知识图谱可视化——Neo4j (windows)
目录
1、安装JDK环境;
2、安装neo4j;
3、快速使用neo4j自带示例;
4、导入自己的三元组(csv文件)
(一) 安装JDK环境
【notes】neo4j-4.*版本需要SDK11以及以上版本
因为上课需要,我在wins安装了JDK1.8,不想重新去改JDK版本,网上推荐可以安装neo4j-3.5.5版本。
jdk1.8和neo4j-3.5.5下载链接:
百度网盘 请输入提取码
提取码: 228q
1)下载JDK1.8解压到 F:\Java,然后配置环境变量

2) 环境变量配置 【所有填写的路径请根据自己的情况修改】
系统变量 --> 新建
CLASS_PATH 值为 :,F:\Java\jdk1.8.0_51\lib
JAVA_HOME 值为 F:\Java\jdk1.8.0_51
系统变量 --> 找到Path --> 编辑
新建 F:\Java\jdk1.8.0_51\bin


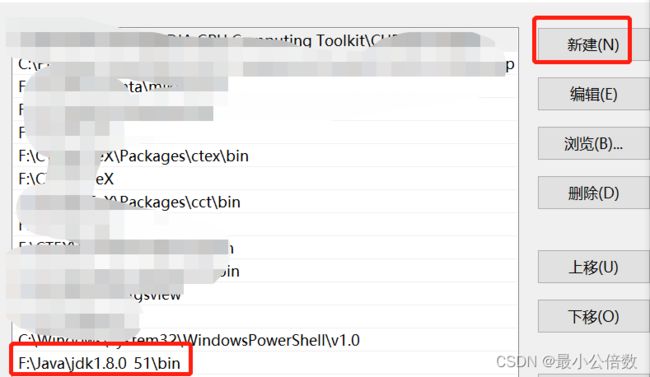
到此,JAVA环境配置完成。
3)测试java:
win+R 输入 “cmd” 回车。然后在命令框输入 java -version,即可看到版本信息。

(二) 安装Neo4j-3.5.5
1)下载压缩包,解压(路径自己决定)
2)配置neo4j的环境变量
系统变量,新建 NEO4J_HOME 值为 F:\neo4j-community-3.5.5
系统变量,找到Path ,编辑,添加 F:\neo4j-community-3.5.5\bin


到此,neo4j和JAVA环境都配置完成。
3)测试neo4j
同时按win+R键,输入“cmd”,从命令框进入上面解压的neo4j文件路径,输入命令:
neo4j.bat console

出现上图所示,则表示成功安装,现在可通过浏览器访问:http://localhost:7474/ 进入图数据库系统。【默认登陆密码为:neo4j】

(三) 使用Neo4j
1)示例数据库的使用:
Example Graph --> Movie Graph ,然后点击运行,即可。里面提供了相关教程可以参考。

2)导入csv数据
一般在使用可视化工具都是想把自己的数据成果展示;neo4j可以用命令创建结点,关系等等,生成图谱。网上有很多命令的教程:NoSQL 简介 | 菜鸟教程
我今天主要是记录下如何用neo4j自带的import功能,批量导入csv里面的三元组。
拿到手的原始数据(txt或者csv),每行结构“头结点--关系--尾结点”:

python脚本将其处理成:带结点ID标识和结点标签的entity.csv;结点与结点对应关系triples.csv
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import pandas as pd
import csv
# 读取csv三元组文件
df = pd.read_csv('ori_triples.csv')
print(df.info())
print(df.head())
# 或者读取txt三元组文件
# df_name = [":START_ID", "role", ":END_ID"]
# df = pd.read_table("ori_triples.txt", decimal="\t", names=df_name)
# 去除重复实体表示
entity = set()
entity_h = df[':START_ID'].tolist()
entity_t = df[':END_ID'].tolist()
for i in entity_h:
entity.add(i)
for i in entity_t:
entity.add(i)
print(len(entity), entity)
# 保存节点文件
csvf_entity = open("entity.csv", "w", newline='', encoding='utf-8')
w_entity = csv.writer(csvf_entity)
# 实体ID,要求唯一,名称,LABEL标签,可自己不同设定对应的标签
w_entity.writerow(("entity:ID", "name", ":LABEL"))
entity = list(entity)
entity_dict = {}
for i in range(len(entity)):
w_entity.writerow(("e" + str(i), entity[i], "my_entity"))
entity_dict[entity[i]] = "e" + str(i)
csvf_entity.close()
# 生成关系文件,起始实体ID,终点实体ID,要求与实体文件中ID对应,:TYPE即为关系
df[':START_ID'] = df[':START_ID'].map(entity_dict)
df[':END_ID'] = df[':END_ID'].map(entity_dict)
df[":TYPE"] = df['role']
df.pop('role')
df.to_csv("triples.csv", index=False)
entity.csv内容:

triples.csv内容:

导入文件——覆盖原数据库
1a) 关闭neo4j运行的命令窗,然后进入neo4解压路径,删除下图路径中的graph.db文件:

导入文件——新增数据库
2a) 将下图路径中的配置文件neo4j.conf用记事本打开,修改dbms.active_database=****.db, 其中***表示你需要导入的数据库名称。


b) import命令导入:【进入neo4j安装的bin路径下】
新版本命令:
.\neo4j-admin.bat import --database graph.db --id-type string --nodes F:\\neo4j-community-3.5.5\\import\\entity.csv --relationships F:\\neo4j-community-3.5.5\\import\\triples.csv旧版本命令:
.\neo4j-import.bat --into F:\\neo4j-community-3.5.5\\data\\databases\\graph.db --id-type string --nodes F:\\neo4j-community-3.5.5\\import\\entity.csv --relationships F:\\neo4j-community-3.5.5\\import\\triples.csv【注】如果选择覆盖原数据库,命令中的graph.db不用修改;如果选择新建数据库,命令中的graph.db需要修改为你自己定义的****.db。
c) 打开neo4j服务,参照上面步骤中的“测试neo4j”版块,打开浏览器,查看Database Information是否出现我们刚刚导入的数据:

