序列模型之循环神经网络(一)
目录
一.数学符号
二.循环神经网络RNN
1.图示网络原理和结构
2.RNN计算过程
3.前向传播&反向传播
三.不同类型的循环神经网络
一.数学符号
先来一个很简单的例子,输入一个句子,然后句子中的每一个单词都对应一个输出,表明此单词是否是人名。

x^(i)
训练集里不同的训练样本的序列长度可能不一样。T_x是输入序列的长度,T_y是输出序列的长度。
T^(i)_x代表第i个训练样本的输入序列长度,T^(i)_y代表第i个训练样本的输出序列长度。
然后我们来看一下如何表示句子中的每个单词,即x^
首先我们需要建立一个我们词典,这个词典中存放我们可能会用的词,然后可以用下标进行索引,
对于一般规模的商业应用来说,30000到50000词大小的词典比较常见,但是100000词的也不是没有,一些大型的互联网公司甚至可能用百万词的词典。
咱们这里用一个10000词的词典来举例,
构建词典的方式:遍历你的训练集,然后统计出使用频率前10000的词放到你的词典中(也可以参考网上的英文词典,他也会告诉你哪些词常用以及频率排名),然后用One-hot表示法来表示你自己创建的词典里的每个单词。如下图所示,训练示例中的每个单词其实都对应一个one-hot向量(10000*1,因为咱们的词典是10000个词),即one-hot向量中值为1对应的那个下标对应到词典中就是x^

如果遇到了一个不在你词典当中的单词的话,我们需要做一个标记,也就是一个叫做Unknown Word的伪造单词,我们标记为
另外说明一点,咱们这个问题是用监督学习来做,所以肯定是有标签的。
二.循环神经网络RNN
1.图示网络原理和结构
我们先来看一下解决这个问题用一个咱们之前接触过的一个标准的神经网络怎么样呢?答案是否定的,原因有二:其一是我们不同的训练示例的输入序列和输出序列可能都不一样长,即便我们确定所有序列的最大长度,然后对不到这个长度的序列进行填充,仍旧不是好方法;其二标准的神经网络解决这个问题的话做不到特征信息的共享,比如我们在位置1确定了Harry可能是人名的一部分,然后下一个序列中Harry中又换到了别的位置,那么也将其识别为人名的一部分就很好了,但是标准的NN很难做到这个。

并且我们之前说过我们的one-hot向量是10000维的,所以神经网络的第一个隐藏层就会有很多的参数,过于庞大,然后我们接下来讲的这个网络结构就没有这个问题。
循环神经网络:
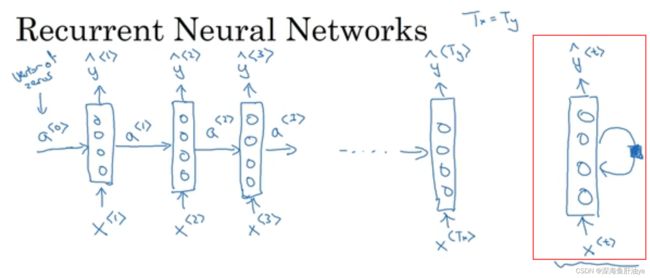
如上图,从左侧看起,我们输入一个序列,这个序列中的元素分别是x^<1>~x^
上面的文字详细的说明了RNN的部分过程,最右侧红框里的是另外一种表示形式,直观的可以看到是个循环的形式。
然后我们往下看RNN的更详细的过程:

先来说一下RNN的权重参数,x^
但是上面的这个RNN有个缺点就是它在某一时刻的预测仅使用了序列中之前的输入信息,并没有使用序列中后部分的信息,比如我们得到yhat^<3>可以看作仅仅只是通过x^<3>和时间步1和时间步2的信息得来的,而后面的x^<4>~x^
2.RNN计算过程
然后我们来看一下RNN具体计算了些什么:
循环神经网络中计算a^
具体计算公式见下图:

把上面的符号简化一下,就会得到下面的式子:
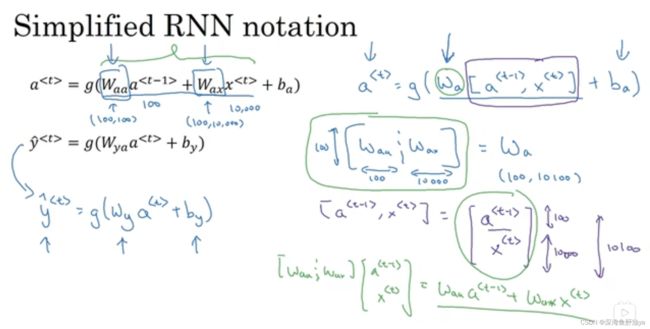
即用矩阵化简了,现代我快忘了基本上(捂脸哭),giao,不过这里先不必深究。大致看懂即可。
3.前向传播&反向传播
前向传播:
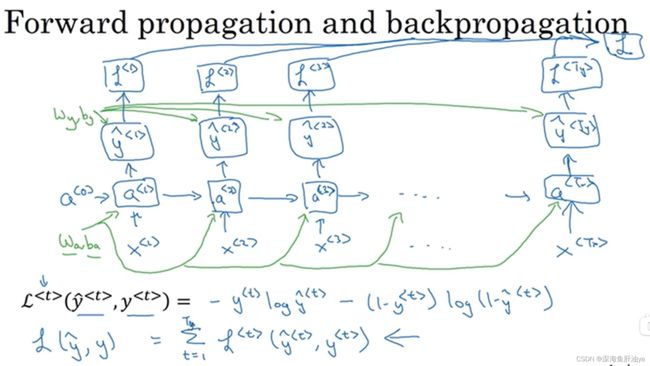
损失函数的定义中,比如还是我们上面的那个例子,y^
反向传播:
不说了吧,没啥可说的,框架都给你自动求导了,看个乐就行了,哈哈(开玩笑,想深究的可以去学反向传播算法)
Backpropagation through time,很cool的一个名字,时间反向传播,只可惜学会了我也回不到过去了(hhhh矫情一波)
三.不同类型的循环神经网络
我们上面讲的那个例子是输入序列的元素个数和输出序列的元素个数一样,Many to Many结构(多对多),即T_x=T_y,但是根据实际情况的不同,还有很多种情况,我们也得相应的修改RNN结构。
下图从左至右依次是多对多,多对一,一对一(一对一只是为了结构完整性画上的,其实不重要)
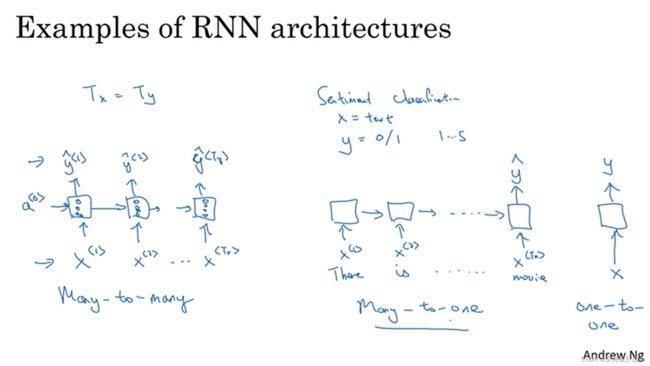
上图中间那个多对一举例:输入一段电影评论(文本),然后输出一个数(0-5,代表给电影的打分)。
然后下面是一对多和多对多(输入长度≠输出长度)的例子
一对多的例子就是音乐生成,你可以什么都不输入,或者只输入一个数(代表你喜欢的音乐类型或想要生成的音乐的第一个乐符等),然后生成一段音乐(注意这种结构一般会把上个时间步输出的yhat喂入下一个时间步的输入)。如下图左侧部分。
然后多对多(输入长度≠输出长度)的一个例子就是机器翻译,你输入一段英文,然后翻译成一段中文,那么输入输出长度可能不相等,该结构可以看成两部分。左边的输入部分是编码器,右边的输出部分是解码器。如下图右侧部分。

总结:
