Fine-tuning一个语言模型
Fine-tuning一个语言模型
原文地址我找不到了。。。。还是transformer上面的一个教程,教程名字是 Fine-tuning a language model
文章目录
- Fine-tuning一个语言模型
-
- 准备数据
- 因果语言模型(CLM)
- 掩码语言模型(MLM)
- 总结
在 Transformers 上微调一个语言模型任务,有两种类型的语言模型任务
- Causal language modeling(因果语言模型):这个语言模型会预测在这句话的下一个单词(标签与向右移动的输入相同)。为了防止模型作弊,在预测第i+1个单词时,会mask第i个后面的单词。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gyo36Wfu-1615467133632)(https://github.com/huggingface/notebooks/blob/master/examples/images/causal_language_modeling.png?raw=1)]
- Masked language modeling(掩码语言模型):模型会预测一些被mask的单词。可以访问整句话,因此它能够使用mask的单词的前后单词
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sC4F4JKS-1615467133633)(https://github.com/huggingface/notebooks/blob/master/examples/images/masked_language_modeling.png?raw=1)]
用transformers和datasets库来加载,使用TrainerAP来fine-tune模型,使用TPU可以利用这个脚本
准备数据
在这个任务中, 使用 Datasets的Wikitext 2这个数据集
from datasets import load_dataset
datasets = load_dataset('wikitext', 'wikitext-2-raw-v1')
可以用the hub里面的任何数据集,也可以用本地数据。只需取消注释以下单元格,然后将路径替换为本都文件即可:
# datasets = load_dataset("text", data_files={"train": path_to_train.txt, "validation": path_to_validation.txt}
加载csv和JSON文件看full documentation
数据的格式是这样,选择一个Split(“test”, “train”,“validation”)查看其中一部分
DatasetDict({
test: Dataset({
features: ['text'],
num_rows: 4358
})
train: Dataset({
features: ['text'],
num_rows: 36718
})
validation: Dataset({
features: ['text'],
num_rows: 3760
})
})

展示数据
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10): # 选择num_exanples个数据展示
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
print(dataset.features.items())
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_random_elements(datasets["train"])
一些是维基百科段落,一些是空行或标题
因果语言模型(CLM)
对于CLM(因果语言模型)采用数据集的所有文本,并且在tokenize后全部拼接起来,然后,拆分为一定长度的示例。这样,模型将接收大块连续的文本,这些文本可能看起来像
part of text 1
or
end of text 1 [BOS_TOKEN] beginning of text 2
取决于它们是否跨越数据集中的几个原始文本。标签与输入一同向左移动(存疑)
使用distilgpt2模型,你可以在这里挑选其它模型代替
model_checkpoint = "distilgpt2"
AutoTokenizer加载模型
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
使用分词器(tokenizer)处理文本。非常方便,可以使用Dataset库map方法,定义一个调用tokenizer
def tokenize_function(examples):
return tokenizer(examples["text"])
对所有的dataset对象的所有Split(“test”, “train”,“validation”), 使用batched=True和4线程加速,不需要text进行移除
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
# 使用tokenize_function函数,批处理, 4线程,移除text # 我在本地报错,删除num_proc
展示处理后的tokenized_datasets
DatasetDict({
test: Dataset({
features: ['attention_mask', 'input_ids'],
num_rows: 4358
})
train: Dataset({
features: ['attention_mask', 'input_ids'],
num_rows: 36718
})
validation: Dataset({
features: ['attention_mask', 'input_ids'],
num_rows: 3760
})
})
此时,就移除了"text",保留下了tokenizer后的’attention_mask’和’input_ids’
tokenized_datasets["train"][1]
------------------------------------------------------
{'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1],
'input_ids': [796, 569, 18354, 7496, 17740, 6711, 796, 220, 198]}
下面就是最难的部分:需要拼接所有的文本到一起,将结果分割成block_size大小。为了做到这个结果,要再用一次map方法,选择batched=True。这个选项实际上允许我们通过返回不同数量的样本来改变数据集中的样本数量。通过这种方式,我们可以从一批示例中创建新的示例。
首先,我们获取预训练模型时所使用的最大长度。这对你的GPU RAM来说可能太大了,所以我们在这里用更少一点的128。
# block_size = tokenizer.model_max_length
block_size = 128
然后,写预处理函数生成自己的texts
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()} # {"attention_mask": , input_ids: } # 将所有的数据加到一起
# 这里这个sum用的迭代相加来清除 []
total_length = len(concatenated_examples[list(examples.keys())[0]]) # 计算出总长度
# 这里会删除掉一部分
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
} # 步长block_size的块
result["labels"] = result["input_ids"].copy()
return result
首先注意,我们复制了标签的输入(label==input_ids)。这是因为transformer库的模型应用了向右移动,所以我们不需要手动操作。
此外,默认方法下,map方法要由预处理函数传递一个批次为1000个examples。这里,我们将丢弃余数部分,使拼接后的tokenize的每1000个文本总长是block_size的倍数。也可以传递更高的批处理大小(这会被处理更慢)。可以用多线程处理。
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
)
我们可以检查我们的数据集是否发生了变化:现在样本包含了block_size连续标记块,可能跨越了几个原始文本。
数据处理完后,实例化Trainer
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_checkpoint)
参数设置TrainingArguments
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
"test-clm",
evaluation_strategy = "epoch",
learning_rate=2e-5,
weight_decay=0.01,
)
将这些内容传递给Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)

训练完成后,可以评估我们的模型,在验证集得到困惑度
import math
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 38.13
掩码语言模型(MLM)
对于掩码语言模型(MLM)将会由显示的数据预处理过程:我们将随机遮挡(MASK)一部分字符(用[MASK]代替),标签仅仅是被遮挡字符(我们不去预测,没有掩码的单词)
使用distilroberta-base模型,也可以在这里选择其他模型。
model_checkpoint = "distilroberta-base"
使用前面的tokenize_function函数删除"text",更新tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
tokenized_datasets = datasets.map(tokenize_function, batched=True, remove_columns=["text"]) # num_proc=4,
像之前一样,我们把文本分组在一起,并把它们分成长度为block_size的样本。如果您的数据集由单独的句子组成,则可以跳过这一步。
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
)
剩下和之前相似,但是有两个例外。首先,使用一个合适的MLM
from transformers import AutoModelForMaskedLM
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
第二,我们要使用特殊的data_collator。data_collator是一个函数,负责批处理采用并处理为tensors。在前面的例子中,我们没有什么特殊的事情要做,所以我们只使用这个参数的默认值。这里我们要进行随机mask。我们将它最为一个预处理步骤(如序列化)但是这些字符将会被采用相似的手段进行遮挡。通过在data_collator中执行这一步,我们可以确保每次检查数据时都以新的方式完成随机屏蔽。
为了实现这个屏蔽,库为语言建模提供了一个DataCollatorForLanguagModeling。我们可以调整掩蔽的概率:
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
然后我们要把所有的东西交给Trainer,然后开始训练:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
data_collator=data_collator,
)
trainer.train()
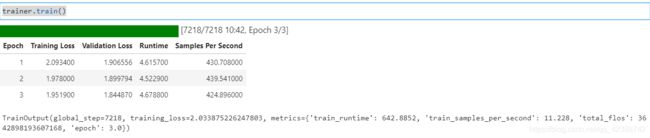
像之前一样,我们可以评估我们的模型在验证集。MLM的困惑度要远远低于CLM是因为我们只用预测被遮挡的部分(仅仅15%,这是一项更简单的任务),而获得其余的令牌。因此,对于模型来说,这是一项更容易的任务。
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 6.24
总结
唉,感觉翻译这些教程没有什么用,开学10天了实验还没跑出来。。。