matlab随机森林特征选择,使用随机森林做特征选择
目录
一、介绍
随机森林模型不仅在预测问题上有着广泛的应用,在特征选择中也有一定的应用,这是因为,随机森林模型在拟合数据后,会对数据属性列,有一个变量重要性的度量,在sklearn中即为随机森林模型的 feature_importances_参数,这个参数将返回一个numpy数组对象,数组里的元素对应为随机森林模型在拟合后认为的所给训练属性列的重要程度,是数值类型数据,数组中元素之和为1。变量重要性度量数组中,数值越大的属性列对于预测的准确性更加重要。
二、实验
2.1 实验数据
这里选用kaggle上的入门比赛,Housing Prices Competition for Kaggle Learn Users的数据集作为实验对象,这是一个预测房价的回归问题,数据集如下:
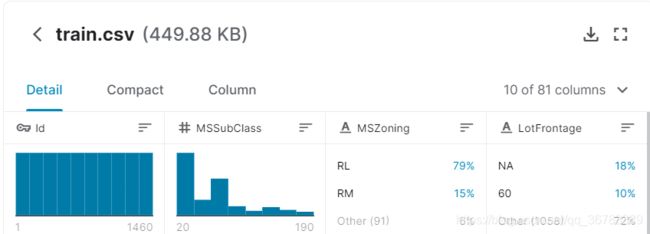
这个数据有81个属性列,1460条数据。
2.2 特征选择
载入数据
#getData函数为自定义的函数,其实就是调用了pandas的read_csv函数
train, test = getData('./data/train.csv', './data/test.csv')
1. 使用皮尔逊相关系数选择特征
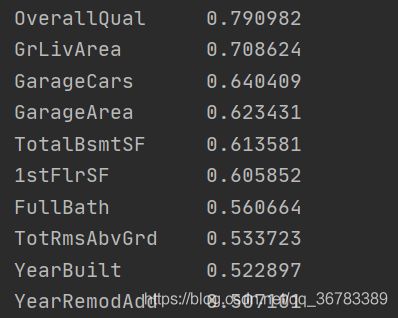
#根据皮尔逊相关系数选择与要预测的属性列SalePrice相关性最高的10个属性
#[:11],选出11个是因为SalePrice自己与自己的相关性最高,所以要将它去除故选择排序后的前11个属性,再去除SalePrice
features = train.corr()['SalePrice'].abs().sort_values(ascending=False)[:11]
features.drop('SalePrice', axis=0, inplace=True)
features = features.index
结果如下
2. 使用随机森林模型选择特征
#先用皮尔逊系数粗略的选择出相关性系数的绝对值大于0.3的属性列,这样不需要训练过多不重要的属性列
#可以这么做而且不会破坏实验的控制变量原则,因为根据皮尔逊相关系数选择出的重要性排名前10的属性列
#它们与要预测的属性列的皮尔逊相关系数均大于0.3,可以当成步骤1中也进行了同样的取相关系数为0.3的操作
features = train.corr().columns[train.corr()['SalePrice'].abs()> .3]
features = features.drop('SalePrice')
#使用随机森林模型进行拟合的过程
X_train = train[features]
y_train = train['SalePrice']
feat_labels = X_train.columns
rf = RandomForestRegressor(n_estimators=100,max_depth=None)
rf_pipe = Pipeline([('imputer', SimpleImputer(strategy='median')), ('standardize', StandardScaler()), ('rf', rf)])
rf_pipe.fit(X_train, y_train)
#根据随机森林模型的拟合结果选择特征
rf = rf_pipe.__getitem__('rf')
importance = rf.feature_importances_
#np.argsort()返回待排序集合从下到大的索引值,[::-1]实现倒序,即最终imp_result内保存的是从大到小的索引值
imp_result = np.argsort(importance)[::-1][:10]
#按重要性从高到低输出属性列名和其重要性
for i in range(len(imp_result)):
print("%2d. %-*s %f" % (i + 1, 30, feat_labels[imp_result[i]], importance[imp_result[i]]))
#对属性列,按属性重要性从高到低进行排序
feat_labels = [feat_labels[i] for i in imp_result]
#绘制特征重要性图像
plt.title('Feature Importance')
plt.bar(range(len(imp_result)), importance[imp_result], color='lightblue', align='center')
plt.xticks(range(len(imp_result)), feat_labels, rotation=90)
plt.xlim([-1, len(imp_result)])
plt.tight_layout()
plt.show()
结果如下图:
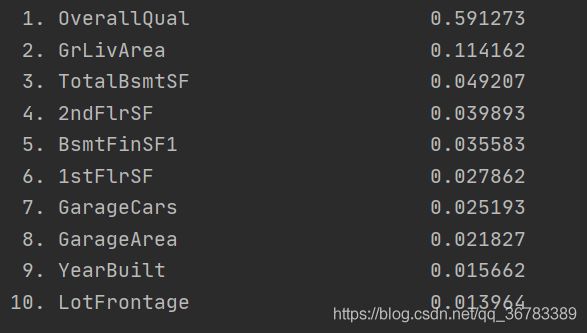
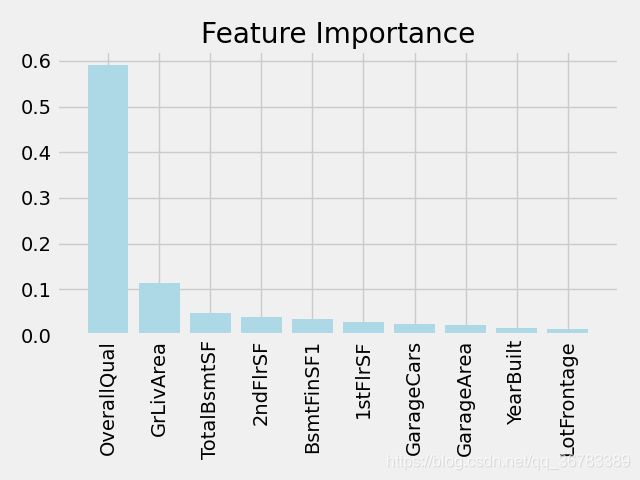
可以看出,步骤2与步骤1中选择出来的属性列差别不大,不过步骤2表明随机森林模型在拟合后觉得OverallQual属性列的重要性很高。
3. 使用同一个模型进行对比训练
经实验,对于随机森林模型RandomForestRegressor(n_estimators=100,max_depth=None)而言,使用步骤1中的通过皮尔逊相关系数获得的属性列进行训练,得分为0.9778667641397033;而使用随机森林选择的特征进行训练,得分为0.9800629050754925。可以看出使用随机森林做特征选择,在这个数据集上对于提高模型的能力还是有一定的作用的。