YOLOX训练-COCO格式
目录
1、准备COCO格式数据集
2、修改
(1)修改coco_classes
(2)修改路径和训练数量num_classes
(3)重写 dataset
3、训练
(1)接着上一次训练
(2)使用tensorboard可视化loss
(3)出现:OSError: [WinError 1455]页面文件太小,无法完成操作
1、准备COCO格式数据集


COCO数据集格式介绍
将MOT17数据集转为COCO格式


import os
import numpy as np
import json
import cv2
# Use the same script for MOT16
DATA_PATH = 'E:\wode\code\YOLOX_deepsort_tracker-master\datasets\mot'
OUT_PATH = os.path.join(DATA_PATH, 'annotations')
SPLITS = ['train_half', 'val_half', 'train', 'test'] # --> split training data to train_half and val_half.
HALF_VIDEO = True
CREATE_SPLITTED_ANN = True
CREATE_SPLITTED_DET = True
if __name__ == '__main__':
if not os.path.exists(OUT_PATH):
os.makedirs(OUT_PATH)
for split in SPLITS:
if split == "test":
data_path = os.path.join(DATA_PATH, 'test')
else:
data_path = os.path.join(DATA_PATH, 'train')
out_path = os.path.join(OUT_PATH, '{}.json'.format(split))
out = {'images': [], 'annotations': [], 'videos': [],
'categories': [{'id': 1, 'name': 'pedestrian'}]}
seqs = os.listdir(data_path)
image_cnt = 0
ann_cnt = 0
video_cnt = 0
tid_curr = 0
tid_last = -1
for seq in sorted(seqs):
if '.DS_Store' in seq:
continue
if 'mot' in DATA_PATH and (split != 'test' and not ('FRCNN' in seq)):
continue
video_cnt += 1 # video sequence number.
out['videos'].append({'id': video_cnt, 'file_name': seq})
seq_path = os.path.join(data_path, seq)
img_path = os.path.join(seq_path, 'img1')
ann_path = os.path.join(seq_path, 'gt/gt.txt')
images = os.listdir(img_path)
num_images = len([image for image in images if 'jpg' in image]) # half and half
if HALF_VIDEO and ('half' in split):
image_range = [0, num_images // 2] if 'train' in split else \
[num_images // 2 + 1, num_images - 1]
else:
image_range = [0, num_images - 1]
for i in range(num_images):
if i < image_range[0] or i > image_range[1]:
continue
img = cv2.imread(os.path.join(data_path, '{}/img1/{:06d}.jpg'.format(seq, i + 1)))
height, width = img.shape[:2]
image_info = {'file_name': '{}/img1/{:06d}.jpg'.format(seq, i + 1), # image name.
'id': image_cnt + i + 1, # image number in the entire training set.
'frame_id': i + 1 - image_range[0], # image number in the video sequence, starting from 1.
'prev_image_id': image_cnt + i if i > 0 else -1, # image number in the entire training set.
'next_image_id': image_cnt + i + 2 if i < num_images - 1 else -1,
'video_id': video_cnt,
'height': height, 'width': width}
out['images'].append(image_info)
print('{}: {} images'.format(seq, num_images))
if split != 'test':
det_path = os.path.join(seq_path, 'det/det.txt')
anns = np.loadtxt(ann_path, dtype=np.float32, delimiter=',')
dets = np.loadtxt(det_path, dtype=np.float32, delimiter=',')
if CREATE_SPLITTED_ANN and ('half' in split):
anns_out = np.array([anns[i] for i in range(anns.shape[0])
if int(anns[i][0]) - 1 >= image_range[0] and
int(anns[i][0]) - 1 <= image_range[1]], np.float32)
anns_out[:, 0] -= image_range[0]
gt_out = os.path.join(seq_path, 'gt/gt_{}.txt'.format(split))
fout = open(gt_out, 'w')
for o in anns_out:
fout.write('{:d},{:d},{:d},{:d},{:d},{:d},{:d},{:d},{:.6f}\n'.format(
int(o[0]), int(o[1]), int(o[2]), int(o[3]), int(o[4]), int(o[5]),
int(o[6]), int(o[7]), o[8]))
fout.close()
if CREATE_SPLITTED_DET and ('half' in split):
dets_out = np.array([dets[i] for i in range(dets.shape[0])
if int(dets[i][0]) - 1 >= image_range[0] and
int(dets[i][0]) - 1 <= image_range[1]], np.float32)
dets_out[:, 0] -= image_range[0]
det_out = os.path.join(seq_path, 'det/det_{}.txt'.format(split))
dout = open(det_out, 'w')
for o in dets_out:
dout.write('{:d},{:d},{:.1f},{:.1f},{:.1f},{:.1f},{:.6f}\n'.format(
int(o[0]), int(o[1]), float(o[2]), float(o[3]), float(o[4]), float(o[5]),
float(o[6])))
dout.close()
print('{} ann images'.format(int(anns[:, 0].max())))
for i in range(anns.shape[0]):
frame_id = int(anns[i][0])
if frame_id - 1 < image_range[0] or frame_id - 1 > image_range[1]:
continue
track_id = int(anns[i][1])
cat_id = int(anns[i][7])
ann_cnt += 1
if not ('15' in DATA_PATH):
#if not (float(anns[i][8]) >= 0.25): # visibility.
#continue
if not (int(anns[i][6]) == 1): # whether ignore.
continue
if int(anns[i][7]) in [3, 4, 5, 6, 9, 10, 11]: # Non-person
continue
if int(anns[i][7]) in [2, 7, 8, 12]: # Ignored person
category_id = -1
else:
category_id = 1 # pedestrian(non-static)
if not track_id == tid_last:
tid_curr += 1
tid_last = track_id
else:
category_id = 1
ann = {'id': ann_cnt,
'category_id': category_id,
'image_id': image_cnt + frame_id,
'track_id': tid_curr,
'bbox': anns[i][2:6].tolist(),
'conf': float(anns[i][6]),
'iscrowd': 0,
'area': float(anns[i][4] * anns[i][5])}
out['annotations'].append(ann)
image_cnt += num_images
print(tid_curr, tid_last)
print('loaded {} for {} images and {} samples'.format(split, len(out['images']), len(out['annotations'])))
json.dump(out, open(out_path, 'w'))2、修改
(1)修改coco_classes

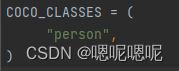
(2)修改路径和训练数量num_classes

(3)重写 dataset



3、训练
python tools/train.py -f /path/to/your/Exp/file -d 8 -b 64 -c /path/to/the/pretrained/weights
注:
(1)接着上一次训练
修改train.py
resume改为True
ckpt改为最后一个epoch的权重
start_epoch根据需要改值
parser.add_argument(
# "--resume", default=False, action="store_true", help="resume training"
"--resume", default=True, action="store_true",help="resume training"
)
parser.add_argument(
"-c", "--ckpt",
# default='pretrained/yolox_s.pth.tar',
default='YOLOX_outputs/yolox_s/latest_ckpt.pth.tar',
type=str, help="checkpoint file")
parser.add_argument(
"-e",
"--start_epoch",
# default=None,
default=2,
type=int,
help="resume training start epoch",
)(2)使用tensorboard可视化loss
在Terminal输入tensorboard --logdir=YOLOX_outputs/yolox_s/ --host=127.0.0.1

点击链接
--logdir是可视化数据所在的文件夹
如果出现:tensorboard : 无法将“tensorboard”项识别为 cmdlet、函数、脚本文件或可运行程序的名称
查看conda环境是不是当前所用的环境
在pycharm的terminal终端默认用的是base环境,需要通过activate命令激活到你所用的环境,再输入tensorboard命令。
如果在pycharm的terminal终端通过activate命令激活时无法激活到对应环境,转到File -> Settings -> Tools -> Termina
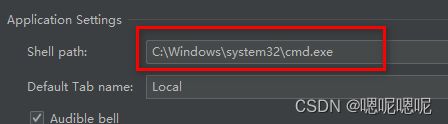
保存之后关闭pycharm重新打开。
(3)出现:OSError: [WinError 1455]页面文件太小,无法完成操作
报的错误是页面文件太小,所以需要调大页面文件的大小。电脑在默认情况下没有给C盘以外的磁盘分配虚拟内存,所以如果将Anaconda装在C盘以外的话,需要给Anaconda所在的那个磁盘分配虚拟内存即可。当然,如果就是安装在C盘,那么就将虚拟内存值调大一些。
此电脑-属性-高级系统设置



重启计算机