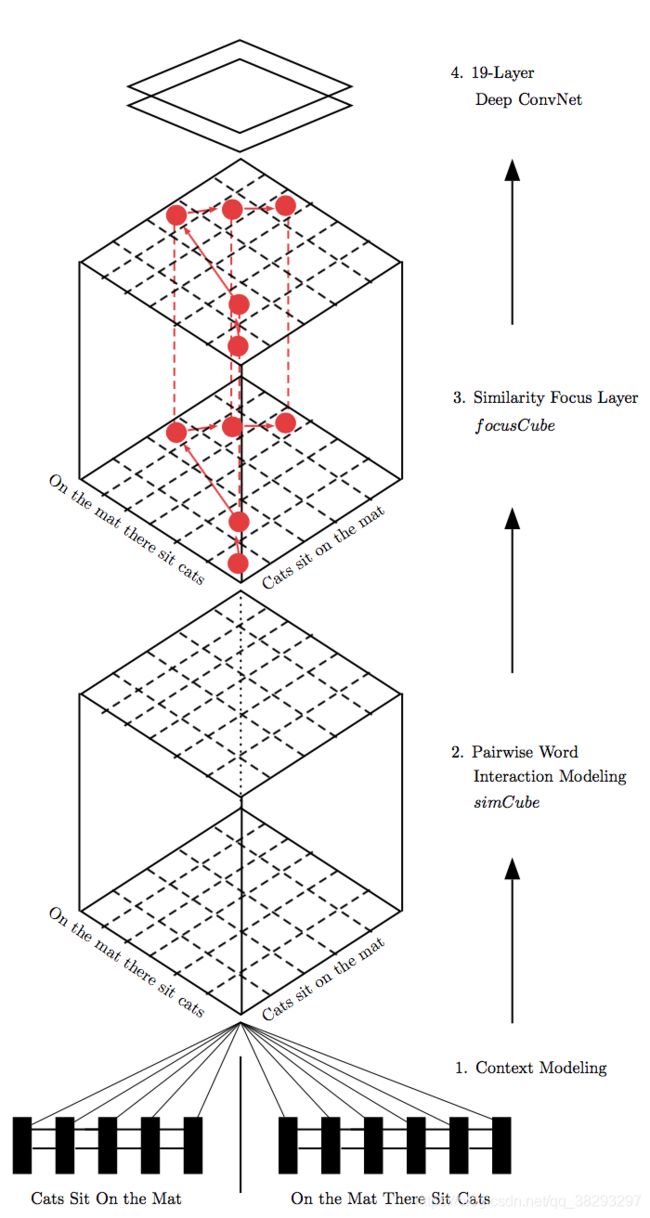
- 上下文建模:这是第一个组件,它使用一个BiLSTM来建模每个单词的上下文。
- 成对词交互建模:这个组件 比较了 BiLSTM 的两个隐藏状态与余弦,L2欧几里得,和点积距离度量 (This component compares two hidden states of BiLSTM with Cosine, L2 Euclidean, and dot product distance measures)
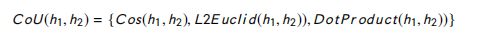
该组件的输出是一个 cube,size是: R 13. ∣ s e n t 1 ∣ . ∣ s e n t 2 ∣ R^{13.|sent1|.|sent2|} R13.∣sent1∣.∣sent2∣,其中, s e n t 1 sent1 sent1和 s e n t 2 sent2 sent2分别是第一句和第二句。对于每对单词,考虑了12个不同的相似距离和一个额外的填充。 - Similarity focus:在这一层中,单词交互通过最大化重要单词交互的权重来分配权重。该组件的输出是一个名为 FocusCube 的cube,被识别为重要的单词在该cube中有更大的权重
- Similarity classification:在这一层中,CNN用于寻找强成对词交互的模式。FocusCube中的问答语句被输入到这一层,并计算相似度评分。
Wan et al. (2016a) 提出了一种利用句子不同位置的表示来匹配两个句子的MV-LSTM。如图18所示,通过计算不同位置的两个句子在不同相似度度量之间的交互,创建每个句子中不同位置的表示,创建多个张量。然后利用 k − m a x k-max k−max 池化层和多层LSTM对两个给定句子的匹配分数进行建模。
以下是图18:(Wan et al., 2016a) 提出的MV-LATM 架构

下面三个步骤将更详细地解释MV-LSTM的架构:
- Positional Sentence Representation:利用BiLSTM得到了句子在一个位置上的表示。BiLSTM用于捕获一个句子中的长、短期依赖关系。这里使用的是与 (Graves et al., 2013)中使用的实现类似的LSTM层。给定句子 S = ( x 0 , x 1 , … , x T ) S = (x_0, x_1,…, x_T) S=(x0,x1,…,xT), LSTM 可表示位置 t t t的句子 h t h_t ht ,如下
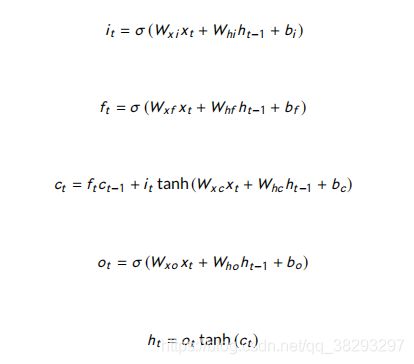
利用 BiLSTM 层,为每个位置生成两个不同的表示 h → t \overrightarrow h_t ht 和 h ← t \overleftarrow h_t ht,每个位置的最终表示被认为是这两个表示的拼接: [ h → t . h ← t ] [ \overrightarrow h_t . \overleftarrow h_t ] [ht.ht] - Interactions between two sentences:这一步使用余弦、双线性和张量相似函数来建模两个位置之间的交互。与余弦函数相比,双线性函数捕获更复杂的交互,如下:
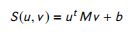
其中, b b b 是偏置, M M M 是一个在不同维度上重新加权 u u u 和 v v v 的矩阵。张量函数更有力地模拟了两个向量之间的交互。它使用下面的方程对交互进行建模:
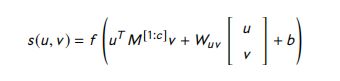
其中, W u v W_{uv} Wuv 和 b b b 是参数, M i M_i Mi 是张量参数的一个切片, f f f 是整流函数。余弦相似度和双线性相似度的输出为交互矩阵,张量层的输出为交互张量。 - Interaction aggregation:第三步使用不同位置句子表示之间的交互,以衡量两个给定句子的匹配分数。应用 K-max pooling 提取一个向量 q q q,它包含一个矩阵的前 k k k 个值,或者每个张量切片的 前 k k k 个值。将k -max pooling的输出输入到全连接隐层中,得到了一种新的表示 r r r 。最后通过下面的函数得到匹配分数 s s s:
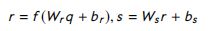
其中, W r W_r Wr 和 W s W_s Ws 是模型参数, b r b_r br 和 b s b_s bs 是偏置。
以下是图19: (Tan et al., 2016) 提出的 Attentive-LSTM 的模型架构
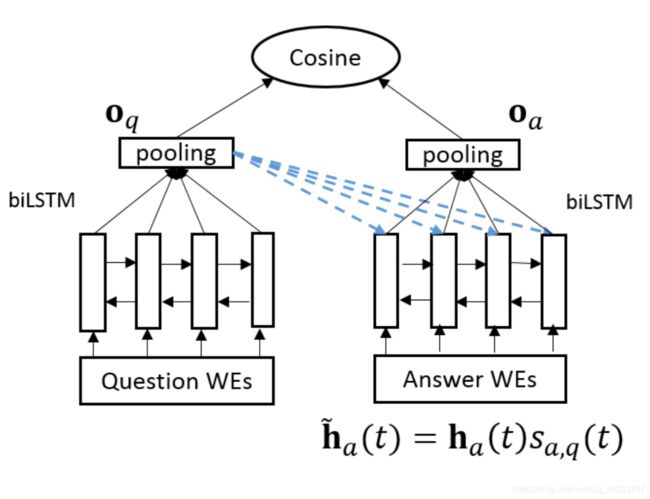
Tan et al. (2016) 提出了一种注意力LSTM, 它是QA-LSTM模型的变体,为了缓解另外两种变体 (基于卷积的LSTM和卷积池LSTM) 存在的一些问题 。前面的两个模型,在4.1节中描述,都有一个共同的问题,那就是答案很长,并且包含了很多与问题句无关的单词。在构建回答句子表征时考虑问题的注意机制可以解决这一问题。在该模型中,注意力机制是通过学习BiLSTM隐藏向量的权值来工作的。如图19所示,BiLSTM的输出乘以softMax权重(由问题表示获得)。该模型基于来自问题表示的信息,给予答案中的每个单词更多的权重。最后,答案句子的表示由下式表示:

其中 h a ( t ) h_a(t) ha(t) 在时间步 t t t 时答案BiLSTM的输出向量, o q o_q oq 是问题表示, W a m , W q m W_{am},W_{qm} Wam,Wqm和 W m s W_ms Wms 是注意力参数, h a ( t ) h_a(t) ha(t) 表示 h ~ a ( t ) \widetilde h_a(t) h a(t) 基于注意力的表示。
Wang et al. (2016a) 提出了四种基于内注意力的RNN模型。这些模型试图缓解传统的基于注意的RNN模型存在的注意力偏差问题。本文首先介绍了传统的基于注意力的神经网络模型,然后介绍了四种基于内注意力 (IARNN) 的神经网络模型。
- 传统的基于注意力的RNN模型( (OARNN)) :该算法首先利用RNN块对句子进行编码,然后利用问题嵌入的注意力权值生成答案句子的表示。这种注意力机制是在学习了嵌入、后面的隐藏状态的偏差后进行的 ,因为它们包含的信息比邻近的句子更多。OARNN 的架构如图20所示。该模型在RNN块之后加入了注意层,因此被命名为OARNN(即outer attention-based RNN)。最后一个隐含层或所有隐含状态的平均值作为问题句子的表示,其中答案的表示是利用问题表示中的注意权值得到的。
以下是图20: (Wang et al., 2016a) 中提出的OARNN 模型架构

- Inner attention-based RNNs (IARNN)::IARNN模型的提出,为了缓解 OARNN 在生成答案语句表示时存在的偏差问题。在这些模型中,在RNN块生成隐藏层之前添加注意力权重下面介绍四种不同IARNN模型的体系结构。
- IARNN-WORD:图21 是其架构。利用问题注意力权重生成每个词的表示,然后利用RNN模型得到整个句子的表示。GRU参数较少,训练速度快,因此在RNN块中选择GRU。句子的表示是由隐含状态 h t h_t ht 的加权平均值生成的。
以下是图21:(Wang et al., 2016a) 中提出的IARNN-word 模型架构
- IARNN-Context:由于IARNN-WORD模型无法捕捉多个相关词,在IARNN-Context中,答案句的上下文信息被输入注意力权重。该模型的架构如图22所示。
以下是图22: IARNN-Context 的模型架构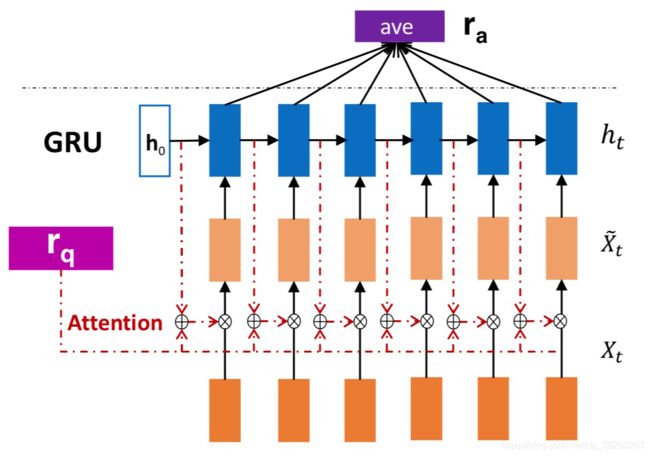
- IABRNN-GATE:由于GRU门在隐藏阶段控制信息流,因此注意力信息将馈送到这些门。 该模型的架构如图23所示。
以下是图23: IABRNN-GATE 的模型架构
- IARNN-OCCAM:这个模型是以奥卡姆剃刀的名字命名的,该意思是:“ 在整个单词集合之间,必须选择能代表句子的最少的单词。”根据问题的类型,回答问题需要不同数量的相关单词。例如,在答案句子中,“what” 和 “where” 的问题比 “why” 和 “how” 的问题需要更少的相关词。这个问题在 IARNN-OCCAM 中通过使用一个调节值来处理。因此,“what” 和 “where” 问题的注意力总和应该更加稀疏, “why” 和 “how” 问题应该分配较小的调节值。该调控模型可用于IARNN-context 和 IARNN-word 模型。
- IARNN-WORD:图21 是其架构。利用问题注意力权重生成每个词的表示,然后利用RNN模型得到整个句子的表示。GRU参数较少,训练速度快,因此在RNN块中选择GRU。句子的表示是由隐含状态 h t h_t ht 的加权平均值生成的。
Yin et al. (2016) 针对文本匹配任务,提出了四种基于注意力的BCNN变体(ABCNN)。下面将描述这些ABCNN模型的体系结构。
以下是图24: (Yin et al., 2016) 提出的 ABCNN-1 的模型架构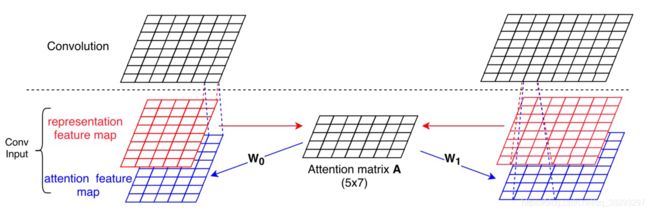
- Attention-based CNN (ABCNN):本文提出了三种不同的基于注意力的模型。在ABCNN-1中,如图24所示,通过比较两个特征图的每个单元,生成一个注意力矩阵 A A A 。令 S 1 S_1 S1 和 S 0 S_0 S0 表示句子的特征图。矩阵 A A A 的每一行表示 S 0 S_0 S0 中对应单元相对于 S 1 S_1 S1 的注意力分布, A A A 的每一列表示 S 1 S_1 S1 中对应单元相对于 S 0 S_0 S0 的注意力分布。然后将矩阵 A A A 转化为与表示特征图维数相同的两个注意力特征图矩阵。根据图24,将表示特征图和注意特征图作为 order-3 张量输入到卷积层。给出句子的两种特征映射的表示 i = 0 , 1 ( F i , r ∈ R d × s ) i = 0, 1 (F_{i,r} ∈ R^{d×s}) i=0,1(Fi,r∈Rd×s),在注意力矩阵( A ∈ R S × S A \in R^{S \times S} A∈RS×S)中的每个元胞计算如下:

其中, 1 1 + ∣ x − y ∣ \frac{1}{{1 + |x - y|}} 1+∣x−y∣1 是输入 x x x 和 y y y 的匹配得分函数。注意力矩阵 A A A 通过以下公式转换为两个给定的特征图( F 0 , a , F 1 , a F_{0, a}, F_{1, a} F0,a,F1,a),其中 W 0 , W 1 ∈ R d × s W_0,W_1 \in R^{d \times s} W0,W1∈Rd×s为需要学习的模型参数:
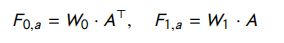
通过将这些矩阵传递给卷积层,可以生成相应句子的高级表示形式。 - ABCNN-2:在这个架构中(如图25所示),注意力机制应用于卷积层的输出。
以下是图25:(Yin et al., 2016) 提出的 ABCNN-2 架构
注意力矩阵 A A A 中的每个单元通过比较卷积输出的对应单元来计算。卷积输出矩阵的每一行表示给定句子的一个单元。每个单元的注意力权重是通过将该单元的所有注意力值相加得到的。第 i i i 句中单元 j j j 的注意力权重用 a i , j a_{ i,j} ai,j表示,计算如下:

然后,新的特征图 F i , r P ∈ R d × s i F_{i,r}^P \in R^{d \times s_i} Fi,rP∈Rd×si 使用 w-ap 池化计算如下:
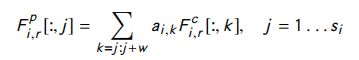
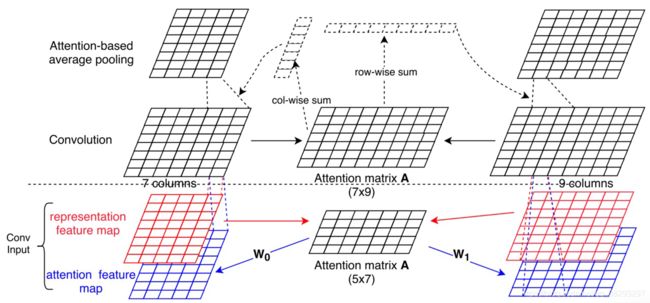
- ABCNN-3:如图26所示,ABCNN-3 利用卷积层前后的注意力机制,结合了之前的两个模型。卷积层的输出比输入的粒度大。这意味着如果卷积层的输入具有单词级的粒度,那么它的输出具有短语级的粒度。因此,在ABCNN-1模型中,注意力机制的粒度级别比ABCNN-2模型小,而在ABCNN-3模型中,注意机制的粒度级别又两个不同。
以下是图26:(Yin et al., 2016) 提出的 ABCNN-3 架构
Bian et al. (2017) 提出了一个估计问题 ( Q Q Q )和答案( A A A )之间的相关性得分 P ( y ∣ Q , A ) P(y |Q, A) P(y∣Q,A) 的模型。如图27所示,该模型由四个主要层组成。
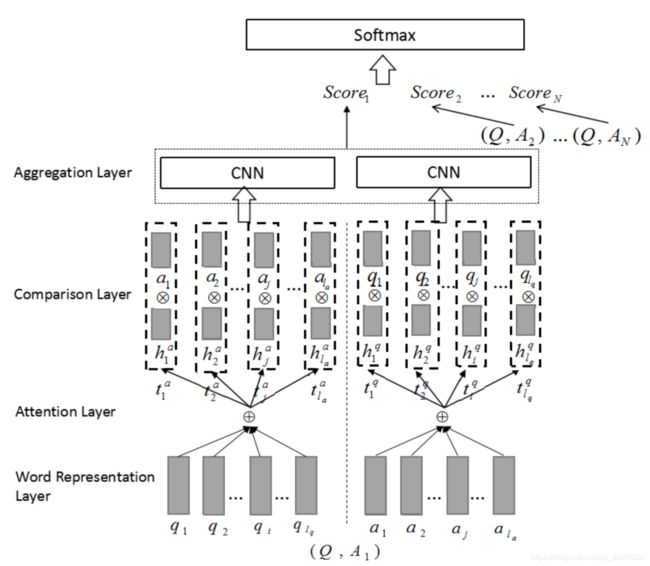
首先,将每个句子的 词表示送入一个注意力层,然后通过句子表示比较注意力层的输出。比较层的输出被送到一个CNN层进行聚合,然后得到两个给定句子在这一层的匹配得分。下面将对这些层进行描述。
- 词表示层: 问题 q = ( q 1 , … , q l q ) q = (q_1,…, q_{lq}) q=(q1,…,qlq) 和答案 a = ( a 1 , … , a l a ) a = (a_1,…, a_{la}) a=(a1,…,ala)的单词表示) 被喂入注意力层;
- 注意力层:应用注意力层的目的是寻找问题和答案对的局部文本子结构之间的关联。 h j a h_j^a hja 和 h i q h_i^q hiq 在这一层中由以下方程得到:
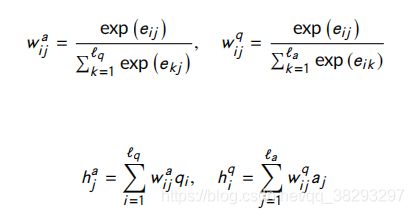
其中, e i j = q i ⋅ a j e_{ij} = q_i \cdot a_j eij=qi⋅aj , w w w 表示注意力权重。该注意力模型存在两个问题:一是两个句子之间只有少量的相互作用是相关的,考虑到不相关的相互作用,语义关系不明确。只考虑相关的相互作用是恰当的。第二,如果回答句中的一个token与 问句中的所有单词没有语义匹配,则最好删除该token。针对上述问题,提出了 k − m a x k-max k−max 注意力 和 k − t h r e s h o l d k-threshold k−threshold 注意力两种滤波方法。下面描述这两个滤波模型在计算 h j a h_{ja} hja 中的实现。
- k − m a x k-max k−max 注意力:该过滤模型通过将 w w w 按递减顺序排序,保留前 k k k 个权值,将其他权值设为零,以帮助丢弃不相关的片段。
- k − t h r e s h o l d k-threshold k−threshold 注意力:这种过滤只是保留了大于 k k k 的注意力权重。这种过滤的工作方式是省略另一个句子中没有语义匹配的单元。
- Comparison:在这一层中比较每一个句子和 在注意层中得到的另一个句子的加权版本。例如,利用比较函数 f f f 将 a j a_j aj 与 h j a h_{ja} hja 进行如下比较:
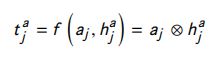
其中, t j a t_{ja} tja 表示比较结果。 - Aggregation:使用一层CNN对每个句子前一层的比较向量进行聚合,最后,问答句之间的相关性得分计算公式如下

Wang et al. (2017) 提出了Bilateral Multi-Perspective Matching Model (BiMPM),双边多角度匹配模型(BiMPM), paraphrase-based method。在BiMPM中,每个样本用 ( P , Q , y ) (P, Q, y) (P,Q,y) 表示,其中 P = ( p 1 , p 2 , … p M ) P = (p_1, p_2,…p_M) P=(p1,p2,…pM) 是长度为 M M M 的回答句, Q = ( q 1 , q 2 , … q N ) Q = (q_1, q_2,… q_N) Q=(q1,q2,…qN) 是长度为 N N N 的问题句, y = 0 , 1 y = 0,1 y=0,1 是一个标签,表示答案是否与问题相关。 y = 1 y = 1 y=1 意味着 P P P 是问题 Q Q Q 的相关答案,而 y = 0 y = 0 y=0 意味着 P P P不是问题 Q Q Q 的相关答案。下图是:图28显示了BiMPM的架构。
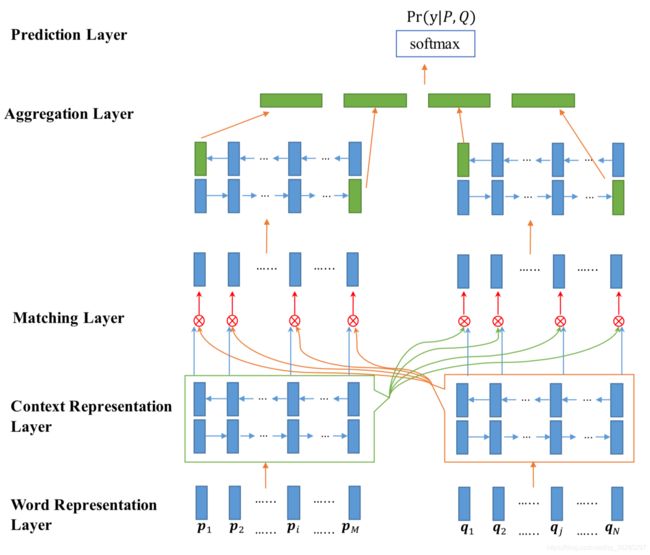
BiMPM由5个主要层组成,下面将对它们进行描述。
以下是图29: (Wang et al., 2017) 中提出的BiMPM-matchings 的架构

- 词表示层:每个单词都用一个由单词嵌入和一个由字符组成的嵌入组成的 d d d 维向量来表示。单词嵌入从预训练的 GloVe (Pennington et al., 2014) 或 word2vec (Mikolov et al., 2013) embeddings 中获得。字符组成的嵌入是通过将单词的字符输入到LSTM中生成的 (Hochreiter and Schmidhuber, 1997)。
- 上下文表示层:BiLSTM 用于将 句子的上下文信息与句子的表示形式结合起来。
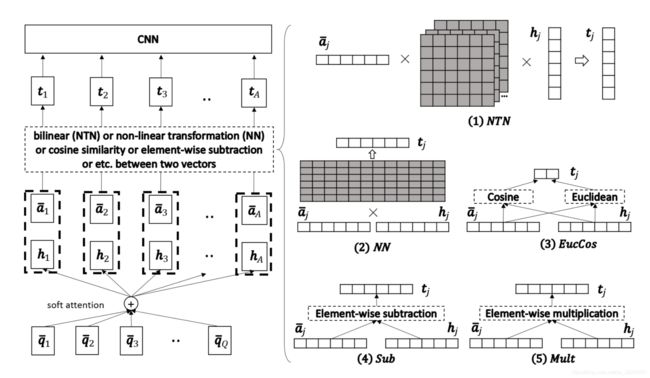
- 匹配层:在该层中,使用多视角匹配操作将一个句子的每一个上下文嵌入与另一个句子的所有上下文表示进行比较。同样,问题和回答句子在两个方向上匹配。多视角余弦匹配函数定义为: M = f m ( v 1 , v 2 ; W ) M = f_m(v_1,v_2;W) M=fm(v1,v2;W),其中, v 1 v_1 v1 和 v 2 v_2 v2 是 d d d 维向量, W ∈ R I × d W \in R^{I \times d} W∈RI×d 是 是可训练参数;每个视角都由 W W W 的一行 控制,而 M M M 是一个 l l l 维向量。每个 M k M_k Mk 计算如下:
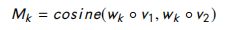
令 w k w_k wk 是 W W W 的第 k k k 行, ◦ ◦ ◦ 是element-wise 乘法;
基于不同的 f m f_m fm 函数,提出了四种不同的匹配策略。这些匹配策略如图29所示,并在下面针对其中一个方向进行了描述。
以下是图29:BiMPM-matchings 的架构
- Full-Matching:将回答句 h → i p \overrightarrow h^p_i hip 的每一个正向时间步表示 与问题句 h → N q \overrightarrow h^q_N hNq 的每一个正向时间步表示进行比较。该策略如图29 (a)所示。
- Maxpooling-Matching:返回 答案句子的每一个前向时间步表示与问题句子的所有前向时间步表示的最大相似度。该策略如图29 (b)所示。
- Attentive-Matching:答案句 h → i p \overrightarrow h^p_i hip 的每一个前向时间步表示与问题句 h → i q \overrightarrow h^q_i hiq 的每一个前向时间步表示之间的余弦相似度被视为注意力权重。该策略如图29 ©所示,然后通过使用注意力权值计算前向时间步表示的加权平均,生成问题句子( Q Q Q )的新表示,记作 h i m e a n h^{mean}_i himean 。最后,用其对应的注意向量 h i m e a n h^{mean}_i himean 计算每个时间步表示的答案句子的匹配向量。
- Max-Attentive-Matching:该策略与注意力匹配策略的不同之处仅在于生成注意力向量 h i m e a n h^{mean}_i himean 。此处的注意力向量是相似度最高的上下文嵌入。该策略如图29 (d)所示。最后,对于每个方向,在每个时间步应用所有这些策略,并将生成的 8 个向量拼接起来,视为该方向上的匹配。
- 聚合层:从匹配层获得的两个句子的匹配向量的两个序列,被输入到BiLSTM中。 然后,通过串联两个BiLSTM的最后四个输出向量来获得固定长度的匹配向量。
- 预测层:在这一层中, P ( y ∣ P , Q ) P(y |P, Q) P(y∣P,Q) 的预测使用了一个两层前馈神经网络,然后跟softMax层。固定长度的匹配向量被提供给这一层。
Wang and Jiang (2017) 提出了两个句子匹配的 compare-aggregate 模型。对于每一对 Q Q Q 和 A A A,这个模型预测了一个标签 y y y,这个标签 y y y 表示候选答案 A A A 对于问题 Q Q Q 是否正确。
以下是图30:Wang and Jiang (2017) 提出的 (compare-aggregate) 模型架构
根据该模型的架构(如图30所示),该模型由以下四个主要层组成。
- 预处理层:这一层为每个单词构造一个嵌入,它代表单词及其上下文信息。 Q Q Q 和 A A A 是这一层的输入。一个版本的LSTM/GRU,它只使用输入门,被用于生成 Q ‾ ∈ R I × Q \overline Q \in R^{I \times Q} Q∈RI×Q 和 A ‾ ∈ R I × A \overline A \in R^{I \times A} A∈RI×A矩阵。
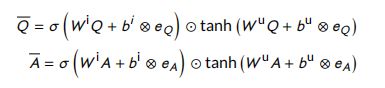
其中, W i , W u ∈ R I × d {W^i},{W^u} \in {R^{I \times d}} Wi,Wu∈RI×d 和 b i , b u ∈ R I {b^i},{b^u} \in {R^I} bi,bu∈RI 是参数。 ( . ⊗ e X ) (. \otimes {e_X}) (.⊗eX) 通过在左边重复这个向量 X X X 次生成一个矩阵。 - 注意力层:此层应用于前一层的输出。注意力加权向量 H ∈ R I × A H \in {R^{I \times A}} H∈RI×A 由下式得到。 H H H 的第 j j j 列表示 Q Q Q 中与 A A A 中第 j j j 个单词匹配最好的部分。

其中, W g ∈ R I × I W^g \in R^{I \times I} Wg∈RI×I 和 b g ∈ R b^g \in R bg∈R 是参数, G ∈ R Q × A G \in R^{Q \times A} G∈RQ×A 是注意力权重矩阵。
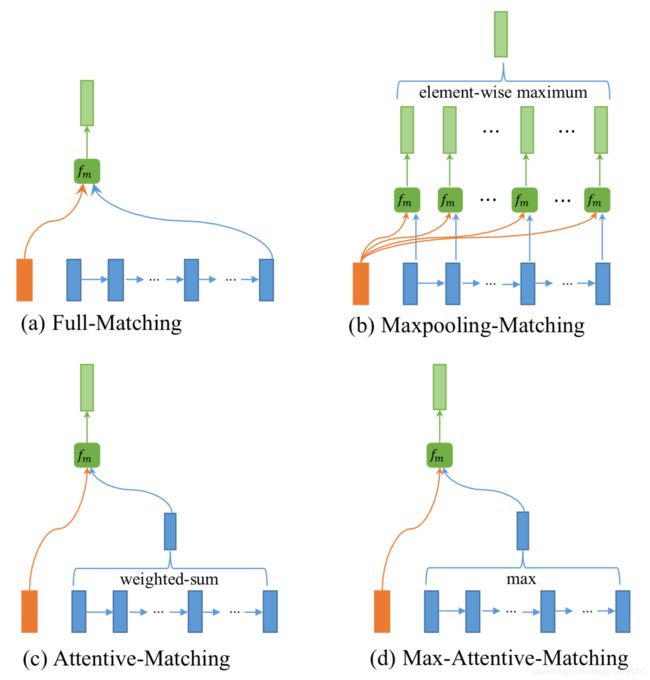
- Comparison layer:将答案中每个单词 a j a_j aj 的嵌入 与对应的注意力权重 h j h_j hj 进行匹配,用向量 t j t_j tj 表示比较结果。本文介绍了六种不同的比较函数。
- Neural Net (NN):
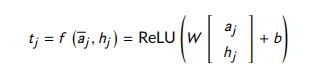
- Neural Tensor Net (NTN)

- Euclidean distance or cosine similarity (EucCos):
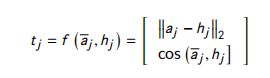
- Subtraction (Sub):
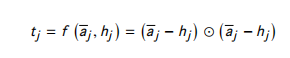
- Multiplication (Mult)

- Submult + NN
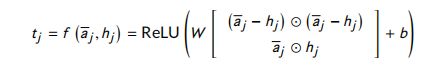
在这些比较函数中,NN 和 NTN 不能很好地捕捉相似性。EucCos 可能会忽略一些重要的信息。Sub 与 Mult 类似于 欧氏距离和余弦相似度,最终模型是Sub, Mult, 和 NN的结合。
- Aggregation:使用单层CNN组合 t j t_j tj 向量。聚合的输出为 r ∈ r n l r∈r^{nl} r∈rnl ,用于最终的分类器。
r = C N N ( [ t 1 , t 2 , . . . , t A ] ) r = CNN([t_1,t_2,...,t_A]) r=CNN([t1,t2,...,tA])
Tay et al. (2018):对于基于检索的QA,提出了 Multi-Cast Attention Network (MCAN)。MCAN的输入是两个句子:问题 q q q 和文档 d d d 。如图31所示,MCAN有五个主要层。下面将对这些层进行描述。
以下是图31: (Tay et al., 2018) 提出的MCAN 模型架构
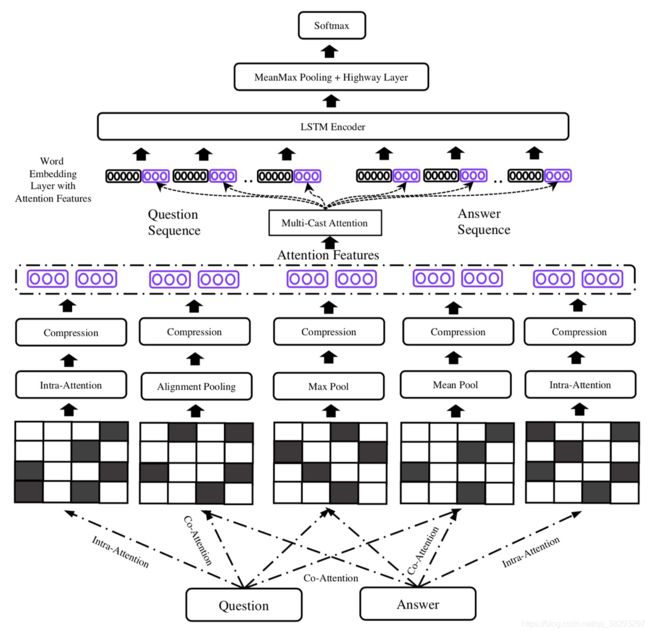
-
输入编码器:输入句子以独热编码向量的形式输入到网络中,单词嵌入通过嵌入层生成。像RNNs这样的 Highway 编码器通过使用门控机制来控制信息流。 Highway 编码器层 用于检测给定句子中的重要词和不重要词。A single highway network is formulated as:
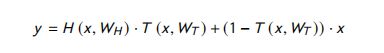
其中, H ( ⋅ ) H(\cdot) H(⋅) 和 T ( ⋅ ) T(\cdot) T(⋅) 是一层使用 ReLU和 sigmoid 激活函数 的仿射变换。 W H , W T ∈ R r × d W_H,W_T \in R^{r \times d} WH,WT∈Rr×d -
Co-Attention:在这一层中,通过以下公式来学习表示两句中每对单词之间相似度的相似度矩阵:
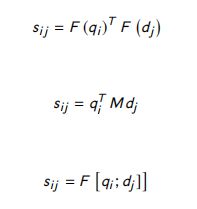
其中, F F F 是一个多层的感知机。
- a. Extractive Pooling:最大池化和平均池化是两种变体。这两个池化的公式如下:

其中, S o f t Soft Soft 是 softMax 函数, d ′ d' d′ 和 q ′ q' q′ 是文档和问题的co-attentive表示。在不同的数据集上,这些pool的性能各不相同,但一般来说,max-pooling根据词汇的最大影响来关注词汇,mean-pooling根据词汇对另一个句子的词汇的总影响来关注词汇。 - b. Alignment pooling:在这个池策略中,来自两个句子的词对被重新排列。Co-attentive 表示的学习如下:
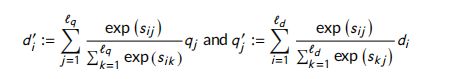
令 KaTeX parse error: Expected group after '^' at position 4: d_i^̲' 是是 q q q 与 d i d_i di 对齐的子短语。 - c. Intra-attention:内部注意力试图在一句话中表表示出长期依赖关系。每个句子的表示 与其他句子无关。因此,它分别应用于文档和问题。 Co-attentive 表示的学习如下:
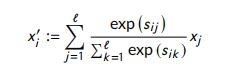
令 KaTeX parse error: Expected group after '^' at position 4: x_i^̲' 是 x i x_i xi 内部注意力表示。
-
Multi-Cast Attention(多播注意力):这个模型利用了所有提到的池功能。下面的值是计算每个 co-attention 函数的输出。
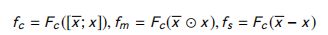
式中, x ‾ \overline x x 为 x x x 的co-attention 表示, F C F_C FC 为压缩函数。在上述公式中, x ‾ \overline x x 和 x x x是通过三种不同的算子来比较的,从不同的角度来建模 x ‾ \overline x x 和 x x x 之间的差异。 x ‾ \overline x x 和 x x x 之间的差是一个 n n n 维向量,它被压缩函数压缩成标量。使用了三种不同的压缩函数:总和、全连接层和因子分解机(FM)。如图31所示,给定一个文档问题对,对问题和文档采用三种不同的池化策略 (1) mean-pooling, (2) Max-pooling, (3)alignment-pooling,对文档和问题分别采用 (4) Intra-attention。为每个单词生成12个标量,并用 词嵌入 进行拼接。将每个单词 w i w_i wi 表示为 w i = [ w i ; z i ] w_i = [w_i;z_i] wi=[wi;zi] 为 multi-cast 层的输出,其中 z ∈ R 12 z \in R^{12} z∈R12。 -
LSTM encoder:将多播注意力所产生的句子词的Casted 表示 馈送给LSTM编码器,并对LSTM的隐藏状态应用 meanMax 池。词汇的Casted 表示方式有助于LSTM网络利用其对每个句子以及问题与文档之间的知识来提取长期依赖关系。
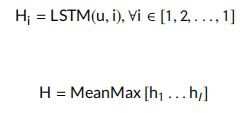
-
Prediction layer and optimization:给定文档和问题的表示形式,采用双层highway 网和 softMax层进行预测计算如下:
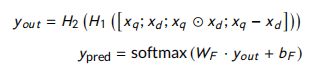
其中, H 1 H_1 H1 和 H 2 H_2 H2 有ReLU函数激活的highway 网网络层, W F ∈ R h × 2 , b F ∈ R 2 W_F \in R^{h \times 2},b_F \in R^2 WF∈Rh×2,bF∈R2。
Yoon et al. (2019) 针对给定一对问题 ( Q = q 1 , . . . , q n ) (Q=q_1,...,q_n) (Q=q1,...,qn)和 答案 ( A = a 1 , . . . , a n ) (A = a1,...,a_n) (A=a1,...,an),提出了 CompClip 来预测匹配得分 ( y ) (y) (y)。为了提高 CompClip 的性能,他们应用迁移学习技术来在 NLI (QNLI)问答语料库中(Wang et al., 2018)做训练。他们还使用 pointwise 学习排序的方法来训练这个模型。他们的工作最突出的特点是使用ELMo语言模型来获取问答句中更有意义的上下文信息。CompClip 的架构由六层组成,如图32所示。下面将对这些层进行描述。
以下是 图32:Yoon et al. (2019) 提出的 CompClip 模型架构
- 语言模型:使用Elmo语言模型(Peters et al. 2018)来更高效地提取给定句子的上下文信息,而不是使用单词嵌入层。在应用ELMo语言模型后,一个新的问题和答案表示分别为 L Q L^Q LQ 和 L A L^A LA 。
- 上下文表示:该模型部分学习权重 W W W,用于提取给定句子的上下文信息,并通过以下公式生成其上下文表示:
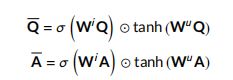
- Attention:利用dynamic-clip attention (Bian et al. 2017)生成问题 H Q H^Q HQ 和答案 H A H^A HA 句子的注意力表示如下:

- Comparison:每个术语形式的问题和回答句子的比较,由问题和回答表示与H A和H Q的元素明智的乘法。
通过分别将问题和答案表示与 H A H^A HA 和 H Q H^Q HQ 进行逐元素相乘,比较每个术语形式的问题和答案句子。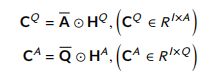
- Aggregation layer:对于比较层的聚合输出,我们使用一个带有 n n n 种滤波器的CNN。这一层的目标是计算问题与答案之间的匹配分数 ( s c o r e ) (score) (score),具体如下:
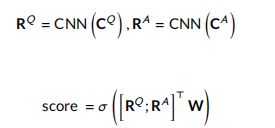
- Latent clustering:为了提高模型的性能,将语料库的潜在聚类信息用于获取问答句的聚类信息。 使用以下等式生成句子 s s s 的潜在聚类信息:
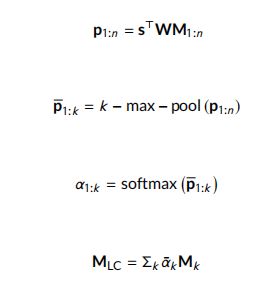
其中, M 1 : n ∈ R d ′ × n M_{1:n} \in R^{d' \times n} M1:n∈Rd′×n 是潜在记忆, W ∈ R d × d ′ W ∈ R^{d×d'} W∈Rd×d′ 是模型参数。将潜在聚类函数 f f f 应用于问答句的上下文表示,分别生成问答类的聚类信息,即 M L C Q M^Q_{LC} MLCQ 和 M L C A M^A_{LC} MLCA 向量。将 M L C Q M^Q_{LC} MLCQ 和 M L C A M^A_{LC} MLCA 与 C Q C^Q CQ 和 C A C^A CA 拼接,分别生成 C n e w Q C^Q_{new} CnewQ 和 C n e w A C^A_{new} CnewA 的新表示。可以将 C n e w Q C^Q_{new} CnewQ 和 C n e w A C^A_{new} CnewA 视为聚合层的输入。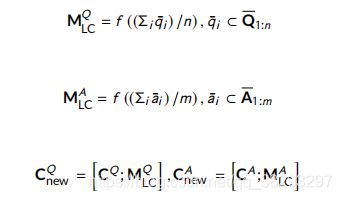
Yang et al. (2019) 提出了一种文本匹配模型——RE2模型。RE2是一个简单快速的模型,可以从两个给定的序列中提取更有效的特征。RE2这个名称来源于该模型使用的增强特征:残差向量、嵌入向量和编码向量。RE2包括两个不同的组件,它们具有用于处理每个序列的共享参数,以及在这两个组件之上的一个预测层。处理给定文本的组件包括 N N N 个相同的块。RE2的体系结构如图33所示。
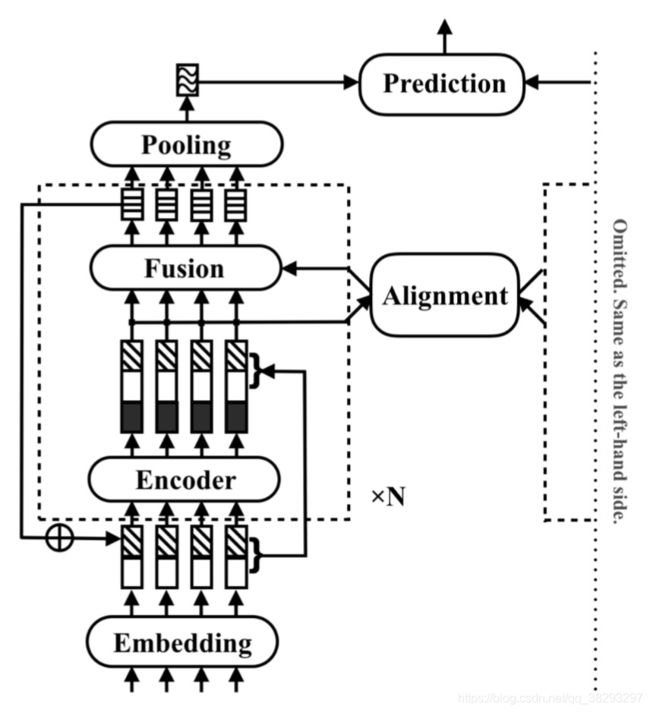
下面将对该模型的每个组件进行描述。
-
Augmented Residual Connections(增强残差连接):块之间通过残差连接彼此进行连接。第一个块的输入是单词嵌入。其他块的输入构造如下:

其中, x i ( n ) x_i^{(n)} xi(n) 是对于 n > 2 n >2 n>2 时第 n n n 块 的输入的第 i i i 个token。 o i ( n ) o_i^{(n)} oi(n) 是第 n n n 块 的输出的第 i i i 个token -
Alignment Layer : 为了对齐两个文本序列 a a a 和 b b b,使用了一个简单的注意力机制来建模两个给定序列 a ′ a' a′ 和 b ′ b' b′ 的注意力表示。
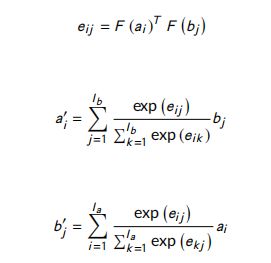
其中, F F F 是一个前馈神经网络。 -
Fusion Layer:该层从三个角度比较对齐的和简单的表示,并合并结果。

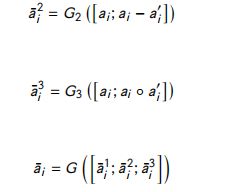
其中, G 1 , G 2 , G 3 G_1,G_2,G_3 G1,G2,G3 和 G G G 是单层 前馈神经网络。 -
Prediction Layer:两个并行组件部署池化层后的输出:用于创建多层前馈网络的输入,用于预测得分 y y y,如下:
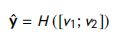
其中, v 1 v_1 v1 和 v 2 v_2 v2 两个文本匹配组件的输出; H H H 是 一个多层前馈网络。
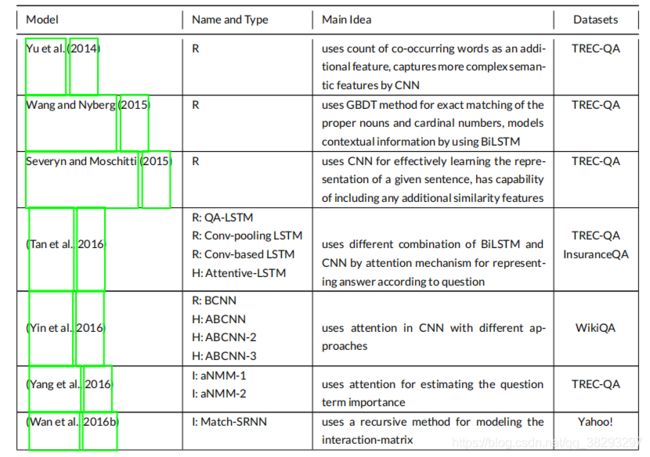
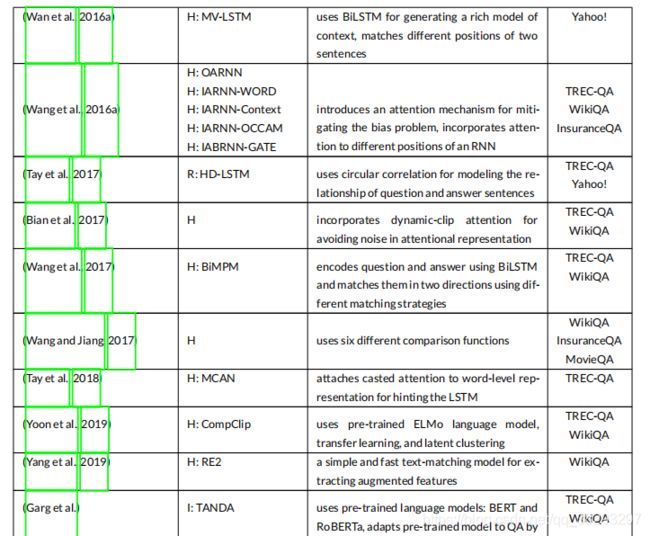
考虑到本节中所描述的所有模型,表2给出了基于深度学习的模型的简要概述。
以下是表2:基于深度学习的模型概述( I I I :基于交互, R R R :基于表示, H H H :混合)
5. QA 的数据集
在本节中,我们将描述五个被广泛用于评估QA任务的数据集。
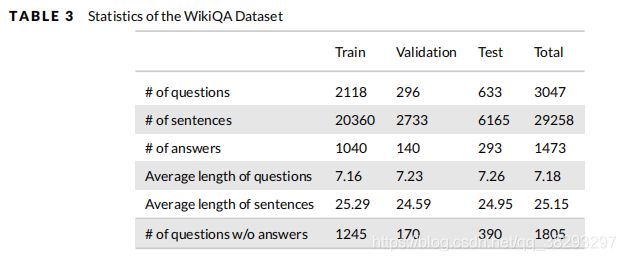
- WikiQA 是一个开放域的QA数据集 (Yang et al., 2015)。此数据集是从必应查询日志中收集的。本数据集中选取至少5个不同用户发布并点击到Wikipedia页面的类问题作为问题,并将对应Wikipedia页面的summary 部分的句子作为相关问题的候选答案。通过众包将候选答案贴上正确或错误的标签,然后选出正确的答案。这个数据集由3047个问题和1473个答案组成,更多关于这个数据集的统计信息见表3。WikiQA的一个值得注意的特性是,这个数据集中的问题并不是所有的都有正确的答案,这使得使用这个数据集中的答案触发组件成为可能。答案触发组件的任务是找出问题是否有答案。
- TREC-QA 收集自文本检索会议(Text REtrieval Conference,TREC) 8-13 QA数据集(Wang et al. 2007)。采用TREC 8-12中的问题作为训练数据集,TREC 13中的问题作为开发和测试数据集。TREC-QA 数据集的统计情况见表4。TREC-QA 包含两个训练数据集:TRAIN和TRAIN- ALL。TRAIN 数据集包含TREC 8-12的前94个问题,候选答案是人工评判的,而TRAIN-ALL 数据集通过将答案与答案正则表达式的预定义模式 进行匹配来识别正确答案。
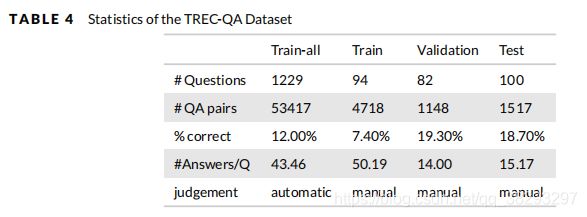
- MovieQA 来自不同的数据源 (Tapaswi et al. 2016),这是该数据集的一个独特的特征。它包含14944个问题,每个问题与五个答案相关,包括一个正确答案和四个欺骗的答案。该数据集的统计数据见表5。
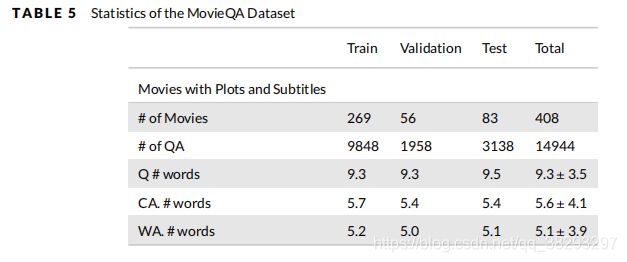
- InsuranceQA 是一个用于保险领域QA的封闭域数据集(Feng et al. 2015)。此数据集的问题/答案对是从互联网上收集的。这个数据集包括Train, Development, Test1, Test2部分。关于 InsuranceQA 的更详细的统计信息见表6。
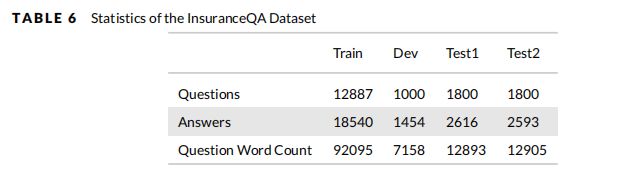
- Yahoo! Dataset 是收集从Yahoo! Answers QA 系统。Yahoo! 包括142,627对问题/答案。但是在文献(Wan et al. 2016b,a)中, 选取了该数据集的一个子集作为正对,并对该子集中的每个问题构造了另外四个负对。选择问题和答案长度在5 - 50个单词之间的(问题,答案)对为正对(包括60564对)。每个问题的四个否定答案是由正确答案 通过查询整个答案集合,并从前1000个检索答案中随机选择四个答案。
6. 评估
在QA评价中,采用了 Mean Reciprocal Rank (MRR)、 Mean Average Precision (MAP) 和 accuracy 三个指标 。
- MRR 表示系统回答问题的能力。一个问题的 倒数秩 (Reciprocal Rank,RR) 是第一个正确答案顺序的倒数(如果有正确答案),如果没有正确答案,倒数为零。计算每个问题的RR ,取其平均值为MRR:

- 第二个度量是 MAP。MAP是在检测到正确答案时,每一等级准确度平均值的平均值(Diefenbach et al. 2018)。 P r e c i s i o n @ k Precision@k Precision@k 是检索到的前 k k k 个答案中正确答案的比例。Precision 表示有多少答案是正确的,计算如下:

其中, k k k is the rank of correctly retrieved answers - Accuracy 用于评估问题只有一个正确答案或一个标签的数据集。准确性表示有多少问题得到了正确的回答:

7. 文献中的结果
如第5部分所述,WikiQA (Yang et al. 2015)、TREC-QA (Wang et al. 2007)、MovieQA (Tapaswi et al. 2016)、InsuranceQA (Feng et al. 2015)和Yahoo! (Wan et al. 2016b,a) 是用于评估基于文本的QA系统的主要数据集。在本节中,我们报告了在提到的数据集上不同模型的结果,以比较最先进的模型的质量。需要指出的是,考虑到本文回顾的模型数量众多,不可能对所有模型进行复现来进行全面的比较,我们只根据它们论文中的可用性来报告结果。
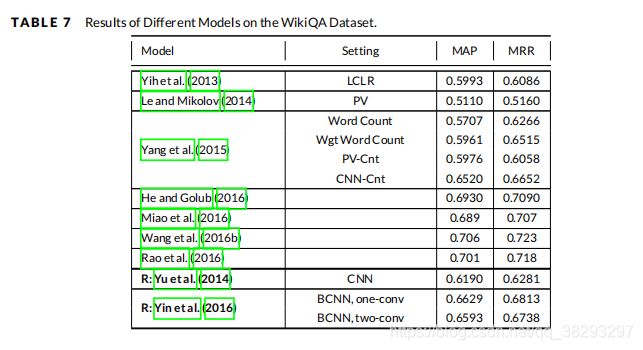
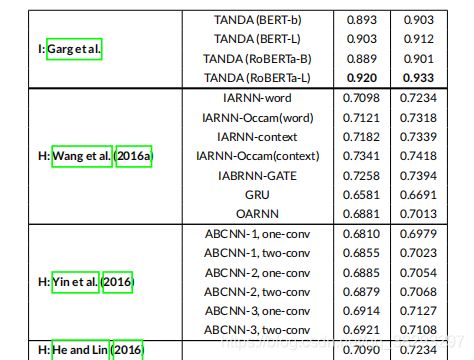
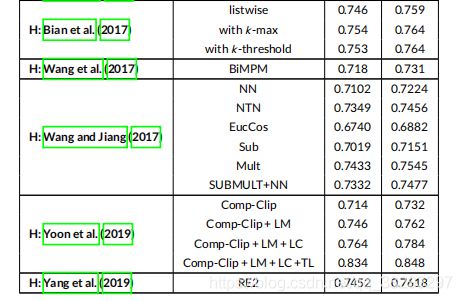
表7报告了基于表示( R R R )、基于交互( I I I ) 和 混合 ( H H H )方法对WikiQA 数据集的结果,并将其与其他基线模型进行了比较。可以看到,TANDA ( Garg et al. )在 WikiQA 数据集的 MRR 和 MAP 度量中取得了最好的结果。尽管这种基于交互的技术是该领域中最先进的模型,但是比较其他模型,我们可以看到混合模型的总体性能要优于基于交互的模型,而次优的结果都来自混合模型。
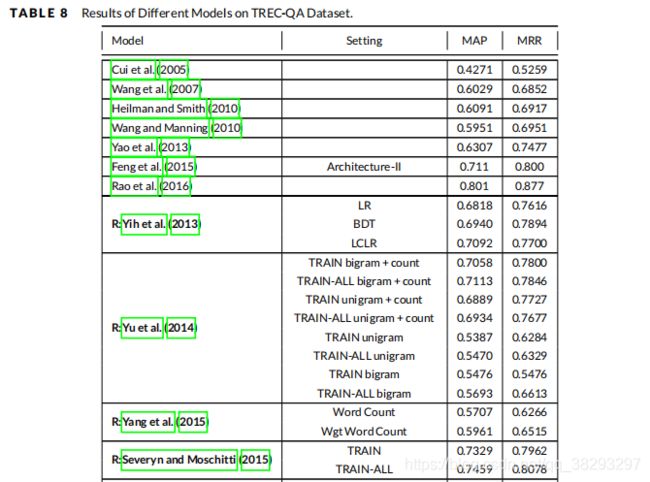
表8报告了第6节中描述的不同模型的结果以及它们关于 TREC-QA 数据集的基线方法。根据该表,TANDA (Garg et al.) 模型在 MAP 中取得了最好的结果。
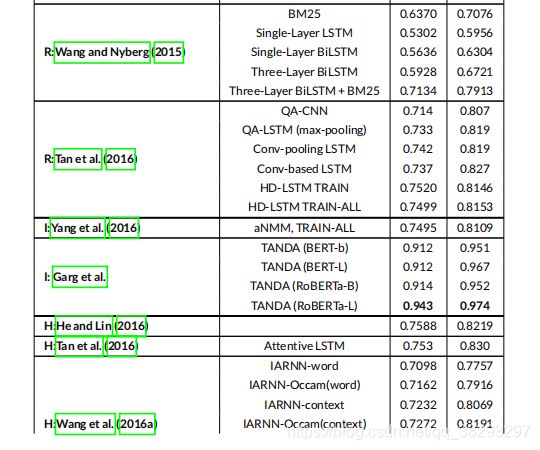
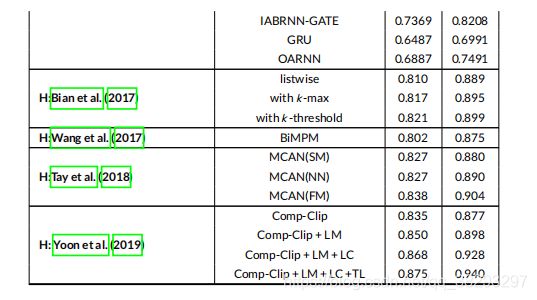
第6节中不同模型的性能 和他们的基线在 Yahoo! 数据集中的报告在表9中。一个基于表示的模型(Tay et al. 2017)、一个基于交互的模型(Wan et al. 2016b)和一个混合模型(Wan et al. 2016a)在 Yahoo! 数据集上评估。可以看出, (Wan et al. 2016b) 提出的Bi-Match-SRNN在P@1和MRR指标上优于其他模型。这是唯一一个基于交互的模型(即Bi-Match-SRNN) 比 混合模型表现更好的数据集。
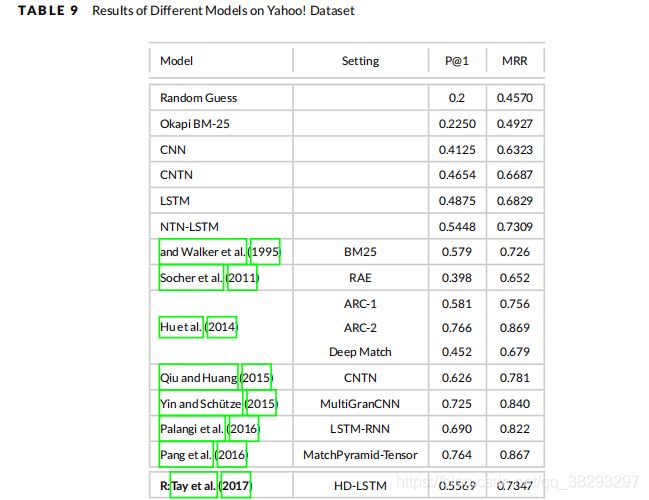
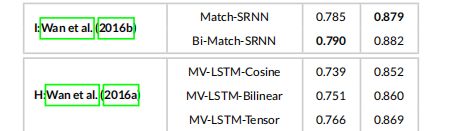
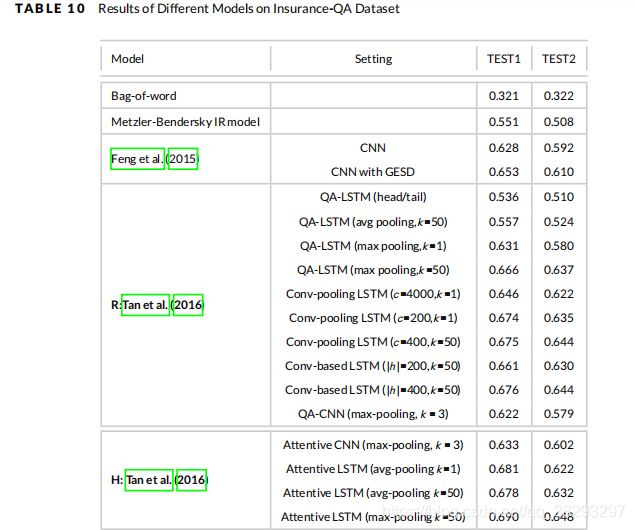
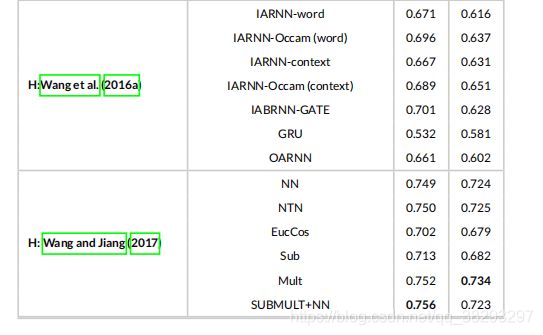
表10报告了 Insurance-QA 数据集上不同模型的结果。在三种深度模型 (基于表示、基于交互和混合模型) 中,混合模型在 Insurance-QA 数据集上也达到了最好的准确率。Wang and Jiang (2017) 提出的模型在 TEST1 上使用 SUBMULT+NN 比较函数,在 TEST2 上使用 Mult 比较函数,得到了最佳的精度。
8. 讨论
在QA中使用深度神经网络消除了人工特征工程。在基于表示的模型中,对每个句子的上下文表示分别建模,然后进行比较。
Yu et al. (2014) 和 Wang and Nyberg (2015) 使用分布语义模型为文本生成上下文化的表示。 Yu et al. (2014) 利用CNN捕捉句子中短语之间的局部依赖关系。CNN上的平均池有助于创建整个句子的意义表示。CNNs 能够在给定的窗口中捕获句子的复杂语义。Wang and Nyberg (2015) 利用 BiLSTM 创建了一个感知较长依赖关系的表示。
在问答句中 专有名词 与 基数 的匹配是一个重要问题。这意味着如果两个句子中的专有名词不匹配,就有足够的理由拒绝这个答案。但是,使用预先训练好的单词嵌入不仅不能区分这些名称,而且还考虑了它们的相近表示。为了缓解这一问题,Yu et al.(2014) 使用了 共现词计数 作为特征,Wang and Nyberg(2015) 使用 GBDT 来精确匹配问答句。
Yin et al. (2016) 和 Severyn and Moschitti (2015) 在他们的架构中使用了CNNs。Severyn and Moschitti (2015) 使用CNN嵌入输入文本,并提出了一个能够添加其他附加特性的架构。Yin et al. (2016) 使用了宽卷积。Tay et al. (2017) 使用全息合成来更好地建模问答关系。他们利用循环相关性( circular correlation)丰富了两个嵌入的聚合。 Tan et al. (2016) CNN和BiLSTM在不同模型中的不同组合。他们使用位于BiLSTM顶部的CNN从文本中获取更丰富的信息,使用位于CNN顶部的BiLSTM 从CNN提取的局部 n-gram 中获取长时依赖关系。将CNN和BiLSTM结合使用,有助于缓解CNN在捕获给定文本中长依赖关系之间的相似性方面的不足。
基于表示的模型在不同的组件上分别为每个句子构建嵌入。尽管它们很简单,并且通常在两个独立组件之间使用共享参数,但它们无法从问答句中捕获每对 token 之间的匹配。基于交互的模型通过在给定句子的每个词之间直接交互来解决这个问题。Yang et al. (2016) 通过将问题的每个 token 与答案的每个 token 进行比较,生成一个匹配矩阵,并使用attention来指定每个问题项的重要程度。 Wan et al. (2016b) 利用GRU提出了一种特殊的递归模型来建模两个序列之间的交互作用。
使用像 Peters et al. (2017), Radford et al. (2018), Devlin et al. (2019)这样的预训练语言模型最近吸引了研究人员,并在许多下游NLP任务中取得了重要进展。预训练的语言模型也被应用到QA任务中,包括当前最先进的模型。TANDA是一种基于文本的QA模型,它使用 Bert 和 Roberta 对问答句之间的上下文关系进行建模。由于在这些预训练的模型中使用了 Transformers,通过使用多头注意机制来建模每个给定 token 的上下文表示,我们将这些模型分类为基于交互的模型。
Wan et al. (2016a) 和 He and Lin (2016) 使用BiLSTM创建每个句子的表示,然后在每个 token 的新表示的顶部构建匹配矩阵。 He and Lin (2016) 通过连接不同的相似性度量来生成交互矩阵。他们利用CNN来发现一对单词之间的强相互作用。在他们的模型中,交互矩阵是通过使用三个不同的相似度度量来比较每一对 token 来建立的,相似度焦点用于根据它们的重要程度来分配交互的权重。 Wan et al. (2016a) 通过使用BiLSTM捕获了每个 token 丰富的上下文化的局部信息,并使用三个不同的相似性度量来构建交互张量。
混合模型结合了交互模型和表示模型。它们由一个表示组件和一个交互组件组成,该表示组件将一个单词序列组合成一个固定的 d d d 维表示。在大多数混合模型中,注意力机制用于通过关注其他句子来生成更丰富的答案或者问题句子的表征。
我们认为注意机制是一种交互组件,因为每个token 的注意权重是基于与两个句子的交互来计算的。 Tan et al. (2016) 在他们提出的 Attentive-LSTM 模型中,使用注意力机制为 回答语句 生成 问题感知表示。他们 为问题句子使用LSTM输出,为每个答案句子tokens 加权。RNNs 的最后一个隐藏状态承载了更多关于句子的信息,这使得注意力倾向于后面的隐藏状态。Wang et al. (2016a)利用了RNN的词、上下文和门级中的注意机制。Yin et al. (2016) 提出了第一个将注意机制纳入CNN的模型。
Bian et al.(2017)、Wang et al.(2017)、Wang and Jiang(2017)、Yoon et al.(2019) 和 Yang et al.(2019) 提出的模型遵循一种 compare-aggregate 架构。一般情况下,问答句中相关词的数量较少,将这些无关词的注意力权重的总和影响相关词的影响。为了缓解这一问题,Bian et al. (2017) 引入了一种新的注意力机制,采用了更符合排序性质的列表排序(list-wise ranking)而不是点排序(point-wise ranking)。
Wang et al.(2017) 从两个方向和多个角度对问题和答案进行匹配。Wang and Jiang(2017) 从问题的角度 使用不同的比较函数 将答案表征与答案的注意力表征进行匹配。
Yoon et al. (2019) 通过迁移学习利用了CompClip的性能。他们还使用ELMo语言模型从问答句中获取更有意义的上下文信息。Tay et al. (2018)为每个单词生成新的嵌入,并使用新嵌入和主词嵌入的拼接。新词嵌入是通过多次投射共同注意( casting the co-attention multiple times)来构建的。换句话说,它 cast 了注意力,而不是把它作为一种池化策略。RE2 (Yang et al. 2019) 通过使用简单的注意力机制对两个句子进行对齐,并使用增强的残差连接,从两个句子中提取出更多信息特征。RE2有一个非常简单和快速的架构,使用最小的参数数量,并且不使用慢速的RNNs。
我们讨论了每个模型的主要特性,发现目前最先进的技术包括使用预先训练好的语言模型的模型,如BERT。同时,表示模型具有最简单的架构,交互模型可以从两个句子的语义关系中提取更丰富的信息。混合模型是这两种模型的结合,通常采用注意力机制。注意力机制有助于在另一个句子的基础上创造更好的表征。这些模型中的大多数遵循 compare-aggregate 架构。注意力机制对QA产生了重大影响。在BERT的结构中也采用了多头注意。利用这一机制并在大量数据集上对其进行预训练,为从文本中提取丰富的语义表示提供了一个强大的模型。
9. 结论
在本文中,我们对基于文本的QA系统的最新方法进行了全面的评述。我们首先介绍了QA系统的一般架构,然后提出了该领域现有出版文章的分类。在第一步中,出版文章被分为两类:基于信息检索的技术和基于深度学习的技术。我们回顾了来自这两个类别的主要方法,并通过遵循众所周知的神经文本匹配的分类法,即基于表示、基于交互和混合模型,更详细地强调了基于深度学习的方法。具有深度学习观点的现有出版 被分类在这些类别中。我们还回顾了广泛用于训练、验证和测试基于文本的QA方法的可用数据集。文中给出了不同技术在这些数据集上的可用结果,对这些技术进行了简单的比较。
10. 图摘
基于文本的问答 在信息检索领域得到了广泛的研究。随着深度学习(DL)技术的出现,各种基于 DL 的方法被用于此任务,但这些方法尚未得到很好的研究和比较。在本文中,我们 为QA提出的不同模型 提供了一个全面的概述, 包括传统的IR视角和 近期的DL视角。