【论文阅读】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
文章目录
- 论文内容
- 摘要(Abstract)
- 1. 介绍(Introduction)
- 2. 相关工作(略)
- 3. BERT
-
- 3.1 预训练BERT(Pre-training BERT)
- 4. 个人总结
论文内容
论文地址: https://arxiv.org/abs/1810.04805
官方代码地址 : https://github.com/google-research/bert
摘要(Abstract)
BERT全称Bidirectional Encoder Representations from Transformers,其是一个基于Transformer模型、使用无监督方式训练的预训练模型。
只要简单的在BERT下游接个输出层进行特定的任务,可能就直接是SOTA(state-of-the-art)模型了,就这么牛。
1. 介绍(Introduction)
BERT的训练使用的是“masked laguage model”(MLM)预训练任务,具体为随机掩盖住输入中的部分词,目标就是根据上下文来预测这些被盖住的词是什么。例如:
输入:我正在学习深度[MASK],目前学到了BERT一节,有点[MASK]。
期望输出:学习,难
同时还使用了NSP(Next Sentence Prediction)任务,具体为给两句话,让网络做二分类任务,区分这两句话是不是一对儿。例如:
输入:窗前明月光,疑是地上霜
期望输出:1
输入:锄禾日当午,李白吃红薯
期望输出:0
2. 相关工作(略)
3. BERT
基于BERT的架构需要两个阶段:pre-training和fine-tuning。
其中pre-training是使用无标签的文本数据,是通过“masked language model”(MLM)任务来进行训练。
而fine-tuning是使用上面的预训练模型,然后使用带有标签的数据进行特定任务。
如下图所示:
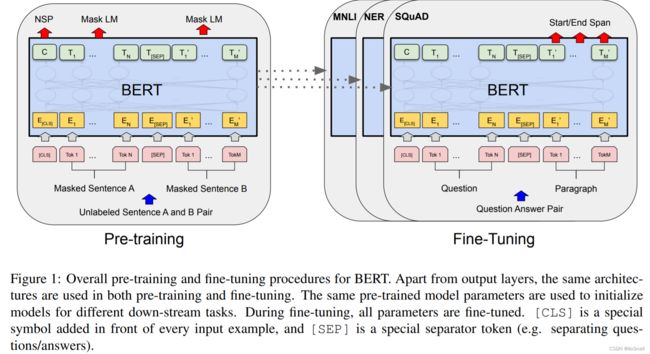
上述包含的缩写含义如下:
[CLS]: class的缩写,其是一个特殊符号,每个输入样本的最前面都会增添一个这玩意。Tok X:Token的缩写,Tok 1表示当前句子中的第一个词,以此类推[SEP]: separator的缩写,表示分隔符。用来分割两个句子。E: embedding的缩写,表示该token被embedding后的向量C:表示[CLS]这个特殊的token经过BERT后的向量T:表示对应Token经过BERT后的向量NSP: Next Sentence Prediction任务Mask LM: masked laguage model, MLM任务- 灰色箭头⇧:Tok到E之间的箭头,表示输入,即Tok为输入
- 红色箭头⇧:表示下游任务
MNLI, NER, SQuAD: 三种特定的任务。
上图表示的内容表示使用BERT进行特定任务分两步:先对BERT进行Pre-training,然后再进行Fine-Tuning
左边表示Pre-training,具体步骤为:
- 首先找一对儿句子(Unlabeled Sentence A and B pair)。例如:A:床前明月光,B: 疑是地上霜。
- 然后对A句子和B句子的部分词进行Mask,得到Masked Sentence A和Masked Sentence B。例如: 床[MASK]前明月[MASK],疑是[MASK]上霜
- 在句子前加入
[CLS]特殊token,两个句子中间加入[SEP]特殊token。例如[CLS]床[MASK]前明月[MASK][SEP]疑是[MASK]上霜 - 将第三步的这些token都送给BERT,最终BERT会为每个token都输出一个向量。例如:BERT的输出Tensor的Shape为(13, 768),其中13表示有13个token,其中第0个就是
[CLS]这个特殊token的输出向量,其包含了整句话的上下文,第1个是床这个token的输出向量,依次类推。 - 之后会使用第4步的输出向量做两个任务:①NSP任务,使用
[CLS]的输出向量来预测A,B两句话是不是一对儿。 ;②Maksed LM任务, 使用各[MASK]token的输出来预测这个token具体是什么。
5.1 对于NSP任务,是将[CLS]token的输出向量送给后面的全连接层做二分类任务,判断A,B两句话是不是一对儿。
5.2 对于Masked LM任务,则是使用全连接层+Softmax做多分类任务,来预测这个token是什么。使用的是Cross Entropy Loss。
当完成Pre-training后,就可以拿BERT进行特定的任务了,也就是右图。在右图中,使用的问答(Question Answer)任务,输入为问题(Question)和一段话(Paragraph),输出为Start/End Span,即答案在这段话的什么位置。例如:
Question:菜徐坤练习了多少年。
Paragraph:我是练习时长两年半的蔡徐坤,擅长唱跳、Rap、篮球。
Anwser:两年半
输出: start=6, end=8, span=3。表示答案在Paragraph中的第6-8个字符,字符数量为3。
因为有Span的存在,所以Start和End只需要一个即可。
由于BERT输出的是向量,所以要进行下游任务的预测,还需要接一个全连接层,这是图上没有画出来的。
Model Architecture
BERT模型是一个多层双向TransformerEncoder(multi-layer bidirectional Transformer encoder),即是多个Transformer Encoder堆叠起来的。
论文中提出了两种尺寸的BERT模型:
- B E R T B A S E \bf{BERT_{BASE}} BERTBASE:12层,hidden size为768,Attention Head数为12,共110M个参数。
- B E R T L A R G E \bf{BERT_{LARGE}} BERTLARGE:24层,hidden size为1024,Attention Head数为16,共340M个参数。
Input/Output Representations
在BERT中对于token的编码是将 Token Emebdding、Segment Embeddings和Position Embedding相加得的。也就是每个Token都包含了词信息、位置信息和所在段落的信息。这三种embedding都是通过学习得到的。如下图所示:

3.1 预训练BERT(Pre-training BERT)
作者使用两种无监督任务来对BERT进行预训练任务。
任务1: Masked LM :将输入的句子拿出15%的token进行替换,然后让网络预测原始的token是什么。对于被替换的token,并不是全部变成[MASK],而是选择80%的token替换成[MASK],10%的token随机变成其他token,10%的token不做任何改变。对于预测,就是BERT后面接个全连接层+Softmax,使用Cross Entropy Loss。
任务2:Next Sentence Prediction(NSP):预测输入中的两句话是不是一对儿。训练样本中,50%是一对儿,剩下的50%不是一对儿。最终,该任务可以达到97%-98%的精准率。
由于是使用NSP任务,在没有进行fine-tuning前,
[CLS]token对应的输出向量并不能很好的对整个句子进行表示。
训练数据:BooksCorpus(800M words),English Wikipedia(2500M words)
4. 个人总结
BERT本身比较简单,所以原论文对于BERT架构的描述并不过,大多都是在将用在下游任务后的效果。
其核心思想主要是以下几点:
- 在Transformer的Token Embedding和Position Embedding基础上,又增加了Segment Embedding,用于区分增加段落信息
- 仅使用了Transformer的EncoderLayer,然后堆叠多层,就是BERT
- 使用MLM任务和NSP任务对BERT进行预训练
如果对BERT的实现感兴趣,可以参考我的另一篇文章:
BERT源码实现与解读(Pytorch): https://blog.csdn.net/zhaohongfei_358/article/details/126892383