【论文笔记】基于深度学习的步态识别综述《Gait Recognition Based on Deep Learning: A Survey》
目录
- 1. 简介
- 2. 理论背景
-
- 2.1 生物识别
-
- 2.1.1 指纹识别
- 2.1.2 虹膜识别
- 2.1.3 人脸识别
- 2.1.4 多模态生物识别
- 2.1.5 其他方法
- 2.2 深度学习方法的步态识别
-
- 2.2.1 卷积神经网络(Convolutional Neural Networks,CNN)
- 2.2.2 胶囊网络(Capsule Networks,CapsNet)
- 2.2.3 循环神经网络(Recurrent Neural Networks,RNN)
- 2.2.4 自动编码器(Auto Encoders,AE)
- 2.2.5 深度信念网络(Deep Belief Networks,DBN)
- 2.2.6 生成对抗网络(Generative Adversarial Networks,GAN)
- 2.2.7 总结
- 2.3 步态识别
- 3. 基于深度学习的步态识别
-
- 3.1 卷积神经网络
- 3.2 胶囊网络
- 3.3~3.6 循环神经网络、自动编码器、深度信念网络、生成对抗网络
- 3.7 总结
-
- 3.7.1 解决方法
- 3.7.2 表示方法
- 4. 数据集
-
- 4.1 CMU MoBo
- 4.2 TUM GAID
- 4.3 HID-UMD
- 4.4 CASIA
- 4.5 OU-ISIR Biometric
- 4.6 USF
- 4.7 SOTON
- 4.8 AVAMVG
- 4.9 KY4D
- 4.10 WhuGAIT
- 4.11 总结归纳
- 5. 总结和展望
《Gait Recognition Based on Deep Learning: A Survey》
出版自期刊《ACM COMPUTING SURVEYS》,发布时间为2022年1月。
原文链接.
1. 简介
步态识别作为生物识别的一个重要分支,侧重于通过测量人体及构造关系进行识别检测,如:人体的躯干和四肢的尺寸测量,以及与个人运动内在形式相关的时空关系信息。
步态识别方法在监控系统或模糊的检测环境下十分有效,因为此类环境下,利用生物独特元素(如:指纹、面部、虹膜识别等)很难被检测到。此外,与其他生物识别模型相比,步态识别方法还具有黑客难以攻击(识别系统安全性高)、步态信息便于收集的优势。
但通过行走和移动来识别某一人类个体并不容易。标准的步态识别方法(包括数据预处理、特征提取等)往往因环境及任务的复杂性受到一些限制和挑战。得益于深度学习技术的出现,为步态识别的进一步研究提供了创新思路。
本文的撰写目的主要有三个方面:
- 系统地介绍最新和最著名的研究成果;
- 提供有关步态识别实质性和说明性的理论背景,探究其在生物识别方面的根源,并揭示用于步态特征提取的流行工具及解决限制的架构;
- 列举可用于步态识别任务的公共数据集目录。
2. 理论背景
2.1 生物识别
早在计算机出现之前,人的识别问题就对人类构成了巨大的挑战,当时的专家学者们通过分析比较文件、签名等其他特征,人为地构建限制性信息(如:银行交易方面)。随着社会信息化的进一步发展,提高识别精度的重要性得到加强,文献中也出现了大量相关技术。
一个标准的生物识别样本需要具备一下特点:
- 普遍性:每个人都应具备这一特征;
- 特殊性:任意两个人的特征使不同的;
- 永久性:该特征在一定的时间内是不变的;
- 可收集性:该特征能够被定量的测量。
此外,在一个实际的生物识别系统中,还存在一些不容忽视的问题:
- 性能:数据集资源、操作、环境等因素可能影响识别精度和识别速度;
- 可接受性:人们在多大程度上愿意接受在其日常生活中使用的某一生物识别器;
- 规避性:识别系统在欺诈性方法下被“愚弄”的容易程度。
在以上约束条件下,指纹、虹膜、人脸和步态识别技术表现尤为突出,下文将简要回顾这些生物识别方法。
2.1.1 指纹识别
指纹识别技术的学术名称为指纹鉴定法(Dactyloscopy),由于手指表面褶皱的奇异性,赋予了每个人独有的内在特征,因此被广泛使用。此外,指纹特征是稳定的,随着时间的推移,退化程度极低,使得数字指纹图像数据库的建立极为可靠。
第一个指纹识别模型是在20世纪60年代末设计的,基于弗朗西斯·高尔顿(Francis Galton)在19世纪创建的一个系统,成为高尔顿点(Galton points)。自此之后,许多工作通过不同的角度来解决指纹识别这一问题,如:数字图像处理、生成对抗网络、滤波表示法等。
指纹识别系统被认为是最准确和可靠的生物识别系统,但该领域仍面临着一些挑战,如在非理想条件下的识别准确性不尽人意,以及诸多欺骗性攻击等安全问题。
2.1.2 虹膜识别
虹膜指的是人类眼睛中一个有色的薄圆形结构,负责控制瞳孔直径从而控制视网膜的进光量。这一结构在人类识别领域具有很大的优势,因为随着环境改变和时间的推移它基本不会发生变化。此外,虹膜识别是最精确、低成本、最方便的识别方法之一,因为它是通过图像进行的,不需要人的接触。
大多数商业性虹膜识别模型是使用积分差分算子(integral-differential operator)来识别虹膜的上下边界,这种算子作为一个圆形边界检测器假定瞳孔是圆形的,后续研究引入了不同数学运算(如:抛物线识别、归一化等),使其更加灵活稳健。
2.1.3 人脸识别
人脸识别已经被广泛应用于多样化领域的识别认证系统,如:银行、军事服务和公安全。人脸识别技术在上个世纪90年代初由Turk和Pentland 提出Eigenfaces方法后开始流行。在接下来的十年里,出现了几种全局识别方法,这些方法来自于低维分布表征,如:线性子空间(linear sub-spaces)、稀疏表示(Sparse representation)等。但全局识别方法对面部定位变化的鲁棒性差,因此形成了局部识别方法,有局部二值模式(Local Binary Patterns,LBP)和基于Gabor特征的分类(the Gabor feature-based classification),目的是训练用于图像志特征提取的滤波器,从而使同一个人的图像之间的差异最小化。
几年前,在AlexNet神经网络赢得ImageNet比赛后,深度学习模型在包括人脸识别在内的生物识别领域获得了格外的关注。一个被称为卷积神经网络的特殊网络“家族”能够达到接近人类认知水平。
尽管人脸识别技术在过去的几年间发展到了前所未有的水准,但该领域仍面临着表情、姿势、光照、衰老以及面部遮挡等因素的影响,Tiong等人使用多模态生物识别技术来解决这些挑战。
2.1.4 多模态生物识别
与基于计算机的方法相比,人脑在人体识别上最显著的优势之一就是能够评估多种模式的描述性信息(面部、步态、头发和眼睛的颜色等)。为了拟合人脑功能,提出了一种新的生物识别模式,即“多模态生物识别”。这种方法旨在结合不同的生物识别方法和辅助信息,从而提高单一技术的性能和可靠性。
2.1.5 其他方法
目前为止提到的特征在某些环境下可能并不能进行很好的检测,要么是由于模型的精确度不高,要么是因为缺乏正确识别的专用设备,因此产生了一些并不十分常见的识别方法:
- 基于耳朵的生物识别
- 基于智能手机应用的识别
- 基于心跳频率的生物识别
- 基于互联网环境下的手势识别
- 基于眼球随动模式的特征识别
- 基于鼻子的生物识别
- 基于静脉构型的生物识别
2.2 深度学习方法的步态识别
尽管传统的机器学习和步态识别策略在过去的几年已经取得了较为满意的结果,但这些方法通常受到人工提取特征和学习数据中的固有模式而使识别能力受限。基于此种情况,深度学习方法的出现不失为一种良好的解决方案,在处理图像或视频的时序特征时,也表现出优异的性能。下文将逐一简要介绍用于步态识别的流行网络架构。

2.2.1 卷积神经网络(Convolutional Neural Networks,CNN)
卷积神经网络自2010年初取得普及以来,成为解决图像处理问题的关键技术。卷积神经网络的基本模块由卷积神经元组成,卷积核的尺寸通常是33或55的,在卷积操作后输出一组新的矩阵,然后被用作模型的后续层。因此,CNN可以被理解为产生连续层输入的卷积核的堆栈。
2.2.2 胶囊网络(Capsule Networks,CapsNet)
尽管CNN在图像特征的处理上效果很好,但容易混淆复杂的空间关系。用一个通俗的例子说明,一个训练好的CNN如果找到了狗的身体、面部、尾巴等组成部分,即使这些部分是按照不同的顺序组合而成的,CNN也能够轻易地识别出这是一只狗,而CapsNet能够有层次的识别这些部分,该模型包括两层结构,第一个是卷积编码器,它执行低层次特征的识别;第二个是代表全连接的线性解码器,采用协议路由算法,将低层次的特征处理到高层次中的正确位置。因此,CapsNet对于对象的定位更加稳健,还能更好地识别场景中的多个或重叠的物体。
2.2.3 循环神经网络(Recurrent Neural Networks,RNN)
许多文献将步态识别问题视为个人运动的图像序列来进行处理,它能够考虑到输入数据的信息以及其他神经元的输出,以循环的方式对每个神经元进行计算。该架构还可以与CNN进行结合,以提取更多关于输入图像的信息,从而进行识别推理。
由于描述一个人的步态通常需要相当数量的序列特征,一组特定的RNNs(即门控RNN)由于其具有处理长序列的能力,更适合于这项任务。在这种情况下,我们可以参考两种主要的架构,即长短时记忆模型(LSTM)和门控循环单元(GRU)。
- 长短时记忆模型(Long-short Term Memory,LSTM)
长短时记忆模型的首次提出是在1997年,由Hochreiter和Schmidhuber为改善长序列数据的结果而提出并实现的。LSTM的工作方式与传统的RNN类似,即一个给定的神经元的输出取决于之前神经元结果的递归信息,主要区别在于LSTM单元的结构更为复杂,具体构建解释如下:
遗忘门:定义了多少信息应该被保留。前一个和当前状态的数据通过一个sigmoid函数,这个函数的输出值在0和1之间,越接近1,保留的信息就越多。
输入门:计算一个新的值来更新当前的隐藏状态。输入门主要考虑两个值:一个sigmoid函数计算先前隐藏状态的重要性;原始值传给一个tanh函数,它负责在-1到1之间压扁这个值。这两个值的乘法运算定义了当前的隐藏状态。
输出门:定义了单元的输出值。来自遗忘门和输入门的值相加并传入一个tanh函数;单元的先前状态传入一个sigmoid函数;前两者相乘得到该单元的输出。 - 门控循环单元(Gated Recurrent Unity,GRU)
门控循环单元是一种循环(递归)神经网络,最初是为了改善神经机器翻译的结果而进行理想化的一种模型。与LSTM一样,GRU具有控制信息流的内部门,主要区别在于每个模型中可用的门的数量,GRU去掉了输入门,只包含遗忘门和输出门。研究表明,尽管GRU使用的门数比LSTM少,但它可以达到类似精确的结果,其优点是减少了计算负担,并且运行速度更快。
2.2.4 自动编码器(Auto Encoders,AE)
自动编码器是一种生成型神经网络,通常用于数据还原和图像去噪。该模型包括两个重要部分:
编码器:负责将输入信息编码到一个通常较小的特征空间。
解码器:执行编码数据的无监督重建。

2.2.5 深度信念网络(Deep Belief Networks,DBN)
深度信念网络是为生成任务理想设计的随机神经网络,由受限玻尔兹曼机(Restricted Boltzmann Machine,RBM) 和sigmoid信念网络(SBN) 构成的混合生成模型。
2.2.6 生成对抗网络(Generative Adversarial Networks,GAN)
生成对抗网络由于其生成真实合成图像的出色能力,在过去几年中变得很流行。该模型包括两个不同的网络:
生成器:用于学习数据的分布特征并生成合成样本
鉴别器:用于识别一个特定的实例是真实的还是由生成器生成的
两者以对抗的方式竞争,生成器试图生成足够真实的样本欺骗鉴别器,鉴别器通过改进自己以识别生成样本。

2.2.7 总结
下表总结了上述方法在步态识别领域的主要任务:
| 技术 | 任务 |
|---|---|
| 卷积神经网络(CNN) | 从图像或视频帧中提取特征 |
| 循环神经网络(RNN) | 包括LSTM和GRU,通过几个门单元来控制信息流,被用来处理时序问题 |
| 自动编码器(AE) | 通过对输入特征进行压缩和解压,从而实现识别 |
| 胶囊网络(CapsNet) | 改善CNN输出的语义特征 |
| 深度信念网络(DBN) | 将编码的特征图像进行压缩表示 |
| 生成对抗网络(GAN) | 通过对来自模型(如:CNN)的数据和生成数据进行反复辨别区分的训练方式 |
2.3 步态识别
目前为止,已经提出了几种通过生物特征识别方法,尽管这些方法的可靠性和安全性已经在银行和公共治理系统中得以证实,但仍存在两个主要障碍:
- 信息源是被动的
- 依赖于专业设备
值得庆幸的是,处理步态识别信息的模型能够有效地处理上述障碍,因为生物识别信息的获取在绝大多数情况下是依赖于一个没有特殊功能的相机或非侵入性传感器,这些信息是能够被动收集且无需考虑法律问题(在合法的前提下)。
此外,现阶段的步态识别技术可以分为基于模板和非模板两大类:
- 基于模板的方法
旨在获取躯干或腿部运动,可以通过典型相关分析、联合稀疏模型、使用组套索运动进行分割,常用的有步行路径图像(Walking Path Image,WPI)、步态信息图(Gait Information Image,GII)、步态能量图(Gait Energy Image,GEI)等。 - 基于非模板的方法
此方法认为形状和其属性是密切相关的,因此通过测量形状进行识别。
3. 基于深度学习的步态识别
3.1 卷积神经网络
卷积神经网络是基于哺乳动物视觉皮层神经元的概念,最初应用于数字分类任务,现阶段已被广泛应用于分类、重建和物体检测等方面。
许多专家学者提出了基于卷积神经网络的步态识别模型,本博客不再一一列举(如有需要,可参考论文原文)。
此外,他们比较了三种类型的数据安排方式:
- 本地底层(Local Bottom):在输入数据之间进行组合,然后直接判断输入数据是否来自同一个人(或不同的人)。
- 中层顶部(Mid-level Top):神经网络在组合两个输入数据之前,提取它们的一些特征,然后确定它们是否来自同一个人。
- 全局顶级(Global Top):与前一个网络类似,但它有一个额外的卷积和Perceptrons层,使得特征的组合是在倒数第二层进行的。
3.2 胶囊网络
另一个著名的用于步态识别的深度架构类型是胶囊神经网络。该网络通过对场景中物体(即胶囊)之间的层次关系进行建模,被开发用于图像分类。
3.3~3.6 循环神经网络、自动编码器、深度信念网络、生成对抗网络
深度信念网络是使用限制性波尔兹曼机作为构建模块的随机神经网络。这种模型由于能够完成多项任务而变得非常流行。
3.7 总结
3.7.1 解决方法
一般来说,步态识别在考虑深度学习解决方案时,卷积神经网络是最受欢迎的选择,特别是关于基于图像/视频的问题,因为CNN在各种应用中获得了出色的结果,并在过去几年中精准度测试方面取得了不错的表现成绩。值得一提的是,其他架构也为步态识别领域提供了宝贵的贡献,在一些特定的任务中表现更好。
例如,胶囊网络能够以分层的方式提取部分步态表征,在场景中有重叠的情况下提供更好的结果;递归神经网络能够较好地处理连续的数据(如视频)。
虽然大多数基于深度学习的步态识别方法包括图像/视频领域,但其他数据源(如:加速度计、陀螺仪、基于传感器等),也在相当多的论文中提供了令人印象深刻的结果,这些论文大多在这个过程中涉及无监督的深度学习方法,如自动编码器和深度信念网络,它们通常在这些数据类型上更具有表现力。这些无监督的方法可以提取有关数据分布的信息并对其进行处理,通常是在一个较低的维度空间,为步态识别提供更具代表性的特征。
最后,生成对抗网络描述了一种特殊情况,即步态系统可以学习更广泛的特征(如:方向、衣服、场景中的个体数量等),因为它们可以生成合成数据用于训练模型。此外,生成对抗网络还可用于评估基于步态的系统中的欺骗行为。
3.7.2 表示方法
关于最常用的表示步态图像数据的方法,步态能量图像(GEI) 反映了使用加权平均法的简单能量图像周期的序列。此外,对一个行进周期的序列进行处理,以对齐二进制剪影。因此,GEI保持了人类行走的静态和动态特征,并大大降低了图像处理的计算成本。通过对该方法的深入分析,我们可以观察到该模型的几个特点:
- GEI对个别图片的剪影噪声较为敏感。
- 它专注于人类行走的具体表现,不会软化矢量图像的背景。
- 它在一张图片中表示人类运动,同时保留了时间信息。
同样,基于跨视角的步态识别(cross-view-based) 是另一种流行的解决方法,用于处理不同的视觉角度。该输入类型需要多个摄像机和不同的环境,因此被限制在真实场景中。此外,在进行任何组合之前,它在视觉上将步态特征归一化,这使得模型能够学习场景中视觉运动之间的关系。
目前基于深度学习的步态识别所面临的主要挑战,可以参考步态数据的复杂性,它源于多种因素的相互作用(如:视线遮挡、相机视点、个体的外观、序列的顺序、身体部位的运动或数据中存在的光源等)。
目前,与步态识别相关的领域还有很多(如:人脸识别、情绪和姿势估计),相关领域的专家学者专注于学习混乱的语境,提取特征,将数据的高维空间中的各种解释因素分开。然而,大多数使用深度学习的步态识别方法还没有探索过这种方法,从而难以明确地以重要的不相干变量的形式分离步态数据的基本结构。尽管最近在一些步态识别方法中使用混乱的背景方法方面取得了进展,但仍有改善和进步的余地。
下表展示了本节中所介绍的所有方法的论文、发表年限、使用基本模型以及评价指标等:
| Ref. | Year | Model | Input Type | Dataset | Measure | Result |
|---|---|---|---|---|---|---|
| GEINET: View-invariant gait recognition using a convolutional neural network | 2016 | CNN | GEI | OU-ISIR | Identification rate | 94.6% |
| A comprehensive study on cross-view gait based human identification with deep CNNs | 2017 | CNN | Cross-view | CASIA-B | Accuracy | 90.8% |
| DeepGait: A learning deep convolutional representation for view-invariant gait recognition using joint Bayesian | 2017 | CNN + Joint Bayesian | Sensors | OU-ISIR | Identification rate | 97.6% |
| Gait recognition based on convolutional neural networks | 2017 | CNN | Optical flow | TUM-GAID and CASIA-B | Accuracy | 97.52% |
| On input/output architectures for convolutional neural network-based cross-view gait recognition | 2017 | CNN + Siamese networks | Cross-view | OU-ISIR | Accuracy | 98.8% |
| Pose-based deep gait recognition | 2017 | CNN + Nearest Neighbor | Optical flow | TUM-GAID, CASIA-B, and OU-ISIR | Identification rate | 99.8% |
| Invariant feature extraction for gait recognition using only one uniform model | 2017 | Autoencoders + PCA | GEI | CASIA-B and SZU RGB-D | Identification rate | 97.58% |
| Deep learning based gait recognition using smartphones in the wild | 2018 | CNN + LSTM | Accelerometer and Gyroscope | WhuGAIT and OU-ISIR | Accuracy | 99.75% |
| Multi-task GANs for view-specific feature learning in gait recognition | 2018 | GAN | PEI | OU-ISIR, CASIA B and USF | Accuracy | 94.7% |
| Artificial neural networks classification of patients with Parkinsonism based on gait | 2018 | DBN | Sensors | Private datasets | Accuracy | 93% |
| Gait recognition based on capsule network | 2019 | Capsule | LBC and MMF | OU-ISIR | Accuracy | 74.4% |
| Nonstandard periodic gait energy image for gait recognition and data augmentation | 2019 | CNN | GEI + Data Augmentation | CASIA-B | Accuracy | 98% |
| Gait recognition via disentangled representation learning | 2019 | Autoencoders + LSTM | Cross-view and Frontal-View Gait (FVG) | CASIA-B, USF and FVG | Accuracy | 99.1% |
| Person identification from partial gait cycle using fully convolutional neural networks | 2019 | Autoencoders + PCA | GEI | OU-ISIR and CASIA-B | Accuracy | 96.15% |
| Deep learning based gait abnormality detection using wearable sensor system | 2019 | LSTM | Sensors | Private datasets | Prediction error | 0.02 |
| Attacking gait recognition systems via silhouette guided GANs | 2019 | GAN | GEI | CASIA-A and CASIA-B | Recognition result | 82% |
| Human gait recognition based on frame-by-frame gait energy images and convolutional long short-term memory | 2020 | LSTM | GEI | CASIA-B and OU-ISIR | Recognition result | 99.1% |
| Cross-view gait recognition using pairwise spatial transformer networks | 2020 | CNN | Cross-view | OU-MVLP, OU-LP, and CASIA-B | Identification rate | 98.93% |
| Robust cross-view gait recognition with evidence: A discriminant gait GAN (DiGGAN) approach | 2020 | GAN | Cross-view | OU-MVLP and CASIA-B | Identification rate | 93.2% |
| Gait recognition using multiscale partial representation transformation with capsules | 2020 | Capsule | Multi-scale representations | CASIA-B and OU-MVLP | Identification rate | 84.5% |
| Continuous human gait tracking using sEMG signals | 2020 | DBN | Sensors | Private datasets | RMSE | 2.61 |
| Multi-model long short-term memory network for gait recognition using window-based data segment | 2021 | LSTM | IMU | whuGAIT and OU-ISIR | Accuracy | 94.15% |
| Associated spatio-temporal capsule network for gait recognition | 2021 | Capsule | Sensors | Several | Accuracy | 99.69% |
原文中的这个表格出现了一些错误,在本篇博客中都予以更正了。
(x, x)为表格行列数
位置 更正前 更正后 (3, 5) (5, 5) (7, 5) (8, 5) (10, 5) (13, 5)
(14, 5) (15, 5) (17, 5) (18, 5) (19, 5) (20, 5)CASIA B CASIA-B (17, 5) CASIA A CASIA-A (14, 3) Autoencoders + LSTN Autoencoders + LSTM (14, 4) Cross- and Frontal-view Cross-view and Frontal-View Gait (FVG) 因为作者在(21, 5)处使用了“CSAIA-B”带连字符的书写形式,而且这种书写形式(好像)更为普遍,所以统一改为带连字符的形式。
4. 数据集
机器学习模型的训练和评估步骤,无论采用何种模式(监督、无监督或任何其他模式),都取决于包括任务主题的数据集。此外,使用某一特定数据集可以判别方法对解决特定问题的有效性,且便于进行比较。
关于步态识别,考虑到公共或私人隐私等问题,在获取和创建数据集方面有两个突出的问题:
- 步态生物测量需要对一个对象进行合理数量的运动记录,这意味着为每个人都要被记录和生成多个视频,这些视频通常具有固有的高维度(导致数据集的增大),因此需要高存储容量。
- 生物识别数据的提取和公开发布需要得到每个参与者的许可。
4.1 CMU MoBo
CMU MoBo数据数包含的数据量相对较少,是从20个人身上提取的几个用于步态识别的视频。该数据集还提供了一组剪影掩码和边界框,从而减轻了分割过程的难度。
CMU MoBo数据集可以免费下载,无需保留或签署协议书,只需要连接Calgary University的文件传输协议(FTP)服务器即可。
4.2 TUM GAID
TUM GAID(Gait from Audio, Image, and Depth)数据集,由RGB图像、音频和深度复合而成,最初由305人录制,有三种不同的变化。后来,其中的32人被重新记录,数据集总共包括3370条记录。
TUM GAID数据集的一个强大优势是有一个明确的评估协议,该数据集需要签署请求文件才可以获得。
下图展示的是该数据集网站中的步态识别示例。

4.3 HID-UMD
HID(Human Identification at a Distance)-UMD数据集包含从四个不同角度拍摄的人走路的视频和各自用于前景分割的二进制掩码,其主要目的是帮助研究人员开发新的步态和面部生物统计学识别方法。此外,该数据集是由两个数据集组成的集合:
-
数据集1:25个人在四个不同姿势下的行走。
正面视图 / 向前走。
正面视图 / 向后走。
正面平行视图 / 向左走;
正面平行视图 / 向右走。 -
数据集2:55个人走过一个T形通道。
这些序列是由两台摄像机获得的,且两台摄像机的拍摄视线是相互正交的。
关于此数据集的更多细节可参见HID-UMD Dataset官网,申请数据集可以在官网申请地址进行申请。
4.4 CASIA
中国科学院自动化研究所提供了CASIA步态数据库,这个数据库由四个数据集组成,主要应用于步态识别,具体描述如下:
- CASIA-A: 创建于2001年12月,以前被称为NLPR步态数据库,包括20个个体,每个个体包括12个视频(即与图像平面平行、45和90度的三个方向各4个视频)。每个图像序列都有一定的持续时间,随着人行走速度的变化而变化。该数据集的总大小约为2.2 GB。下图展示了CASIA-A数据集中不同视角的一些示例。

- CASIA-B: 创建于2005年,包括从11个不同角度拍摄124个人。每个序列都重复了三次(衣着,行走速度等变化)。此外,该数据集还包括一组为所有序列提供的剪影,可用于前景分割。
下图分别展示的是不同角度和不同衣着条件下的示例图。

- CASIA-C: 创建于2005年,包含了153个由红外摄像机(热光谱)拍摄的对象,所有图像都是在夜间进行拍摄的,共有四种不同的变化:正常行走、缓慢行走、快速行走和背着背包正常行走。下图是CASIA-C的数据示例。

- CASIA-D: 包含图像和累积的脚部压力信息,该数据集包括3,496张步态姿势图像和2,658张累积脚压信息。

CASIA数据集介绍及申请地址
4.5 OU-ISIR Biometric
OU(Osaka University)-ISIR(Institute of Scientific and Industrial Research)数据集是2007年以来世界上最大的步态识别数据库,包含8个数据集:
- 跑步机数据集(Treadmill Dataset)
这组数据由人们在电子跑步机上行走的序列组成,周围有25台摄像机以每秒60帧的速度拍摄,分辨率为640×480,包含四个子数据集:
- A-速度变化: 包括34名受试者在横向视野中,速度在2到10公里/小时之间变化,间隔为1公里/小时。
- B-衣着变化: 由68个侧视的人组成,有32个服装变化。
- C-视角变化: 包括168人,年龄从4岁到75岁不等,具有25个不同的视角。
- D-步态波动: 由185名受试者的步态剪影序列组成,从侧面角度观察,速度按照高速和低速的变化被细分为两组,每组100名受试者(有15人重复)。
- 大型人群数据集(Large Population Dataset, OU-LP)
建立于2009年,通过外展活动收集的大型人口数据集由4016名受试者组成,每个受试者从四个摄像机角度拍摄两次,分辨率为30FPS,640×480像素。
- 速度过渡数据集(Speed Transition Dataset)
此数据集包括两个子集:
- Dataset A: 包含179个场景,这些场景是人们在跑步机或地面上以每小时4公里的速度匀速行走。在这组数据中,背景已被去除。
- Dataset B: 包括25个人在跑步机上行走的序列,速度在1到5公里/小时之间变化。每个人都被拍摄了两次,加速和减速在三秒钟内进行,中间的一秒钟的序列从这两段中提取出来。
- 多视角大型人群数据集(Multi-view Large Population Dataset, OU-MVLP)
该数据集由10,307个样本组成,其中5,114个为男性,其余5,193个为女性,年龄在2-87岁之间,为交叉视觉的运动识别方法而开发。这些图像从14个不同角度拍摄,帧率为每秒25帧,分辨率为1,280 × 980。用于拍摄的设备被放置在横向距离和高度分别为8米和5米的地方。
- 带有袋子的大型人群数据集(Large Population Dataset with Bag, OU-Bag)
该数据集侧重于对携带物体的人的步态识别,目的是不仅要依靠生物识别信息,而且要识别被运送部分(如果有的话)在身体上的位置。带袋子的大型人口数据集包括62,528人,年龄在2到95岁之间,通过一个距离约为8米、高度为5米的摄像机获得。这些序列的拍摄速度为每秒25帧,分辨率为1,280 × 980像素。每个人被拍摄了三次,这样,第一次,即A1,携带或不携带物体,而第二次和第三次则不携带任何东西。最后,在携带东西的情况下,总共标记了四个区域,即下侧、上侧、前侧和后侧。所有视频都有各自的二进制掩码,用于去除背景。
- 基于年龄的大型人口数据集(Large Population Dataset with Age, OU-Age)
基于年龄的大型人口数据集是为了研究有关人们年龄和性别的步态识别。该数据集包括62,846个在特定路径上行走的人,摄像机以每秒30帧的速度捕捉640×480像素的分辨率。这些序列中的人年龄在2到90岁之间,所有视频都有各自的二进制掩码,用于去除背景。
- 惯性传感器数据集(Inertial Sensor Dataset)
惯性传感器数据集被指定用于研究和评估通过运动传感器和加速度计进行个人识别的方法,它是最大的基于惯性传感器的步态数据库,由收集自744名受试者(389名男性和355名女性)的图像组成,其年龄范围为2至78岁。
- 相似动作惯性数据集(Similar Actions Inertial Dataset)
相似动作惯性数据集包括460名年龄在8到78岁之间的参与者,其性别分布基本相等,数据集还呈现了地板的六个不同特征:无效、平坦、爬楼梯、爬楼梯、爬坡道和坡道下降。
4.6 USF
USF(University of South Florida)的数据集包括来自122名受试者的1,870个序列,使用两种不同的鞋子。该数据集还考虑了携带或不携带公文包的个体,不同的表面条件(草地和混凝土),以及不同的摄像机视角(左/右视角)。这些视频是在户外环境中拍摄的两个不同的时间点上拍摄的。
4.7 SOTON
SOTON(Southampton Human ID at a Distance)数据库是南安普顿大学创建的,由三个主要部分组成:
- SOTON小型数据集(SOTON Small database) 由12名受试者组成,他们穿着不同的鞋子和衣服,携带或不携带袋子,以不同的速度在内部轨道上行走。
- SOTON大型数据集(SOTON Large database) 包含114名受试者在室外、室内的实验室轨道上和室内的跑步机上行走。图像从六个不同的角度拍摄,共计5000+个序列。
- SOTON短时数据集(SOTON Temporal) 该数据是使用多生物测量隧道采集的,它包含12个同步的摄像头来捕捉人们在一段时间内的步态。该数据集由动态环境组成,包括不同的背景、照明、行走表面和摄像机的位置。该数据集包括25名受试者(17名男性和8名女性),年龄从20岁到55岁不等。
注意,被拍摄者都是赤脚状态。
4.8 AVAMVG
AVAMVG(AVA Multi-view Dataset for Gait Recognition)数据集是一个专门为基于三维的步态识别算法设计的数据库,它包括来自20个演员的步态图像,描述了不同的轨迹。这些序列是使用专门为该任务校准的相机获得的,随后使用三维图像重建算法进行了后处理步骤。此外,每个序列还提供了各自的二进制剪影用于分割。最后,该数据库包含200个六通道多视图视频,也可以作为1200个单视图视频使用,即6×200。

4.9 KY4D
KY4D(Kyushu University 4D Gait Database)数据集是由42名受试者沿四条直线和两条曲线行走的连续三维模型和图像序列组成。这些视频由16台摄像机记录,分辨率为1,032 × 776像素,并分为三个子集:
- 数据集A(直线): 由连续的三维模型和人们沿直线行走的图像序列组成。
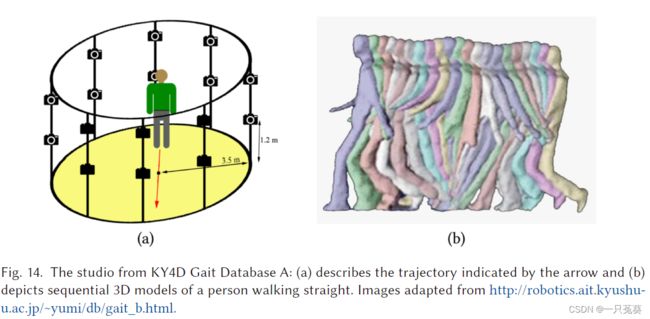
- 数据库B(曲线): 包括人们沿着曲线轨迹行走的图像序列
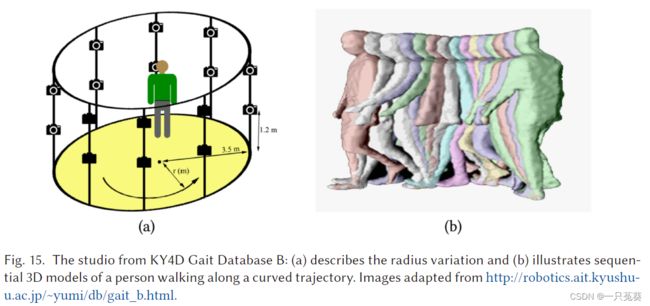
- KY红外(IR)阴影步态数据库: 它是由54名受试者的时间序列阴影图像组成的。

4.10 WhuGAIT
武汉大学于2018年发布了whuGAIT数据集,并公开了源代码和预训练模型。与其他数据集不同,whuGAIT包括从118人身上收集的3D加速度计和3轴陀螺仪信息,其中20人在三天内收集,98人在一天内收集。根据所需的任务,该数据集被分为六个不同的子集。
- 数据集#1: 由来自118人的33104个样本组成,用于训练,3740个用于测试,分为两步分割。
- 数据集#2: 与数据集#1类似,包括一个两步分割数据集,由49,275个用于训练的样本和4,936个用于测试的样本组成,提取自20人的三天收集的数据。
- 数据集#3: 这个子集被分为时间大小的窗口,每个样本包括2.56秒。该集包括26283个用于训练的实例和2991个用于测试的实例。
- 数据集#4: 与数据集#3类似,该子集被划分为2.56秒的时间框架,但使用的是三天内收集的20个人的数据。该子集包括35,373个用于训练,3,941个用于测试。
- 数据集#5: 这个子集被用于验证目的。它由118人的74,142个实例组成,从98人中提取的信息被用于训练,而其余20人被用于验证。认证程序是由一对来自一个或两个不同主体的样本组成的。这些实例包括两步的加速度和陀螺仪数据。
- 数据集#6: 这个子集采用了与数据集#5相同的结构,但它使用的不是水平对齐,而是垂直对齐。
4.11 总结归纳
下表展示了各个数据集所含数据的属性特点:
| 方面\数据集 | CMU MoBo | TUM GAID | HID-UMD | CASIA | OU-ISIR | USF | SOTON | AVAMVG | KY4D | WhuGAIT |
|---|---|---|---|---|---|---|---|---|---|---|
| Viewpoint (固定视角) |
× | × | × | × | × | × | × | × | × | |
| Pace (步态图像) |
× | × | × | × | × | × | ||||
| Object (携带物) |
× | × | × | × | ||||||
| Shoe (穿鞋) |
× | × | × | × | × | × | × | × | ||
| Clothing (穿衣服) |
× | × | × | × | × | × | × | |||
| Time (时间序列) |
× | × | × | × | × | |||||
| Surface (?没看懂) |
× | × | × | × | × | × | × | × | ||
| Silhouette (步态剪影) |
× | × | × | × | ||||||
| Gait Fluctuation (步态波动) |
× | |||||||||
| Treadmill Walking (跑步机行走) |
× | × | × | |||||||
| Overground Walking (室外行走) |
× | × | × | × | × | × | × | × | ||
| Foot Pressure (脚部压力) |
× |
博主看了几篇近年来步态识别领域的最新成果(虽然不是很多篇),感觉还是CASIA和OU-ISIR数据集的利用率更高一些,并且评价指标在业界的认可度也更高,另外就是一些作者自建的私有数据集(Private datasets),那些数据集在论文中不能单独使用进行性能评估,必须结合公开数据集。其他的一些公开数据集的利用率并不是很高,初学者了解一下就可以了(大概)。
5. 总结和展望
关于基于视频构建的数据集,有以下几点需要注意:
- 在用于测试或训练的视频序列中,有且仅有一个人出现
- 数据集中除人以外的背景是保持不变的(暗示了对于背景环境不变的强约束条件?)
因此,基于此类数据集构建的步态识别模型应用于现实世界时(如:检测公共街道上行走的多个行人),很容易出现识别错误。
关于未来的工作展望,作者提出了以下4点:
- 注意力机制:此方法尚未在步态识别领域开展较为成熟的研究。【Attention is all you need】
- 性别和年龄识别:性别和年龄的识别在论文【A deep learning approach on gender and age recognition using a single inertial sensor】中被提及,并逐渐得到应用重视。
- 危险环境监测:步态识别与危险环境监测有极大的相似度,在论文【A novel siamese-based approach for scene change detection with applications to obstructed routes in hazardous environments】中有所涉及。
- 多人场景的识别:大多数步态识别工作集中在受控环境中场景中的单一个体,但现实生活中的问题通常需要对场景中多人的非受控环境进行稳健的解决。
此外,作者观察到对穿着不同衣服或携带物品的个人进行步态识别的需求越来越大,以及由步态和补充性生物识别特征组成的混合方法,如加入面部、耳朵等部位共同进行识别。
本篇关于步态识别领域的综述文章,主要是为了初步了解此领域的研究内容、所涉及的基本方法、数据集、最新研究成果。
研究内容——能够感性认识“步态识别”到底是干什么的;
基本方法——文章内介绍的基本方法类型已经比较详实,但是具体的工作原理还需要自行查找相关资料(毕竟综述性文章不会将具体工作流程一一介绍),需要新学习的知识还有很多啊;
数据集——(截至此文发布日期)公开数据集的介绍已经非常详细,并且基本都提供了数据集的获取方法;
最新研究成果——因为步态识别近年来的研究成果更新迭代速度很快,文中所引用的成果可能在最近已经不是最优解决方案了,但是模型构建思路还具有很高的参考价值(一共引用了140篇,挑着看咯~)。
博主是翻译结合自己的理解阅读的这篇文章,如有错误恳请批评指正!