《Deep Learning for Computer Vision withPython》阅读笔记-StarterBundle(第6 - 7章)
6.配置您的开发环境
当涉及到学习新技术(尤其是深度学习)时,配置开发环境往往是成功的一半。在不同的操作系统、不同的依赖版本以及实际的库本身之间,配置您自己的深度学习开发环境可能是相当令人头痛的事情。
这些问题都因深度学习库的更新和发布速度而变得更加复杂——新功能推动了创新,但也打破了以前的版本。尤其是CUDA工具包就是一个很好的例子:平均每年有2-3个新版本的CUDA。
每一个新版本都会带来优化、新特性和更快训练神经网络的能力。但每个版本都会使向后兼容性更加复杂。这个快速发布周期意味着深度学习不仅取决于您如何配置开发环境,还取决于您何时配置它。根据时间范围,您的环境可能已过时!
由于深度学习依赖关系和库的性质在迅速变化,我决定将本章的大部分内容转移到配套网站上(http://dl4cv.pyimagesearch.com/)因此,新的、新鲜的教程将始终可供您使用。
你应该用这一章来帮助自己熟悉我们将在本书中使用的各种深度学习库,然后按照本书中链接到这些库的页面上的说明进行操作。
P65
//2021.12.18日下午14:43学习笔记
6.1库和包
为了成为一个成功的深度学习实践者,我们需要一套正确的工具和包。本节详细介绍了编程语言以及我们将用于研究计算机视觉深度学习的主要库。
6.1.1 python
我们将在计算机视觉深度学习中使用Python编程语言的所有示例。Python是一种容易学习的语言,而且无疑是最好的学习深度学习算法的方法。简单、直观的语法让你专注于学习深度学习的基础知识,而不是花时间修复其他语言的编译器错误。
6.1.2 Keras
为了建立和训练我们的深度学习网络,我们将主要使用Keras库。Keras同时支持TensorFlow和Theano,使得快速构建和训练网络非常容易。有关TensorFlow和Theano与Keras兼容性的更多信息,请参阅第6.2节。
6.1.3 Mxnet
我们还将使用mxnet,一个专门用于分布式、多机器学习的深度学习库。在海量图像数据集(如ImageNet)上训练深度神经网络架构时,跨多个gpu /设备并行训练的能力至关重要。
重点:mxnet库只在本书的ImageNet Bundle中使用。
6.1.4 OpenCV, scikit-image, scikit-learn等等
由于本书侧重于将深度学习应用于计算机视觉,我们也将利用一些额外的库。在使用这本书的时候,你不需要是这些库的专家或者有使用它们的经验,但是我建议你熟悉一下OpenCV的基本知识。实用Python和OpenCV的前五章足以让你理解OpenCV库的基础知识。
OpenCV的主要目标是实时图像处理。这个库从1999年就已经出现了,但是直到2009年的2.0版本,我们才看到了令人难以置信的Python支持,其中包括将图像表示为NumPy数组。
OpenCV本身是用C/ c++编写的,但是在运行安装时提供了Python绑定。在图像处理方面,OpenCV无疑是事实上的标准,因此我们将在从磁盘加载图像、将其显示到屏幕以及执行基本的图像处理操作时使用它。
为了补充OpenCV,我们还将使用少量的scikit-image [62] (scikit-image.org),这是一组用于图像处理的算法。
Scikit-learn [5] (scikit-learn.org)是一个开源为机器学习Python库,交叉验证,和可视化——这图书馆补充Keras,帮助我们从没有“重新发明轮子”,特别是当它涉及到创建培训/测试/验证分裂和验证深度学习模型的准确性。
6.2配置开发环境
如果你已经准备好配置你的深度学习环境,只需点击下面的链接,并按照提供的操作系统说明,以及你是否将使用GPU:
如果您还没有在Python计算机视觉深度学习的配套网站上创建您的帐户,请参阅本书的前几页(紧跟着目录)的注册链接。在那里,创建你的账户,你就可以访问补充材料。
6.3预配置虚拟机
我意识到,配置开发环境不仅是一项耗时、乏味的任务,而且如果您是基于unix的环境的新手,那么这可能是一个主要的入门障碍。由于这一困难,您购买的Python计算机视觉深度学习包括一个预配置的Ubuntu VirtualBox虚拟机,它提供了所有必要的深度学习和计算机视觉库,当您使用这本书时,您将需要成功地进行预配置和预安装
确保您下载了包中包含的VirtualMachine.zip以访问此虚拟机。关于如何设置和使用虚拟机的说明可以在随本书下载的README.pdf中找到。
6.4基于云计算的实例
Ubuntu虚拟机的一个主要缺点是,根据虚拟机的定义,虚拟机不允许访问主机的物理组件(如GPU)。当训练更大的深度学习网络时,拥有GPU是非常有益的。
对于那些希望在训练他们的神经网络时访问GPU的人,我建议:
- 配置支持GPU的Amazon EC2实例。
- 注册FloydHub帐户并配置云中的GPU实例。
需要注意的是,每个选项都是根据启动实例的小时数(EC2)或秒数(FloydHub)收费的。如果你决定走“GPU在云路线”,一定要比较价格和意识到你的支出-没有什么比得到一个大的,意外的账单云使用。
如果您选择使用基于云的实例,那么我建议您使用我预配置的Amazon Machine instance (AMI)。AMI提供了本书中所需要的所有深度学习库,这些库都是预先配置和安装的。
要了解更多关于AMI的信息,请参考Python同伴网站的计算机视觉深度学习。
6.5 如何组织项目
现在您已经有机会配置开发环境,现在花一点时间下载与Starter Bundle关联的代码和数据集的.zip。
下载完文件后,解压缩它,你会看到以下目录结构:
每一章(包括附带的代码)都有自己的目录。每个目录然后包括:
- 本章的源代码。
- 深入学习的pyimagesearch库,你将创建,随着你跟随这本书。
- 运行各自示例所需的任何额外文件。
顾名思义,datasets目录包含Starter Bundle的所有图像数据集。
举个例子,假设我想训练我的第一个图像分类器。我首先将目录改为chapter07-first_image_classifier,然后执行knn.py脚本,将命令行参数——dataset指向动物数据集:

这将指导knn.py脚本在“动物”数据集(数据集中的一个子目录)上训练一个简单的k-Nearest Neighbor (k-NN)分类器,该数据集是图像中狗、猫和熊猫的一个小集合。
如果你是命令行和如何使用命令行参数的新手,我强烈建议你在阅读这本书之前阅读命令行参数和如何使用它们:
Python, argparse, and command line arguments - PyImageSearch
熟悉命令行(以及如何使用终端调试错误)是需要开发的一项非常重要的技能。
最后,作为一个简短的说明,我想提一下,我喜欢把我的数据集与源代码分开,因为它:
1.保持我的项目结构整洁
2.允许我跨多个项目重用数据集
我鼓励您对自己的项目采用类似的目录结构。
6.6总结
当涉及到配置您的深度学习开发环境时,您有许多选项。如果您更喜欢在本地机器上工作,这是完全合理的,但是您需要首先编译和安装一些依赖项。如果你打算在本地机器上使用兼容cuda的GPU,还需要一些额外的安装步骤。
对于刚开始配置开发环境的读者,或者只是想跳过整个过程的读者,请务必查看包含在Python包Deep Learning For Computer Vision下载中的预先配置的Ubuntu VirtualBox虚拟机。
如果你想使用GPU,但没有一个连接到你的系统,考虑使用基于云的实例,如Amazon EC2或FloydHub。虽然这些服务需要每小时收费,但与预先购买GPU相比,它们可以节省你的钱
最后,请记住,如果您计划进行任何严肃的深度学习研究或开发,请考虑使用Linux环境,如Ubuntu。深度学习工作时绝对可以在Windows上完成(不推荐)或macOS(完全可以接受如果你是刚刚开始),几乎所有的生产级深度学习利用基于linux的操作系统环境中,记住这一点当你配置自己的深度学习开发环境。
7. 你的第一个图像分类器
在过去的几章中,我们花了相当多的时间讨论图像的基本原理、学习类型,甚至是我们在构建自己的图像分类器时可以遵循的四步管道。但是我们还没有建立一个真正属于我们自己的图像分类器。
这将在本章中改变。我们将首先构建几个助手实用程序,以便于预处理和从磁盘加载图像。从那里,我们将讨论k近邻(k-NN)分类器,这是您第一次接触使用机器学习进行图像分类。事实上,这个算法非常简单,它根本不做任何实际的“学习”——但它仍然是一个重要的算法,我们可以在未来的章节中了解神经网络如何从数据中学习。
最后,我们将运用我们的k-NN算法来识别图像中的各种动物。
7.1使用图像数据集
当处理图像数据集时,我们首先必须考虑以字节为单位的数据集的总大小。我们的数据集是否足够大,以适应我们机器上的可用RAM ?我们可以像加载一个大矩阵或数组一样加载数据集吗?或者数据集太大,超过了我们机器的内存,需要我们将数据集“块”成段,每次只加载部分?
Starter Bundle中的数据集都足够小,我们可以将它们加载到主存中,而无需担心内存管理;然而,在练习者Bundle和ImageNet Bundle中更大的数据集将需要我们开发一些聪明的方法来有效地处理加载的图像,以一种我们可以训练图像分类器(而不会耗尽内存)的方式
也就是说,在开始使用图像分类算法之前,您应该始终了解数据集的大小。正如我们将在本章的其余部分看到的,花时间组织、预处理和加载数据集是构建图像分类器的一个关键方面。
7.1.1介绍“Animals”数据集
“Animals”数据集是一个简单的示例数据集,我把它们放在一起,演示如何使用简单的机器学习技术和先进的深度学习算法训练图像分类器。

Animals数据集中的图像属于三个不同的类别:狗、猫和熊猫,每个类别有1000张示例图像。狗和猫的图像从Kaggle狗vs猫挑战(http://pyimg.co/ogx37)中采样,而熊猫的图像从ImageNet数据集[42]中采样。
仅包含3000张图片的Animals数据集可以很容易地放入我们机器的主内存中,这将使我们的模型的训练速度更快,而不需要我们编写任何“开销代码”来管理无法放入内存的数据集。最重要的是,深度学习模型可以在CPU或GPU上快速训练该数据集。不管你的硬件设置如何,你都可以使用这个数据集学习机器学习和深度学习的基础知识。
在本章中,我们的目标是利用k-NN分类器,尝试仅使用原始像素强度来识别图像中的每一个物种(即没有进行特征提取)。正如我们将看到的,原始像素强度并不适合k-NN算法。尽管如此,这是一个重要的基准实验,所以我们可以理解为什么卷积神经网络能够获得如此高的原始像素强度的精度,而传统的机器学习算法不能做到这一点。
7.1.2深度学习工具包的开始
正如我在第1.5节中提到的,我们将在整本书中构建我们自己的自定义深度学习工具包。我们将从基本的辅助函数和类开始,以预处理图像和加载小数据集,最终构建当前最先进的卷积神经网络的实现。
事实上,我在做我自己的深度学习实验时也使用了同样的工具箱。该工具包将逐章逐章地构建,允许您查看组成该包的各个组件,最终成为一个成熟的库,可用于快速构建和训练您自己的定制深度学习网络。
让我们开始定义工具箱的项目结构:
如您所见,我们有一个名为pyimagesearch的模块。我们开发的所有代码都将存在于pyimagesearch模块中。为了本章的目的,我们需要定义两个子模块:

datasets子模块将启动一个名为SimpleDatasetLoader的类的实现。我们将使用这个类从磁盘加载小图像数据集(可以放入主存),根据一组函数选择性地预处理数据集中的每个图像,然后返回:
1. 图像(即原始像素强度)
2. 类标签与每个图像相关联
然后我们有预处理子模块。我们将在后面的章节中看到,有许多预处理方法可以应用于我们的图像数据集,以提高分类精度,包括平均减法,随机采样补丁,或简单地将图像调整为固定大小。在本例中,SimplePreprocessor类将执行后一种操作——从磁盘加载图像并将其大小调整为固定大小,忽略长宽比。在接下来的两节中,我们将手工实现SimplePreprocessor和SimpleDatasetLoader。
虽然我们将在本书中回顾整个pyimagesearch模块,以便深入学习,但我特意留下了对__init__的解释。作为对读者的练习。这些文件只是包含快捷导入,与理解应用于图像分类的深度学习和机器学习技术无关。如果您是Python编程语言的新手,我建议您温习一下包导入的基础知识[63](http://pyimg.co/7w238)。
7.1.3基本图像预处理器
机器学习算法,如k-NN,支持向量机,甚至卷积神经网络,都要求数据集中的所有图像具有固定的特征向量大小。在图像的情况下,这个要求意味着我们的图像必须经过预处理和缩放,以具有相同的宽度和高度。
有很多方法可以实现这种大小调整和缩放,从更高级的方法,即尊重原始图像的长宽比到缩放后的图像,到简单的方法,即忽略长宽比并简单地压缩宽度和高度到所需的尺寸。确切地说,你应该使用哪种方法取决于你的变化因素的复杂性(第4.1.3节)——在某些情况下,忽略纵横比就可以了;在其他情况下,你会想要保持纵横比
1 # import the necessary packages
2 import cv2
3
4 class SimplePreprocessor:
5 def __init__(self, width, height, inter=cv2.INTER_AREA):
6 # store the target image width, height, and interpolation
7 # method used when resizing
8 self.width = width
9 self.height = height
10 self.inter = inter
11
12 def preprocess(self, image):
13 # resize the image to a fixed size, ignoring the aspect
14 # ratio
15 return cv2.resize(image, (self.width, self.height),
16 interpolation=self.inter)
代码解释:
第2行导入了我们唯一需要的包,我们的OpenCV绑定。然后我们在第5行上定义SimpleProcessor类的构造函数。构造函数需要两个参数,然后是第三个可选参数,每个参数详细如下:
•width:调整后的输入图像的目标宽度。•height:调整后的输入图像的目标高度。•inter:一个可选参数,用于控制调整大小时使用哪种插值算法。
预处理函数定义在第12行,它只需要一个参数—我们想要预处理的输入图像。
第15行和第16行对图像进行预处理,将其调整为固定的宽度和高度大小,然后将其返回给调用函数。
同样,这个预处理器的定义是非常基本的——我们所做的就是接受一个输入图像,调整它的大小到固定的尺寸,然后返回它。然而,当在下一节中与图像数据集加载器结合时,该预处理器将允许我们快速从磁盘加载和预处理数据集,使我们能够快速通过图像分类管道并转移到更重要的方面,例如训练我们的实际分类器。
7.1.4构建镜像加载器
现在我们的SimplePreprocessor已经定义好了,让我们继续看SimpleDatasetLoader:
1 # import the necessary packages
2 import numpy as np
3 import cv2
4 import os
5
6 class SimpleDatasetLoader:
7 def __init__(self, preprocessors=None):
8 # store the image preprocessor
9 self.preprocessors = preprocessors
10
11 # if the preprocessors are None, initialize them as an
12 # empty list
13 if self.preprocessors is None:
14 self.preprocessors = []
代码解释:
第2-4行导入所需的Python包:NumPy用于数值处理,cv2用于OpenCV绑定,os用于提取图像路径中的子目录名。
第7行定义了SimpleDatasetLoader的构造函数,我们可以选择传入一个图像预处理程序列表(例如SimpleProcessor),这些图像预处理程序可以依次应用于给定的输入图像。
指定这些预处理器列表而不是单个值是很重要的——会有次我们首先需要调整图像afixed大小,然后执行某种形式的扩展(如平均减法),其次是将图像数组转换为适合Keras格式。这些预处理器中的每一个都可以独立实现,使我们能够以一种有效的方式将它们顺序地应用到图像中。
然后我们就可以进入load方法,SimpleDatasetLoader的核心:
16 def load(self, imagePaths, verbose=-1):
17 # initialize the list of features and labels
18 data = []
19 labels = []
20
21 # loop over the input images
22 for (i, imagePath) in enumerate(imagePaths):
23 # load the image and extract the class label assuming
24 # that our path has the following format:
25 # /path/to/dataset/{class}/{image}.jpg
26 image = cv2.imread(imagePath)
27 label = imagePath.split(os.path.sep)[-2]
我们的加载方法需要一个参数—imagepath,它是一个列表,指定驻留在磁盘上的数据集中的图像的文件路径。我们还可以为verbose提供一个值。这个“冗长级别”可以用来将更新打印到控制台,允许我们监视SimpleDatasetLoader处理了多少图像。
第18行和第19行初始化数据列表(即图像本身)和标签,即图像的类标签列表。
在第22行,我们开始循环每个输入图像。对于这些图像,我们从磁盘加载它(第26行),并根据文件路径(第27行)提取类标签。我们假设我们的数据集按照以下目录结构组织在磁盘上:

dataset_name可以是数据集的名称,在本例中是动物。类应该是类标签的名称。在我们的示例中,类是dog、cat或panda。最后,image.jpg是实际图像本身的名称。
基于这种分层的目录结构,我们可以保持数据集整洁有序。因此,可以假定dog子目录中的所有图像都是dog的示例。类似地,我们假设panda目录中的所有图像都包含熊猫的示例。
我们在用Python进行的计算机视觉深度学习中检查的几乎每一个数据集都将遵循这种分层目录设计结构——我强烈建议您在自己的项目中也这样做。
现在我们的图像已经从磁盘加载,我们可以对它进行预处理(如果必要的话)
29 # check to see if our preprocessors are not None
30 if self.preprocessors is not None:
31 # loop over the preprocessors and apply each to
32 # the image
33 for p in self.preprocessors:
34 image = p.preprocess(image)
35
36 # treat our processed image as a "feature vector"
37 # by updating the data list followed by the labels
38 data.append(image)
39 labels.append(label)
第30行做了一个快速检查,以确保我们的预处理程序不是None。如果检查通过,我们循环遍历第33行上的每个预处理处理器,并将它们依次应用于第34行上的图像——这个操作允许我们形成一个可以应用于数据集中的每一张图像的预处理链。
图像预处理完成后,我们分别更新数据和标签列表(第39行和第39行)。
最后一个代码块只是处理将更新打印到控制台,然后将数据和标签的两个元组返回给调用函数
41 # show an update every ‘verbose‘ images
42 if verbose > 0 and i > 0 and (i + 1) % verbose == 0:
43 print("[INFO] processed {}/{}".format(i + 1,
44 len(imagePaths)))
45
46 # return a tuple of the data and labels
47 return (np.array(data), np.array(labels))
正如你所看到的,我们的数据集加载器的设计很简单;然而,它使我们能够轻松地将任意数量的图像处理器应用于数据集中的每一张图像。这个数据集加载器唯一需要注意的是,它假设数据集中的所有图像都可以一次放入主存中。
对于太大而无法装入系统RAM的数据集,我们需要设计一个更复杂的数据集加载器——我在从业者Bundle中介绍了这些更高级的数据集加载器。现在我们了解了如何(1)预处理图像和(2)从磁盘加载图像集合,现在我们可以进入图像分类阶段。
7.2 k-NN:一个简单的分类器
k近邻分类器是迄今为止最简单的机器学习和图像分类算法。事实上,它是如此简单,以至于它实际上并没有“学到”任何东西。相反,该算法直接依赖于特征向量之间的距离(在我们的例子中,是图像的原始RGB像素强度)。
简单地说,k- nn算法通过在k个最接近的例子中找到最常见的类来分类未知的数据点。k个最接近的数据点中的每个数据点都投一票,票数最高的类别获胜。或者,用简单的英语说:“告诉我你的邻居是谁,我就告诉你你是谁”[64],如图7.2所示。
为了让k-NN算法工作,它首先假设具有相似视觉内容的图像在n维空间中紧密地分布在一起。在这里,我们可以看到三种类型的图像,分别表示为狗、猫和熊猫。在这个假设的例子中,我们沿着x轴绘制动物皮毛的“蓬松性”,沿着y轴绘制动物皮毛的“轻度”。每个动物数据点在我们的n维空间。这意味着两只猫之间的距离比一只猫和一只狗之间的距离要小得多。
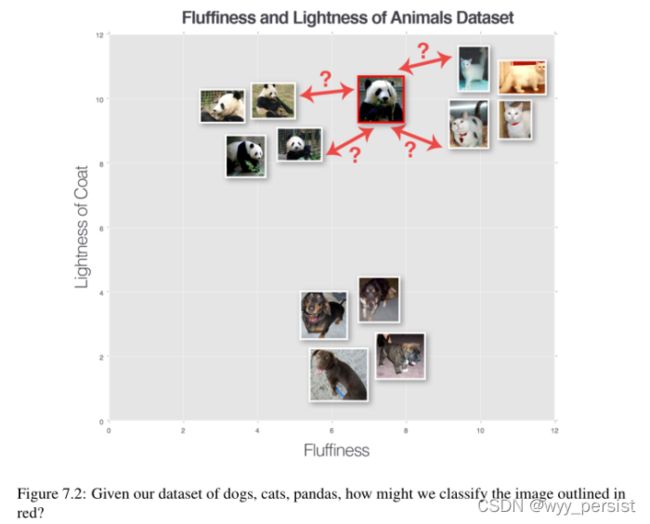
然而,为了应用k-NN分类器,我们首先需要选择一个距离度量或相似函数。一个常见的选择包括欧几里得距离(通常称为L2distance):

然而,其他距离度量,如曼哈顿/城市街区(通常称为l1距离)也可以使用:

实际上,您可以使用最适合您的数据(并给您最好的分类结果)的距离度量/相似性函数。然而,在这节课的剩余部分,我们将使用最流行的距离度量:欧几里得距离。
7.2.1 k-NN故障示例
至此,我们了解了k-NN算法的原理。我们知道它依赖于特征向量/图像之间的距离来进行分类。我们知道它需要一个距离/相似度函数来计算这些距离。
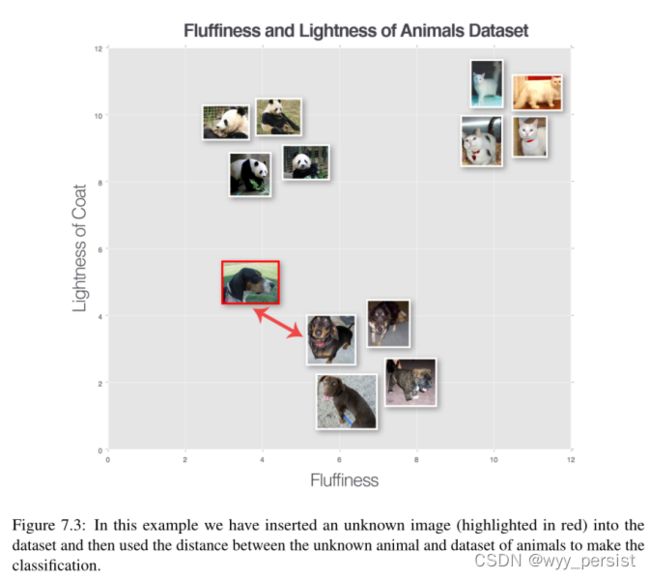
但是我们如何进行分类呢?为了回答这个问题,让我们看看图7.3。这里我们有三种动物的数据集——狗、猫和熊猫——我们根据它们的绒毛和皮毛的轻度绘制了它们。
我们还插入了一个“未知动物”,我们试图只使用一个邻居(即k = 1)对其进行分类。在这种情况下,离输入图像最近的动物是一个狗数据点;因此我们的输入图像应该归类为狗。
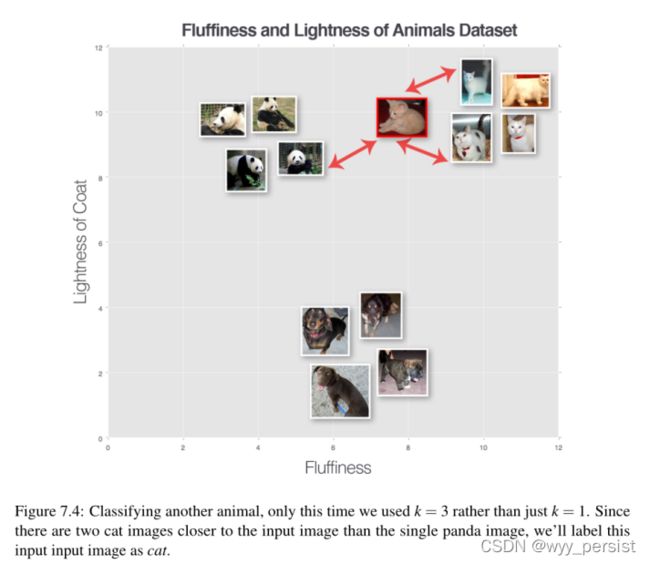
让我们尝试另一个“未知动物”,这次使用k = 3(图7.4)。我们发现前三名中有两只猫和一只熊猫。因为cat类别拥有最多的票数,所以我们将输入图像分类为cat。
我们可以一直执行这个过程对于不同的k值,但无论多么大或小k,原理是相同的——与选票最多的类别k最近的训练点胜是用作输入标签数据点。
重点:在打成平手的情况下,k-NN算法随机选择一个打成平手的类标签。
7.2.2事例Hyperparameters
在运行k-NN算法时,有两个明显的超参数需要考虑。第一个很明显,k的值,k的最优值是多少?如果它太小(例如k = 1),那么我们会获得效率,但会变得容易受到噪声和异常数据点的影响。然而,如果k太大,那么我们就有过度平滑分类结果和增加偏倚的风险。
我们应该考虑的第二个参数是实际距离度量。欧氏距离是最好的选择吗?曼哈顿的距离是多少?
在下一节中,我们将在Animals数据集上训练k-NN分类器,并在测试集上评估模型。我鼓励您使用不同的k值和不同的距离度量,注意性能如何变化。
要详细了解如何调优k-NN超参数,请参阅PyImageSearch Gurus课程[33]中的第4.3课。
7.2.3实施KNN
本节的目标是在Animals数据集的原始像素强度上训练一个k-NN分类器,并使用它来分类未知的动物图像。我们将使用四步管道来训练第4.3.2节中的分类器:
第1步-收集我们的数据集:动物数据集由3000张图片组成,每只狗、猫和熊猫类分别有1000张图片。每个图像都是用RGB表示的颜色空间。我们将对每张图像进行预处理,将其大小调整为32 × 32像素。考虑到三个RGB通道,图像尺寸的调整意味着数据集中的每一幅图像都由32 × 32 × 3 = 3072个整数表示。
步骤2 -分割数据集:对于这个简单的例子,我们将使用数据的两次分割。一个用于训练,另一个用于测试。我们将省略超参数调优的验证集,并将此留给读者作为练习。
步骤#3 -训练分类器:我们的k-NN分类器将根据训练集中图像的原始像素强度进行训练。
步骤#4 -评估:一旦我们的k-NN分类器训练好,我们就可以评估测试集上的性能。
让我们开始吧。打开一个新文件,命名为knn.py,并插入以下代码:
1 # import the necessary packages
2 from sklearn.neighbors import KNeighborsClassifier
3 from sklearn.preprocessing import LabelEncoder
4 from sklearn.model_selection import train_test_split
5 from sklearn.metrics import classification_report
6 from pyimagesearch.preprocessing import SimplePreprocessor
7 from pyimagesearch.datasets import SimpleDatasetLoader
8 from imutils import paths
9 import argparse
//上述是引入包的代码块

//这是解析命令行输入的代码块
•—dataset:我们的输入图像数据集驻留在磁盘上的路径。•——neighbors:可选,使用k- nn算法时应用的邻居数k。•——jobs:可选,在计算输入数据点与训练集之间的距离时要运行的并发作业数量。-1的值将使用处理器上所有可用的内核。
现在我们的命令行参数已经被解析,我们可以获取数据集中图像的文件路径,然后加载和预处理它们(分类管道中的步骤#1):
# grab the list of images that we’ll be describing
22 print("[INFO] loading images...")
23 imagePaths = list(paths.list_images(args["dataset"]))
24
25 # initialize the image preprocessor, load the dataset from disk,
26 # and reshape the data matrix
27 sp = SimplePreprocessor(32, 32)
28 sdl = SimpleDatasetLoader(preprocessors=[sp])
29 (data, labels) = sdl.load(imagePaths, verbose=500)
30 data = data.reshape((data.shape[0], 3072))
31
32 # show some information on memory consumption of the images
33 print("[INFO] features matrix: {:.1f}MB".format(
34 data.nbytes / (1024 * 1000.0)))
第23行获取数据集中所有图像的文件路径。然后在第27行初始化用于将每张图像的大小调整为32 × 32像素的SimplePreprocessor。
在第28行初始化SimpleDatasetLoader,并将实例化的SimplePreprocessor作为参数提供(这意味着sp将应用于数据集中的每个图像)。
在第29行调用.load从磁盘加载实际的图像数据集。这个方法返回一个2元组的数据(每个图像的大小调整为32 × 32像素)以及每个图像的标签
从磁盘加载图像后,数据NumPy数组的形状为(3000,32,32,3),表明数据集中有3000幅图像,每个32 × 32像素有3个通道。
然而,为了应用k-NN算法,我们需要将图像从3D表示“平化”为单个像素强度列表。完成后,第30行调用数据NumPy数组上的.重塑方法,将32 × 32 × 3图像平展成具有形状(3000,3072)的数组。实际的图像数据完全没有改变——这些图像只是简单地表示为3000个条目的列表,每个条目的亮度为3072 (32 × 32 × 3 = 3072)。
为了演示在内存中存储这3,000个图像需要多少内存,第33和34行计算数组消耗的字节数,然后将该数转换为兆字节)。
接下来,让我们构建我们的训练和测试分割(步骤2):

第37行和第38行将标签(表示为字符串)转换为整数,每个类只有一个整数。这个转换允许我们将cat类映射为整数0,将dog类映射为整数1,将panda类映射为整数2。许多机器学习算法假设类标签被编码为整数,所以我们必须养成执行这一步的习惯。
训练和测试分割的计算由第42和43行上的train_test_split函数处理。在这里,我们将数据和标签划分为两个独特的集合:75%的数据用于训练,25%用于测试。
通常使用变量X指代包含我们将用于训练和测试的数据点的数据集,而y指代类标签(关于参数化学习的第8章将详细介绍这一点)。因此,我们使用变量trainX和testX分别表示训练和测试示例。变量trainY和testY是我们的训练和测试标签。你会在本书和其他机器学习书籍、课程和教程中看到这些常见的符号。
最后,我们能够创建我们的k-NN分类器并评估它(图像分类管道中的步骤#3和#4):

第47和48行初始化KNeighborsClassifier类。调用.fit方法49行“火车”分类器,虽然没有实际的“学习”怎么回事——事例的模型仅仅是存储trainX和trainY数据内部,这样就可以创建预测计算设定的测试输入数据之间的距离和trainX数据。
第50和51行通过使用classification_report函数来评估分类器。这里,我们需要提供testY类标签、模型中预测的类标签,以及可选的类标签名称(例如,“dog”、“cat”、“panda”)。
7.2.4kNN结果
要运行我们的k-NN分类器,执行以下命令:
然后你应该看到如下输出类似如下:
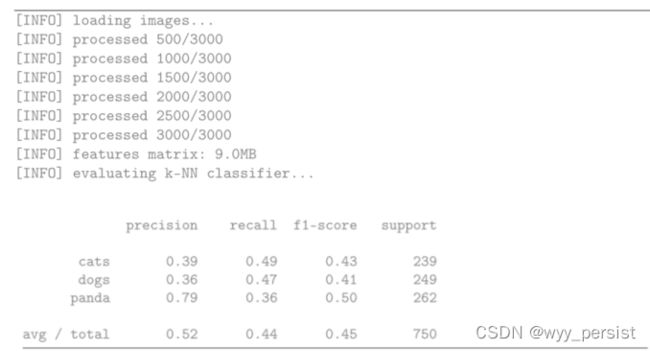
请注意,我们的特征矩阵对于3000张图像只消耗9MB的内存,每张图像的大小为32 × 32 × 3——这个数据集可以很容易地存储在现代机器的内存中,没有任何问题。
评估我们的分类器,我们看到我们获得了52%的准确率——考虑到随机猜测正确答案的概率是1/3,对于一个根本不做任何真正“学习”的分类器来说,这个准确率并不坏。
但是,检查每个类标签的准确性是很有趣的。“熊猫”类的准确率为79%,这可能是因为熊猫大部分是黑白的,因此在我们3072暗的空间里,这些图像距离更近。
狗和猫的分类准确率相对较低,分别为39%和36%。这些结果可以归因于这样一个事实,即狗和猫可以有非常相似的皮毛深浅,它们的皮毛颜色不能用来区分它们。背景噪音(如后院的草,动物休息的沙发的颜色,等等)也会“混淆”k-NN算法,因为它无法学习任何区分这些物种的模式。这种混乱是k-NN算法的主要缺点之一:虽然它很简单,但它也无法从数据中学习。
我们的下一章将讨论参数化学习的概念,我们可以从图像本身学习模式,而不是假设具有相似内容的图像将聚集在一个n维空间中。
7.2.5 k-NN的利弊
k-NN算法的一个主要优点是它的实现和理解非常简单。此外,分类器完全不需要训练时间,因为我们所需要做的就是存储我们的数据点,以便稍后计算到它们的距离,并获得我们最终的分类。
然而,我们在分类时为这种简单性付出了代价。分类一个新的测试点需要与我们的训练数据中的每一个数据点进行比较,这扩展了O(N),使得使用更大的数据集在计算上是禁止的。
我们可以通过使用近似最近邻(ANN)算法(如kd-trees [65], FLANN[66],随机投影[67,68,69]等)来解决这个时间开销;然而,使用这些算法需要我们用空间/时间复杂性来换取最近邻算法的“正确性”,因为我们正在执行一个近似。也就是说,在很多情况下,使用k-NN算法是很值得的,而且在准确性上损失很小。这种行为与大多数机器学习算法(以及所有的神经网络)不同,在大多数机器学习算法中,我们花费大量的时间预先训练我们的模型以获得较高的准确性,反过来,在测试时能够非常快速地分类。
最后,k-NN算法更适合于低维特征空间(图像不适合)。高维特征空间中的距离通常是不直观的,你可以在Pedro Domingo的优秀论文[70]中读到更多。
同样需要注意的是,k-NN算法实际上并没有“学习”任何东西-算法不能使自己更聪明,如果它犯了错误;它只是简单地依靠n维空间中的距离来进行分类。
考虑到这些缺点,为什么还要费心去研究k-NN算法呢?原因是算法很简单。这很容易理解。最重要的是,它给了我们一个可以用来比较神经网络和卷积神经网络的基线,当我们在本书的其余部分的进展时。
7.3总结
在本章中,我们学习了如何构建一个简单的图像处理器,并将图像数据集加载到内存中。然后我们讨论了k近邻分类器,简称k-NN。
k-NN算法通过将未知数据点与训练集中的每个数据点进行比较,对未知数据点进行分类。比较是使用距离函数或相似性度量来完成的。然后,从训练集中k个最相似的例子中,我们累积每个标签的“投票”数量。拥有最高票数的类别“获胜”,并被选为整体分类。
虽然k-NN算法简单直观,但也存在一些缺点。首先,它实际上并没有“学习”任何东西——如果算法犯了错误,它没有办法“纠正”和“改进”自己,以便以后的分类。其次,由于没有专门的数据结构,k-NN算法随着数据点数量的增加而线性扩展,这不仅使其在高维中使用具有实际挑战性,而且在理论上的使用也存在问题[70]。
现在我们已经获得了使用k-NN算法进行图像分类的基线,我们可以继续参数化学习,所有深度学习和神经网络都是建立在参数化学习的基础上。使用参数化学习,我们实际上可以从输入数据中学习,并发现潜在的模式。这一过程将使我们能够构建高精度的图像分类器,从而彻底颠覆k-NN的性能。
上述实验代码详见本人github地址:
TheWangYang/Code_For_Deep_Learning_for_Computer_Vision_with_Python: A code repository for Deep Learning for Computer Vision with Python. (github.com)