Python数据分析 | (10)NumPy线性代数和伪随机数生成
本篇博客所有示例使用Jupyter NoteBook演示。
Python数据分析系列笔记基于:利用Python进行数据分析(第2版)
目录
1.线性代数
2.伪随机数生成
3.示例:随机漫步
1.线性代数
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等)是数组库的重要组成部分。
NumPy提供了矩阵乘法的dot函数:
import numpy as np
x = np.array([[1.,2.,3.],[4.,5.,6.]])
y = np.array([[6.,23.],[-1,7],[8,9]])
print(x)
print(y)
print(x.dot(y)) #用2维数组表示矩阵 矩阵乘法用dot A.dot(B) 满足A的列数等于B的行数
print(np.dot(x,y)) #np.dot(a,b) 等价于 a.dot(b)
一个2维数组跟一个大小合适的一维数组的矩阵点积运算之后会得到一个一维数组:
print(x)
print(np.dot(x,np.ones(3)))
此时的这个一维数组可以看作是一个列向量,不过一般使用2维数组来表示行/列向量,用1维数组表示向量容易出现莫名其妙的错误:
print(x)
print(np.dot(x,np.ones(3).reshape(3,1))) #用2维数组表示向量

结果是一个向量,同样是用2维数组表示。
@符也可以用作中缀运算符,进行矩阵乘法:
print(x)
print(y)
print(x @ y)
numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东西,和Matlab使用的是相同的行业标准线性代数库。
from numpy.linalg import inv,qr
x = np.random.randn(5,5) #2维数组/矩阵
mat = x.T.dot(x) #计算x的转置和x的内积 得到一个mat方阵
print(inv(mat)) #返回mat矩阵的逆矩阵
print("------------------")
print(mat.dot(inv(mat))) #得到单位矩阵
print("------------------")
q,r = qr(mat) #对mat矩阵进行qr分解
print(q)
print("------------------")
print(r)
常用的线性代数函数:

2.伪随机数生成
numpy.random模块对Python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值函数。
比如可以使用normal来得到一个标准正态分布的4*4样本数组:
sample = np.random.normal(size=(4,4))
sample
Python内置的random模块一次只能生成一个样本值,如果需要产生大量样本值,numpy.random快了不止一个量级:
from random import normalvariate #Python内置的random模块
N = 1000000
%timeit samples = [normalvariate(0,1) for _ in range(N)]
%timeit samples = np.random.normal(size=N)![]()
之所以说这些是伪随机数,是因为他们都是通过算法基于随机数生成器种子,在确定的条件下生成的。可以利用np.random.seed更改随机数生成种子:
np.random.seed(1234)numpy.random的数据生成函数使用了全局的随机种子。要避免全局状态,可以使用numpy.random.RandomState,创建一个与其他隔离的随机数生成器:
rng = np.random.RandomState(1234)
rng.randn(10)![]()
下表列出了numpy.random中的部分函数:

3.示例:随机漫步
利用之前的随机函数一次性生成大量样本。
通过模拟随机漫步来说明如何运用数组运算,看一个简单的随机漫步的例子:从0开始,步长1和-1出现的概率相等。
首先通过Python内置的random模块已纯Python的方式实现1000步随机漫步:
import random
position = 0
walk = [position]
steps = 1000
for i in range(steps):
step = 1 if random.randint(0,1) else -1 #在[0,1]间随机生成整数 如果是0 step=-1 如果是1 step=1
position += step
walk.append(position)
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(walk[:100])
上述过程可以使用数组运算来实现:
nsteps = 1000
draws = np.random.randint(0,2,nsteps) #生成nsteps个[0,2)之间的随机整数 构成一个数组 要么0,要么1
steps = np.where(draws>0,1,-1) #把数组中大于0的元素设置为1 小于等于0设置为-1 产生一个新数组
walk = steps.cumsum() #对数组求累计和
print(walk.max()) #np.max(walk) 数组最大值
print(walk.min()) #np.min(walk) 数组最小值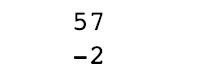
现在稍微复杂一些,找到随机漫步过程中第一次到达某个特定值的时间。假设我们想知道本次随机漫步需要多久才能距离初始0点至少10步远(任何一个方向均可)。
(np.abs(walk)>=10).argmax()
np.abs(walk)>=10可以得到一个布尔型数组,表示离0点的距离是否达到或超多10,是的话为True,否则为False,而我们想知道第一个>=10或<=-10的索引,可以使用argmax,返回第一个最大值的索引,对于布尔数组来说,最大值就是True,返回第一个True的索引。
注意这里使用argmax不是很高效,因为他无论如何都会对数组进行完全扫描。在本例中,只要发现第一个True,我们就知道它是最大值了。
一次模拟多个随机漫步:
如果希望模拟多个随机漫步过程,如5000个,需要对上述代码稍作修改,给随机函数传入一个2元元组就可以生成一个2维数组了,就可以一次性计算5000个随机漫步过程的累计和了。
nwalks = 5000
nsteps = 1000
draws = np.random.randint(0,2,size=(nwalks,nsteps)) #生成nwalks*nsteps个[0,2)之间的随机整数 构成一个2维数组 要么0,要么1
steps = np.where(draws>0,1,-1) #把数组中大于0的元素设置为1 小于等于0设置为-1 产生一个新数组
walk = steps.cumsum(1) #对2维数组steps沿1轴求累计和(沿各个列的方向,水平方向,求每一行的累计值)
print(walk.max())
print(walk.min())
接下里计算离0点距离为30的最小时间,因为并不是5000个过程都会达到30,可以使用any函数进行检验:
hist30 = (np.abs(walk)>=30).any(1) #沿轴1(各个列的方向,水平方向) 如果某一行/某一个随机漫步过程达到过30,-30 该行为True
print(hist30)
print(hist30.sum()) #np.sum(hist30) 统计达到过30,-30的行数/漫步过程数
#得到每行/每个随机漫步过程达到30,-30的最小时间
correct_time = (np.abs(walk[hist30])>=30).argmax(1)
print(correct_time.min())
print(correct_time.mean())
利用hist30这个布尔数组选出哪些达到30,-30的随机漫步过程/行,调用argmax(1)得到每行第一个最大值(第一个True)的索引,即达到30,-30的最小时间。
也可以使用不同的随机数生成函数得到漫步数据,如normal函数用于生成指定均值和标准差的正态分布数据:
steps = np.random.normal(loc=0,scale=0.25,size=(nwalks,nsteps)) #生成均值为0 标准差为0.25的正太分布数据 size指定数组大小rand函数用于生成0-1之间的随机浮点数,只需指定数组大小即可:
randn函数用于生成均值为0,标准差为1的标准正态分布数据,只需指定数组大小即可:
a = np.random.randn(2,10)
b = np.random.randn(3)
c = np.random.rand(3,3)
d = np.random.rand(4)
print(a)
print(b)
print(c)
print(d)