MMDetection训练自己的数据集过程
接着前一篇MMDetection亲测安装教程,安装好后就来尝试训练自己的数据集吧,以训练 RetinaNet 模型为例说明。
1. 准备数据集
本文采用VOC格式训练,在 mmdetection 项目中新建data文件夹,按如下组织形式存放自己的数据。
./data
└── VOCdevkit
└── VOC2007
├── Annotations # 标注的VOC格式的xml文件
├── JPEGImages # 数据集图片
└── ImageSet
└── Main # 存放训练验证测试集图片名称列表的txt
├── test.txt # 划分的测试集
├── train.txt # 划分的训练集
├── trainval.txt # 训练和验证合集
└── val.txt # 划分的验证集
2. 修改相关配置文件
2.1 修改模型配置文件
修改 mmdetection/configs/retinanet/retinanet_r50_fpn_1x_coco.py
_base_ = [
'../_base_/models/retinanet_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
将第3行改为
'../_base_/datasets/voc0712.py',
还可以配置优化器 optimizer
optimizer = dict(type='Adam', lr=0.0005, weight_decay=0.0001)
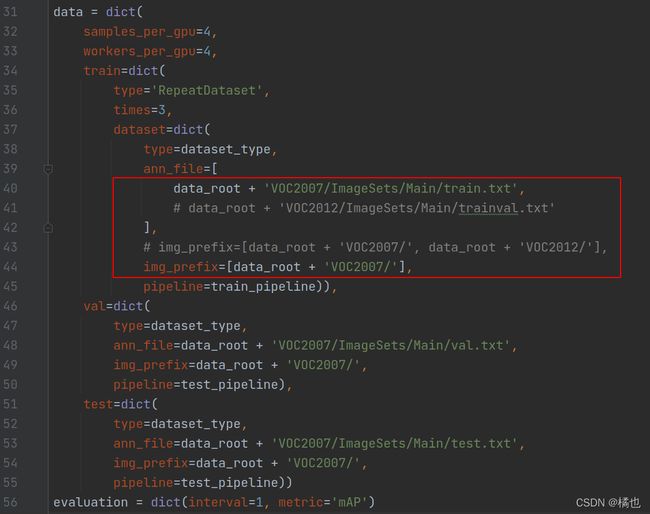
2.2 修改训练数据的配置文件
修改 mmdetection/configs/_ base_/datasets/voc0712.py
因为使用的是VOC2007,因此只要把其中含有VOC2012的注释即可。
可以修改数据集的路径 data_root、ann_file、img_prefix、samples_per_gpu、workers_per_gpu、重复次数 times、interval、添加图像增强方式,修改图像缩放比例 img_scale。
img_scale: 图像的最大尺寸
samples_per_gpu:单个 GPU 的 Batch size
workers_per_gpu:单个 GPU 分配的数据加载线程数
times:使用 RepeatDataset 包装器来重复数据集的次数
interval:隔多少个epoch进行一次验证
2.3 修改模型文件中的类别个数
修改 mmdetection/configs/_ base_/models/retinanet_r50_fpn.py
将 num_classes 修改为自己数据集的类别数,是几类就写几。
2.4 修改测试时的标签类别文件
修改 mmdetection/mmdet/core/evaluation/class_names.py
将 def voc_classes() 改为要训练的数据集的类别名称。如果不改的话,最后测试的结果的名称还会是’aeroplane’, ‘bicycle’, ‘bird’, ‘boat’,…这些。
【注意】如果只有一个类别,需要加上一个逗号,否则将会报错,例如只有一个类别,如下:
def voc_classes():
return ['aeroplane', ]
2.5 修改voc.py文件
修改 mmdetection/mmdet/datasets/voc.py
将 CLASSES 修改为自己数据集的类别名称,同理只有一个类别的话,需要在最后面加逗号。
2.6 修改训练计划
修改 mmdetection/configs/_ base_/schedules/schedule_1x.py
可以修改学习率 lr 和迭代轮数 max_epochs
warmup=‘linear’, # 预热(warmup)策略,也支持 exp 和 constant
warmup_iters=500, # 预热的迭代次数
warmup_ratio=0.001, # 用于热身的起始学习率的比率
step=[8, 11]) # 衰减学习率的起止回合数
【注】默认学习率 lr=0.02 对应批大小 batch_size=16。因此需要根据实际情况,按比例缩放学习率。
batch_size = num_gpus * samples_per_gpu
lr = 0.02 * (batch_size / 16)
3. 开始训练
上面修改了代码后,要重新编译代码,再进行训练。重新编译的原因是因为环境里的源文件没有修改,直接训练会报错。mmdetection-master目录下只是一些python文件,真正运行程序时,运行的还是环境里的源文件。
在终端编译:
pip install -v -e .
再进行训练:
python tools/train.py configs/retinanet/retinanet_r50_fpn_1x_coco.py
 等到训练结束就可以测试模型效果啦。
等到训练结束就可以测试模型效果啦。
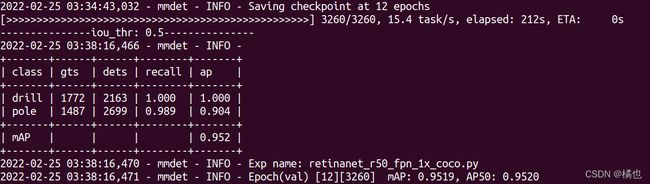
4. 可视化训练结果
python tools/analysis_tools/analyze_logs.py plot_curve ./work_dirs/retinanet_r50_fpn_1x_coco/20220222_202503.log.json --keys loss_cls loss_ bbox
xxxx.log.json为你训练过程中给产生的日志文件,一般在work_dirs目录下,
–key 后面可以跟参数 loss_cls 、loss_bbox等等,或者也可以跟bbox_mAP等等
loss_cls 、loss_bbox这些由于模型的不同,可能名字会有些不同,具体以你json文件里面的为准
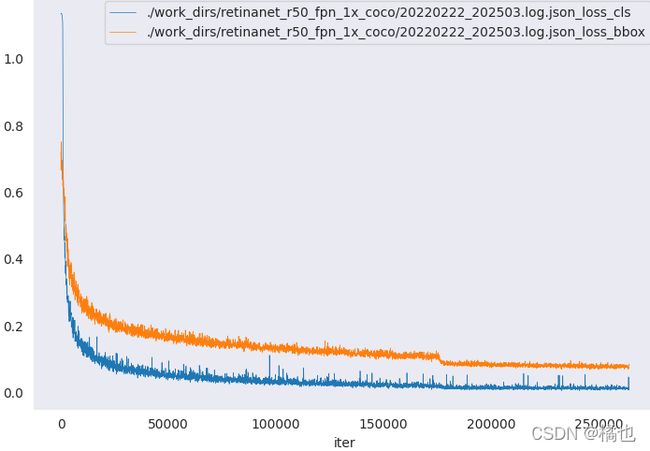
【注】loss类 和 mAP 不要一起画,因为 loss 每个iter都有,一个epoch会有很多个iter,但是 mAP 是每个 epoch 结束才有。如果两者同时出现会导致图像非常扭曲!!!
5. 在图片上测试
5.1 检测单张图片
测试的脚本为:mmdetection/demo/image_demo.py
以下命令是将测试图片001.jpg也放在了demo文件夹下,用训练好的最后一个模型.pth进行检测。
python demo/image_demo.py demo/001.jpg configs/retinanet/retinanet_r50_fpn_1x_coco.py work_dirs/retinanet_r50_fpn_1x_coco/latest.pth
5.2 检测整个测试集图片
测试的脚本为:mmdetection/tools/test.py
该命令针对测试集上的所有图片进行检测
python tools/test.py configs/retinanet/retinanet_r50_fpn_1x_coco.py work_dirs/retinanet_r50_fpn_1x_coco/latest.pth --out ./result.pkl --show-dir test_result
./result.pkl:生成一个result.pkl文件,该文件中会保存各个类别对应的信息,用于计算AP
-show-dir 参数,可以把检测图片结果保存到指定文件夹中
具体其他可选参数详见 test.py。
【注】.pkl 是python保存文件的一种文件格式,如果直接打开会显示一堆序列化的东西。该存储方式,可以将python项目过程中用到的一些暂时变量、或者需要提取、暂存的字符串、列表、字典等数据保存起来。需要使用的时候再 open,load。
 添加 --eval mAP 可以获得评估结果
添加 --eval mAP 可以获得评估结果
python tools/test.py configs/retinanet/retinanet_r50_fpn_1x_coco.py work_dirs/retinanet_r50_fpn_1x_coco/latest.pth --out ./result.pkl --eval mAP
6. 其他评估
测试的脚本为:tools/analysis_tools/get_flops.py
计算给定模型的浮点运算次数和参数大小,还可以看到整个模型结构。
python tools/analysis_tools/get_flops.py configs/retinanet/retinanet_r50_fpn_1x_coco.py --shape 1024 608
–shape 是模型输入尺寸

参考博客:
- mmdetection 训练自己的数据集[v2.14.0 (29/6/2021)]
- 最新版本的mmdetection2.0 (v2.0.0版本)环境搭建、训练自己的数据集、测试以及常见错误集合
- MMDetection v2 目标检测(3):配置修改