EMNLP 2020 BiST: Bi-directional Spatio-Temporal Reasoning for Video-Grounded Dialogues
动机

- 基于视频的对话是非常具有挑战性的,这是因为(i)包含空间和时间变化的视频的复杂性,以及(ii)用户在视频或者多个对话轮中查询不同片段和/或不同目标的话语的复杂性。然而,现有的基于视频的对话方法往往关注于表面的时间级视觉线索,而不是从视频中获取更细粒度的空间信号。作者的方法旨在通过双向推理框架从视频中检索细粒度信息来挑战基于视频的对话来解决这一问题。
- 与视频对话相关的任务是视频问答和视频captioning。之前在这些研究领域的努力,如 Tgif-qa、GRU-EVEhft+sem-(CI)明确地考虑了输入视频的空间和时间特征。这些模型根据对问题的重要性来学习概括空间特征,而不是对每个区域进行等同考虑。作者受到这些方法的激励,并提议将时空推理扩展到对话。
- 作者注意到,在某些情况下,例如长时间的扩展视频,在确定特定的感兴趣的主题之前,首先识别相关的视频片段,而不是固定地处理空间输入然后学习时间输入。考虑对话设置中的问题,假设问题与视频的不同时间位置相关是适当的,而不仅仅是一个小的固定片段。
方法
简介
通常,时空学习方法的目标是从复杂视频中获取更高分辨率的信息,这些复杂视频涉及每个视频帧中的多个目标或视频片段上的运动。作者提出了一种双向视觉语言推理方法,将该方法命名为双向时空学习(BiST),通过两个推理方向来充分利用空间和时间层面的特征。作者的方法包括两个并行网络,基于用户话语中的语言信号,从输入视频中学习相关的视觉信号。每个网络将基于语言的特征投射到一个三维张量,然后该张量被用于按照一个推理方向独立地学习视频信号,该推理方向可以是空间的→时间的或时间的→空间的。每个网络的输出由基于语言和视觉特征计算的重要性分数动态组合。加权输出被循环地用作推理模块的输入,以允许模型在多个步骤中递进地导出相关视频信号。直观地看,时空推理更适合于与特定实体相关的人类查询或涉及多个目标的输入视频。时空推理更适合于人类对特定视频片段或长视频的查询。
模型
输入包括视频V、(t-1)轮对话历史(其中t是当前轮),每轮包括一对(人类话语H、对话智能体响应A)(H1, A1, …, HT-1, AT-1),以及当前人类的话语。输出是可以处理当前人类的话语的一个系统响应。输入视频可以包含不同模态的特征,包括视觉、音频和文本(例如视频caption或字幕)。在无泛化损失的情况下,作者可以将每个文本输入表示为一系列token,每个token由词汇集V中的唯一token索引表示:数据历史Xhis、用户话语Xque、视频的文本输入Xcap、以及输出响应Y。作者还将LS表示为序列S的长度。例如,Lque是Xque的长度。

作者的模型由四部分组成:
(1)编码器将文本序列和视频输入(包括视觉、音频和文本特征)编码成连续的表示。对于视觉和声音等非文本特征,作者遵循之前TVQA的工作,并假设访问预训练好的模型。
(2)多个神经推理组件学习用户话语/查询与多模态视频特征之间的依赖关系。对于视频视觉特征,作者提出在两个方向上同时学习空间和时间层面的依赖关系(参见图2)。具体地说,作者允许用户查询中的每个token与视频的每个空间位置或时间步骤之间进行交互。基于空间或基于时间的推理的输出在时间空间和空间时间两个方向上依次进行。这种双向策略使信息动态融合,并捕获对话中的文本信号和视频中的视觉信号之间的复杂依赖关系。
(3)解码器通过多个attention步骤传递编码的系统响应,每个attention步骤从文本或视频表示中提取信息。通过自回归方式,解码器输出传递给生成器以生成token。
(4)生成器计算词汇集上的三个分布,一个分布是从线性变换输出的,另一个分布是基于输入序列位置上的指针attention分数。
具体包括:
-
编码器。
1)文本编码器。作者使用编码器将基于文本的输入X嵌入到连续表示Z∈RLX×d中。LX是序列X的长度,d是嵌入维数。文本编码器包括token级嵌入层和层归一化。嵌入层包括一个可训练矩阵E∈R|V|×d,其中每一行表示词汇表集合V中的一个token,作为维度D的向量。作者将E(X)作为查找输入序列X中每个token的向量的嵌入函数:Zemb=E(X)∈RLX×d。将位置编码层,作者采用Attention is all you need中的方法,每个token位置表示为正弦或余弦函数。位置编码和token级嵌入的输出通过点加和层归一化相结合。编码器输出包括对话历史Zhis、用户查询Zque、视频caption Zcap和目标响应Zres的表示。对于目标响应,在训练期间,序列左移一个位置,以允许解码步骤i中的预测是在先前的位置1, … , (i-1)是自回归的。作者共享嵌入矩阵E来编码所有的文本序列。
2)视频编码器。作者利用3D-CNN视频模型提取时空视觉特征。输出结果的维度取决于采样步长和剪辑长度的配置。作者将预训练的视觉模型的输出表示为Zvispre∈RF×P×dvispre,其中F是采样视频片段的数量,P是来自3D CNN层的空间维度,dvispre是特征维度。作者采用一个带有ReLU的线性层,再加上层归一化,将特征维度降至d。对于音频特征,作者遵循类似的步骤来获得音频表示Zaud∈RF×d。作者保留预训练好的视觉并直接将提取的特征用于作者的对话模型。
-
双向推理。作者提出了一种双向体系结构,其中文本特征用于选择在两个推理方向中的空间和时间维度上的相关信息(见图2)。
1)时间→空间。在一个方向上,用户查询是用来根据独立于每个空间区域的时间步骤,选择相关的信息。作者首先将编码的查询特征堆叠到P空间位置,并将堆叠的特征表示为Zquestack∈RP×Lque×d。对于每个空间位置,模型通过一个attention机制学习问题和每一个时间步骤之间的依赖关系如下:
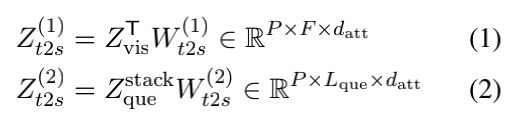

其中datt是attention隐层的维数,Wt2s(1)∈Rd×datt和Wt2s(2)∈Rd×datt。这个attention分数St2s(1)被用来获得沿着Zvis的每个空间位置的时间维度的加权和。得到的张量经过线性变换和ReLU层。输出包含时间关注的视觉特征,并通过跳连接与语言特征结合。作者用向量Zt2st表示输出。
从时间相关的特征中,再次使用用户查询来获得空间维度上的依赖关系。作者使用一个相似的注意网络来模拟查询中每个token和每个时间关注的空间区域之间的交互。

其中Wt2s(3)∈Rd×datt和Wt2s(4)∈Rd×datt。attention得分St2s(2)用于从Zt2st获得所有空间位置的加权和。输出是从时间到空间的视觉特征,并通过跳转连接整合到语言特征中。作者将结果输出表示为Zt2s。
2)空间→时间。在这个推理方向上,相似的神经操作被用来计算空间上的关注特征,然后是时间上的关注特征。与其他推理方向的主要区别在于,作者将查询特征叠加到F个时间步骤以获得Zquestack∈RF×Lque×d。其他网络组件,包括两个注意层,如公式1到6所述。最终输出表示为Zs2t。
以往基于视频的NLP任务的研究方法主要关注问题的全局表征与视频的时间层面表征之间的交互作用。这种策略可能会丢失视频帧中空间变化的关键信息。作者的方法不仅强调空间和时间特征空间,而且允许神经模型以两种不同的方式从这些特征空间扩散信息。由于作者可以把空间信息看作局部信号,把时间信息看作全局信号,作者的方法实现了视频中视觉线索的全局到局部和局部到全局的扩散。这种方法类似于Learning spatio-temporal representation with local and global diffusion,其中局部和全局的视觉信号被学习和扩散。然而,与这种方法不同的是,作者的方法侧重于语言-视觉推理,以获得更精确的视觉信息查询。
3)多模态推理。除了语言-视觉推理之外,作者的模型还考虑了查询与音频输入或文本视频输入之间的其他信息依赖关系的学习。
• 语言音频推理。作者采用了语言-视觉推理的相似神经操作。不同的是,作者直接使用查询特征,而没有将特征堆叠到公式1到3中。文本-音频推理的结果输出被表示为Zq2a,它包含Zaud的查询引导、时间关注的特征。
• 语言→语言推理。该模块主要关注用户查询和视频caption(如果caption可用)之间的单峰相关性。由于caption可以包含视频内容的有用信息,作者采用了类似于音频特征的点积attention机制来获得Zq2c。
4)多模态融合。考虑到这些特征,作者将它们结合起来,得到查询引导的视频表示,将来自所有模态的信息结合在一起。作者用以下方式表示拼接表示:

其中;是拼接操作。这些特征通过重要性评分矩阵组合起来:

其中Wq2vid∈R5d×4。Svid的得分被用于获得分量视频模态的加权和,从而得到来自多个模态的融合向量。作者将结果输出表示为Zvid。与以前通常处理所有模态都一样的工作相比,作者的多模态特征是以问题依赖的方式融合在一起的。潜在的,作者的方法可以避免噪音或不必要的信号,例如由于问题只涉及视觉内容,音频特征是不被需要。
-
响应解码器。解码器旨在以自回归方式解码系统响应。在推断期间,一个特殊的token 被馈送到解码器。然后将输出token拼接到该特殊token作为解码器的输入,以再次解码第二个token。重复该过程直到解码轮数到达极限或当预测到特殊token 时。作者应用与MTN相似的解码架构。解码器包括三个attention层,用于从文本成分获取上下文线索到输出token表示。第一层是self-attention,学习不同的token之间的依赖关系。直观地说,这有助于塑造一个语义上更结构化的序列。第二和第三个attention步骤用于从对话历史和当前用户查询中捕获上下文信息,以使响应与整个对话上下文连贯地连接。为了结合来自视频分量的文本线索,作者的解码器与MTN略有不同。代替顺序地经过多个attention层,作者只需要一层的融合特征Zvid。这是更有效的memory,因为它只需要一个单一的attention操作。也不依赖于attention层排序的设计决策。在解码步骤j中,作者表示解码器输出为Zdec∈Rj×d。
-
指针生成器。给定解码器的输出,生成器网络用于将响应物化为自然语言。线性变换用于获得词汇集V上的分布。

其中,Wvocab∈Rd×|V|。由于源序列和目标响应之间的语义相似,作者共享Wvocab和E之间的权重。为了加强模型生成能力,作者采用指针网络来强调来自源序列的token,即用户查询和视频captions。作者将Ptr(Z1, Z2)表示为指针网络操作,即Z2中的每个token通过一个可学习的概率分布“指向”Z1中的所有token。得到的概率分布由Z中的所有token聚合得到Ptr(Z1, Z2)∈LZ2×|V|。最终输出分布,表示为Pout∈Rj×|V|,它是三个分布的加权和:Pvocab、Ptr(Zque, Zdec)和Ptr(Zcap, Zdec)。该融合的权值是通过线性变换和softmax学习得到:a=Softmax(ZgenWgen)∈RLres×3,其中Zgen=[Zres; Zqueexp; Zcapexp]∈Rj×4d,Wgen∈R4d×3,Zqueexp和Zcapexp是caption的堆叠张量和到j维的用户查询。优化。在训练过程中,作者通过最小化生成损失来学习所有模型参数:

实验
实验细节
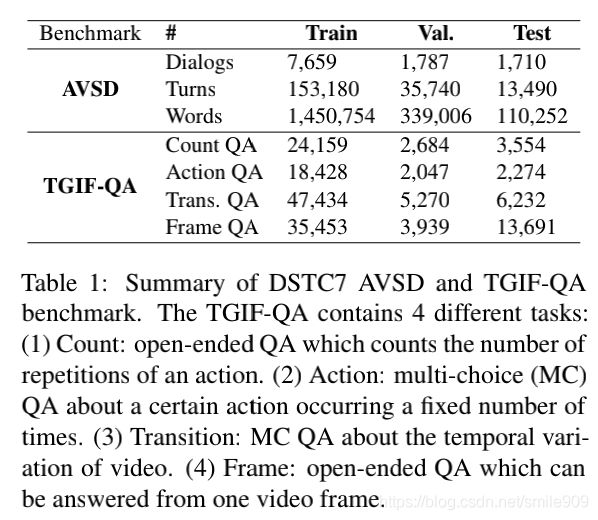
数据集。作者使用来自DSTC7的AVSD基准,该基准包含基于Charades视频的对话。此外,作者将作者的模型适应视频QA基准TGIF-QA。(两个数据集的汇总见表1)。为了提取视觉和音频特征,作者使用在Kinetics上预训练好的3D-CNN ResNext-101以获得时空视觉特征,使用在YouTube视频上预训练好的VG-GISH以提取(时间)音频特征。作者在AVSD和TGIF-QA中分别对窗口大小为16帧、步幅为16和4的视频片段进行采样,以提取视觉特征。在TGIF-QA实验中,作者还从预训练好的ResNet-152中提取视觉特征,以便与现有工作进行公平比较。在AVSD实验中,作者利用视频摘要作为视频相关的文本输入Xcap。
训练过程。作者采用来自Attention is all you need的Adam优化器和学习率策略。作者设置了相当于5个epoch的学习率的预热步骤,训练模型最多达到50个epoch。作者根据验证集中每个epoch的平均损失来选择最佳模型。作者以均匀分布初始化所有模型参数。在训练期间,作者采用来自MTN的辅助自动编码器丢失功能。在作者的模型中采用Transformer attention并选择以下超参数:d=datt=128,Natt=Ndec=3,和hatt=8,其中Natt和Ndec是多模态推理和解码器网络中Transformer块的数目,hatt是注意力头的数目。在验证集上进行网格搜索之后,作者调优了其他超参数。在AVSD实验中,作者通过在目标系统响应Y上应用标签平滑来训练作者的模型。作者采用beam搜索技术,一个beam大小为5。
视频QA的修改
在TGIF-QA等许多视频QA基准中,任务是基于检索的(例如,为每个输出CAN-DIDATE输出单个得分),而不是像许多对话任务那样基于生成的。作者首先将问题与每个候选答案单独拼接起来,并将其视为作者模型的Zque。由于没有目标响应需要解码,作者通过使用一个可训练向量zj∈Rd来表示一个候选响应Rj,代替对话中的Zres ∈Rj×d作为解码器的输入,使作者的模型适应这种设置。将表示为Zj,dec∈Rd的输出传递到线性变换层以获得分数sj,out=Zj,decWout∈R,其中Wout∈Rd×1。在此设置中,作者删除了language→language和language→audio推理模块。损失函数是肯定答案soutp和每一个否定的答案soutp分数之间的相加成对hinge损失。

其中K为候选答案总数,m是一个超参数,用作正负答案之间的一个边际。
训练。在K=5和m=1的成对损失后训练多项选择任务,包括Action和Transition。Count任务用类似的方法训练,但它是一个回归问题,具有单一的输出分数sout。损失函数被测量为输出sout和标签Y之间的均方误差。开放式Frame任务被训练为一个生成任务,类似于对话响应生成任务,具有单token输出。作者使用向量z∈Rd作为解码器的输入。该生成器包括一个Wout∈Rd×|V|的线性层。在这种情况下,作者不采用指针网络,因为输出只是一个单token响应。
实验结果
AVSD结果。作者报告了客观评分,包括BLEU、METEOR、ROUGE-L和CIDEr。这些度量标准是从机器翻译和captioning等语言生成任务中借鉴来的,它描述了生成的和GT对话响应之间的词汇重叠。作者将作者所产生的响应与6篇参考响应进行比较。主要的基准模型有:(1)Baseline包括由基于LSTM的编码器组成,在用户查询和时间级的视觉和音频特征之间具有attention层。
(2) Baseline+GRU+HierAttn延伸(1)通过GRU和问题引导的self-attention和caption attention。
(3) FA+HRED采用FiLM神经块进行语言视觉依赖学习。
(4) Video Summarization将任务重新定义为视频摘要任务,并通过大规模摘要基准的迁移学习增强模型。
(5) Student-Teacher采用双网络架构,其中学生网络被训练成模仿教师网络,教师网络通过额外的视频相关文本输入进行训练。
(6)MTN通过一个Transformer解码器体系结构将不同模态的时间特征顺序地融合。
(7)FGA由所有模态对之间的attention网络组成,模型沿着attention图的边缘聚合attention分数。

在表2中,作者通过不同的特征组合给出了分数,包括视觉Zvis、音频Zaud和文本Zcap。在所有情况下,作者的模型都优于现有的方法。作者的模型在纯视觉环境下的性能表明了作者的双推理语言-视觉推理方法所带来的性能增益。作者的双向语言-视觉推理方法所带来的性能增益。此外,当考虑视频中的文本特征时,还可以观察到性能的提升。然而,当作者添加音频特征时,性能增益并不显著。这揭示了作者工作中的一个潜在的未来扩展,以更好地结合视觉和音频特征表示。FGA报告在仅视觉设置下CIDEr得分为0.806。与FGA相比,作者的性能提高表明了在空间和时间两个层次上学习查询和视觉特征之间的细粒度依赖关系以从视频中选择相关信息的有效性。

TGIF-QA结果。作者给出了计算任务的L2损失和其他三个QA任务的准确性。从表3可以看出,作者的模型在所有QA任务中都优于现有的方法,使用帧级(外观)特征ResNet或序列级特征ResNext。作者的模型在使用ResNext时表现得更好,因为作者期望序列级特征比帧级特征更一致。在该基准测试上的实验表明,作者的双向语言-视觉推理方法的性能得到了更明显的提高,因为它不像AVSD实验那样受到生成组件错误的影响。通过从时空特征中学习高分辨率的依赖关系,作者的模型能够充分利用上下文线索,为视频问答任务选择更好的答案。

空间-时间学习的影响。作者考虑了基于时空-时间的模型的变体,并在表4中报告结果。作者注意到,当使用单一推理方向时,具有时间空间的模型比具有反向推理方向的模型性能更好。这种观察不同于以往的时空学习研究,如 Tgif-qa,它们局限于推理顺序空间→时间。这可以解释为AVSD基准中的视频通常比其他QA基准长。在选择单个帧中的空间区域之前,首先关注帧序列中的时间位置是实际的。此外,对话查询被定位在多轮设置中,由此,随着对话的发展,每一轮是和不同的视频段相关。这一观察结果潜在地表明了视频对话与视频问答的一个重要区别。其次,作者还观察到,当作者同时使用两个推理方向而不是只使用其中一个时,作者的模型性能有所提高。作者提出这种方法的动机与Bi-RNN相似,后者提出了一种双向策略来处理向前和向后两个方向的序列。同样,作者的方法通过一种双向信息扩散策略来利用视觉信息,该策略可以根据语言输入从空间和时间两个方面来解释信息。最后,作者认为使用时空特征是比只使用其中的一个更好,证明了信息在两个维度上的重要性。为了获得仅空间或仅时间特征的Zvis,时空特征通过分别沿时间维度或空间维度做平均池化操作。
消融分析

作者用不同超参数集的模型变体进行实验。具体地说,作者改变attention轮数Natt和attention头数hatt。从表5中,作者注意到了多轮体系结构对语言-视觉推理的贡献,因为随着推理步骤的增加,即多达三轮attention,性能得到改善。然而,作者观察到当作者增加到超过3个推理步骤时,模型性能仅有轻微的改善。作者还注意到,使用多头attention机制适合于处理视频和视频等信息密集型媒体的任务。多头结构能够将特征投影到多个子空间,并捕获复杂的语言-视觉依赖关系。
定性分析

在图3中,作者给出了一些示例输出。作者注意到BiST模型的预测对话响应更接近于GT响应。特别是对于查询特定片段(示例B、C、D)和/或特定空间位置(示例D)的复杂问题,作者的方法通常能够产生更好的响应结果。另一个观察是,对于不明确的例子,如例子C(其中视觉外观不能清晰地区分“apartment”和“business office”),作者的模型可以返回正确答案。潜在地,这可以通过从空间级特征表示中提取的信号来解释。最后,作者注意到仍有一些错误使输出的句子部分错误,如不匹配的主语(例A)、错误的实体(例B)、或错误的动作(例C)。
贡献
(1)作者的方法不是只利用时间级信息,同时强调视频的空间和时间特征,以实现更高分辨率的视频线索查询。
(2)针对会话查询中信息的多样性,作者提出了一种双向策略,即时间↔空间策略,使信息在两个视觉特征空间之间得到全面的扩散。
(3)作者的模型在来自第七届对话系统技术测试(DSTC7)的“AVSD”(视听场景感知对话)基准上实现了具有竞争力的性能。作者将作者的模型应用于视频QA任务“TGIF-QA”,并实现了显著的性能提升。
(4)对本文提出的双向推理方法进行了全面的理论分析和定性分析,验证了本文提出的双向推理方法的有效性。
小结
作者提出了pose双向时空学习(BiST)是一种基于文本线索的视频高分辨率查询的视觉语言神经框架。具体地说,作者的方法不仅利用了空间和时间两个层次的信息,而且通过空间到时间和时间到空间的推理来学习信息在两个特征空间之间的动态扩散。双向策略旨在解决对话设置中用户查询的语义演变问题。检索到的视觉线索被用作上下文信息来构造对用户的相关响应。作者的实验结果和全面的量化分析表明,BiST在大规模AVSD基准测试中取得了良好的性能,并产生了合理的响应。作者还调整了作者的BiST模型以适应视频QA设置,并且在TGIF-QA基准测试上大大优于以前的方法。