吴恩达 机器学习2022 第一课
一共有三个部分:Supervised Machine Learning: Regression and Classification,Advanced Learning Algorithms,Unsupervised Learning, Recommenders, Reinforcement
逻辑回归的代价函数 7.1 Cost function for logistic regression_哔哩哔哩_bilibili
Introduction
AGI即Artificial general intelligence的简写,人工通用智能
AGI源于AI,但是由于主流AI研究逐渐走向某一领域的智能化(如机器视觉、语音输入等),因此为了与它们相区分,增加了general
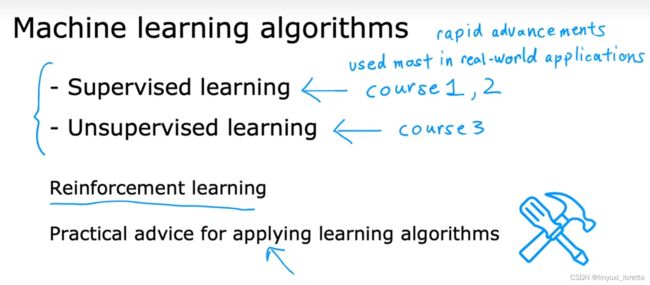
学习算法最常用两个类型就是监督学习、无监督学习。
监督学习是指,我们将教计算机如何去完成任务,
而在无监督学习中,我们打算让它自己进行学习。

数据集“正确答案”

这个“房价预测”例子是一种特殊类型的监督学习,regression
另一种监督学习的类型“classification”



学习算法可能会找到一些边界,通过数据拟合出boundary
怎么处理无限多个特征,甚至怎么存储这些特 征都存在问题,你电脑的内存肯定不够用。我们以后会讲一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。想象一下,我没有写下这两种和右边的三种特征,而是在一个无限长的列表里面,一直写一直写不停的写,写下无限多个特征,

1 - 4 - Unsupervised Learning
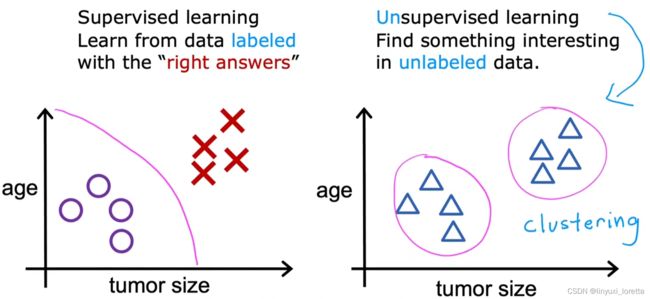
we call it unsupervised because we're not trying to supervise the algorithm.
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。
这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同
的簇。所以叫做聚类算法(clustering algorithm)。

what's cool is that this clustering algorithm figures out on his own which words suggest, that certain articles are in the same group.

some other types of unsupervised learning algorithms.

anomaly detection异常检测,用于 金融系统中的欺诈检测 fraud detection in the financial system,
dimensionality reduction降维.
The most widely used tool by machine learning and data science practitioners today is the Jupyter Notebooks .
Linear Regression Model
监督学习过程完整的流程
the first model of this course, Linear Regression Model.
线性回归模型是一种特殊的监督学习模型,叫做回归模型
Linear regression is one example of a regression model.




why use linear func.?
sometimes you want to fit more complex non-linear functions as well, like a curve
But since this linear function is relatively simple and easy to work with, let's use a line as a foundation that will eventually help you to get to more complex models that are non-linear.
cost func.

the cost function will tell us how well the model is doing so that we can try to get
it to do better.
the squared error cost function is by far the most commonly used one for linear regression and for that matter, for all regression problems where it seems to give good results for many applications.
3D表面图
contour plot等高线图

github上有源码,用jupyter打开lab的文件
week1下的work文件夹里的lab04文件
4.1 梯度下降
一种自动查找参数w和b的值,提供最佳拟合线 的算法-----梯度下降

the most advanced NN models, also called deep learning models.
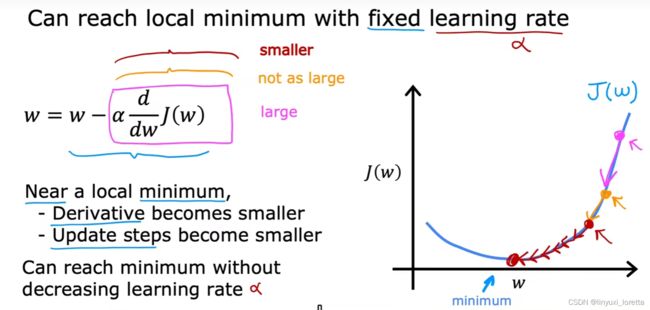
What this expression is saying is, after your parameter w by taking the current value of w and adjusting it a small amount,
α learning rate.
usually a small positive number between 0 and 1 and it might be say, 0.01.
What Alpha does is, it basically controls how big of a step you take downhill.
导数项 in which direction you want to take your baby step.
4.2 梯度下降的实现
assignment operations 赋值操作
repeat these two update steps until the algorithm converges.
By converges, I mean that you reach the point at a local minimum where the parameters w and b no longer change much with each additional step that you take.
一个细节:simultaneously update

要同时更新。从一元函数的泰勒展开推导到梯度下降引申到多元函数就可以知道是同时下降的
导数决定梯度下降方向,学习率决定步长
4.3 理解梯度下降

4.4 学习率

所以可以得到解析解的话,可以把所有导数为零的点求出来,然后取最小的那个值对应的w,就是最小的
4.5 用于线性回归的梯度下降
我们已经学习了 线性回归模型、 cost function, 梯度下降算法
本节,我们用 the squared error cost function平方误差成本函数 for the linear regression model
with gradient descent.
This will allow us to train the linear regression model to fit a straight line。


4.6 运行梯度下降

其主要区别 在训练数据的选择上。
1、批量梯度下降法BGD
批梯度下降法(Batch Gradient Descent)针对的是整个数据集,通过对所有的样本的计算来求解梯度的方向。

week2
1.1 多维特征

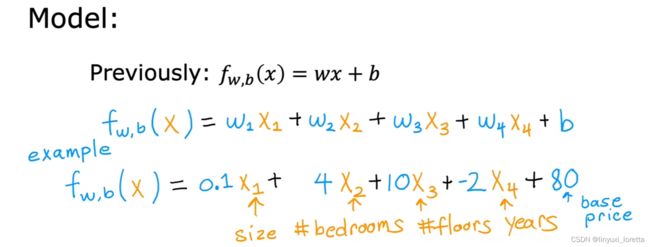
multiple linear regression多元线性回归
多元回归( multivariate regression)(多元回归是统计学里的概念)

1.2 向量化
一个非常巧妙的技巧:向量化
使用向量化既可以减少代码量,又可以运行得更高效,
写向量化代码时,我们会用到现代数值线性代数的函数库 allow you to take advantage of modern numerical linear algebra libraries, NumPy
也会用到计算机的GPU硬件、一般来说,GPU是一种用来提高电脑处理图像速度的硬件
但当我们在写向量化代码时,使用它可以加快代码执行的速度
特别是当n很大的时候,它会比前面的两个代码示例运行的快得多。
向量化能加快运行速度的原因在于,我们有个幕后帮手
NumPy dot函数能够调用计算机中的并行硬件,
无论你是在一台普通电脑上用CPU,还是用GPU(经常用于加速机器学习任务)来运行这个算法,

与之相反,NumPy中的dot函数通过计算机硬件实现向量化
计算机可以得到向量w和x的所有值,在一步中,
它同时并行地将w和x相乘。
然后,计算机调用专门的硬件,非常高效地计算这16个数字的和
而不需要一个接一个地做不同的加法来计算这16个数的和
当你在大型数据集上运行算法或训练大模型时(机器学习通常就是这种情况),这点尤其重要


1.4 用于多元线性回归的梯度下降法
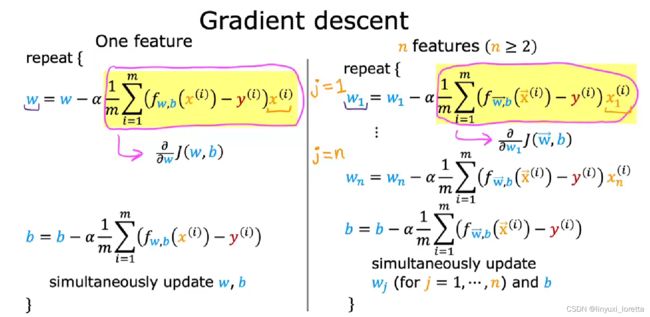
an alternative way for finding w and b for linear regression. This method is called
the normal equation 正规方程

技巧:
picking and scaling features
Alpha率 选择
2.1 特征缩放
特征缩放的技术,它能让梯度下降运行得更快。
look at the relationship between the size of 特征 and the size of its associated parameter.

scatterplot散点图

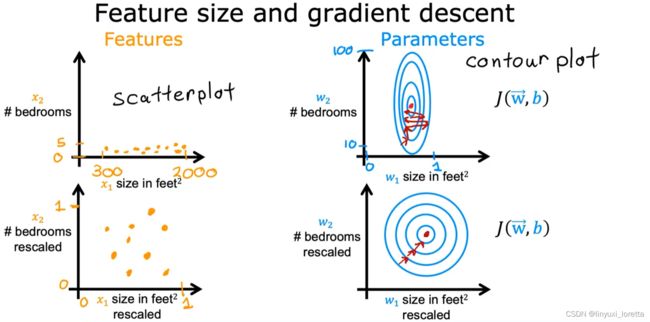
总结一下,当你有不同的特征且取值范围
差异较大,它可能会导致梯度下降运行缓慢,但
通过重新放缩这些特征,使它们都具有可比较的值范围。
可显著加快梯度下降速度。
做法:
1.
2. 均值归一化

3. Z-score标准化(也叫做Z-score归一化/规范化)

就是通过缩放尽量让所有特征的取值在差不多范围,这样它们的变化对预测值的影响都是接近的
基本意思是,保证各个特征的数量级一致

2.3 判断梯度下降是否收敛
how to check if gradient descent is really working?
= finding you the global minimum or something close to it.
= how to recognize if gradient descent is converging,
请注意,机器学习中使用了几种不同类型的学习曲线,
如果梯度下降正常运作,那么每次在迭代后代价J应该会降低。
如果成本J的值在一次迭代后反而增加了,
这意味着要么学习率α选择得不好,通常意味着Alpha太大,要么代码有bug

顺便说一下,不同的运用场景中,梯度下降的收敛速度可能有很大差异。
事实证明,我们很难事先知道梯度下降要经过多少次迭代才能收敛,
所以你可以先画个学习曲线图,看看你需要在迭代多少次之后停止模型的训练。
另一种帮助你决定什么时候完成模型训练的方法是使用自动收敛测试。
我经常发现,选出正确的 ε 是相当困难的。
实际上我倾向于看像左边这样的图,而不是依赖于自动收敛测试。
2.4 如何设置学习率

小技巧:所以如果梯度下降无法正常工作,我经常做的一件事就是将α设为 一个很小的数字,看看是否每次迭代的代价都降低。
所以当我使用梯度下降法时,我通常会尝试一系列学习率α值。
对于每一个α选择,你可以用梯度下降法进行 少量的迭代并绘制代价函数J、作为迭代次数的函数。在尝试了几个不同的α值之后,你可能会选择能快速且持续 降低代价的α值

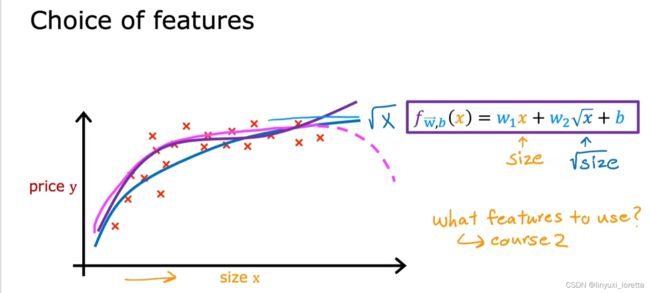
2.5 特征工程
choosing custom features自定义特征选取, which will also allow you to fit curves帮助你拟合曲线, not just a straight line to your data.
特征的选取 对你的学习算法的性能有很大的影响。事实上,在许多实际应用中,选择或输入合适的特征才是 a critical step to making the algorithm work well.
a different way to use these features in the model that could be even more effective.
你可能会有一种直觉,即土地面积更能预测价格,

特征工程的一个特色,它不仅能帮你拟合直线,
2.6 多项式回归
让我们结合多元线性回归和特征工程的概念
来提出一种叫做多项式回归的新算法,polynomial regression, ,which will let you fit curves, non-linear functions,

一个流行的开源工具包,scikit-learn
week3 classification
3.1 motivation
事实证明,线性回归并不是解决分类问题的好算法。让我们看看为什么,由此也引入另一种算法:逻辑回归。
二分类问题binary classification
在这些问题中,我将交替使用类(classes)和类别(categories)这两个术语,它们的意思基本上是一样的。
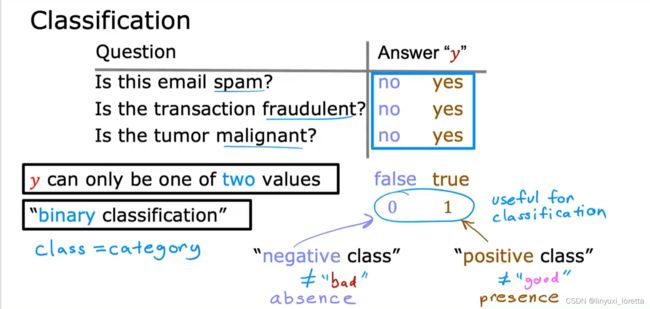
需要明确的是,正负样本并不意味着样本的好坏,
这样说只是为了传达”absence/zero/false" 或者 “presence/one/true"的概念,
就非垃圾邮件和垃圾邮件而言,用 0/false 还是 1/true 来表示它们,取决于你的心情。
所以,不同的工程师,叫法可能正好反过来。正样本可以是封正常的邮件、

其中有一类是 1(positive/yes 良性肿瘤 ),还有一类是 0 (negtive/no 恶性肿瘤)。
我在横轴上标出了肿瘤的大小 x ,在纵轴上标出了 对应的标签y。
但这不是我们想要的,因为添加一个训练样本并不应该改变任何我们之前判定肿瘤良恶性时下的结论
decision boundary决策边界
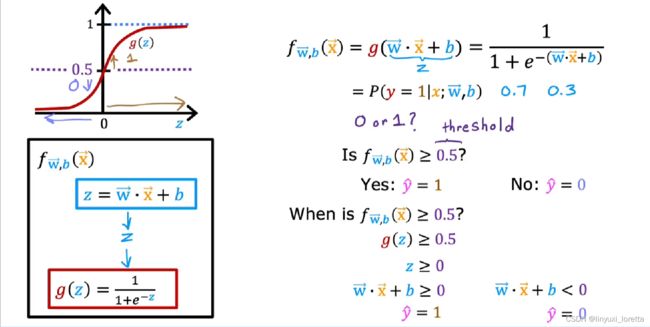
logistic regression 实际上是用来解决 输出标签y为0或1的二元分类问题的。
它输出的结果值总在0到1之间。
1.2 逻辑回归
6.2 逻辑回归 Logistic regression_哔哩哔哩_bilibili
相比之下,逻辑回归的结果是拟合出这样一条曲线,一条s型曲线去拟合这个数据集。
算法输出0.7,说明这个肿瘤很有可能是恶性的。
但是输出标签y不会等于0.7,只会是0或1。
要想创建逻辑回归算法,我们需要引入一个重要的数学函数:Sigmoid函数,有时也叫做逻辑函数。

现在,让我们用这个sigmoid函数来建立逻辑回归算法。2 steps

接下来,让我们看看如何解释逻辑回归的输出。
把这个输出看作是 在给定输入x的情况下,类别或标签y等于1的概率。

For a long time, 许多线上广告实际上是靠着逻辑回归的微小变化而选择投放的。
1.3 决策边界
decision boundary. 它能提供几种不同的方法来映射模型输出的数字,(This will give you a few different ways to map the numbers that this model outputs,) 例如0.3、0.7或0.65,以预测y实际上是0还是1。
如果你想要算法预测出的值是0或1该怎么办?
你可以设置一个阈值(threshold),超过这个阈值则预测 y=1,或者说让预测值 y帽=1。
我们常把阈值设置为0.5。如果f (x)大于等于0.5,那么 y帽=1
visualize how to model makes predictions:
在决策边界上,y=0 or 1的概率几乎一致。
当然,如果你选择不同的参数,决策边界将会是不同的线。

怎么知道每个特征值都要平方呢
通过观察数据分布,假设特征值表达式,对图像进行初步拟合,再经过梯度下降寻找w和b。
不用观察,用之前的多项式迭代就能得出表达式(?)

用多项式特征,可以得到非常复杂的决策边界。
通过这个可视化,我希望你现在能够对逻辑回归可能得到的模型范围有一个概念。
现在你已经知道了f (x)可以计算出什么,
让我们看看如何训练逻辑回归模型。
我们先来看看逻辑回归的成本函数然后,算出如何应用梯度下降法。
2.1 逻辑回归中的代价函数
还记得代价函数吗,它可以测量出一组特定参数与训练数据的吻合程度。从而为我们提供了一种选择更好参数的方法。
在这个视频中,我们会看到平方误差代价函数并不是逻辑回归的理想代价函数。
我们来看一个不同的成本函数,它可以帮助逻辑回归选择更好的参数。


这里有个可以使得代价函数再次凸化的代价函数,保证梯度下降可以收敛到全局最小值。
稍微改变一下代价函数J(w,b)的定义,

当 y=1时,损失函数推动算法做出更准确的预测,因为当f(x)预测的值接近1时,损失是最低的。

事实上,当预测值接近1时,损失实际上接近于无穷大。
以上,我们定义了单个训练样本的损失,并提出了逻辑回归损失函数的新定义。
选择这个损失函数后,整个代价函数就是凸函数了,此时你就可以安心的使用梯度下降法以得到全局最小值。

我们还会学到一种简写版的代价函数,这样以后运行梯度下降时,可以为逻辑回归找到好的参数。
2.2 简化逻辑回归代价函数


你可能会想,明明我们有那么多其他的代价函数可以选,非得要选这个?
这个特殊的代价函数是用一种叫做极大似然估计的统计原理中推导出来的,
统计学,idea on how to efficiently find parameters from different models
这种代价函数具有凸函数的优点。
逻辑回归的梯度下降 7.3 Gradient Descent Implementation_哔哩哔哩_bilibili


你可能会想,线性回归实际上和逻辑回归是一样的吗?
虽然这些方程看起来是一样的,但这并不是线性回归,因为函数f (x)的定义变了。
same concept with线性回归:
如何监视梯度下降以确保它收敛。(learning curve)
用向量化的逻辑回归,使其梯度下降的速度更快。
特征缩放就是将所有特征缩放到相似的值范围,比如在- 1和+ 1之间,它使得梯度下降更快地收敛。
过拟合 8.1 The problem of overfitting_哔哩哔哩_bilibili
一些处理过拟合的技巧。 正则化会帮助你最小化出现过拟合的概率,让你的算法更好地工作。

该算法不能很好地拟合训练数据。用专业术语描述,就是模型对训练数据的拟合不足(欠拟合underfitting)。或者说:the algorithm has high bias,算法连训练集都没办法很好的拟合。
希望算法也能适用于没出现在训练集中的样本,这样的能力称为“泛化”(Generalization)。
有了这个四次多项式,你就可以精确地拟合出通过所有五个训练例子的曲线。
过拟合或高方差背后的直觉是算法非常努力地拟合每一个训练样本。
如果你的特征太少,就像左边的这个例子,它欠拟合了,并且有高方差。

8.2 解决过拟合Addressing overfitting_哔哩哔哩_bilibili
如果过拟合的情况已经发生了,那我们能做些什么?
首要做法。收集更多的训练数据。在有了更大的训练集之后,算法就会拟合出一个不那么摇摆不定的函数。


解决过拟合问题的第二个方法,观察是否可以使用更少的特征。
1.不用这么多个多项式特征。
2.feature selection,用直觉
in course 2,你还将看到一些算法,可以自动选择最合适的特征集,用于我们的预测任务。
第三种方法,正则化

其实正则化减少特征影响的方式算是比较温和了,它不是暴力的直接抹掉这个特征。正则化所做的是尽可能地让算法缩小参数的值,而不是要求一定要把参数变成0。
事实证明,即使你拟合一个像这样的高次多项式,只要你能让算法使用更小的参数值w1, w2, w3, w4,最终得到的曲线会更好地拟合数据。
正则化的作用是,它让你保留所有的特征,但防止特征权重过大,这有时会导致过拟合。
顺便说一下,按照惯例,我们通常只需要减小参数wj的大小,也就是从w1到wn。对参数b正不正则化没有太大差别。你想的话就可以。我通常不会这样做,正则化w1到wn的效果就挺不错了,但我并不鼓励缩小参数b的值。在实践中,是否对b进行正则化应该没有太大区别。

8.3 带有正则化的代价函数 Cost function with regularization_哔哩哔哩_bilibili
在上个视频中我们学习了正则化,通过缩小参数w1到wn的值,以减少过拟合的风险。
在这个视频中,我们将基于这种直觉, 改进算法中的代价函数,

如果这样做,那么我们最终会得到一个更接近二次函数的数据,其中也有 x³ 和 x⁴ 的小小贡献。

正则化背后的逻辑:参数值越小,模型可能会简单。也许是因为一个模型的特征变少了,那它过拟合的可能性也变小了。
更普遍的,你有很多特征,比如100个特征,你可能不知道哪些是最重要的,哪些应该被正则化。所以正则化的实现方式通常是惩罚所有的特征,或者更准确地说,你惩罚所有的wj参数。
λ,正则化参数。和学习率α有点类似,你也要为正则化参数 λ 选择一个具体的数字。
说明:
按照惯例,我们不用 λ * Σ wj² ,而是用 λ/2m * Σ wj²,所以第一项和第二项都乘以1 / 2m。用同样的方式缩放这两项,我们选择λ的值就更容易了。特别地,即使你的训练集规模变大,比如说你有了更多的训练样本,此时m的值(训练集大小)变大,你会发现之前确定的 λ 可能现在还能用,前提是你使用了这个2m倍的缩放(缩小)。

这个新的代价函数权衡了两个目标。
最小化第一项,可以让(预测值 - 真实值)² 尽可能的小,从而算法能更好地拟合数据(第一个目标:拟合数据)。
然后最小化第二项,
让参数 wj 尽可能的小(第二个目标),这样可以减小过拟合的风险。
你选择的 λ 值体现了相对重要性或相对权衡,就是说这两个目标你是如何取舍的。
8.4 线性回归的正则化 Regularized linear regression_哔哩哔哩_bilibili


α very small positive number
λ usually a small number
so,这一项意味着,每次迭代时,你会用w_j乘以一个略小于1的数字,before carrying out the usual update. 使得w_j缩小了一点点,这也给了我们另一种视角理解正则化为什么可以在每次迭代中缩小wj的值。这就是正则化的原理

在特征多和训练样本少时,使用正则化线性回归可以减少过拟合的风险。
请进空间看下一部分8.5 Regularized logistic regression_哔哩哔哩_bilibili

通常来说,when you train logistic regression with 很多features,whether多项式特征or some other features,发生过拟合的风险增加了。

实际上它们是相同的方程,只不过f的定义不再是线性函数,