NLP基础算法总结
NLP基础算法总结
-
- 一、词法分析
-
- 1、分词
- 二、句法分析
-
- 1、依存句法分析:
-
- (1)、依存句法介绍:
- (2)、依存句法分析方法
- (3)、依存分析器的性能评价:
- (4)、依存分析任务数据集:
- (5)、依存分析的工具:
- (6)、依存句法分析应用
-
- a、在词袋模型中,依存句法的作用。
- (7)、其他
-
- a、依存句法分析与语义依存分析的区别
- 三、语义分析
-
- 1、词语级语义分析:
-
- (1)词义消歧
-
- 词义消歧的方法
-
- a、基于词典的词义消歧
- b、有监督词义消歧
- c、无监督和半监督词义消歧
- (2)词义表示和学习
- 2.句子级语义分析
-
- (1)浅层语义分析
- (2)深层语义分析
- 四、文档分析
NLP(Natural Language Processing) 简称:自然语言处理
以下为自然语言处理用到的基础算法,包括词法分析、句法分析、语义分析、文档分析
一、词法分析
词法分析包括分词、词性标注、实体识别、拼写检查等。
1、分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
这里只写中文的分词方法。
jieba分词:常用轻量级的分词方法工具(可以实现分词、词性标注、关键词提取等)
项目地址:github:https://github.com/fxsjy/jieba
简单示例:
import jieba
import jieba.posseg as pseg
import jieba.analyse
str1 = "我来到北京清华大学"
str2 = 'python的正则表达式是好用的'
str3 = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造"
seg_list = jieba.cut(str1,cut_all = True) ##全模式
result = pseg.cut(str1) ##词性标注,标注句子分词后每个词的词性
result2 = jieba.cut(str1) ##默认是精准模式
result3 = jieba.analyse.extract_tags(str1,2)
##关键词提取,参数setence对应str1为待提取的文本,topK对应2为返回几个TF/IDF权重最大的关键词,默认值为20
result4 = jieba.cut_for_search(str3) ##搜索引擎模式
print(" /".join(seg_list))
我 /来到 /北京 /清华 /清华大学 /华大 /大学
print(" /".join(result2))
我 /来到 /北京 /清华大学
hanlp分词系统
hanlp可以实现很多功能,例如分词、标注、实体识别等。
功能请参考:http://www.cnblogs.com/iihcy/p/5106305.html
个人感觉hanlp要比jieba功能强大很多
简单示例:
from pyhanlp import *
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg("我来到北京清华大学")
print(term_list)
[我/r, 来到/v, 北京清华大学/nt]
项目地址:
HanLP项目主页:https://github.com/hankcs/HanLP
HanLP下载地址:https://github.com/hankcs/HanLP/releases
二、句法分析
句法分析是自然语言处理(natural language processing, NLP)中的关键底层技术之一,其基本任务是确定句子的句法结构或者句子中词汇之间的依存关系。
根据句法结构的表示形式不同,最常见的句法分析任务可以分为以下三种:
- 句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
- 依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。
- 深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar, LTAG)、词汇功能文法(Lexical Functional Grammar, LFG)、组合范畴文法(Combinatory Categorial Grammar, CCG)等,对句子进行深层的句法以及语义分析。
1、依存句法分析:
(1)、依存句法介绍:
依存句法是由法国语言学家L.Tesniere最先提出。它将句子分析成一棵依存句法树,描述出各个词语之间的依存关系。(百度百科)
依存句法分析,(Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
例如,句子:国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。
依存句法分析结果(via 哈工大LTP):

从分析结果中我们可以看到,句子的核心谓词为“提出”,主语是“李克强”,提出的宾语是“支持上海…”,“调研…时”是“提出”的 (时间) 状语,“李克强”的修饰语是“国务院总理”,“支持”的宾语是“探索 新机制”。
有了上面的句法分析结果,我们就可以比较容易的看到,“提出者”是“李克强”,而不是“上海”或“外高桥”,即使它们都是名词,而且距离“提出”更近。
依存句法分析标注关系 (共14种) 及含义如下:

(2)、依存句法分析方法
基于规则的方法: 早期的基于依存语法的句法分析方法主要包括类似CYK的动态规划算法、基于约束满足的方法和确定性分析策略等。
基于统计的方法: 统计自然语言处理领域也涌现出了一大批优秀的研究工作,包括生成式依存分析方法、判别式依存分析方法和确定性依存分析方法,这几类方法是数据驱动的统计依存分析中最为代表性的方法。
基于深度学习的方法: 近年来,深度学习在句法分析课题上逐渐成为研究热点,主要研究工作集中在特征表示方面。传统方法的特征表示主要采用人工定义原子特征和特征组合,而深度学习则把原子特征(词、词性、类别标签)进行向量化,在利用多层神经元网络提取特征。
(3)、依存分析器的性能评价:
通常使用的指标包括无标记依存正确率(unlabeled attachment score,UAS)、带标记依存正确率(labeled attachment score, LAS)、依存正确率(dependency accuracy,DA)、根正确率(root accuracy,RA)、完全匹配率(complete match,CM)等。这些指标的具体意思如下:
- 无标记依存正确率(UAS): 测试集中找到其正确支配词的词(包括没有标注支配词的根结点)所占总词数的百分比。
- 带标记依存正确率(LAS): 测试集中找到其正确支配词的词,并且依存关系类型也标注正确的词(包括没有标注支配词的根结点)占总词数的百分比。
- 依存正确率(DA): 测试集中找到正确支配词非根结点词占所有非根结点词总数的百分比。
- 根正确率(RA): 有二种定义,一种是测试集中正确根结点的个数与句子个数的百分比。另一种是指测试集中找到正确根结点的句子数所占句子总数的百分比。
- 完全匹配率(CM): 测试集中无标记依存结构完全正确的句子占句子总数的百分比。
(4)、依存分析任务数据集:
- Penn Treebank: Penn Treebank是一个项目的名称,项目目的是对语料进行标注,标注内容包括词性标注以及句法分析。
- SemEval-2016 Task 9中文语义依存图数据: http://ir.hit.edu.cn/2461.html
下载地址:https://github.com/HIT-SCIR/SemEval-2016 - CoNLL经常开放句法分析的学术评测。
比如2018年的通用句法分析评测任务:http://universaldependencies.org/conll18/
2009年多语言多语言的句法依存和语义角色联合评测任务:http://ufal.mff.cuni.cz/conll2009-st/
2008年英语的依存句法-语义角色联合评测任务:https://www.clips.uantwerpen.be/conll2008/
2007年多语言依存分析评测:https://www.clips.uantwerpen.be/conll2007/
(5)、依存分析的工具:
- 哈工大 LTP: 哈工大LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作
Github地址:https://github.com/HIT-SCIR/ltp
官网:http://ltp.ai/index.html - StanfordCoreNLP: 斯坦福的,提供依存句法分析功能。
Github地址:https://github.com/Lynten/stanford-corenlp
官网:https://stanfordnlp.github.io/CoreNLP/ - Hanlp: HanLP是一系列模型与算法组成的NLP工具包。提供了中文依存句法分析功能。
Github地址:https://github.com/hankcs/pyhanlp
官网:http://hanlp.linrunsoft.com/ - SpaCy: 工业级的自然语言处理工具,遗憾的是不支持中文。
Gihub地址:https://github.com/explosion/spaCy
官网:https://spacy.io/ - FudanNLP: 复旦大学自然语言处理实验室开发的中文自然语言处理工具包,包含信息检索: 文本分类、新闻聚类;中文处理: 中文分词、词性标注、实体名识别、关键词抽取、依存句法分析、时间短语识别;结构化学习: 在线学习、层次分类、聚类。
Github地址:https://github.com/FudanNLP/fnlp
(6)、依存句法分析应用
a、在词袋模型中,依存句法的作用。
以百度框计算为例。对于以下两个query:
Query 1: 谢霆锋的儿子是谁?
Query 2: 谢霆锋是谁的儿子?
这两个Query的bag-of-words完全一致,如果不考虑其语法结构,很难直接给用户返回正确的结果。类似的例子还有很多。在这种情况下,通过句法分析,我们就能够知道用户询问的真正对象是什么。
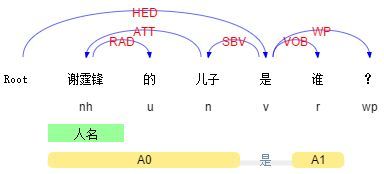

推而广之,对Query进行更general的需求分析大都离不开描述对象的提取,很多时候句法结构非常关键,更是下一步语义分析的前提
(7)、其他
a、依存句法分析与语义依存分析的区别
通过对比,对依存句法会更清晰
https://www.cnblogs.com/CheeseZH/p/5768389.html
三、语义分析
1、词语级语义分析:
词汇层面上的语义分析主要体现在如何理解某个词汇的含义,主要包含两个方面:词义消歧和词义表示
(1)词义消歧
词汇的歧义性是自然语言的固有特征。词义消歧根据一个多义词在文本中出现的上下文环境来确定其词义,作为各项自然语言处理的基础步骤和必经阶段被提出来。词义消歧包含两个必要的步骤:
(a)在词典中描述词语的意义;
(b)在语料中进行词义自动消歧。
例如“苹果”在词典中描述有两个不同的意义:一种常见的水果;美国一家科技公司。对于下面两个句子:
她的脸红得像苹果。
最近几个月苹果营收出现下滑。
词义消歧的任务是自动将第一个苹果归为“水果”,而将第二个苹果归为“公司”。
从上面的例子中我们发现,词义消歧主要面临如下两个关键问题:
(a)词典的构建;
(b)上下文的建模。
词义消歧的方法
词义消歧的研究是自然语言处理的一项基础技术,根据所使用的资源类型不同,可将词义消歧方法分为以三类:
a、基于词典的词义消歧
基于词典的词义消歧方法研究的早期代表工作是Lesk 于1986 的工作。给定某个待消解词及其上下文,该工作的思想是计算语义词典中各个词义的定义与上下文之间的覆盖度,选择覆盖度最大的作为待消解词在其上下文下的正确词义。但由于词典中词义的定义通常比较简洁,这使得与待消解词的上下文得到的覆盖度为0,造成消歧性能不高。
b、有监督词义消歧
有监督的消歧方法使用词义标注语料来建立消歧模型,研究的重点在于特征的表示。常见的上下文特征可以归纳为三个类型:
(1)词汇特征通常指待消解词上下窗口内出现的词及其词性;
(2)句法特征利用待消解词在上下文中的句法关系特征,如动-宾关系、是否带主/宾语、主/宾语组块类型、主/宾语中心词等;
(3)语义特征在句法关系的基础上添加了语义类信息,如主/宾语中心词的语义类,甚至还可以是语义角色标注类信息。
随着深度学习在自然语言处理领域的应用,基于深度学习方法的词义消歧成为这一领域的一大热点。深度学习算法自动的提取分类需要的低层次或者高层次特征,避免了很多特征工程方面的工作量。
c、无监督和半监督词义消歧
虽然有监督的消歧方法能够取得较好的消歧性能,但需要大量的人工标注语料,费时费力。为了克服对大规模语料的需要,半监督或无监督方法仅需要少量或不需要人工标注语料。
一般说来,虽然半监督或无监督方法不需要大量的人工标注数据,但依赖于一个大规模的未标注语料,以及在该语料上的句法分析结果。另一方面,待消解词的覆盖度可能会受影响。
参考代码:
import os
from urllib import request
from lxml import etree
from urllib import parse
import jieba.posseg as pseg
import jieba.analyse as anse
import numpy as np
embedding_size =300
embedding_path = "D:\workspace\project\\NLPcase\\mutilSenmanticWord\\data\\wrod_vec_300.bin"
sim_limit = 0.8
def get_html(url):
'''根据url,获取html页面'''
return request.urlopen(url).read().decode('utf-8').replace(' ','')
def collect_mutilsens(word):
'''根据单词,到百度百科上面去查询各种语义相关的句子'''
url = "http://baike.baidu.com/item/%s?force=1"%parse.quote(word)#parser.quote 对含有特殊符号的URL进行编码,使其转换为合法的url字符串
html = get_html(url)
selector = etree.HTML(html)
sens = [ ''.join(i.split(':'))for i in selector.xpath('//li[@class="list-dot list-dot-paddingleft"]/div/a/text()')]
sens_link = ['http://baike.baidu.com' + i for i in selector.xpath('//li[@class="list-dot list-dot-paddingleft"]/div/a/@href')]
sens_dict = {sens[i]:sens_link[i] for i in range(len(sens))}
return sens_dict
def extract_concept(desc):
'''概念抽取'''
desc_seg = [[i.word,i.flag] for i in pseg.cut(desc)]
concepts_candi = [i[0] for i in desc_seg if i[1] in ['n','b','v','d']]
return concepts_candi[-1]
def entity_clusters(s):
'''对具有联通边的实体进行聚类'''
clusters = []
for i in range(len(s)):
cluster = s[i]
for j in range(len(s)):
if set(s[i]).intersection(set(s[j])) and set(s[i]).intersection(set(cluster)) and set(
s[j]).intersection(set(cluster)):
cluster += s[i]
cluster += s[j]
if set(cluster) not in clusters:
clusters.append(set(cluster))
return clusters
def similarity_cosine(vector1, vector2):
'''计算问句与库中问句的相似度,对候选结果加以二次筛选'''
cos1 = np.sum(vector1*vector2)
cos21 = np.sqrt(sum(vector1**2))
cos22 = np.sqrt(sum(vector2**2))
similarity = cos1/float(cos21*cos22)
if str(similarity) == 'nan':
return 0.0
else:
return similarity
def get_wordvector(word):
'''获取单个词的词向量'''
return np.array(embdding_dict.get(word, [0]*embedding_size))
def load_embedding(embedding_path):
'''加载词向量'''
embedding_dict = {}
count = 0
for line in open(embedding_path):
line = line.strip().split(' ')
if len(line) < 300:
continue
wd = line[0]
vector = np.array([float(i) for i in line[1:]])
embedding_dict[wd] = vector
count += 1
if count%10000 == 0:
print(count, 'loaded')
print('loaded %s word embedding, finished'%count)
return embedding_dict
embdding_dict = load_embedding(embedding_path)
def concept_cluster(concept_dict):
'''词的义项聚类'''
sens_list = []
cluster_sens_dict = {}
for sen1 in concept_dict:
sen1_list = [sen1]
for sen2 in concept_dict:
if sen1 == sen2:
continue
sim_score = similarity_cosine(get_wordvector(sen1),get_wordvector(sen2))
if sim_score>= sim_limit:
sen1_list.append(sen2)
sens_list.append(sen1_list)
sens_clusters = entity_clusters(sens_list)
for sens in sens_clusters:
symbol_sen = list(sens)[0]
cluster_sens_dict[symbol_sen] = concept_dict[symbol_sen]
return cluster_sens_dict
def extract_desc(link):
'''获取该义项的描述信息,作为该义项的意义描述'''
html = get_html(link)
selector = etree.HTML(html)
keywords = selector.xpath('//meta[@name="keywords"]/@content')
desc = selector.xpath('//meta[@name="description"]/@content')
return desc,keywords
def collect_concepts(wd):
'''多义词主函数'''
sens_dict = collect_mutilsens(wd)
if not sens_dict:
return {}
concepts_dict = {}
concept_dict = {}
for sen,link in sens_dict.items():
concept = extract_concept(sen)
if concept not in concept_dict:
concept_dict[concept] = [link]
else:
concept_dict[concept].append(link)
# 对抽取的概念进行聚合
cluster_concept_dict = concept_cluster(concept_dict)
for concept,links in cluster_concept_dict.items():
# 获取对应义项的连接页面内容,并进行处理
link = links[0]
desc, keywords = extract_desc(link)
context = ''.join(desc+[' '+keywords])# 将两个内容进行合并,作为其描述
concepts_dict[concept] = context
return concepts_dict
#------------------------------------------句子的语义级别表示----------------------
# 对义项的描述信息进行关键词提取,作为该义项的一个结构化表示
def extract_keywords(sent):
keywords = [i for i in anse.extract_tags(sent,topK=20,withWeight=False)]# 结巴的关键词提取
return keywords
# 基于word2vector,通过lookup table的方式找到句子的wordvector的表示
def rep_sentVector(sent):
word_list = extract_keywords(sent)
embedding = np.zeros(embedding_size)
sent_len = 0
for index, wd in enumerate(word_list):
if wd in embdding_dict:
embedding += embdding_dict.get(wd)# 通过求和的方式表示该句子
sent_len += 1
else:
continue
return embedding/sent_len
# 基于词语相似度,计算句子的相似度
def distance_words(sent1,sent2):
wds1 = extract_keywords(sent1)
wds2 = extract_keywords(sent2)
score_wds1 = []
score_wds2 = []
for word1 in wds1:
score = max([similarity_cosine(get_wordvector(word1),get_wordvector(word2)) for word2 in wds2])
score_wds1.append(score)
for word2 in wds2:
score = max([similarity_cosine(get_wordvector(word2),get_wordvector(word1)) for word1 in wds1])
score_wds2.append(score)
sim_score = max(sum(score_wds1)/len(wds1),sum(score_wds2)/len(wds2))
return sim_score
#-----------------------对该词进行消歧---------------
def detect_main(sent,word):
sent = sent.replace(word,'')
# 多义词的获取
concept_dict = collect_concepts(word)
# 待消句子的表示
sent_vector = rep_sentVector(sent)
concept_scores_sent = {}
concept_scores_wds = {}
for concept, desc in concept_dict.items():
concept_vector = rep_sentVector(desc)
similarity_sent = similarity_cosine(sent_vector,concept_vector)
concept_scores_sent[concept] = similarity_sent
similarity_wds = distance_words(desc,sent)#另一种计算相似度的方法
concept_scores_wds[concept] = similarity_wds
concept_scores_sent = sorted(concept_scores_sent.items(),key=lambda asd:asd[1],reverse=True)
concept_scores_wds = sorted(concept_scores_wds.items(),key=lambda asd:asd[1],reverse=True)
return concept_scores_wds,concept_scores_sent
(2)词义表示和学习
对于词义表示,早期的做法将某个词义表示为,从该词义在同义词网络中出现的位置到该网络根节点之间的路径信息。
词义表示的另一个思路是将其数字化。最直观,也是到目前为止最常用的词表示方法是one-hot表示方法,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为0,只有一个维度的值为1,这个维度就代表了当前的词。不难想象,这种表示方法存在一个重要的问题:任意两个词之间都是孤立的。造成的结果是:光从两个向量中看不出两个词是否有关系,即使这两个词是同义词,例如“计算机”和“电脑”、“上海”和“上海市”。
随着机器学习算法的发展,目前更流行的词义表示方式是词嵌入(Word Embedding,又称词向量)。其基本想法是:通过训练将某种语言中的每一个词映射成一个固定维数的向量,将所有这些向量放在一起形成一个词向量空间,而每一向量则可视为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性。
例如:浅层网络的word2vec和深度神经网络的预训练模型等。
2.句子级语义分析
句子级的语义分析试图根据句子的句法结构和句中词的词义等信息,推导出能够反映这个句子意义的某种形式化表示。根据句子级语义分析的深浅,又可以进一步划分为浅层语义分析和深层语义分析。
(1)浅层语义分析
语义角色标注(Semantic Role Labeling,简称SRL)是一种浅层的语义分析。给定一个句子,SRL的任务是找出句子中谓词的相应语义角色成分,包括核心语义角色(如施事者、受事者等)和附属语义角色(如地点、时间、方式、原因等)。
目前SRL的实现通常都是基于句法分析结果,即对于某个给定的句子,首先得到其句法分析结果,然后基于该句法分析结果,再实现SRL。
(2)深层语义分析
深层的语义分析(有时直接称为语义分析,Semantic Parsing)不再以谓词为中心,而是将整个句子转化为某种形式化表示,例如:谓词逻辑表达式(包括lambda演算表达式)、基于依存的组合式语义表达式(dependencybased compositional semantic representation)等。
以下给出了GeoQuery数据集中的一个中英文句子对,以及对应的一阶谓词逻辑语义表达式:
中文:列出在科罗拉多州所有的河流
英文:Name all the rivers in Colorado
语义表达式:answer(river(loc_2(stateid(‘colorado’))))
虽然各种形式化表示方法采用的理论依据和表示方法不一样,但其组成通常包括关系谓词(如上例中的loc_2、river等)、实体(如colorado)等。语义分析通常需要知识库的支持,在该知识库中,预先定义了一序列的实体、属性以及实体之间的关系。
四、文档分析
文档是指由一系列连续的子句、句子或语段构成的语言整体单位,在一个文档中,子句、句子或语段间具有一定的层次结构和语义关系,文档结构分析旨在分析出其中的层次结构和语义关系。具体来说,给定一段文本,其任务是自动识别出该文本中的所有篇章结构,其中每个篇章结构由连接词,两个相应的论元,以及篇章关系类别构成。篇章结构可进一步分为显式和隐式,显式篇章关系指连接词存在于文本中,而隐式篇章关系指连接词不存在于文本中,但可以根据上下文语境推导出合适的连接词。对于显式篇章关系类别,连接词为判断篇章关系类别提供了重要依据,关系识别准确率较高;但对于隐式篇章关系,由于连接词未知,关系类别判定较为困难,也是篇章分析中的一个重要研究内容和难点。
参考资料:
https://blog.csdn.net/weixin_41657760/article/details/96449921
http://www.ctiforum.com/news/guandian/510101.html
https://blog.csdn.net/Zh823275484/article/details/88115041