机器学习笔记(第六章支持向量机)
机器学习(周志华著) Datawhale打卡第四天
第六章 支持向量机
基本
- 为什么使用支持向量
对于给定训练集 D = { ( x 1 , y 1 ) , . . . , ( x m , y m ) } , y ∈ { − 1 , + 1 } D=\{(x_1,y_1),...,(x_m,y_m)\},y\in\{-1,+1\} D={(x1,y1),...,(xm,ym)},y∈{−1,+1}二分类问题,之前的线性回归的思想是在样本空间找到一个划分超平面,但如下图所示,将样本划分的超平面可能有很多,我们如何得知哪个超平面是最佳的呢。

直观上看,两堆样本的“正中间”的划分超平面,对样本局部扰动的“容忍”性最好。例如,当训练集由于局限性或者噪声的因素而产生一些接近分隔平面的样本点时,其他划分平面会更容易出现错误,而最中间的超平面受影响最小,即“鲁棒”性最好,如何找到这个超平面,就是支持向量机的任务。
- 支持向量
样本空间中,划分超平面用如下方程描述:
w T x + b = 0 其 中 w = { w 1 , w 2 , . . . , w d } 为 法 向 量 , b 为 位 移 项 w^Tx+b=0\\ 其中w=\{w_1,w_2,...,w_d\}为法向量,b为位移项 wTx+b=0其中w={w1,w2,...,wd}为法向量,b为位移项
样本中任意点到超平面的距离 r = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ r=\frac{|w^Tx+b|}{||w||} r=∣∣w∣∣∣wTx+b∣,由于这个公式比较重要,下面来证明
证 : 设 任 意 一 点 为 x 0 = ( x 1 0 , x 2 0 , . . . , x n 0 ) T 其 在 超 平 面 上 的 投 影 点 为 x 1 = ( x 1 1 , x 2 1 , . . . , x n 1 ) T 有 w T x 1 + b = 0 , 且 有 x 1 x 0 ⃗ 与 法 向 量 w 平 行 因 此 ∣ w . x 1 x 0 ⃗ ∣ = ∣ ∣ w ∣ ∣ . ∣ ∣ x 1 x 0 ⃗ ∣ ∣ = ∣ ∣ w ∣ ∣ . r w . x 1 x 0 ⃗ = w 1 ( x 1 0 − x 1 1 ) + . . . w n ( x n 0 − x n 1 ) = w T x 0 − w T x 1 = w T x 0 + b 即 r x 0 = ∣ w T x 0 + b ∣ ∣ ∣ w ∣ ∣ 证:设任意一点为x_0=(x_1^0,x_2^0,...,x_n^0)^T\\ 其在超平面上的投影点为x_1=(x_1^1,x_2^1,...,x_n^1)^T\\ 有w^Tx_1+b=0,且有\vec{x_1x_0}与法向量w平行\\ 因此|w.\vec{x_1x_0}|=||w||.||\vec{x_1x_0}||=||w||.r\\ \begin{aligned} w.\vec{x_1x_0}&=w_1(x_1^0-x_1^1)+...w_n(x_n^0-x_n^1)\\ &=w^Tx_0-w^Tx_1\\ &=w^Tx_0+b \end{aligned} \\ 即r_{x_0}=\frac{|w^Tx_0+b|}{||w||} 证:设任意一点为x0=(x10,x20,...,xn0)T其在超平面上的投影点为x1=(x11,x21,...,xn1)T有wTx1+b=0,且有x1x0与法向量w平行因此∣w.x1x0∣=∣∣w∣∣.∣∣x1x0∣∣=∣∣w∣∣.rw.x1x0=w1(x10−x11)+...wn(xn0−xn1)=wTx0−wTx1=wTx0+b即rx0=∣∣w∣∣∣wTx0+b∣
假设超平面 ( w , b ) (w,b) (w,b)能将样本正确分类,对于二分类的正样本 y i = + 1 y_i=+1 yi=+1,与负样本 y i = − 1 y_i=-1 yi=−1,其应该满足:
{ w T x i + b ≥ + 1 , y i = + 1 w T x i + b ≤ − 1 , y i = + 1 \begin{cases} & w^Tx_i+b\ge +1 ,y_i=+1\\ & w^Tx_i+b\le -1,y_i=+1 \end{cases} {wTxi+b≥+1,yi=+1wTxi+b≤−1,yi=+1
其中,存在缩放变换 ς w ⟼ w ′ 和 ς b ⟼ b ′ \varsigma w\longmapsto w'\text和\varsigma b\longmapsto b' ςw⟼w′和ςb⟼b′,使得距离超平面最近的几个样本点,可使上式等号成立,如图所示,
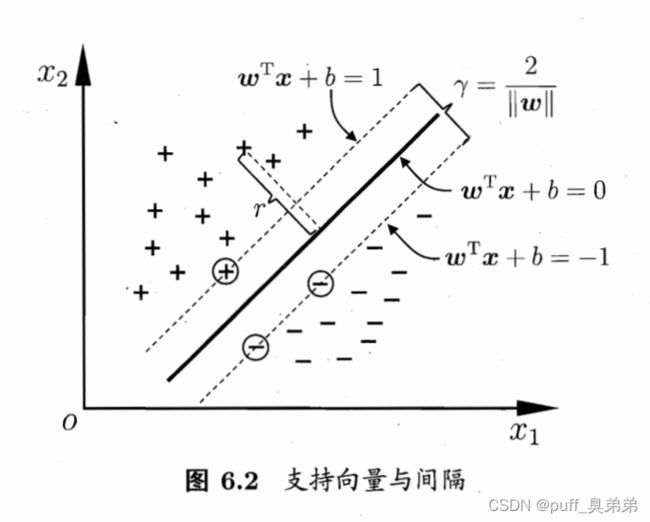
这些使等号成立的向量被称为“支持向量”。
它们到超平面的距离之和为 γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac{2}{||w||} γ=∣∣w∣∣2,称为“间隔”。
支持向量的任务便转化为寻找“最大间隔”的划分超平面,即找到合适的 w , b w,b w,b,使得
max w , b 2 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2... , m \max_{w,b}\frac{2}{||w||} \\ s.t. \ y_i(w^Tx_i+b)\ge 1,\ i=1,2...,m w,bmax∣∣w∣∣2s.t. yi(wTxi+b)≥1, i=1,2...,m
而最大化 ∣ ∣ w ∣ ∣ − 1 ||w||^{-1} ∣∣w∣∣−1等价于最小化 ∣ ∣ w ∣ ∣ 2 ||w||^2 ∣∣w∣∣2,于是上式可重写为
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2... , m \min_{w,b}\frac{1}{2}||w||^2\\ s.t. \ y_i(w^Tx_i+b)\ge 1,\ i=1,2...,m w,bmin21∣∣w∣∣2s.t. yi(wTxi+b)≥1, i=1,2...,m
这就是支持向量机(Support Vector Machine,SVM)的基本型。
- 对偶问题
基本型可以直接用现成的优化方法求解,但是求解其对偶问题更为高效。
对基本型使用拉格朗日乘子法可得到其“对偶问题”
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) 令 ∂ L ∂ w = 0 , ∂ L ∂ b = 0 得 w = ∑ i = 1 m α i y i x i 0 = ∑ i = 1 m α i y i L(w,b,\alpha)=\frac{1}{2}||w||^2+\sum_{i=1}^{m}\alpha_i (1-y_i(w^Tx_i+b))\\ 令\frac{\partial L}{\partial w}=0,\frac{\partial L}{\partial b}=0\\ 得w=\sum_{i=1}^{m}\alpha_iy_ix_i\\ 0=\sum_{i=1}^{m}\alpha_iy_i\\ L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))令∂w∂L=0,∂b∂L=0得w=i=1∑mαiyixi0=i=1∑mαiyi
代入得对偶问题
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . , m \max_{\alpha}\sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j\\ s.t. \ \sum_{i=1}^{m}\alpha_iy_i=0,\\ \alpha_i\ge0,\ i=1,2,...,m\\ αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t. i=1∑mαiyi=0,αi≥0, i=1,2,...,m
以及KKT条件
{ α i ≥ 0 y i f ( x i ) − 1 ≥ 0 α i ( y i f ( x i ) − 1 ) = 0 \begin{cases} & \alpha _i\ge 0 \\ & y_if(x_i)-1\ge 0\\ & \alpha _i(y_if(x_i)-1)=0 \end{cases} ⎩⎪⎨⎪⎧αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
算法的求解比较复杂,后面再写。。。
- 未完待续。。。